Download as PDF, PPTX


![TokyoTech
TokyoTech
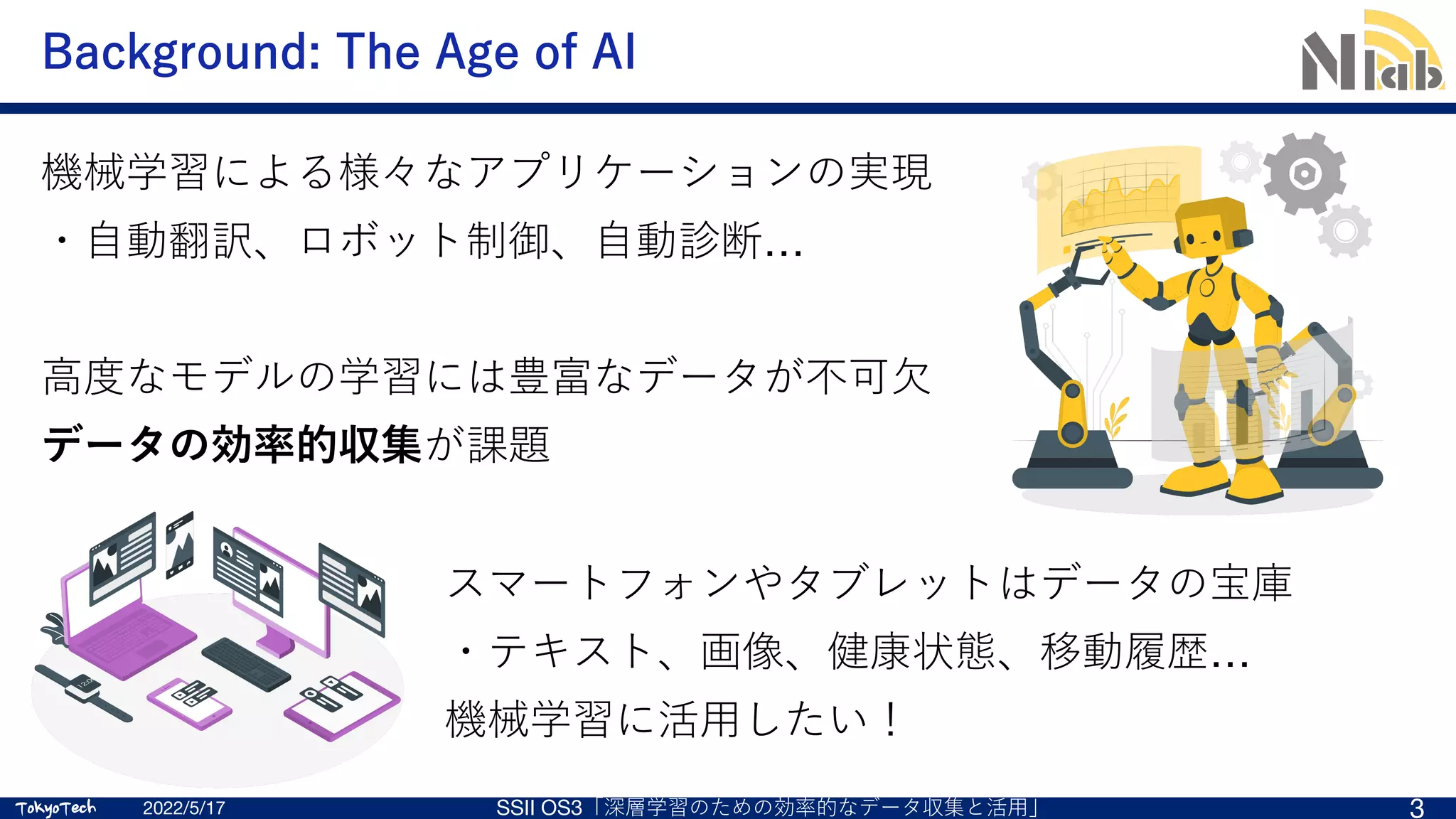
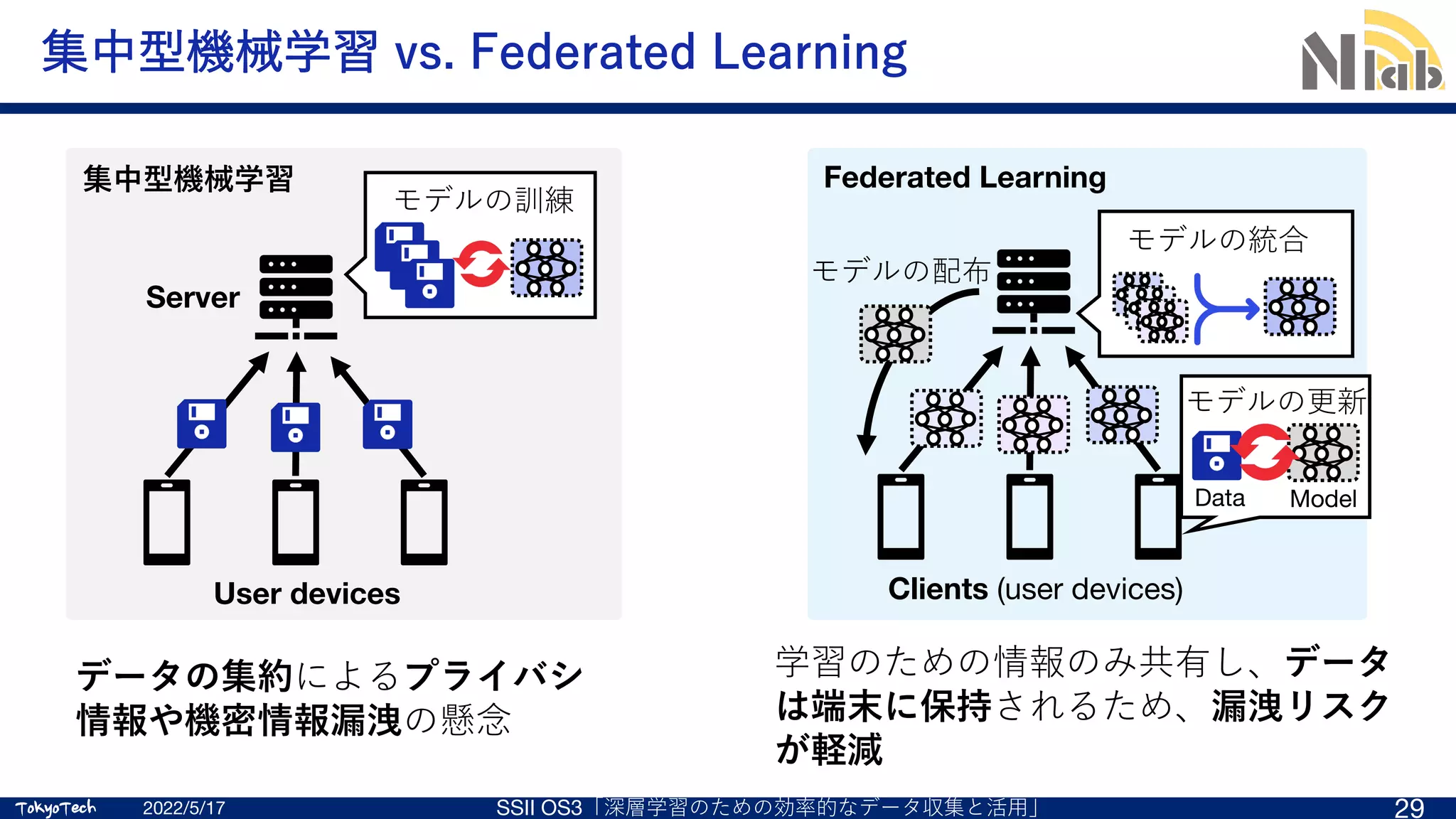
機械学習のためにデータを収集したいが…
データの集約にはリスクが伴う
•データの漏洩
•プライバシ情報の流出
⼼理的障壁
•データを提供するのはなんとなく嫌
2022/5/17 SSII OS3「深層学習のための効率的なデータ収集と活⽤」 4
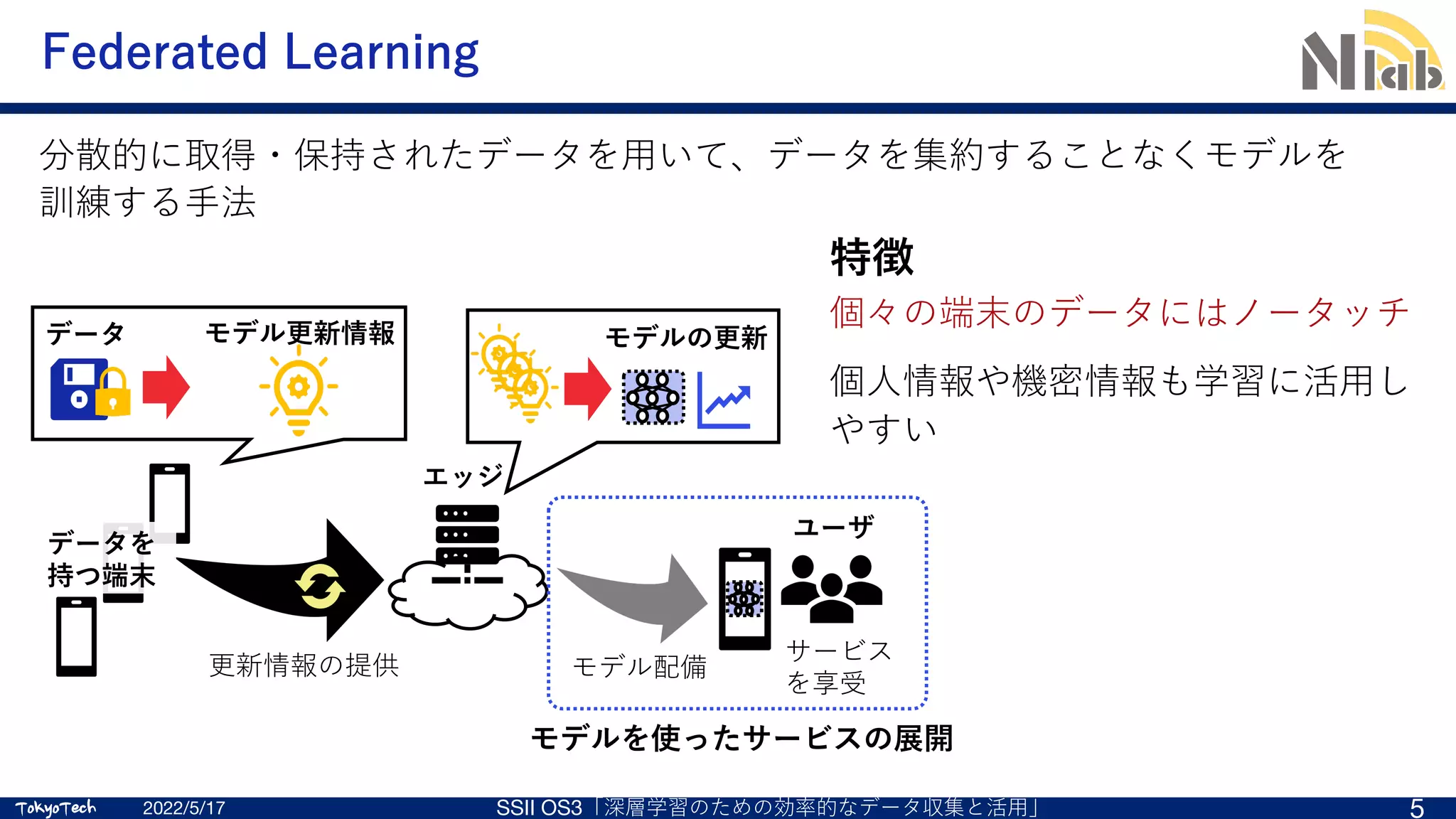
Federated Learning (FL, 連合機械学習)[1]
[1] B. McMahan, et al.,“Communication-efficient learning of deep networks from decentralized data,” Proc. AISTATS, pp. 1273–1282, Apr. 2017.
Server
盗聴
クラッキング
個⼈の特定
Motivation: データを集約せずに学習に活⽤したい!](https://image.slidesharecdn.com/ssii2022-os3-02-220607020834-2b5f93ff/75/SSII2022-OS3-02-Federated-Learning-4-2048.jpg)
![TokyoTech
TokyoTech
Applications: Emoji prediction from Google [4]
2022/5/17 T5: Part1 8
[4] Ramaswamy, et al., “Federated Learning for Emoji
Prediction in a Mobile Keyboard,” arXiv:1906.04329.
ML model predicts a Emoji based on the context.
