Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Tomohiro Motoda
2,566 views
三次元表現まとめ(深層学習を中心に)
最近の三次元表現やこれをニューラルネットワークのような深層学習モデルに入力,出力する際の工夫についてまとめています.気まぐれに一晩で作成したので,多少の粗さはお許しください.
Technology
◦
Related topics:
Neural Networks
•
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 38
2
/ 38
Most read
3
/ 38
4
/ 38
5
/ 38
6
/ 38
7
/ 38
8
/ 38
9
/ 38
10
/ 38
11
/ 38
12
/ 38
13
/ 38
14
/ 38
15
/ 38
16
/ 38
17
/ 38
18
/ 38
19
/ 38
20
/ 38
21
/ 38
22
/ 38
23
/ 38
24
/ 38
25
/ 38
26
/ 38
27
/ 38
28
/ 38
29
/ 38
30
/ 38
31
/ 38
32
/ 38
33
/ 38
34
/ 38
35
/ 38
36
/ 38
37
/ 38
38
/ 38
More Related Content
PDF
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
PPTX
SfM Learner系単眼深度推定手法について
by
Ryutaro Yamauchi
PPTX
[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...
by
Deep Learning JP
PDF
SSII2019企画: 点群深層学習の研究動向
by
SSII
PPTX
[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
by
Kento Doi
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
PDF
EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monoc...
by
Kazuyuki Miyazawa
PDF
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
by
Deep Learning JP
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
SfM Learner系単眼深度推定手法について
by
Ryutaro Yamauchi
[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...
by
Deep Learning JP
SSII2019企画: 点群深層学習の研究動向
by
SSII
[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
by
Kento Doi
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monoc...
by
Kazuyuki Miyazawa
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
by
Deep Learning JP
What's hot
PDF
Point net
by
Fujimoto Keisuke
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PDF
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
PPTX
【DL輪読会】EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Pointsfor...
by
Deep Learning JP
PDF
Transformer メタサーベイ
by
cvpaper. challenge
PDF
SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...
by
SSII
PDF
Lucas kanade法について
by
Hitoshi Nishimura
PDF
【メタサーベイ】Neural Fields
by
cvpaper. challenge
PDF
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
PDF
深層学習によるHuman Pose Estimationの基礎
by
Takumi Ohkuma
PDF
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
PDF
Optimizer入門&最新動向
by
Motokawa Tetsuya
PPTX
【DL輪読会】ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
by
Deep Learning JP
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PDF
【DL輪読会】Patches Are All You Need? (ConvMixer)
by
Deep Learning JP
PDF
【メタサーベイ】Vision and Language のトップ研究室/研究者
by
cvpaper. challenge
PDF
ORB-SLAMを動かしてみた
by
Takuya Minagawa
PDF
SSII2019TS: 実践カメラキャリブレーション ~カメラを用いた実世界計測の基礎と応用~
by
SSII
Point net
by
Fujimoto Keisuke
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
【DL輪読会】EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Pointsfor...
by
Deep Learning JP
Transformer メタサーベイ
by
cvpaper. challenge
SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...
by
SSII
Lucas kanade法について
by
Hitoshi Nishimura
【メタサーベイ】Neural Fields
by
cvpaper. challenge
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
深層学習によるHuman Pose Estimationの基礎
by
Takumi Ohkuma
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
Optimizer入門&最新動向
by
Motokawa Tetsuya
【DL輪読会】ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
by
Deep Learning JP
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
【DL輪読会】Patches Are All You Need? (ConvMixer)
by
Deep Learning JP
【メタサーベイ】Vision and Language のトップ研究室/研究者
by
cvpaper. challenge
ORB-SLAMを動かしてみた
by
Takuya Minagawa
SSII2019TS: 実践カメラキャリブレーション ~カメラを用いた実世界計測の基礎と応用~
by
SSII
Similar to 三次元表現まとめ(深層学習を中心に)
PDF
Learning Spatial Common Sense with Geometry-Aware Recurrent Networks
by
Kento Doi
PPTX
cvsaisentan20141004 kanezaki
by
kanejaki
PDF
これからのコンピュータビジョン技術 - cvpaper.challenge in PRMU Grand Challenge 2016 (PRMU研究会 2...
