輪読内容について
• Neural scenerepresentation and rendering
– S. M. Ali Eslami, Danilo J. Rezende, et al.
• Rezendeは,VAEやnormalizing flowを提案した人
• Deep Mind (Last authorはDemis Hassabis)
• Scienceに採録
• Generative Query Network(GQN)を提案した論文
– 本発表では,GQNの説明のために深層生成モデルの基礎から順番に話します.
– 合わせて,関連研究(全部DeepMind発)や世界モデルとの関連についても説明します.
• 本論文についての私見
– 確率モデル的には新しいことを提案しているわけではなく,従来の研究の応用.
– 学習できるアーキテクチャを提案した&実際に学習できることを示したことに意味があると考えていま
す.
– 世界モデルの研究的には非常に重要な論文で,今後こういう研究はどんどん増えていくのは確実(既
にDeepMindが量産している)
→どの部分が重要なのかをおさえることが大事 2
3.
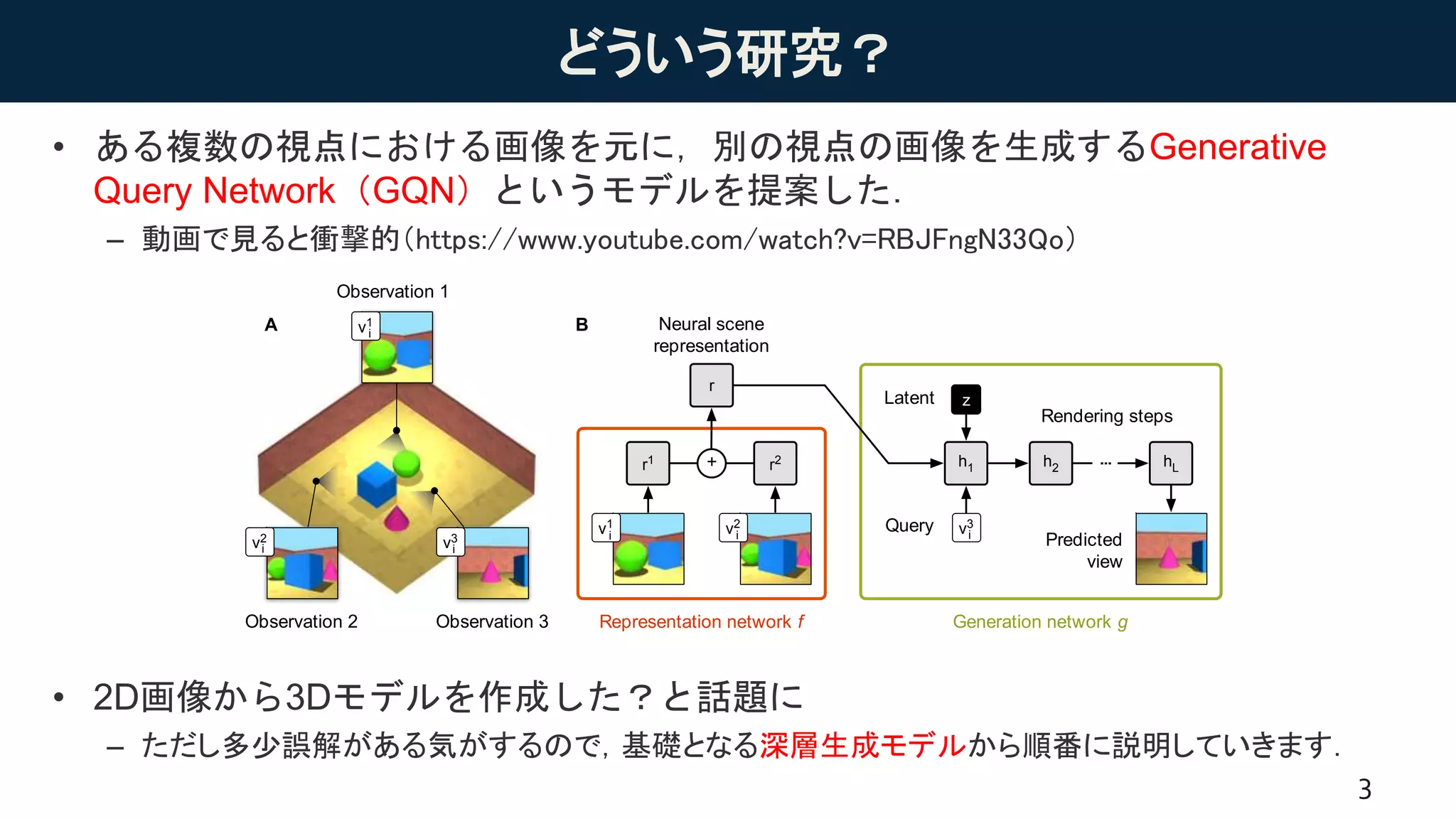
どういう研究?
• ある複数の視点における画像を元に,別の視点の画像を生成するGenerative
Query Network(GQN)というモデルを提案した.
–動画で見ると衝撃的(https://www.youtube.com/watch?v=RBJFngN33Qo)
• 2D画像から3Dモデルを作成した?と話題に
– ただし多少誤解がある気がするので,基礎となる深層生成モデルから順番に説明していきます.