The model trained via FL achieved better prediction accuracy (+7%).](https://image.slidesharecdn.com/ssii2022-os3-02-220607020834-2b5f93ff/75/SSII2022-OS3-02-Federated-Learning-7-2048.jpg)
![TokyoTech
TokyoTech
Applications: Oxygen needs prediction from NVIDIA [6]
[6] https://blogs.nvidia.com/blog/2020/10/05/federated-learning-covid-oxygen-needs/
2022/5/17 T5: Part1 9
Using NVIDIA Clara Federated Learning Framework,
researchers at individual hospitals were able to
use a chest X-ray, patient vitals and lab values to
train a local model and share only a subset of model
weights back with the global model in a privacy-
preserving technique called federated learning.](https://image.slidesharecdn.com/ssii2022-os3-02-220607020834-2b5f93ff/75/SSII2022-OS3-02-Federated-Learning-8-2048.jpg)



![TokyoTech
TokyoTech
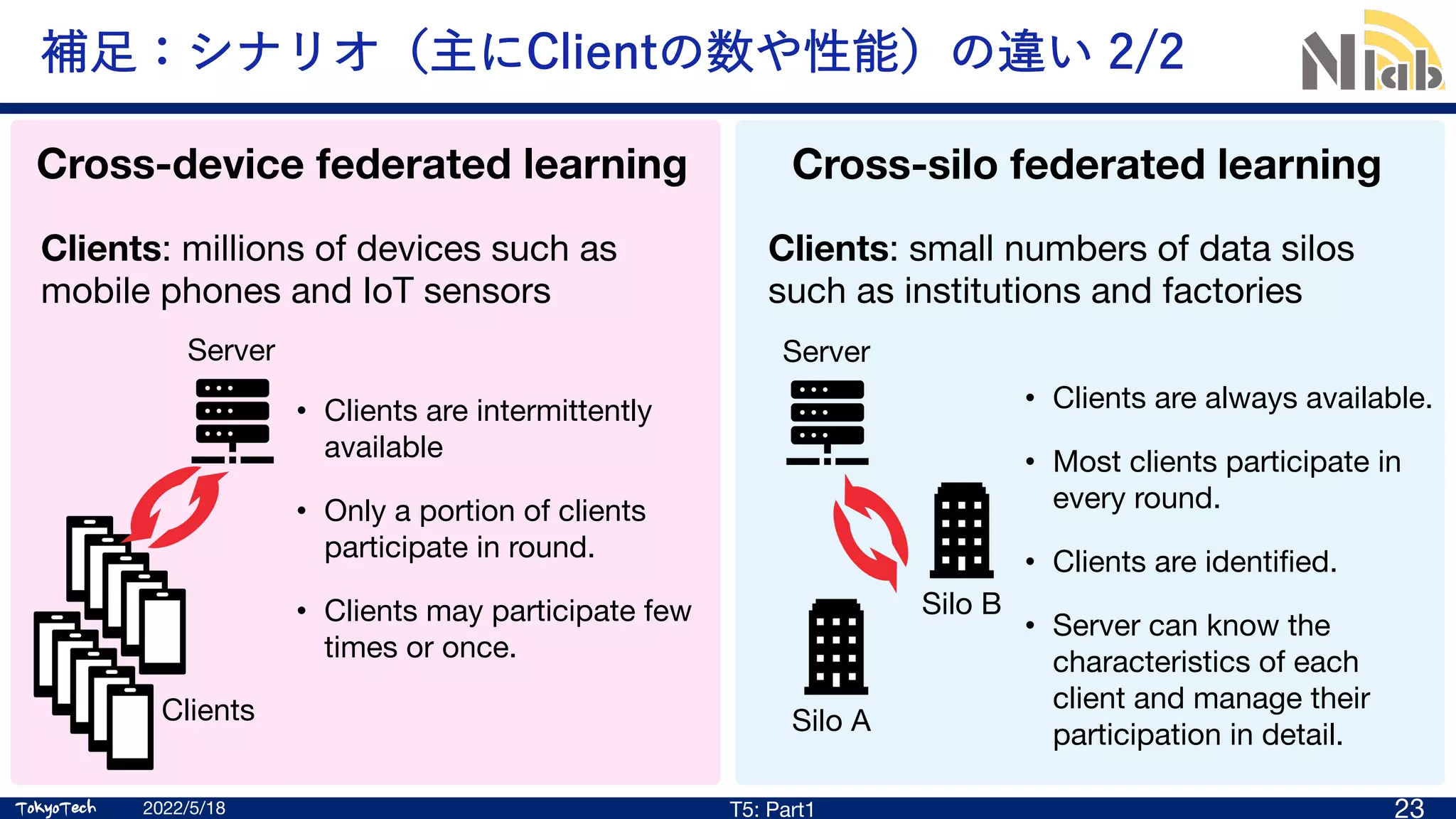
補⾜:シナリオ(主にClientの数や性能)の違い 1/2
2022/5/18 T5: Part1 22
Cross-silo federated learning
Cross-device federated learning
Clients: millions of devices such as
mobile phones and IoT sensors
Clients: small numbers of data silos
such as institutions and factories
Server
Use cases
• Keyboard next-word
prediction [3]
• Emoji prediction [4]
• Speaker recognition [5]
Client: Millions of smart phone
Server
Use case
Oxygen need prediction [6]
Client: 20 hospitals
Silo A
Silo B
Clients](https://image.slidesharecdn.com/ssii2022-os3-02-220607020834-2b5f93ff/75/SSII2022-OS3-02-Federated-Learning-13-2048.jpg)
![TokyoTech
TokyoTech