by
cvpaper. challenge
PDF
【CVPR 2020 メタサーベイ】3D From a Single Image and Shape-From-X
by
cvpaper. challenge
PDF
20190706cvpr2019_3d_shape_representation
by
Takuya Minagawa
PPTX
Soft Rasterizer: A Differentiable Renderer for Image-based 3D Reasoning
by
Kohei Nishimura
PDF
Neural scene representation and rendering の解説(第3回3D勉強会@関東)
by
Masaya Kaneko
PDF
FastDepth: Fast Monocular Depth Estimation on Embedded Systems
by
harmonylab
PDF
物体検知(Meta Study Group 発表資料)
by
cvpaper. challenge
PDF
[DL輪読会]Unsupervised Learning of 3D Structure from Images
by
Deep Learning JP
PPTX
[DL輪読会]Deep Face Recognition: A Survey
by
Deep Learning JP
PDF
object detection with lidar-camera fusion: survey
by
Takuya Minagawa
PPTX
20190831 3 d_inaba_final
by
DaikiInaba
PDF
【CVPR 2020 メタサーベイ】Neural Generative Models
by
cvpaper. challenge
PDF
20160525はじめてのコンピュータビジョン
by
Takuya Minagawa
PPTX
【DL輪読会】DiffRF: Rendering-guided 3D Radiance Field Diffusion [N. Muller+ CVPR2...
by
Deep Learning JP
PDF
object detection with lidar-camera fusion: survey (updated)
by
Takuya Minagawa
PDF
SLAMチュートリアル大会資料(ORB-SLAM)
by
Masaya Kaneko
PDF
【DL輪読会】Monocular real time volumetric performance capture
by
Deep Learning JP
PDF
[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...
by
Deep Learning JP
Learning Spatial Common Sense with Geometry-Aware Recurrent Networks
by
Kento Doi
cvsaisentan20141004 kanezaki
by
kanejaki
これからのコンピュータビジョン技術 - cvpaper.challenge in PRMU Grand Challenge 2016 (PRMU研究会 2...
by
cvpaper. challenge
【CVPR 2020 メタサーベイ】3D From a Single Image and Shape-From-X
by
cvpaper. challenge
20190706cvpr2019_3d_shape_representation
by
Takuya Minagawa
Soft Rasterizer: A Differentiable Renderer for Image-based 3D Reasoning
by
Kohei Nishimura
Neural scene representation and rendering の解説(第3回3D勉強会@関東)
by
Masaya Kaneko
FastDepth: Fast Monocular Depth Estimation on Embedded Systems
by
harmonylab
物体検知(Meta Study Group 発表資料)
by
cvpaper. challenge
[DL輪読会]Unsupervised Learning of 3D Structure from Images
by
Deep Learning JP
[DL輪読会]Deep Face Recognition: A Survey
by
Deep Learning JP
object detection with lidar-camera fusion: survey
by
Takuya Minagawa
20190831 3 d_inaba_final
by
DaikiInaba
【CVPR 2020 メタサーベイ】Neural Generative Models
by
cvpaper. challenge
20160525はじめてのコンピュータビジョン
by
Takuya Minagawa
【DL輪読会】DiffRF: Rendering-guided 3D Radiance Field Diffusion [N. Muller+ CVPR2...
by
Deep Learning JP
object detection with lidar-camera fusion: survey (updated)
by
Takuya Minagawa
SLAMチュートリアル大会資料(ORB-SLAM)
by
Masaya Kaneko
【DL輪読会】Monocular real time volumetric performance capture
by
Deep Learning JP
[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...
by
Deep Learning JP
三次元表現まとめ(深層学習を中心に)
1.
3D Representation 元田智大 1 ~One Night
Survey (2021/11/24)~ 深層学習を用いた方法を中心に紹介
2.
コンピュータビジョン 3D (現実)→投影→2D画像/3D画像 ● 三次元再構成 ●
ポーズ推定 ● 物体追跡(トラッキング) ● 領域分割(セグメンテーション) ● 物体検出 ● 行動推定 ● シーン認識 ● 顔認識 ● 画像修復 ● etc... 2 ● 画像センサ ● 2次元画像処理 ● 3次元画像処理 ● 認識・識別 ● 情報提示 主要な国際学会 ● CVPR ● ICCV ● ECCV ● NeurIPL (AI研究) ※旧 NIPS 著名だが,普段はこの手の論文は読まない(難しくて読めない) 研究分野(抜粋)
3.