3
Fig. 1. Schematic illustration of the Generative Query Network. (A) The agent observes
training scene ! from different viewpoints (in this example from &$
/
, &$
@
and &$
A
). (B) The inputs
to the representation network 2 are observations made from viewpoints &$
/
and &$
@
, and the
A B
r1 r2
r
h1 h2 hL
z
Generation network gRepresentation network f
···
v2 v3
v1
v2v1 v3
Neural scene
representation
Query
Latent
Rendering steps
Predicted
view
+
i
i i
i i i
Observation 1
Observation 3Observation 2
本論文の問題設定
• データセット:
– {(𝑥𝑖
𝑘
,𝑣𝑖
𝑘
)}(𝑖 ∈ 1, … , 𝑁 , 𝑘 ∈ {1, … , 𝐾})
• 𝑥𝑖
𝑘
はRGB画像
• 𝑣𝑖
𝑘
は視点(viewpoint)
– 𝑤(カメラの位置,3次元),𝑦(ヨー,1次元), 𝑝(ピッチ,1次元)
• 目的:
– M個の観測(文脈という)(𝑥𝑖
1,…,𝑀
, 𝑣𝑖
1,…,𝑀
)と任意の視点(クエリ)𝑣𝑖
𝑞
が与えられ
たもとで, 対応する𝑥𝑖
𝑞
を予測する.
– しかし,3次元空間を有限の2次元の観測で決定論的にカバーすることは困難
19
Fig. 1. Schematic illustration of the Ge
training scene ! from different viewpoin
to the representation network 2 are obse
output is the scene representation 4, whi
observations’ representations. The gener
representation to predict what the scene
generator can only succeed if 4 contains
A B
Repre
v2
v3
v1
v1
i
i i
i
Observation 1
Observation 3Observation 2
→条件付き確率モデル(深層生成モデル)を利用する
表現ネットワーク
• M個の観測(𝑥1,…,𝑀
, 𝑣1,…,𝑀
)を表現ネットワーク𝑓によって,一つの表現(文脈)r=
𝑓(𝑥1,…,𝑀
, 𝑣1,…,𝑀
)に要約する.
– 表現ネットワークのアーキテクチャは次のとおり
• 𝜓(𝑥, 𝑣)はCNNなど
• 各視点の平均(上式では総和)を取ることで,視点の順番に依存しない表現にす
ることができる.
– 順列ではなく組み合わせに対応した表現.
– 学習時に平均する視点の数をランダムに変更することで,任意の視点の数での推論が可能.
→(個人的に)GQN系のアーキテクチャで最も重要な部分
23
Fig. 1. Schematic illustration of the Generative Query Network. (A) Th
training scene ! from different viewpoints (in this example from &$
/
, &$
@
and
to the representation network 2 are observations made from viewpoints &$
/
output is the scene representation 4, which is obtained by element-wise sum
observations’ representations. The generation network, a recurrent latent va
representation to predict what the scene would look like from a different vi
A B
r1
r2
r
h1
z
GeneRepresentation network f
v2
v3
v1
v2v1 v3
Neural scene
representation
Query
Latent
+
i
i i
i i i
Observation 1
Observation 3Observation 2
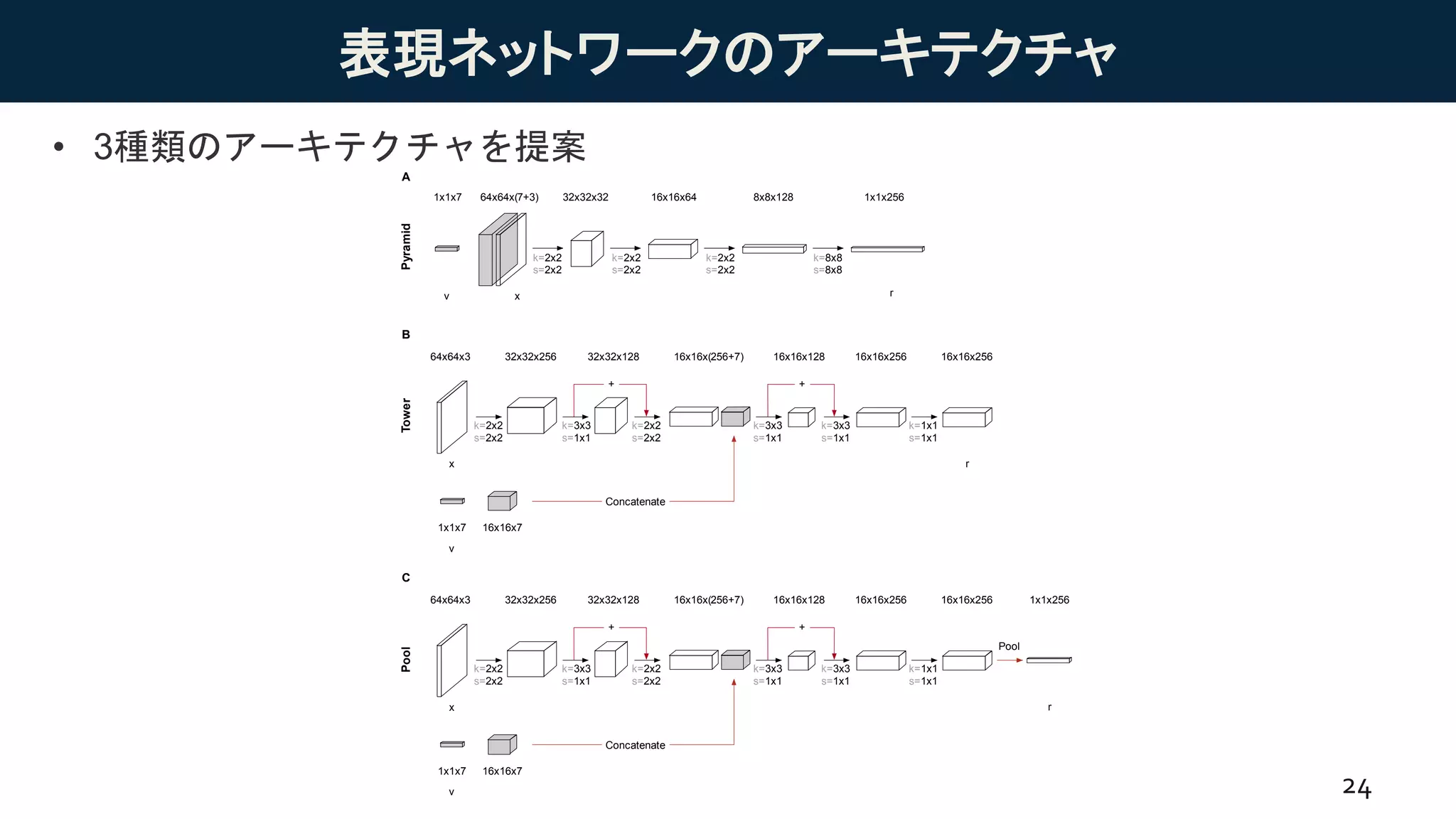
24.