Federated Learningの具体的なアルゴリズム
2022/5/18 SSII OS3「深層学習のための効率的なデータ収集と活⽤」 24
Clients (user devices)
Model
Data
3. モデルの更新
5. モデルの統合
2. モデルの配布
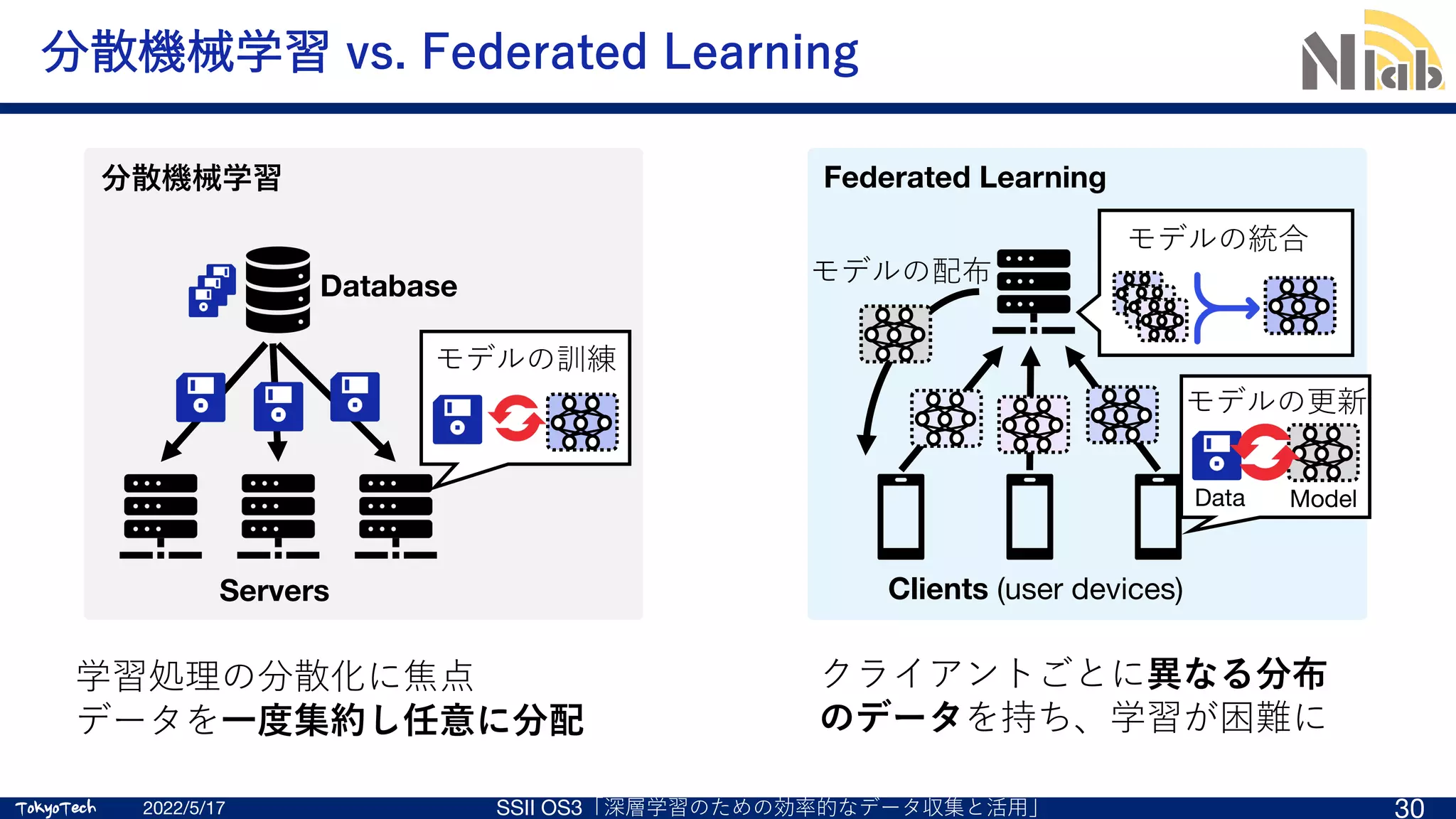
FedAvg (Federated Averaging) [1]
各Clientが訓練したモデルのパラメタ
を収集し、算術平均をとることで⼀つ
のモデルに統合し、学習する⽅式
• Server-Client間でやりとりするのは
モデルだけ
• データはそれを保持するClient⾃⾝
しか参照しない
[1] B. McMahan, et al.,“Communication-efficient learning of deep networks from decentralized data,” Proc. AISTATS, pp. 1273–1282, Apr. 2017.](https://image.slidesharecdn.com/ssii2022-os3-02-220607020834-2b5f93ff/75/SSII2022-OS3-02-Federated-Learning-15-2048.jpg)
![TokyoTech
TokyoTech
Federated Learningの具体的なアルゴリズム
1. Client selection: サーバはラウンド(⼀連
の更新⼿順)に参加するClientを選択
2. 選択されたClientにグローバルモデルを配布
3. Local update: Clientは⾃⾝の持つデータを
使って、配布されたモデルを更新する。更
新したモデルはローカルモデルと呼ぶ。
4. ローカルモデルのパラメタをサーバに共有
する
5. Model aggregation: 共有されたパラメタを
平均し、グローバルモデルとする
6. 1~5の⼿順を繰り返す
2022/5/18 SSII OS3「深層学習のための効率的なデータ収集と活⽤」 25
[1] B. McMahan, et al.,“Communication-efficient learning of deep networks from decentralized data,” Proc. AISTATS, pp. 1273–1282, Apr. 2017.
Clients (user devices)
Model
Data
3. モデルの更新
5. モデルの統合
2. モデルの配布](https://image.slidesharecdn.com/ssii2022-os3-02-220607020834-2b5f93ff/75/SSII2022-OS3-02-Federated-Learning-16-2048.jpg)

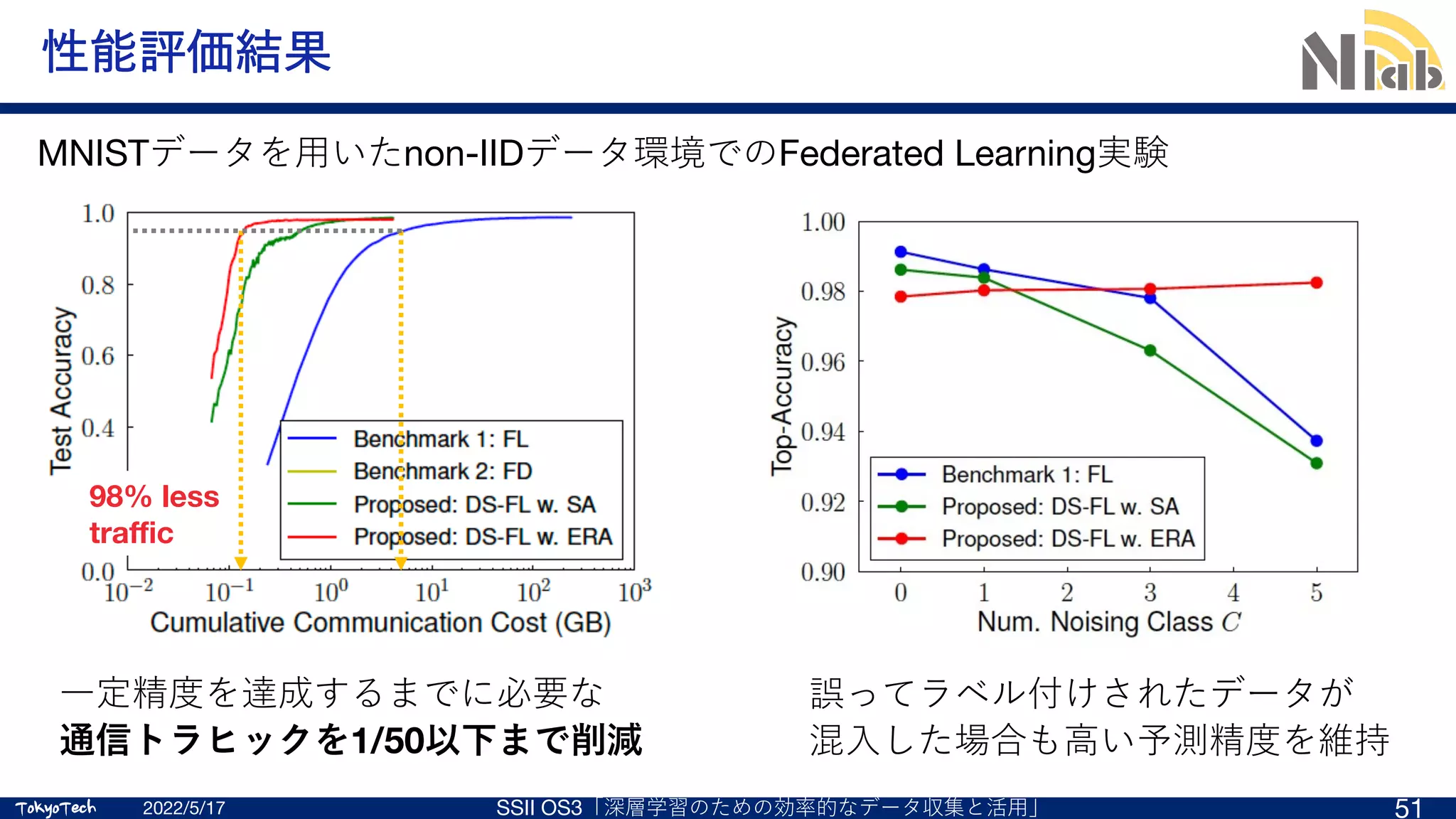
![TokyoTech
TokyoTech
性能評価 (Supplementary PDF of [B. McMahan, et al.,“Communication-efficient learning of deep networks from
decentralized data,” Proc. AISTATS, pp. 1273‒1282, Apr. 2017.])