【おまけ】観測技術について ● 画像処理(RGB,Gray Image) ●
ステレオ視 ○ カメラ2台以上 ○ カメラパラメータ,キャリブレーションの重要性. ● 三次元センサ ○ シフト処理 ○ ステレオカメラ方式 ○ ToF (IR) 方式 ● 三次元センサの汎用化 ○ Kinect (Microsoft)の登場 ○ Xtion (ASUS), Astra (Orbbec), realsense (Microsoft) etc. ● さらに超高性能センサが続々登場 ○ Ensense (iDS), PhoXi (Photoneo), Ycam3D (Yoods), realsense (Microsoft) ect. ○ Sony, Omrom, Denso, Canon, Keyence etc. ● (おまけ)センサフュージョン ○ Multi sensor fusion and integration (複数種類のセンサの協調) 3
4.
三次元表現(3D representation) ● 点群
(Point clouds) ○ メモリ効率▲,幾何変換◯,テクスチャ☓,制作コスト◎,深層学習▲,厳密さ◎ ● ボクセル (Voxel) ○ メモリ効率☓,幾何変換▲,テクスチャ▲,制作コスト◯,深層学習◎,厳密さ◯ ● メッシュ (Mesh) ○ メモリ効率◯,幾何変換◯,テクスチャ◯, 制作コスト☓,深層学習▲,厳密さ◯ ● 陰関数表現 (Implicit function),陰関数的な表現 ○ メモリ効率◎,幾何変換◯,テクスチャ☓,制作コスト☓,深層学習◯,厳密さ▲? ○ 例:SDFs (Signed Distance Fields) 4 古い? 流行? 人気 ● 点群は局所情報などの処理に弱い?ので深層学習が苦手.もちろん,メモリ効率も最悪. ● ボクセルは,深層学習にピッタリの性質を持っていて,粒度次第で綺麗に表現可能.幾何的に図形を変換することが苦手で, メモリ領域を専有するための効率は悪い. ● メッシュは,概ね最高の指標となりうるが,メッシュを貼るコストが大きい.そのため,当然深層学習との相性が悪い. ● 陰関数表現は,近年着目されるもので,メモリ効率と深層学習の相性から高精度化が可能.ただ,美しい3 D表現とは程遠い 上,深層学習以外の方法では,人間がパラメータを用意するのは至難の業.
5.
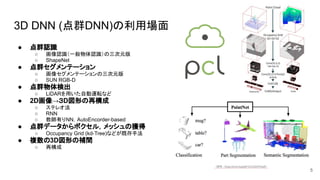
3D DNN (点群DNN)の利用場面 ●
点群認識 ○ 画像認識(一般物体認識)の三次元版 ○ ShapeNet ● 点群セグメンテーション ○ 画像セグメンテーションの三次元版 ○ SUN RGB-D ● 点群物体検出 ○ LiDARを用いた自動運転など ● 2D画像→3D図形の再構成 ○ ステレオ法 ○ RNN ○ 教師有りNN,AutoEncorder-based ● 点群データからボクセル,メッシュの獲得 ○ Occupancy Grid (kd-Tree)などが既存手法 ● 複数の3D図形の補間 ○ 再構成 5
6.
三次元物体認識/表現の分類(主にDNN) ● 2Dベースアプローチ ○ BEV ●
敵対生成モデルによる三次元図形の生成 ○ 3DGAN (NIPS2016), 3D-WIGAN ● 点群ベースアプローチ ○ PointNet, PointNet++,VoteNet ○ VoxelNet, PointPillar ○ ShapeNet (大規模CADデータ) ● 点群と2DベースNNのアプローチ ● ニューラルネットによる三次元表現 ○ IM-NET, DeepSDF, NeRF系統 6
7.
2Dベースアプローチ ● 例:3D YOLO
(ECCV workshop 2018), Complex YOLO (ECCV workshop 2018) ○ 点群からBird’s eye view (BEV)を生成←俯瞰視点の情報を含む ○ 既存の物体検出手法(YOLO, Faster-RCNN)に空間的な認識を追加. 7 読解不足
8.