表現ネットワークのアーキテクチャ
• 3種類のアーキテクチャを提案
24
64x64x(7+3)
v x
32x32x3216x16x64 8x8x128 1x1x256
k=2x2
s=2x2
k=2x2
s=2x2
k=2x2
s=2x2
k=8x8
s=8x8
r
1x1x7
64x64x3
v
x
32x32x256 32x32x128 16x16x(256+7) 16x16x128
k=2x2
s=2x2
k=3x3
s=1x1
k=2x2
s=2x2
k=3x3
s=1x1
r
1x1x7
k=3x3
s=1x1
k=1x1
s=1x1
16x16x256 16x16x256
Concatenate
+
16x16x7
+
A
B
64x64x3
v
x
32x32x256 32x32x128 16x16x(256+7) 16x16x128
k=2x2
s=2x2
k=3x3
s=1x1
k=2x2
s=2x2
k=3x3
s=1x1
r
1x1x7
k=3x3
s=1x1
k=1x1
s=1x1
16x16x256 16x16x256
Concatenate
+
16x16x7
+
C
Pool
1x1x256
PyramidTowerPool
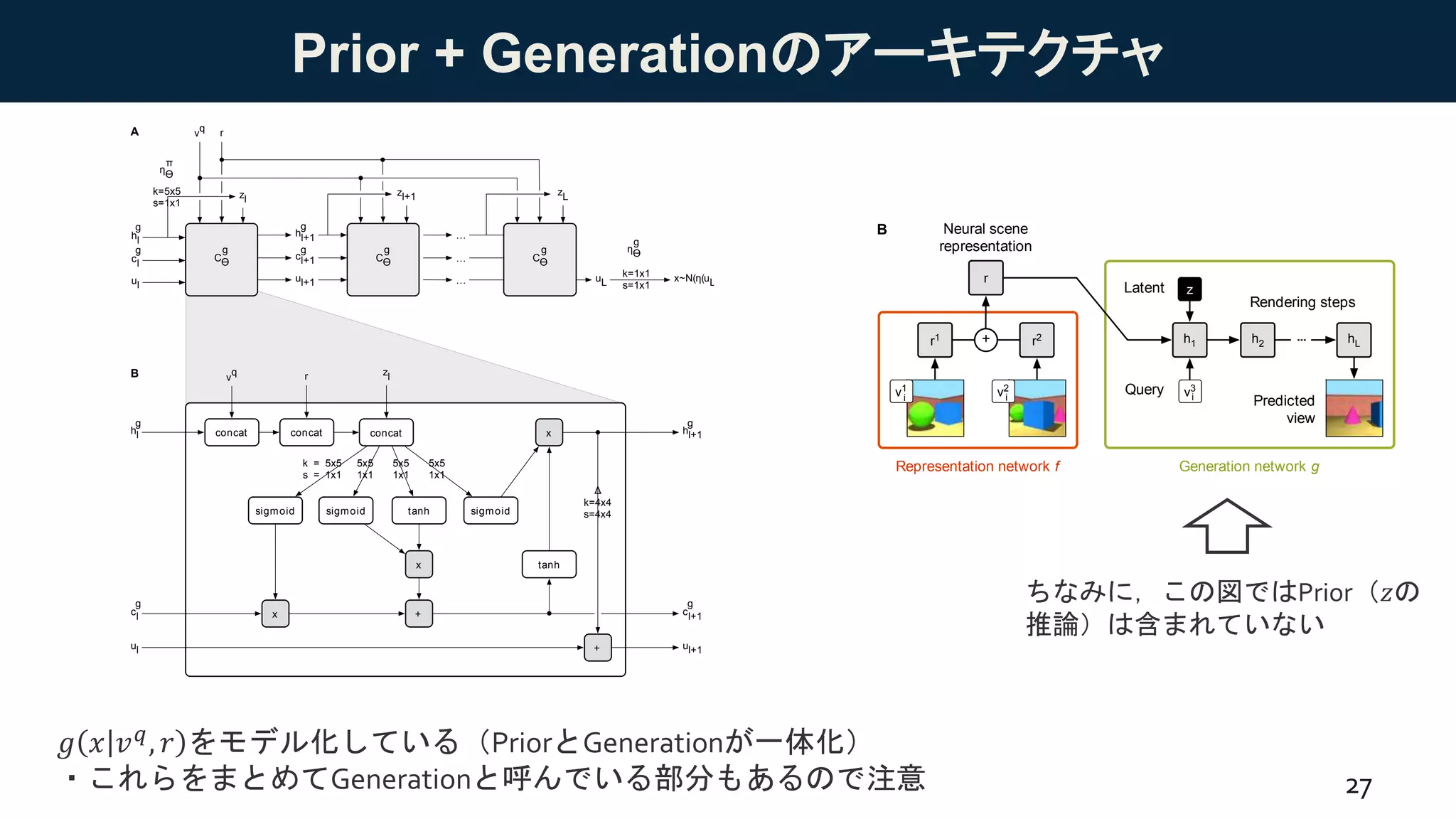
Prior + Generationのアーキテクチャ
27
cl
hl
rv
q
zl
ul
cl+1
hl+1
zl+1
ul+1
…
…
zL
…uL x~N(η(uL))
Cϴ Cϴ Cϴ
g g g
cl
hl
rv
q
ul
cl+1
hl+1
ul+1
concat concat
zl
concat
sigmoidtanhsigmoidsigmoid
tanhx
+x
x
+
Δ
k=4x4
s=4x4
k = 5x5
s = 1x1
5x5
1x1
5x5
1x1
5x5
1x1
k=1x1
s=1x1
ηϴ
g
g
g
g
g
g
g
g
g
ηϴ
π
k=5x5
s=1x1
A
B
FigureS2: Generation network architecture. Implementation detailsof onepossiblearchitec-
ture for the generation network, which given query viewpoint vq
and representation r defines
the distribution g✓(xq
|vq
, r) from which images can be sampled. Convolutional kernel and
stride sizesare indicated by k and s respectively. Convolutions of stride1 ⇥1 aresizepreserv-
ing, whilst all others are ‘valid’. (A) The architecture produces the parameters of the output
distribution through theapplication of asequence of computational cores Cg
✓ that takevq
and r
g
𝑔 𝑥 𝑣 𝑞, 𝑟 をモデル化している(PriorとGenerationが一体化)
・これらをまとめてGenerationと呼んでいる部分もあるので注意