2022/5/17 SSII OS3「深層学習のための効率的なデータ収集と活⽤」 28
CIFAR-10 (画像分類タスク)
ハイパーパラメータにもよるが、
データを集約した場合と同程度の
精度までモデルを訓練できている](https://image.slidesharecdn.com/ssii2022-os3-02-220607020834-2b5f93ff/75/SSII2022-OS3-02-Federated-Learning-18-2048.jpg)


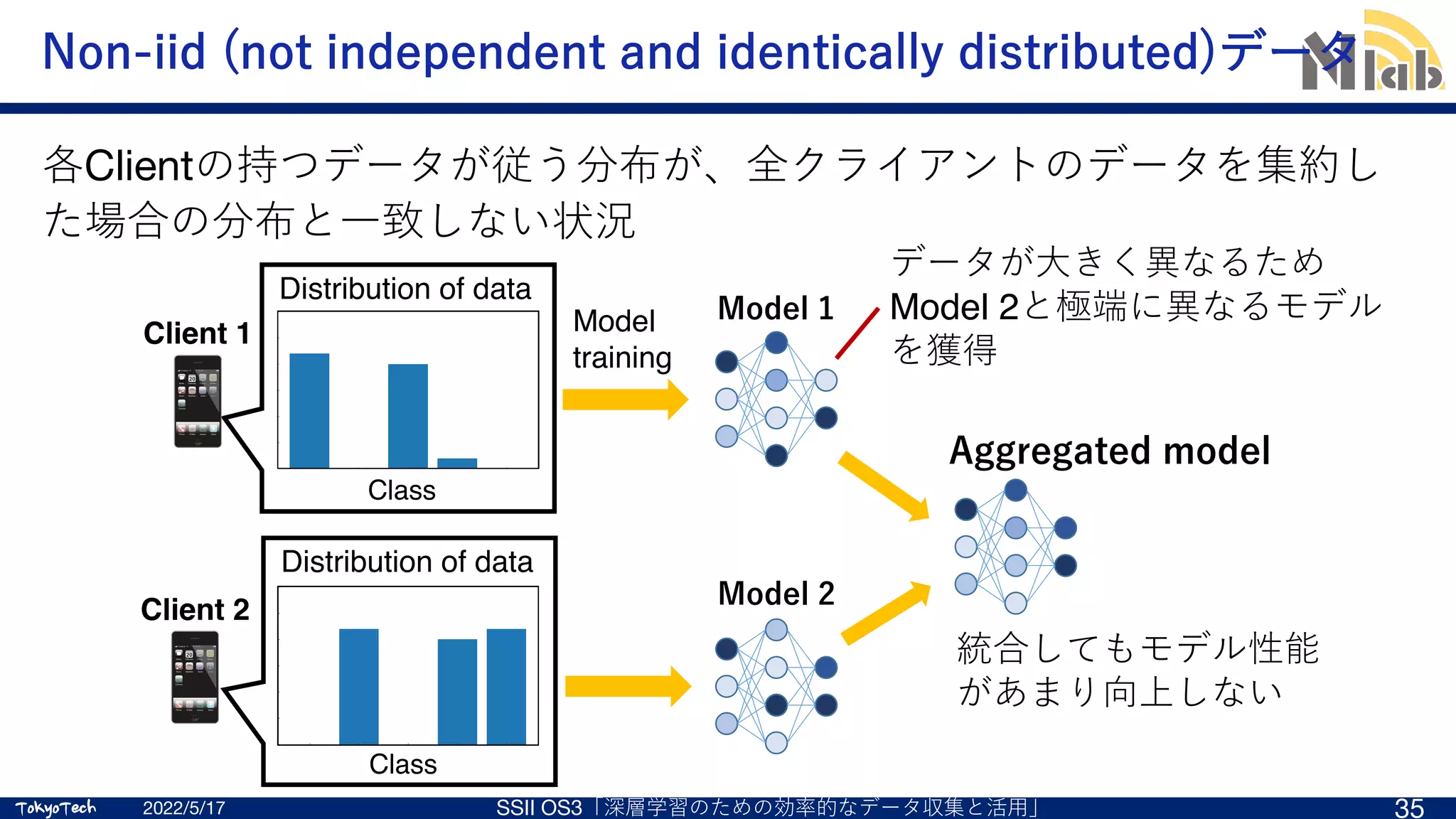
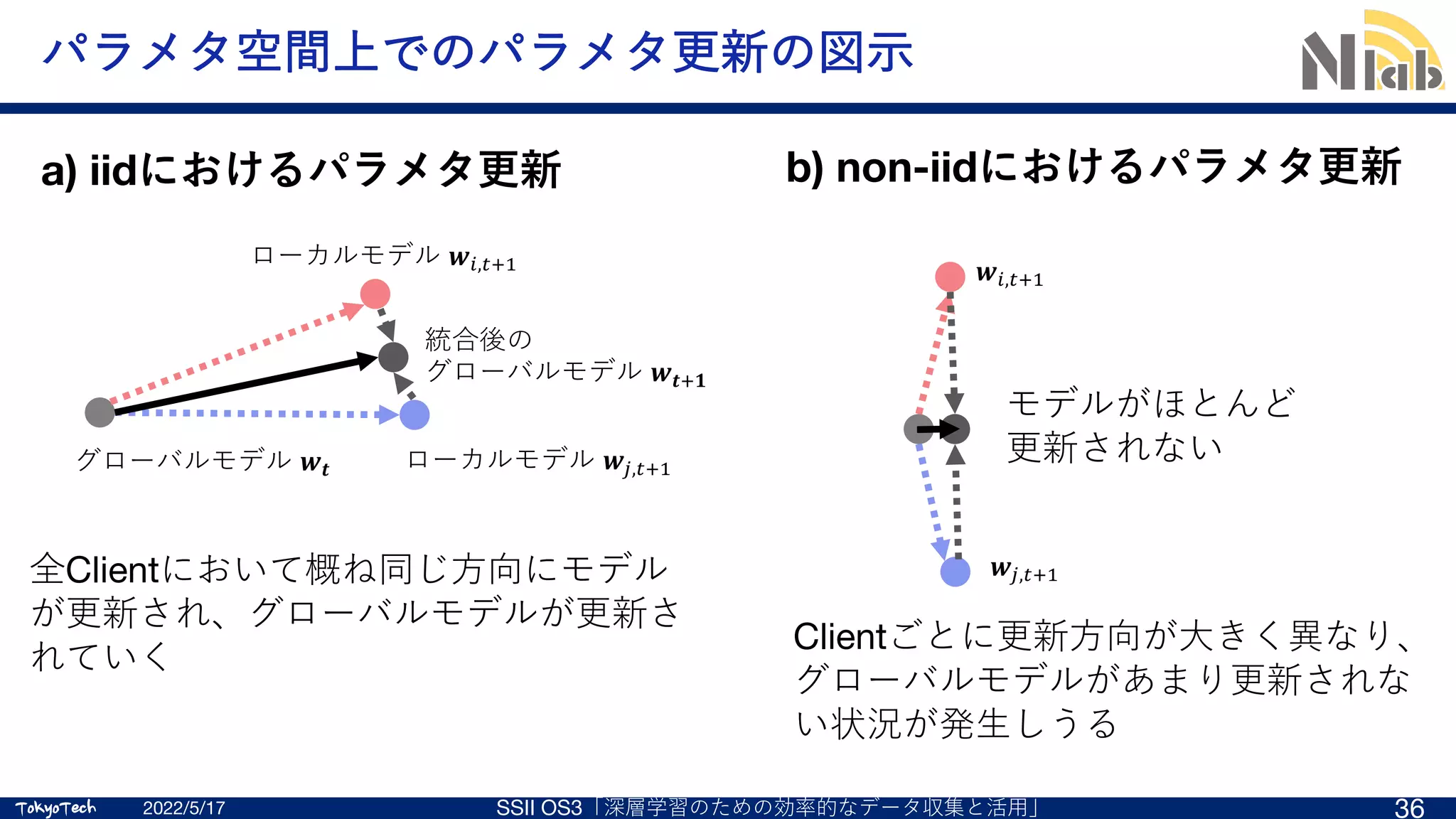

![TokyoTech
TokyoTech
Non-iidデータ 1/2
Local updateの改良
2022/5/17 SSII OS3「深層学習のための効率的なデータ収集と活⽤」 40
SCAFFOLD [N1]
グローバルモデルの更新⽅向を推定
し、その⽅向にローカルモデルが更
新されるよう補正を加える [N1] Karimireddy, Sai Praneeth, et al. "Scaffold: Stochastic
controlled averaging for federated learning." ICML 2020.
引⽤
[N2] Wang, Hao, et al. "Optimizing federated
learning on non-iid data with reinforcement
learning." IEEE INFOCOM, 2020.
Client selectionの改良
FAVOR [N2]
モデル性能の向上に寄与するClient
セット選択戦略を強化学習により学習
引⽤](https://image.slidesharecdn.com/ssii2022-os3-02-220607020834-2b5f93ff/75/SSII2022-OS3-02-Federated-Learning-28-2048.jpg)
![TokyoTech
TokyoTech
Non-iidデータ 2/2
2022/5/18 SSII OS3「深層学習のための効率的なデータ収集と活⽤」 41
Model aggregationの改良 [N4] H. Wu and P. Wang, “Fast-Convergent
Federated Learning With Adaptive Weighting,”
IEEE Transactions on Cognitive
Communications and Networking, vol. 7, no. 4,
pp. 1078-1088, Dec. 2021.
FedAdp [N4]
Clientの学習への貢献(更新時の勾配をもと
