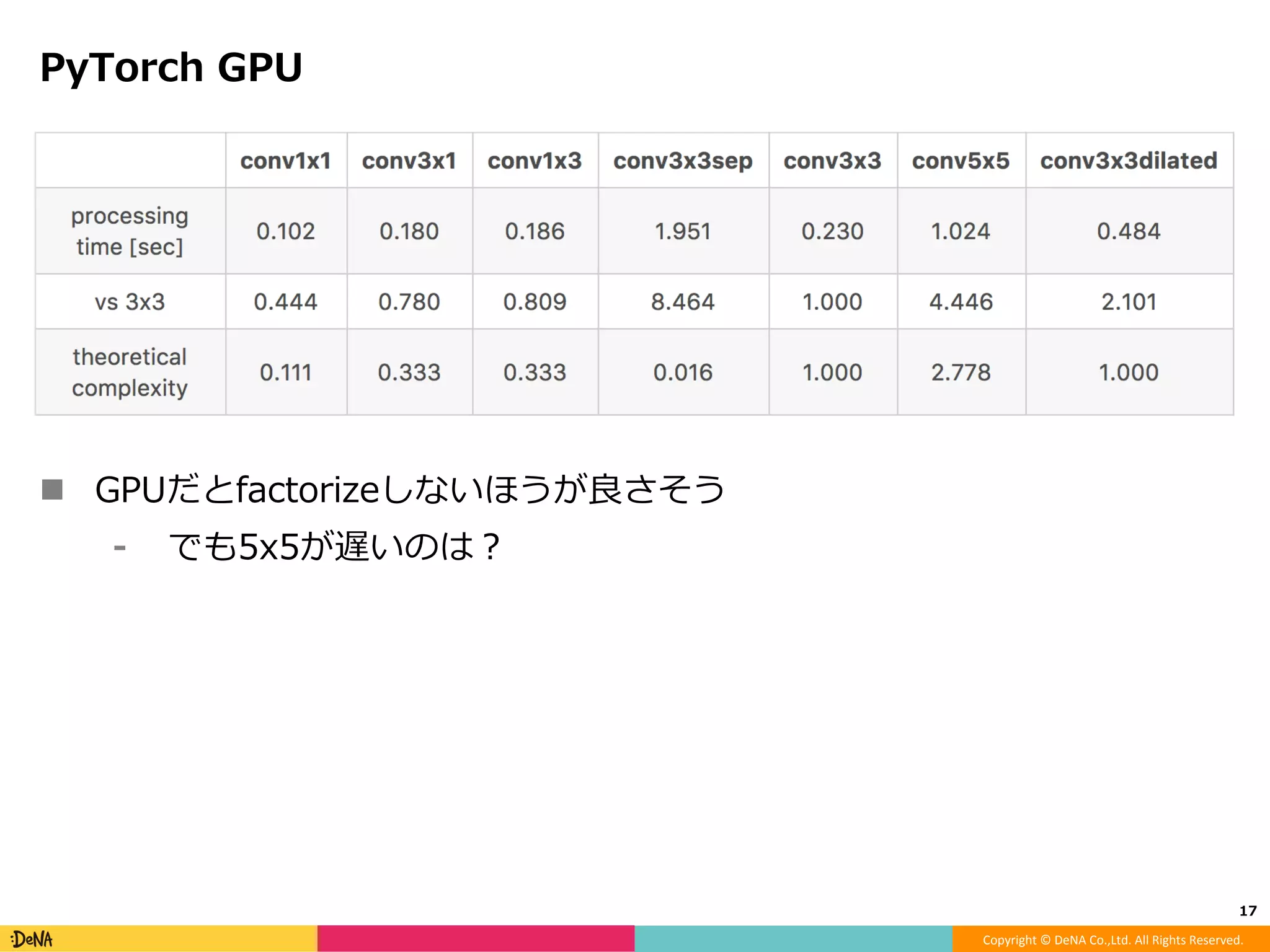
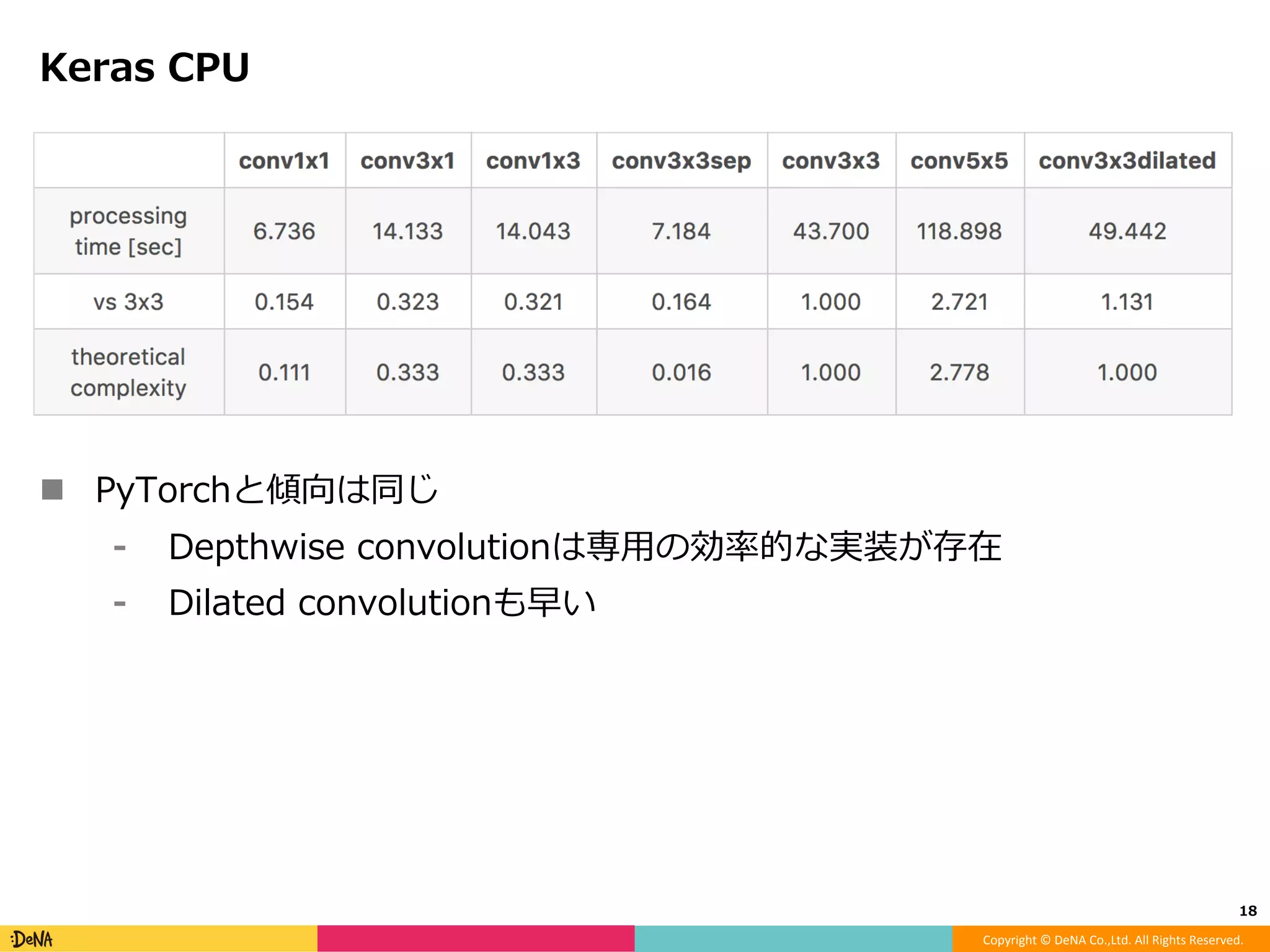
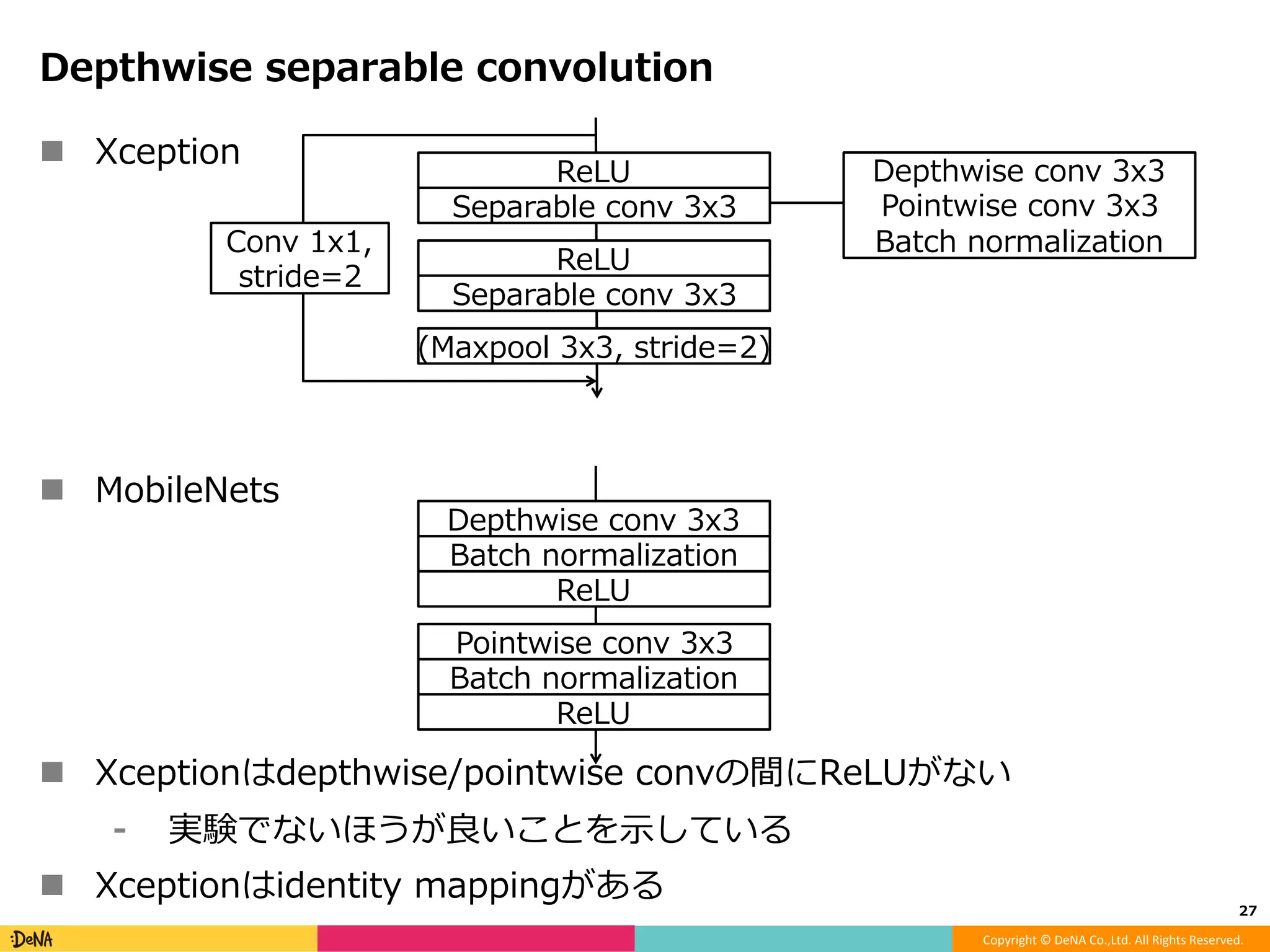
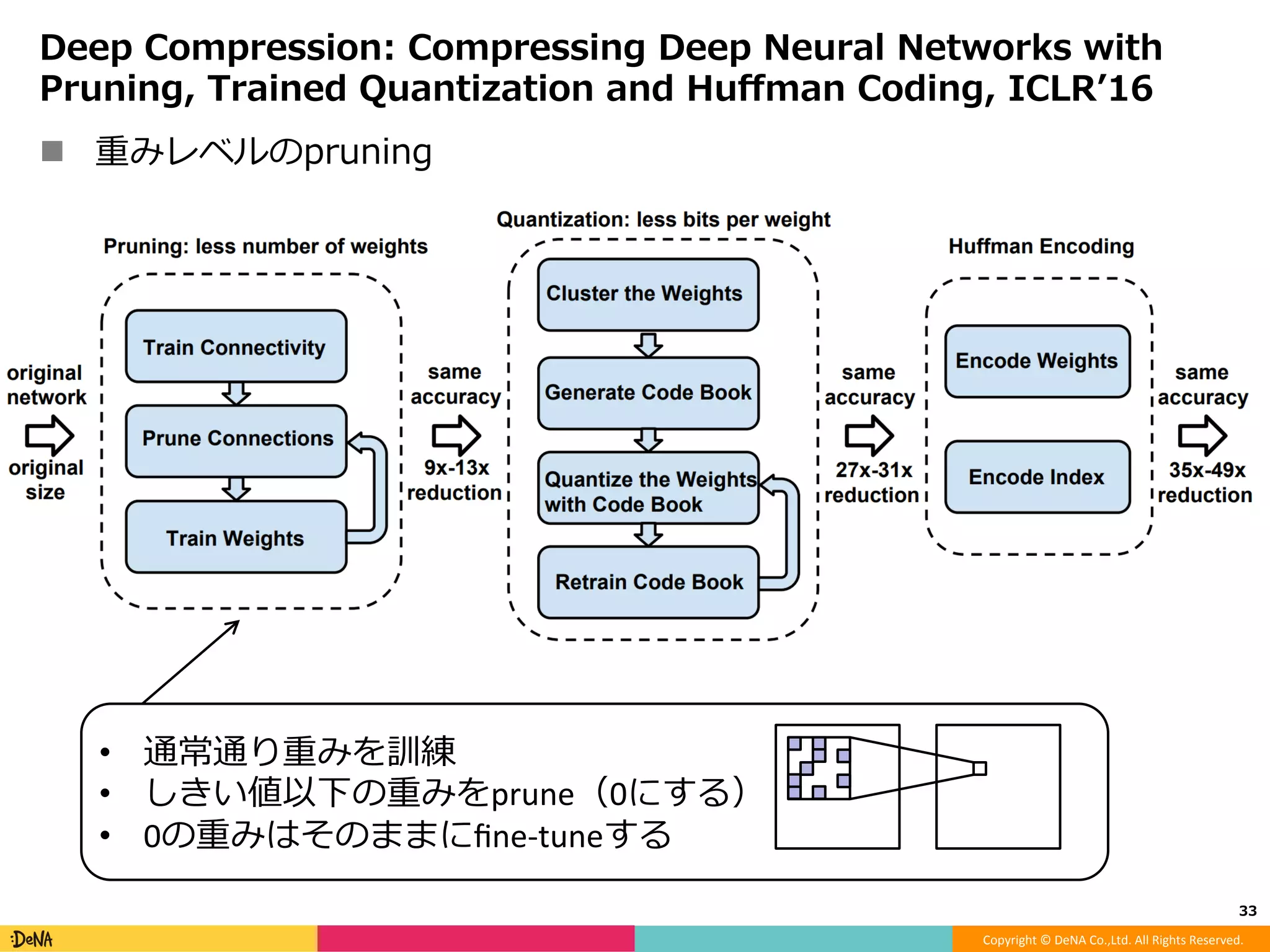
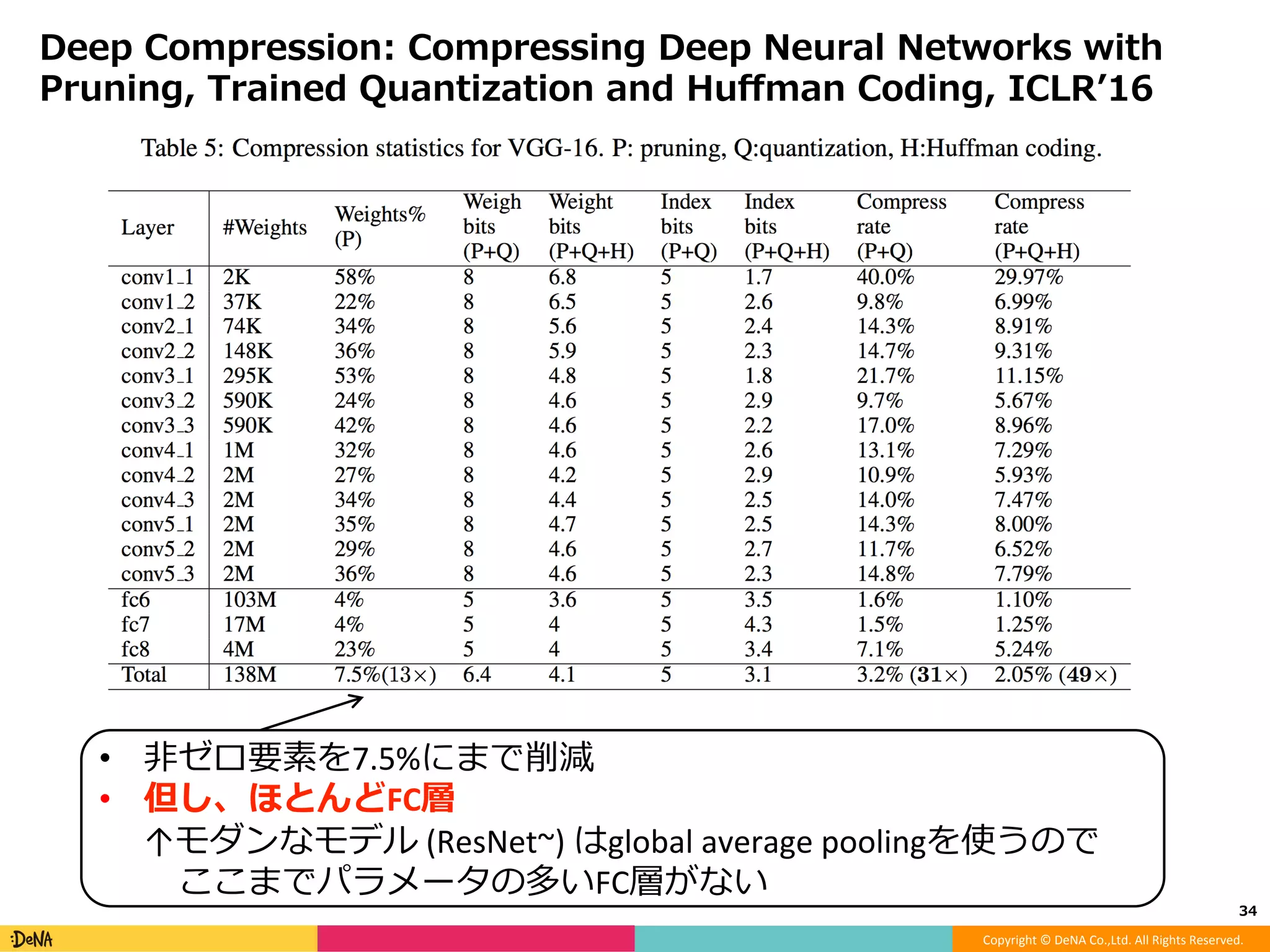