Fig. 1. Schematic illustration of the Generative Query Network. (A) The agent observes
training scene ! from different viewpoints (in this example from &$
/
, &$
@
and &$
A
). (B) The inputs
to the representation network 2 are observations made from viewpoints &$
/
and &$
@
, and the
output is the scene representation 4, which is obtained by element-wise summing of the
observations’ representations. The generation network, a recurrent latent variable model, uses the
representation to predict what the scene would look like from a different viewpoint &$
A
. The
generator can only succeed if 4 contains accurate and complete information about the contents of
the scene (e.g., the identities, positions, colours and counts of the objects, as well as the room’s
colours). Training via back-propagation across many scenes, randomizing the number of
A B
r1
r2
r
h1 h2 hL
z
Generation network gRepresentation network f
···
v2 v3
v1
v2
v1
v3
Neural scene
representation
Query
Latent
Rendering steps
Predicted
view
+
i
i i
i i i
Observation 1
Observation 3Observation 2
ちなみに,この図ではPrior(𝑧の
推論)は含まれていない
データ集合1:Rooms
• Rooms:
– ランダムな四角い部屋にランダムな数(1~3)の様々な物体を配置
•部屋の壁のテクスチャは5種類: red, green, cerise, orange, yellow
• 部屋の床のテクスチャは3種類: yellow, white, blue
• 物体の形は7種類: box, sphere, cylinder, capsule, cone, icosahedron and triangle
– サイズ,位置,色はランダム.ライトもランダム
• その他のシーンのパラメータは省略
– 2万種類のシーンをレンダリング
• 「シーン」は,上記の様々な配置等のうち一つを指す.
• 各シーンについて,5つの視点の画像(解像度は64×64)を獲得
• 学習時は,各ミニバッチでランダムな数の視点を使用
– データセットは公開されている.