に算出)をもとにAggregation時の重みを調整
少量のIIDデータの活⽤
[N3] N. Yoshida, T. Nishio, et al., "Hybrid-FL for Wireless Networks:
Cooperative Learning Mechanism Using Non-IID Data," IEEE ICC 2020.
Hybrid FL [N3]
極少数 (~1%)のClientはデータのアップロードを許可
アップロードデータでサーバ側にIIDデータセットを
構築し、モデル更新に活⽤
2 4 6 8 10
Mode of r, µ
0.0
0.2
0.4
0.6
0.8
1.0
Accuracy
(a) CIFAR-10.
Centralized model training FedCS
IID
non-IID
2 4 6 8 10
Mode of r, µ
0.0
0.2
0.4
0.6
0.8
1.0
Accuracy
(a) CIFAR-10.
Centralized model training FedCS Hybrid-FL (maxThroughput/minCV)
2 4 6
Mode of r, µ
0.0
0.2
0.4
0.6
0.8
1.0
Accuracy
(b) Fashion MNIST.](https://image.slidesharecdn.com/ssii2022-os3-02-220607020834-2b5f93ff/75/SSII2022-OS3-02-Federated-Learning-29-2048.jpg)
![TokyoTech
TokyoTech
Non-iidデータ 2/2
少量のIIDデータの活⽤
2022/5/17 SSII OS3「深層学習のための効率的なデータ収集と活⽤」 42
[N3] N. Yoshida, T. Nishio, et al., "Hybrid-FL for Wireless Networks:
Cooperative Learning Mechanism Using Non-IID Data," IEEE ICC 2020.
Hybrid FL [N3]
極少数 (~1%)のClientはデータのアップロードを許可
アップロードデータでサーバ側にIIDデータセットを構築し、モデル更新に活⽤
2 4 6 8 10
Mode of r, µ
0.0
0.2
0.4
0.6
0.8
1.0
Accuracy
(a) CIFAR-10.
Centralized model training FedCS Hybrid-FL (maxThroughput/minCV)
2 4 6 8 10
Mode of r, µ
0.0
0.2
0.4
0.6
0.8
1.0
Accuracy
(b) Fashion MNIST.