敵対生成モデルによる三次元図形の生成(3DGAN系統) ● 3D-GAN,3D-VAE-GAN (NIPS2016) ○
確率空間から3Dオブジェクトの生成. ○ 敵対的学習による高精度化. ○ 低次元確率空間(ノイズパターン?)からマッピング可能. ○ 識別器は強力な「3D形状記述子」となる. ● その他(要調査) 8 勉強不足
9.
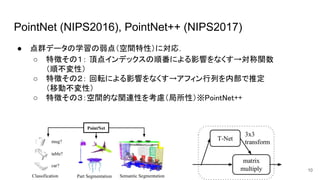
点群ベースアプローチ(PointNet系統) ● PointNet (NIPS
2016) ○ 点群に対し,全結合ネットワークを複数回通し,特徴量を抽出. ○ 最後にMaxPoolingを行い,点群全体特徴量を取得. ● PointNet++ (NIPS 2017) ○ 局所特徴が失われることへの課題の克服. ○ PointNetを階層化(?). ○ PointNetへの入力点群を事前にクラスタリングした近傍点にする.擬似的 に局所特徴の抽出を可能にした. ● VoteNet (ICCV 2019) ○ 物体の中央をHough-votingで中心点を予測→物体の検出. ● Fustrum PointNets (CVPR2017) ○ LiDARを用いたPointNet ○ R-CNN + PointNet <- 実装上の簡単さ 9 従来法はVoxel化による凹凸の 消滅が課題だった
10.
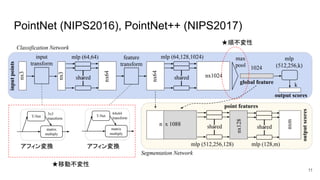
PointNet (NIPS2016), PointNet++
(NIPS2017) ● 点群データの学習の弱点(空間特性)に対応. ○ 特徴その1: 頂点インデックスの順番による影響をなくす→対称関数 (順不変性) ○ 特徴その2: 回転による影響をなくす→アフィン行列を内部で推定 (移動不変性) ○ 特徴その3:空間的な関連性を考慮(局所性)※PointNet++ 10
11.
PointNet (NIPS2016), PointNet++
(NIPS2017) 11 アフィン変換 アフィン変換 ★順不変性 ★移動不変性
12.
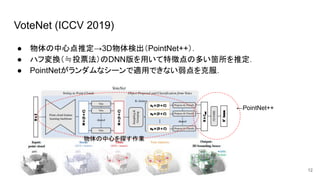
VoteNet (ICCV 2019) ●
物体の中心点推定→3D物体検出(PointNet++). ● ハフ変換(≒投票法)のDNN版を用いて特徴点の多い箇所を推定. ● PointNetがランダムなシーンで適用できない弱点を克服. 12 ←PointNet++ 物体の中心を探す作業
13.
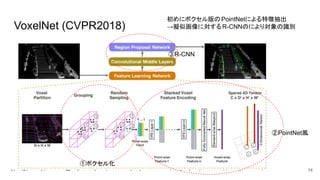
点群と2DベースNNのアプローチ ● VoxelNet (CVPR
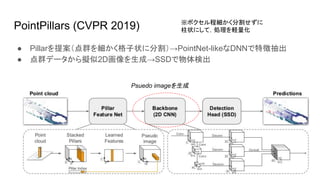
2018) ○ PointNet風のネットワーク(三次元情報のエンコード) →CNN(抽象的な情報から特徴抽出). ○ PointNet とCNNのいいとこ取り. ○ メモリ使用量が多いのが弱点. ● PointPillars (CVPR 2019) ○ 点群のみでは高精度ながら,低速. BEVなどでは,点群の細かい情報は消失. ○ エンコードネットワークによって点群情報を変換して擬似画像( Pseudo image)を生成. ○ 点群のエンコードのために, Pillarと呼ぶ格子状に点群を分割 →点群DNNで特徴量を抽出. 13 ※これらも結局PointNetにインスパイアされている.
14.
VoxelNet (CVPR2018) 14 ③R-CNN ①ボクセル化 ②PointNet風 初めにボクセル版の PointNetによる特徴抽出 →擬似画像に対するR-CNNのにより対象の識別
15.