• https://github.com/deepmind/gqn-datasets
• 3つの難易度のroomsデータセットが公開されている
30
Scene
i=1
A PredictionObservationsB
Scene
i=2
Scene
i=3
Scene
i=4
v2 v3v1 vq
Prediction Truth Prediction Truth
Observation
Observation
C
i i i i
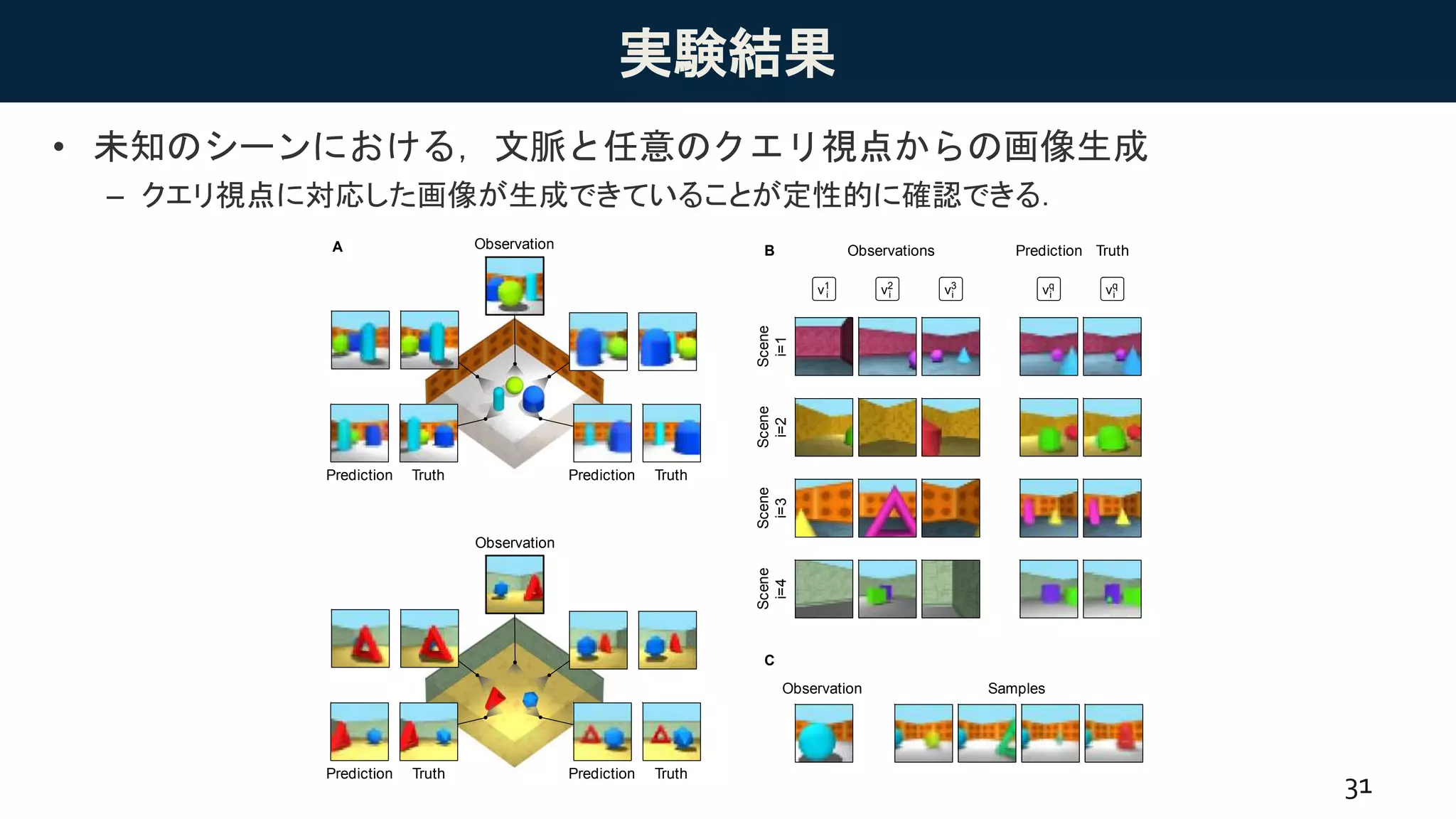
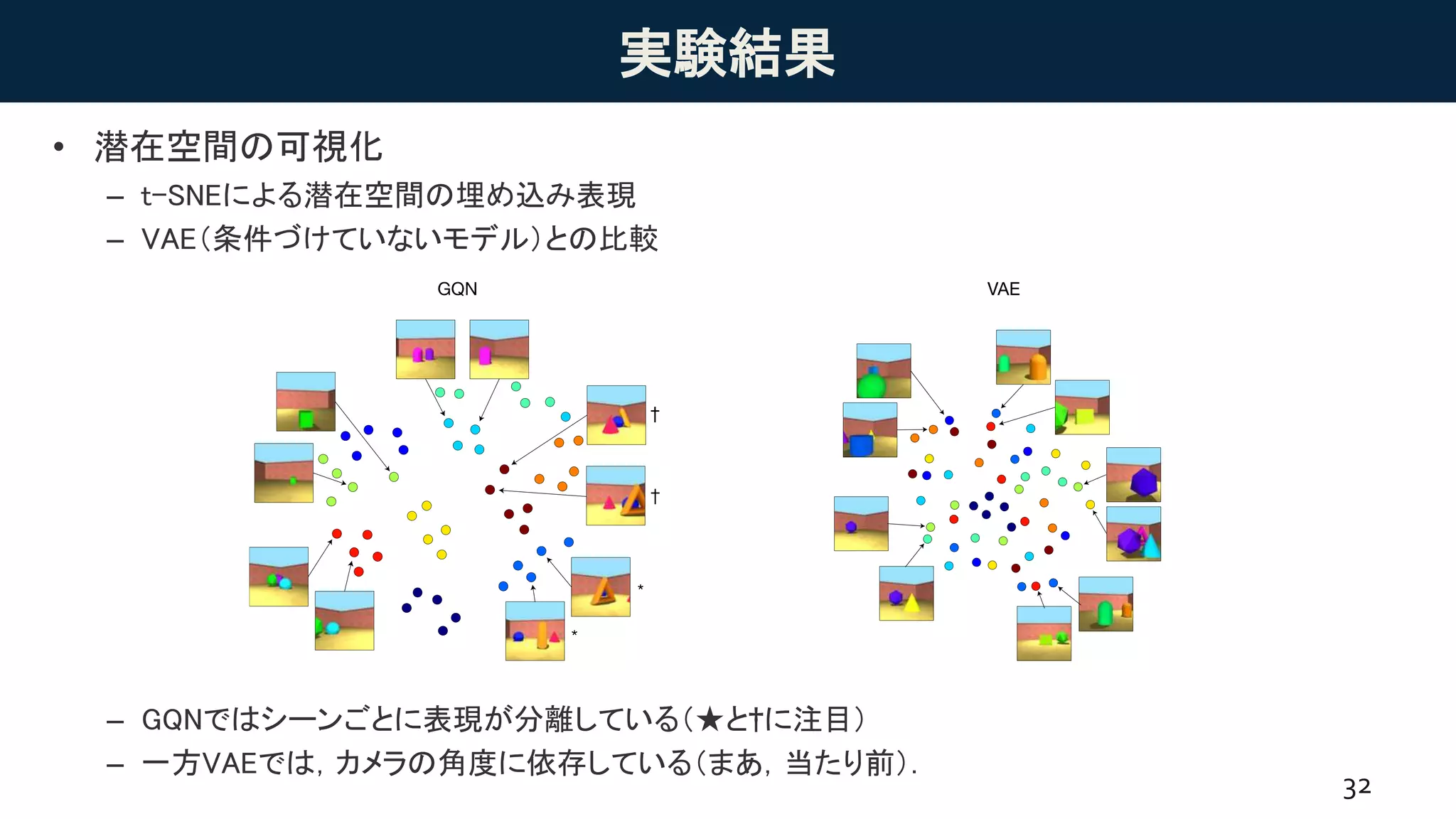