IID
non-IID IID
non-IID](https://image.slidesharecdn.com/ssii2022-os3-02-220607020834-2b5f93ff/75/SSII2022-OS3-02-Federated-Learning-30-2048.jpg)
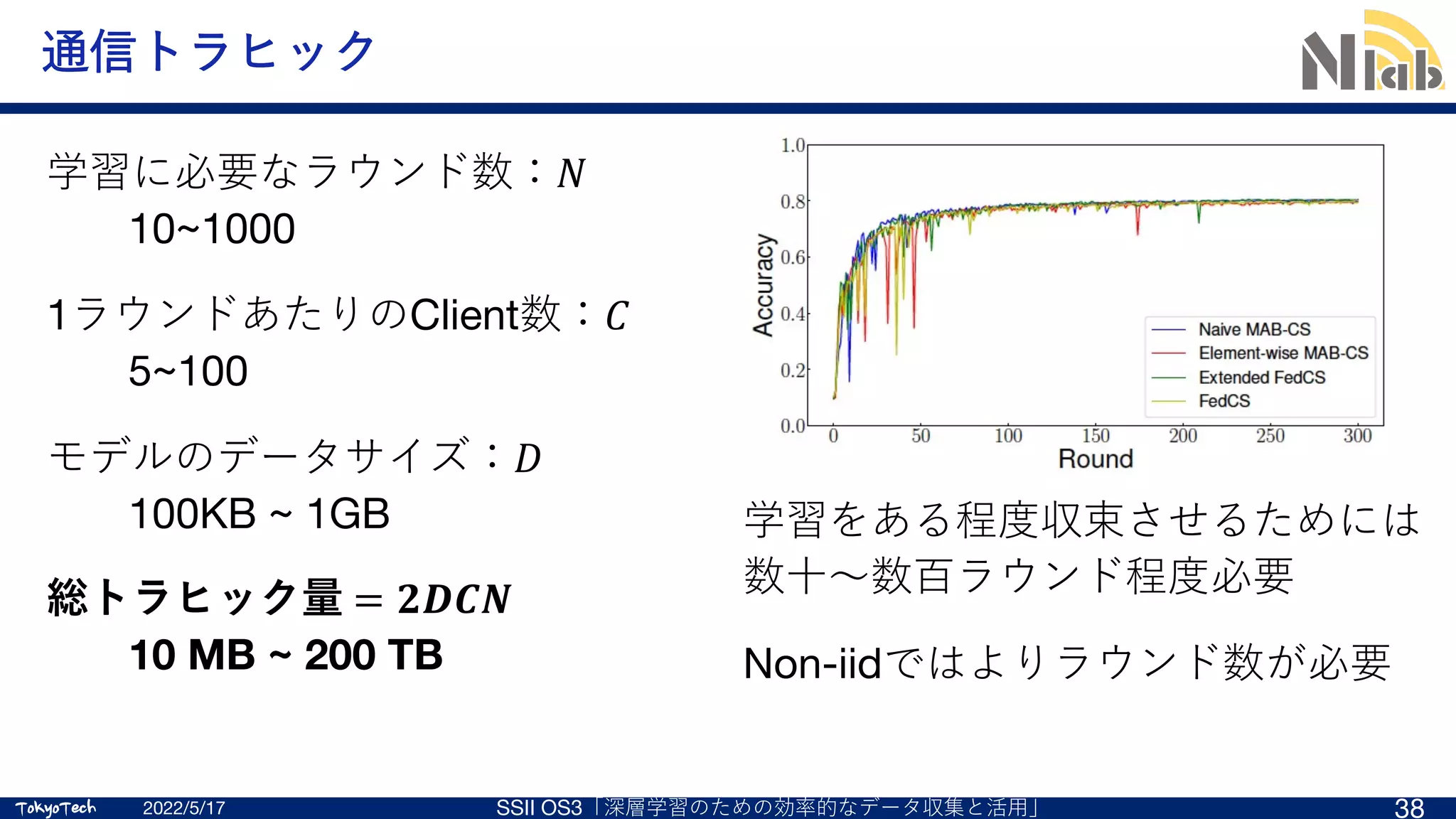
![TokyoTech
TokyoTech
通信トラヒック削減
モデルの圧縮
巨⼤なニューラルネットワークに対し、
パラメタの量⼦化、枝刈り、パラメタの少ないモデルに
置き換え等を⾏い、モデルのデータサイズを⼩さくする。
2022/5/17 SSII OS3「深層学習のための効率的なデータ収集と活⽤」 43
空中計算
1
3
3+1=4
空中計算
データをアナログ振幅変調し、多数のClientが同時送信するこ
とで、電波の重畳現象により受信振幅値から総和を求める⼿法
モデル統合に応⽤することで、送信局の数が⾮常に多い場合に
チャネル専有時間が削減される
スパース化
モデルを共有しない学習⽅法: Distillation-based Federated Learning
[C2] K. Yang et al., "Federated learning via over-the-air computation."
IEEE Trans. Wireless Commun. 2020.
[C1] F. Haddadpour, et al., "Federated learning with compression: Unified
analysis and sharp guarantees." AISTATS 2021.](https://image.slidesharecdn.com/ssii2022-os3-02-220607020834-2b5f93ff/75/SSII2022-OS3-02-Federated-Learning-31-2048.jpg)
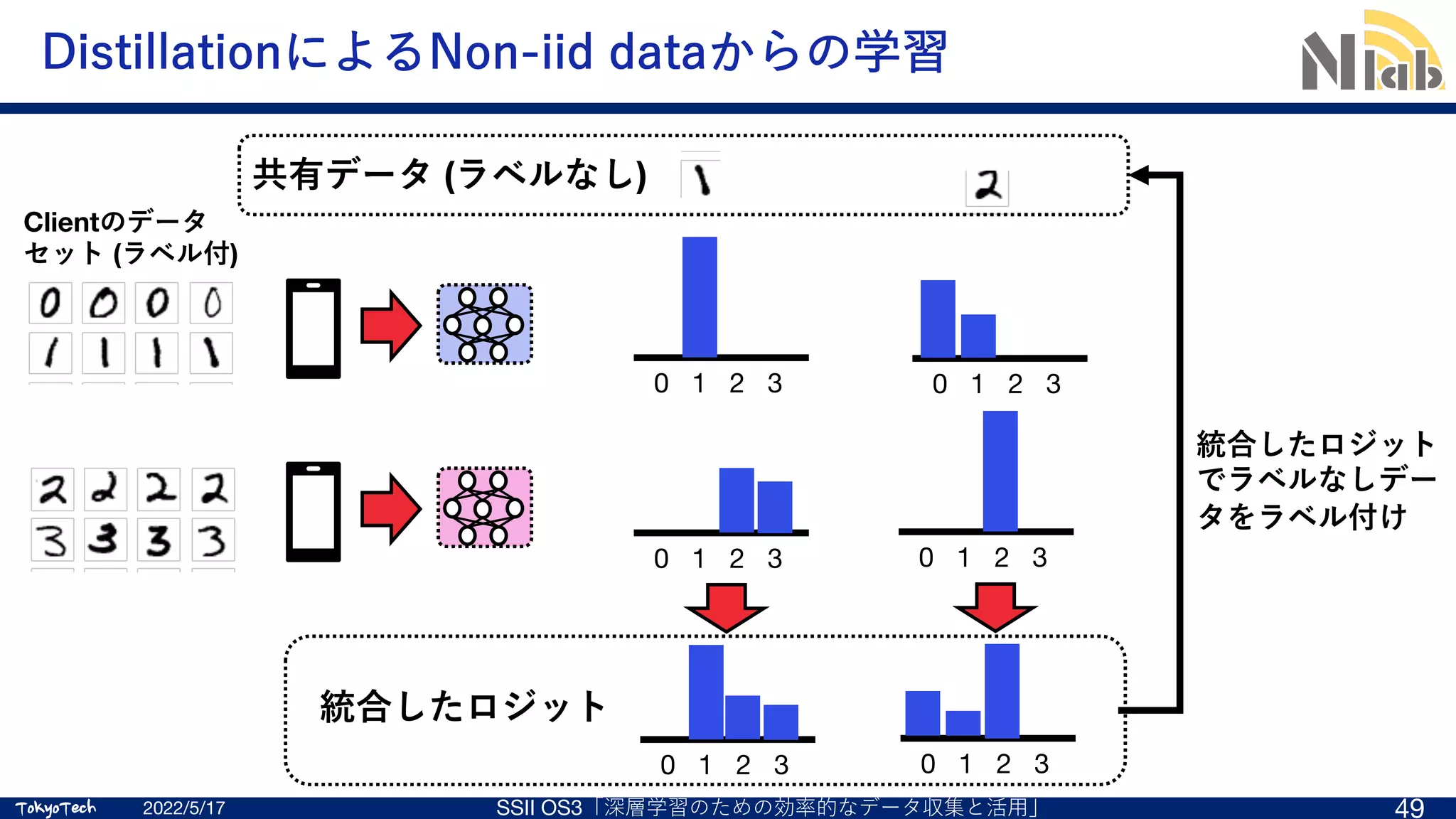
![TokyoTech
TokyoTech
Distillation based Semi-Supervised Federated Learning (DS-FL) [A]
[A] S. Itahara, T. Nishio, et al.,, “Distillation-Based Semi-Supervised Federated Learning for Communication-Efficient Collaborative Training with Non-IID Private Data,”
IEEE Trans. Mobile Compt.