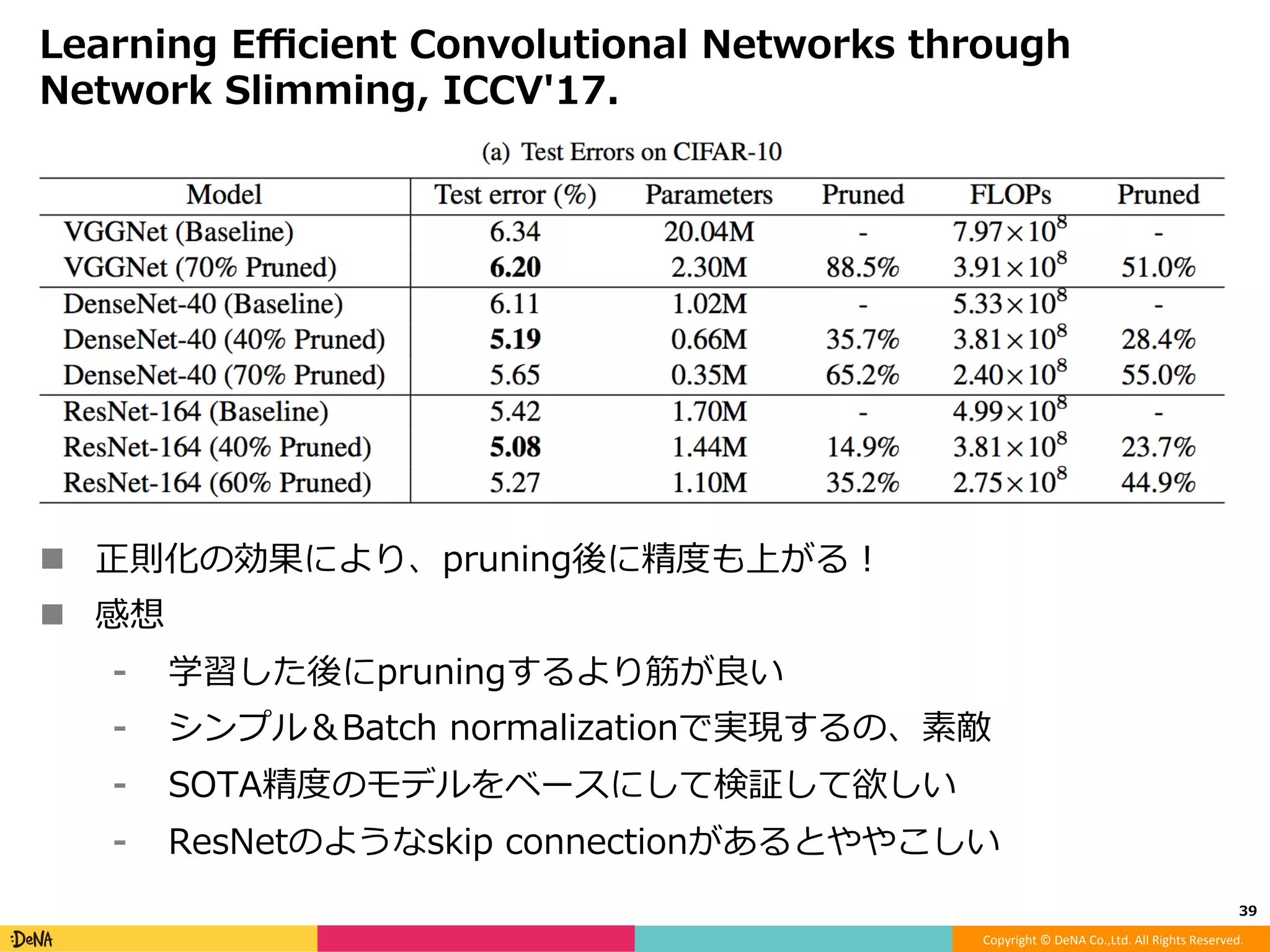
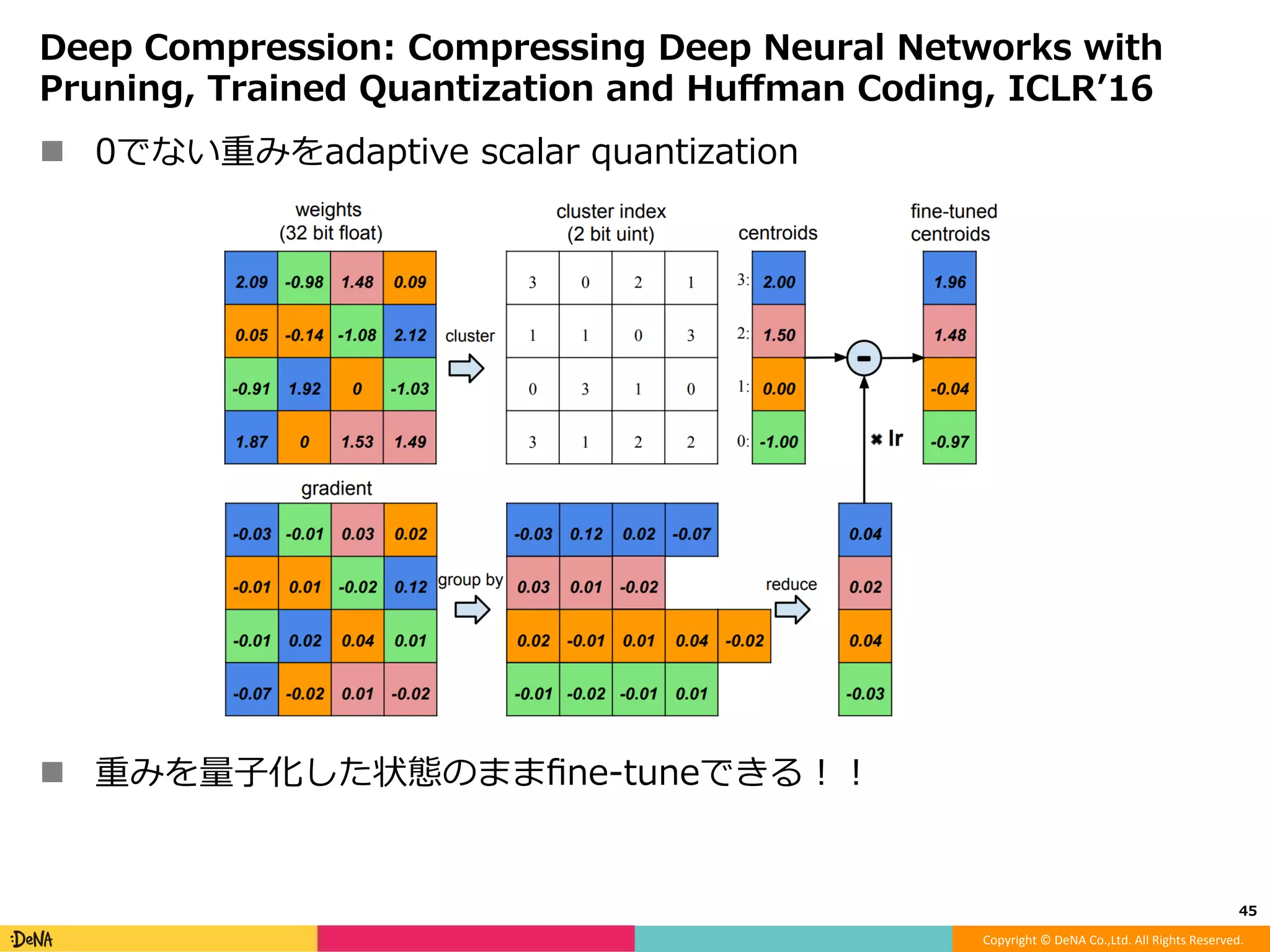
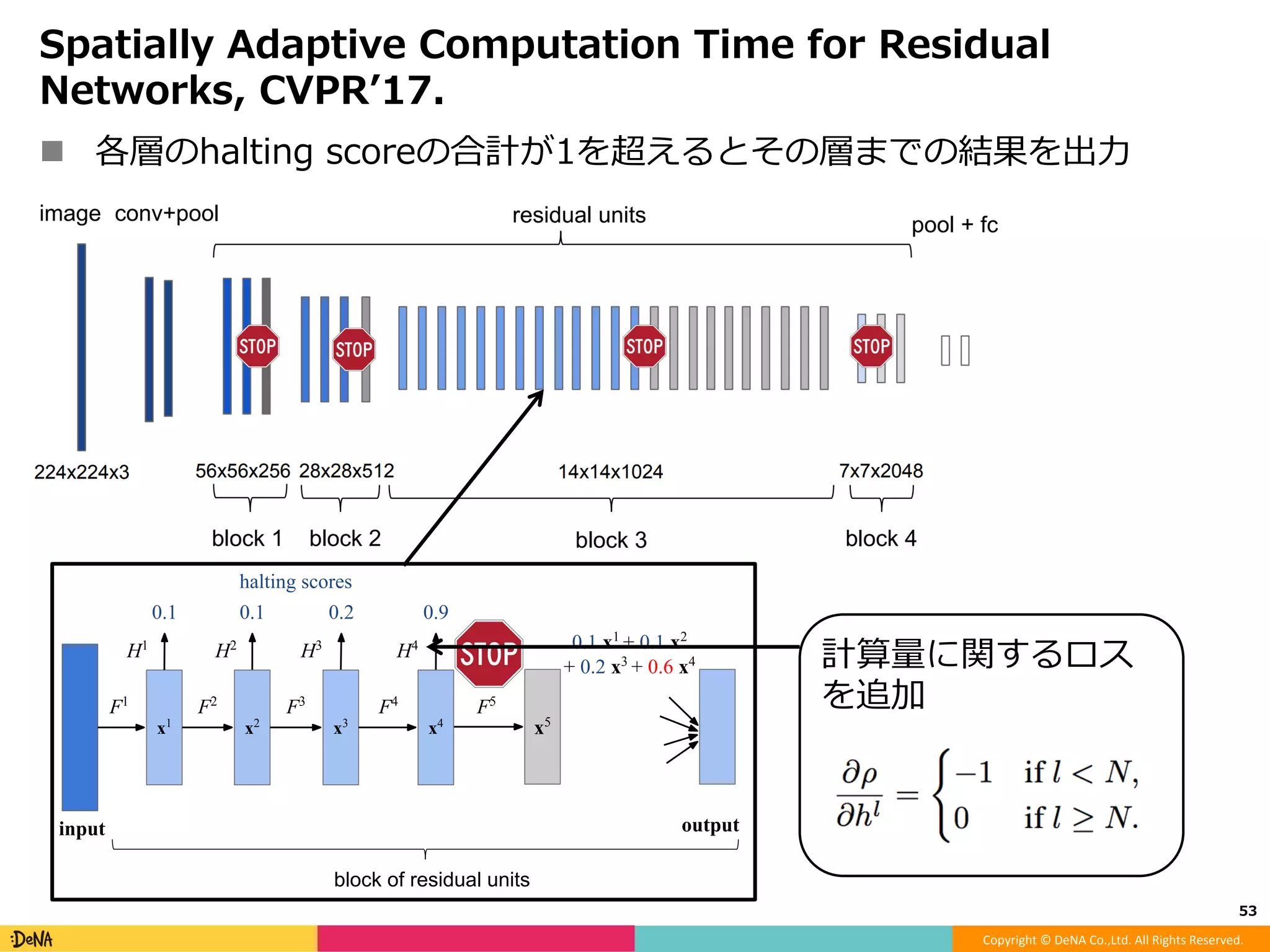
モデルアーキテクチャ観点からのDeep Neural Network高速化 -Factorization -Efficient microarchitecture (module) -Pruning -Quantization -Distillation -Early termination




![Copyright © DeNA Co.,Ltd. All Rights Reserved.
Convolutionの計算量
6
W
H
W
H
N M
K
K
• ⼊⼒レイヤサイズ:H x W x N
• 畳み込みカーネル:K x K x N x M
[conv K x K, M]と表記 (e.g. [conv 3x3, 64])
• 出⼒レイヤサイズ:H x W x M
• 畳み込みの計算量:H・W・N・K2・M
※バイアス項無視、padding = “same”](https://image.slidesharecdn.com/random-170903035945/75/Deep-Neural-Network-6-2048.jpg)
![Copyright © DeNA Co.,Ltd. All Rights Reserved.
Convolutionの計算量
7
W
H
W
H
N M
K
K
• ⼊⼒レイヤサイズ:H x W x N
• 畳み込みカーネル:K x K x N x M
[conv K x K, M]と表記 (e.g. [conv 3x3, 64])
• 出⼒レイヤサイズ:H x W x M
• 畳み込みの計算量:H・W・N・K2・M
※バイアス項無視、padding = “same”
画像スケール、
チャネル数、
カーネルサイズの2乗に⽐例](https://image.slidesharecdn.com/random-170903035945/75/Deep-Neural-Network-7-2048.jpg)












































![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)














![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]YOLO9000: Better, Faster, Stronger](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20170804-170803075138-thumbnail.jpg?width=640&height=640&fit=bounds)























![[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190621dlhack-190621022108-thumbnail.jpg?width=640&height=640&fit=bounds)


