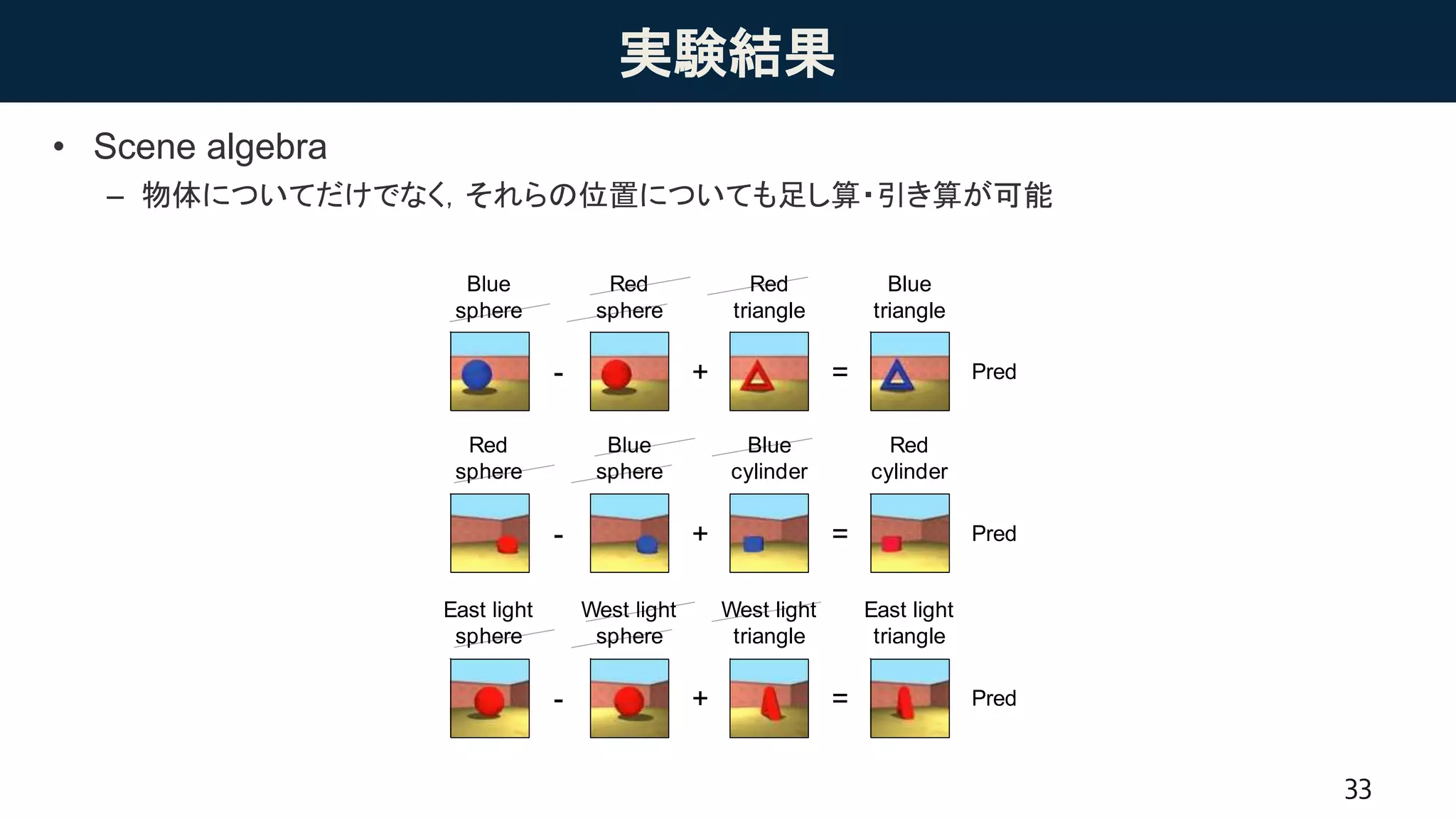
実験結果
• Scene algebra
–物体についてだけでなく,それらの位置についても足し算・引き算が可能
33
H
obs
Previous ob
A B
- =+
Blue
sphere
Red
sphere
Red
triangle
Blue
triangle
- =+
Red
sphere
Blue
sphere
Blue
cylinder
Red
cylinder
- =+
East light
sphere
West light
sphere
West light
triangle
East light
triangle
Pred
Pred
Pred
dueto
obs2
34.