PointPillars (CVPR 2019) ●
Pillarを提案(点群を細かく格子状に分割)→PointNet-likeなDNNで特徴抽出 ● 点群データから擬似2D画像を生成→SSDで物体検出 15 ※ボクセル程細かく分割せずに 柱状にして,処理を軽量化 Psuedo imageを生成
16.
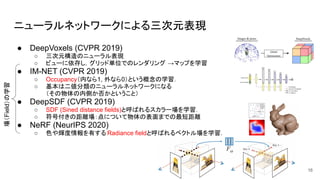
ニューラルネットワークによる三次元表現 ● DeepVoxels (CVPR
2019) ○ 三次元構造のニューラル表現 ○ ビューに依存し,グリッド単位でのレンダリング →マップを学習 ● IM-NET (CVPR 2019) ○ Occupancy(内なら1, 外なら0)という概念の学習. ○ 基本は二値分類のニューラルネットワークになる (その物体の内側か否かということ) ● DeepSDF (CVPR 2019) ○ SDF (Sined distance fields)と呼ばれるスカラー場を学習. ○ 符号付きの距離場:点について物体の表面までの最短距離 ● NeRF (NeurIPS 2020) ○ 色や輝度情報を有する Radiance fieldと呼ばれるベクトル場を学習. 16 場(Field)の学習
17.
陰関数(的な)表現 implicit representations ●
例:SDF (符号付き距離場)による三次元データの表現 17 もっと勉強が必要 参考:https://xtech.nikkei.com/atcl/nxt/mag/rob/18/00007/00025/ x^2 + y^2 - r^2 = 0 この流れを汲むNeRFはDQNやDCGANに次ぐブレイクスルーなるとかなりそうだとか ... 少ないパラメータで図形を表現するテクニック
18.
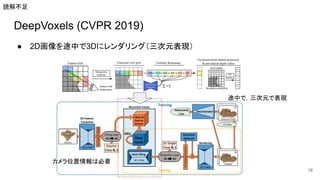
DeepVoxels (CVPR 2019) ●
2D画像を途中で3Dにレンダリング(三次元表現) 18 途中で,三次元で表現 カメラ位置情報は必要 読解不足
19.
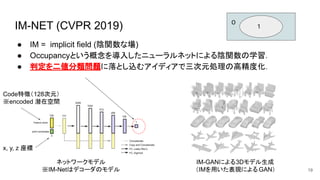
IM-NET (CVPR 2019) ●
IM = implicit field (陰関数な場) ● Occupancyという概念を導入したニューラルネットによる陰関数の学習. ● 判定を二値分類問題に落とし込むアイディアで三次元処理の高精度化. IM-GANによる3Dモデル生成 (IMを用いた表現による GAN) ネットワークモデル ※IM-Netはデコーダのモデル 1 0 19 Code特徴(128次元) ※encoded 潜在空間 x, y, z 座標
20.
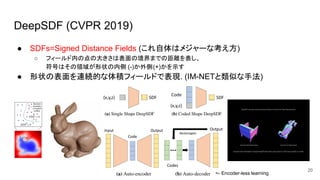
DeepSDF (CVPR 2019) ●
SDFs=Signed Distance Fields (これ自体はメジャーな考え方) ○ フィールド内の点の大きさは表面の境界までの距離を表し、 符号はその領域が形状の内側 (-)か外側(+)かを示す ● 形状の表面を連続的な体積フィールドで表現. (IM-NETと類似な手法) 20 <- Encoder-less learning
21.
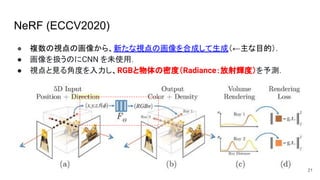
NeRF (ECCV2020) ● 複数の視点の画像から、新たな視点の画像を合成して生成(←主な目的). ●
画像を扱うのにCNN を未使用. ● 視点と見る角度を入力し、RGBと物体の密度(Radiance:放射輝度)を予測. 21
22.
NeRF (ECCV2020) 22
23.
