Downloaded 784 times





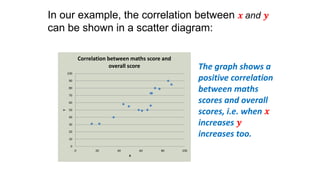
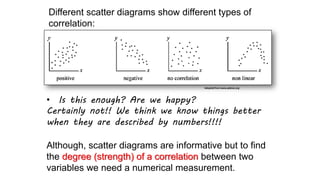



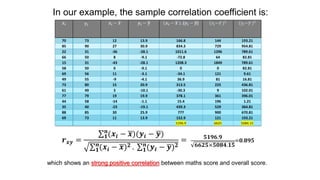
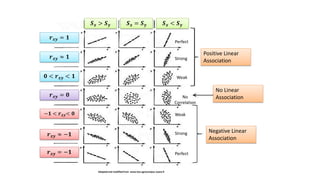


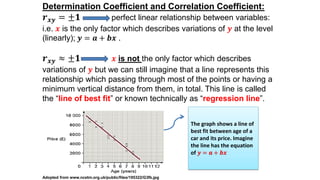










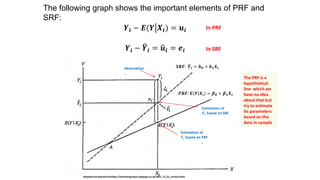

























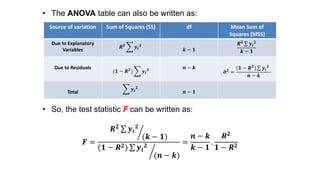


This document provides an introduction to correlation and regression analysis. It defines key concepts like variables, random variables, and probability distributions. It discusses how correlation measures the strength and direction of a linear relationship between two variables. Correlation coefficients range from -1 to 1, with values closer to these extremes indicating stronger correlation. The document also introduces determination coefficients, which measure the proportion of variance in one variable explained by the other. Regression analysis builds on correlation to study and predict the average value of one variable based on the values of other explanatory variables.















































