実験結果
• Bayesian Surprise
–𝑦が与えられた下で,𝑥を観測したときのSurpriseを次式で計算(information gain).
𝐼𝐺 𝑥, 𝑦 = 𝐾𝐿[𝑞(𝑧|𝑥, 𝑦)|𝑝(𝑧|𝑦)]
– 文脈の視点数を変更したときのSurprise度合いを確認.
• 視点数が増えるごとに,Surpriseが減少していることがわかる.
34
Held out
observation
Previous observations
B
=
Red
triangle
Blue
triangle
=
Blue
cylinder
Red
cylinder
=
West light
triangle
East light
triangle
Pred
Pred
Pred
dueto
obs2
dueto
obs5
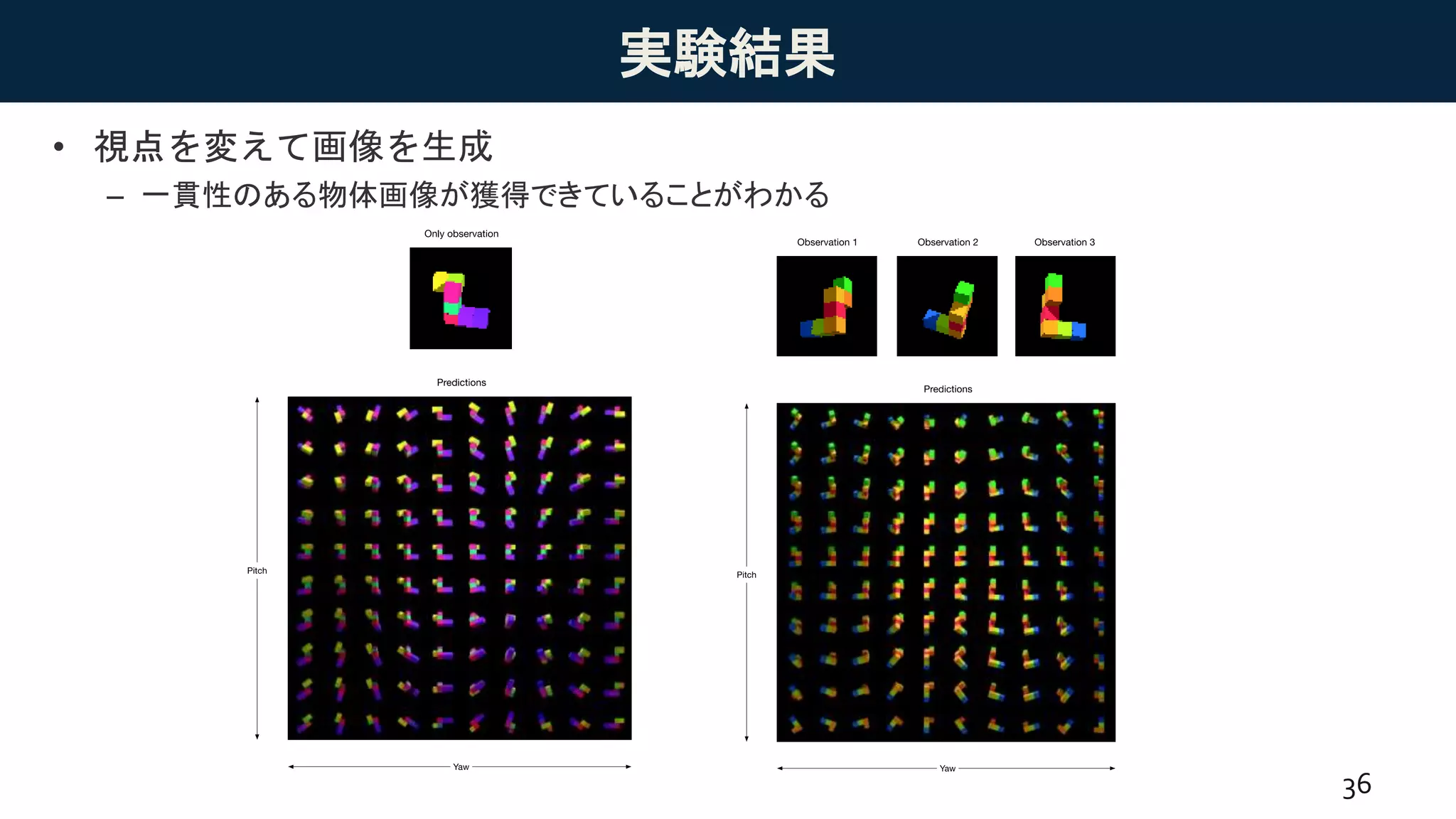
実験結果
• Predicted uncertainty
–Predicted information gain(information gainの期待値)を利用.