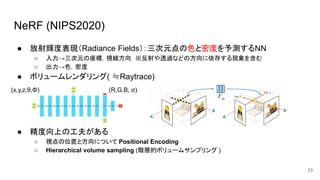
NeRF (NIPS2020) ● 放射輝度表現(Radiance
Fields):三次元点の色と密度を予測するNN ○ 入力→三次元の座標,視線方向 ※反射や透過などの方向に依存する現象を含む ○ 出力→色,密度 ● ボリュームレンダリング( ≒Raytrace) ● 精度向上の工夫がある ○ 視点の位置と方向について Positional Encoding ○ Hierarchical volume sampling (階層的ボリュームサンプリング ) 23 (x,y,z,θ,Φ) (R,G,B, σ)
24.
NeRFの欠点 NeRFは若干の弱点→派生手法が多数(多くの課題は解決されている) ● 動的なシーンの予測 ● カメラパラメータ (カメラの情報が重要,COLMAPと呼ばれるツールが必要) ●
同一環境下の条件(反射や透過などの条件) ● 学習データ量 ● 学習時間 ● 推論時間 ● その他(General Sceneには不向きなど...) 24 見解としては,このあたりが実用との壁が大きい …? 改善手法が多く提案されており,もうすぐ Robotics分野に殴りこんでくる? ※この辺は要考察.
25.
NeRF派生手法 ● NeRF in
the Wild (CVPR2021) ○ 雑多な画像を用いた NeRF ○ インターネット上の画像から復元 ● NeRF for video (CVPR2021) ● NeRF + GAN (2020, 2021) ● Dex-NeRF (CoRL2021) 25
26.
NeRF in the
Wild (NeRF-W) (CVPR 2021) ● 天候の変化やオクルージョンが発生している自然な写真の集合への工夫 ○ 天候などの照明変化を明示的にモデルに組み込む. (見かけの変化に関係する潜在変数の導入) ○ 通行人や車などの一時的に映っている物体も明示的に組み込み, レンダリング結果を分布として推定. (静的な部分と動的な部分に分類) ● General sceneへの復元を実現(?) ○ 建物限定?シーンの制限は? 26 読解不足
27.
NeRF for video
(CVPR2021) ● 単眼の動画から4Dのview synthesis ○ NeRFに時間方向の情報が追加されている ● Neural Scene Flow Fields (NSFF)により実現. ● これで動的なシーンへの対応. 27 Scene flow fields ● 輝度一貫性 ● サイクル一貫性 ● 幾何学整合性 読解不足 NNにて最適化 ※よくよく調べると NSFFの類似手法は死ぬほどあるよう オプティカルフローとほぼ同じ性質を考慮
28.
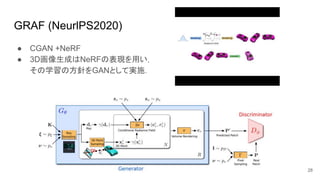
GRAF (NeurlPS2020) ● CGAN
+NeRF ● 3D画像生成はNeRFの表現を用い, その学習の方針をGANとして実施. 28
29.
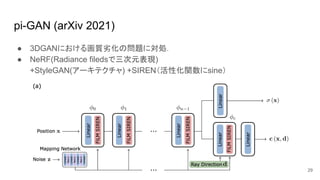
pi-GAN (arXiv 2021) ●
3DGANにおける画質劣化の問題に対処. ● NeRF(Radiance filedsで三次元表現) +StyleGAN(アーキテクチャ) +SIREN(活性化関数にsine) 29
30.
Dex-NeRF (CoRL2021) ● 透明物体の再構成に主眼を当てて,パラメータチューニングした手法. ●
オリジナルNeRFではσ(密度)> 0 →この研究では,鏡面反射特性と示す指標を学習していると捉 え,σ≦0を許容して学習する.※ ○ だから光源が多い方が鏡面反射が発生しやすく,レンダリング性能が上がる. 30 反射箇所は白とびし ているはず 【ポイント】オリジナル NeRFは暗にランバート反射が発 生しないことを仮定している.だから exp関数を用いて非 ゼロに数値を調整していた.
31.