2022/5/17 SSII OS3「深層学習のための効率的なデータ収集と活⽤」 44
Distillation (蒸留)
モデルの出⼒であるロジットを⽤いた学習⽅式
モデルの代わりにサイズの⼩さいロジットを⽤いることでトラヒック
を⼤幅に削減
Semi-supervised learning (半教師あり学習)
ラベル付きデータに加えて、ラベルなしデータも活⽤する機械学習
従来はモデルの汎化性能向上に⽤いられることが多い
本⽅式ではDistillationをFLに組み込むために活⽤
通信トラヒックを⼤幅削減可能(FedAvgの1/50)な学習⼿法](https://image.slidesharecdn.com/ssii2022-os3-02-220607020834-2b5f93ff/75/SSII2022-OS3-02-Federated-Learning-32-2048.jpg)
![TokyoTech
TokyoTech
DS-FLと従来⼿法(FedAvg)の⽐較
[A] S. Itahara, T. Nishio, et al.,, “Distillation-Based Semi-Supervised Federated Learning for Communication-Efficient Collaborative Training with Non-IID Private Data,” IEEE Trans. Mobile Compt.
2022/5/17 SSII OS3「深層学習のための効率的なデータ収集と活⽤」 46
データサイズの⼤きいモデルを何度も
共有するため⼤きなトラヒックが発⽣
Clients (user devices)
Model
Data
モデルの更新
出⼒統合とモデル訓練
Model Logit
モデルの出⼒
提案⼿法
Clients (user devices)
Model
Data
モデルの更新
モデルの統合
モデルの配布
従来のFL
モデルの出⼒情報を⽤いて学習するこ
とで学習時のトラヒックを⼤幅に削減](https://image.slidesharecdn.com/ssii2022-os3-02-220607020834-2b5f93ff/75/SSII2022-OS3-02-Federated-Learning-33-2048.jpg)



SSII2022 [OS3-02] Federated Learningの基礎と応用 6月10日 (金) 11:00 - 12:30 メイン会場 登壇者:西尾 理志 氏(東京工業大学) 概要:Federated Learning (FL)とは、分散して保持されたデータを収集・集約することなく機械学習モデルの訓練に用いる方法である。画像や音声、ヘルスケア情報など個人情報や機密情報の保護の観点から集約が難しいデータを機械学習へ活用できるという期待から、学術および産業の両面から注目を集めている。本講演では、FLの原理と応用例、FLの課題解決に向けた近年の取り組みについて解説する。



![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2021 [OS2-03] 自己教師あり学習における対照学習の基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/os2-04-210605061641-thumbnail.jpg?width=640&height=640&fit=bounds)







![SSII2022 [OS1-01] AI時代のチームビルディング](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os1-01-220607015404-49188612-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ICML2019読み会in京都] (LT)Bayesian Nonparametric Federated Learning of Neural Net...](https://cdn.slidesharecdn.com/ss_thumbnails/roadrollerbayesiannonparametricfederatedlearningofneuralnetworks-190804070640-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]"Dynamical Isometry and a Mean Field Theory of CNNs: How to Train 10,0...](https://cdn.slidesharecdn.com/ss_thumbnails/wakasugi-180824003300-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS2] 自律移動ロボットのためのロボットビジョン〜 オープンソースの自動運転ソフトAutowareを解説 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2ssii2022r4-220607054405-1c6b5fc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-04] Human-in-the-Loop 機械学習](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-04-220607021031-e69700d5-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-03] スケーラブルなロボット学習システムに向けて](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-03-220607020929-1e2b15e8-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-01] 深層学習のための効率的なデータ収集と活用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-01-220607020740-e80781dc-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS2-01] イメージング最前線](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os2-1-220607020403-b550c379-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS2] Deepfake Generation and Detection – An Overview (ディープフェイクの生成と検出)](https://cdn.slidesharecdn.com/ss_thumbnails/ss2-01-210607043612-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS3] 機械学習のアノテーションにおける データ収集 〜 精度向上のための仕組み・倫理や社会性バイアス 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts3-01-210607043121-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~](https://cdn.slidesharecdn.com/ss_thumbnails/ts1-01-210607042113-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-03] 画像と点群を用いた、森林という広域空間のゾーニングと施業管理](https://cdn.slidesharecdn.com/ss_thumbnails/os3-04-210605062524-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-02] BIM/CIMにおいて安価に点群を取得する目的とその利活用](https://cdn.slidesharecdn.com/ss_thumbnails/os3-03-210605062350-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-01] 設備や環境の高品質計測点群取得と自動モデル化技術](https://cdn.slidesharecdn.com/ss_thumbnails/os3-02-210605062048-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3] 広域環境の3D計測と認識 ~ 人が活動する場のセンシングとモデル化 ~(オーガナイザーによる冒頭の導入)](https://cdn.slidesharecdn.com/ss_thumbnails/os3-01-210605061816-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS1-03] エネルギーの情報化:需要家主体の分散協調型電力マネージメント](https://cdn.slidesharecdn.com/ss_thumbnails/os1-04-210605055326-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS1-02] まち全体のインフラや人流をサステナブルに計測する](https://cdn.slidesharecdn.com/ss_thumbnails/os1-03-210605055213-thumbnail.jpg?width=640&height=640&fit=bounds)