まとめ ● 2016年以降の深層学習ベースの三次元認識,処理手法を確認. ● CV分野では,3Dを深層学習の問題に落とすアイディアが求められる. ●
近年,ニューラルネットワークを用いた三次元表現手法が紹介されている. ● NeRFとその派生手法はどうやらブームが来ている.(少なくとも2021年前半は) ● データ・セットの少なさが常の課題. ● CV分野の研究なので,画像認識や復元に主眼がある →応用分野での活用には(まだ)検証とさらなる派生手法が必要 ● (論文には書いていない難しさもあるだろう...) 31
32.
32 末尾
33.
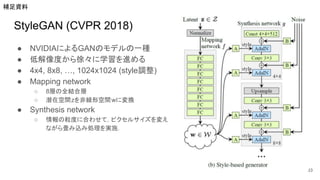
StyleGAN (CVPR 2018) ●
NVIDIAによるGANのモデルの一種 ● 低解像度から徐々に学習を進める ● 4x4, 8x8, …, 1024x1024 (style調整) ● Mapping network ○ 8層の全結合層 ○ 潜在空間zを非線形空間wに変換 ● Synthesis network ○ 情報の粒度に合わせて,ピクセルサイズを変え ながら畳み込み処理を実施. 33 補足資料
34.
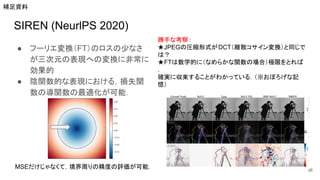
SIREN (NeurlPS 2020) ●
陰関数表現方法の一つ. ○ ● 画像,動画,音声などの自然信号を表現するネットワーク ○ 信号を詳細にモデル化するアーキテクチャが必要 →周期関数を活性化関数にするアイディア ● 活性化関数にsine関数(正弦関数)を利用. ○ 導関数が位相の違いで表現可能(例: sinの微分はpi/2のズレ) →損失関数において, 1次導関数による損失 も利用可能.またラプラシアンも OK. ○ 直感的に捉えると,ただのフーリエ変換のよう になる. ○ ただし,初期値の与え方が難しいらしい.(正負が周期的に来るので,誤差が伝播しやすい) ● 位置のエンコーディング→自然信号への射影 34 補足資料 こういうImplicit representationをMPLで行う方法
35.
SIREN (NeurlPS 2020) 35 補足資料
36.
SIREN (NeurlPS 2020) ●
フーリエ変換(FT)のロスの少なさ が三次元の表現への変換に非常に 効果的 ● 陰関数的な表現における,損失関 数の導関数の最適化が可能. 36 MSEだけじゃなくて,境界周りの精度の評価が可能. 勝手な考察: ★JPEGの圧縮形式がDCT(離散コサイン変換)と同じで は? ★FTは数学的に(なめらかな関数の場合)極限をとれば , 確実に収束することがわかっている.(※おぼろげな記 憶) 補足資料
37.
GANverse3D (ICLR2021) ● 平面的な画像から3Dモデルを生成 ●
開発者のカスタマイズで背景などをコントロール可能 ● これまでは学習データが3Dモデルに依存 ○ マルチビューの入手の観点から. ○ 実際の画像の方がいいに決まっている. ○ →GANのモデルに着目. ● GANを活用して,2D画像から3Dを生成. (そういうEncoderとも言える) 37 Nvidia、写真1枚を3Dモデルに変換する GANverse3D のデモを公開 | CGinterest
38.
NeuS (NeurIPS2021) ● NeRF+Implicit
Surface ● これまでの手法が,オクルージョンや薄い物体に弱い (←周囲環境に影響を受けるため,局所的な結果になる) ● 最近のNeRFと派生手法はvolume rendering を用いている. ○ ただし,高品質に表面の状況を学習することは難しい,の制約がある. ● ★SDFを用いた新しいvolume renderingを実現する. →引き起こされる誤差を考慮した定式化を提案. 38
Download


























![[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...](https://cdn.slidesharecdn.com/ss_thumbnails/181214dlpointnet-181214053349-thumbnail.jpg?width=640&height=640&fit=bounds)

![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[DL輪読会]Unsupervised Learning of 3D Structure from Images](https://cdn.slidesharecdn.com/ss_thumbnails/sugihara-161213071700-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Face Recognition: A Survey](https://cdn.slidesharecdn.com/ss_thumbnails/20181221-181221023935-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=640&height=640&fit=bounds)