𝑃𝐼𝐺 𝑥, 𝑦 = 𝐸 𝑝 𝑥 𝑧, 𝑦 𝑝(𝑧|𝑦)[𝐼𝐺(𝑥, 𝑦)]
– 視点が増えるにつれて,不確実性が下がっていることがわかる.
38
Fig. 6. Partial observability and uncertainty. (A) The agent (GQN) records several
observations of a previously unencountered test maze (indicated by grey triangles). It is then
B
Predicted
uncertaintyObservationsViewpoints
1 2 3 0 1 2 30
Predicted
mapview
sample1
Predicted
mapview
sample2
A
Prediction Truth Prediction TruthObservations Observations
Decreasing uncertainty Decreasing uncertainty
39.
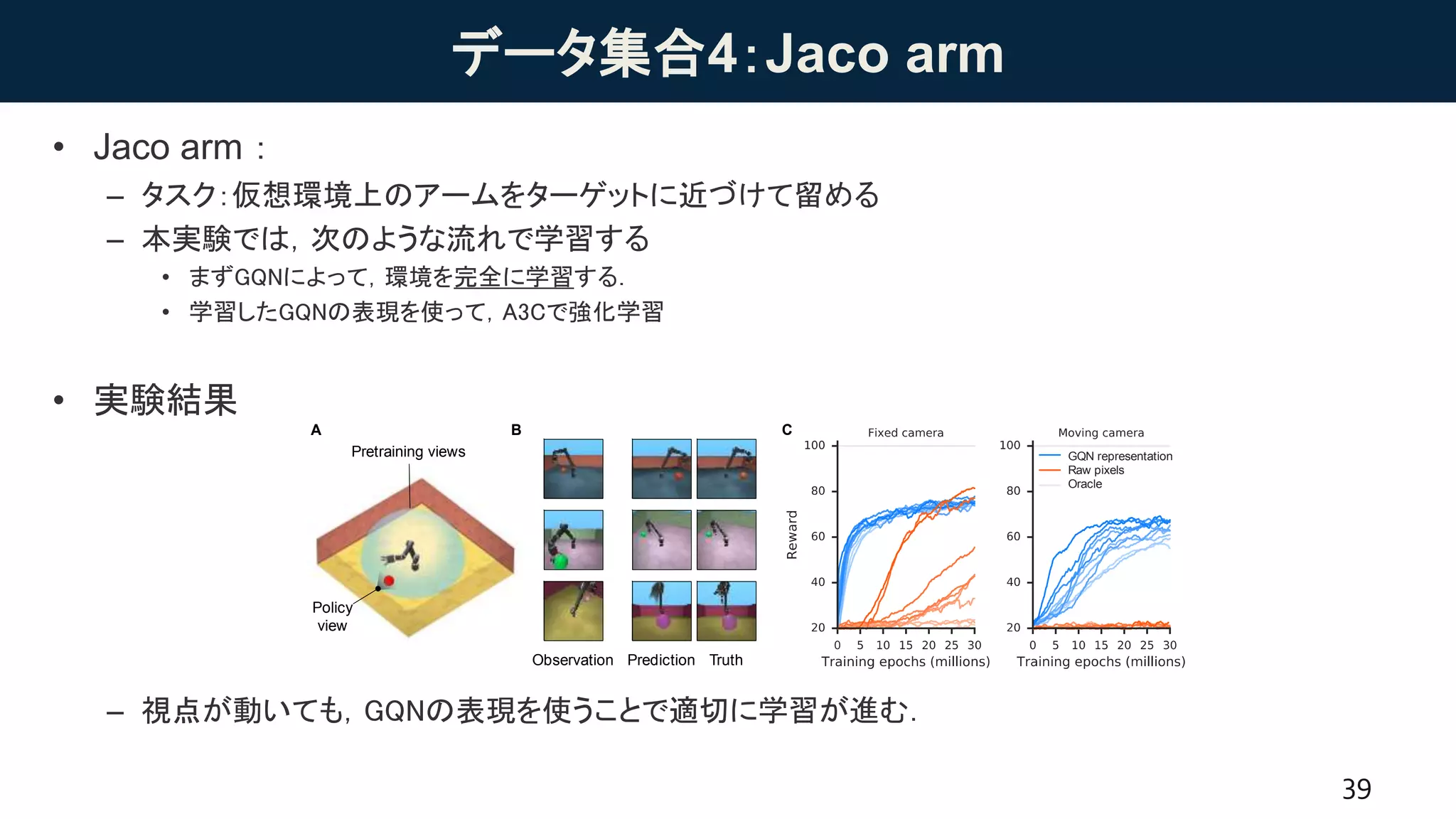
データ集合4:Jaco arm
• Jacoarm:
– タスク:仮想環境上のアームをターゲットに近づけて留める
– 本実験では,次のような流れで学習する
• まずGQNによって,環境を完全に学習する.
• 学習したGQNの表現を使って,A3Cで強化学習
• 実験結果
– 視点が動いても,GQNの表現を使うことで適切に学習が進む.
39
Fig. 5. GQN representation enables more robust and data-efficient control. (A) The goal is
to learn to control a robotic arm to reach a randomly positioned coloured object. The controlling
policy observes the scene from a fixed or moving camera (grey). We pretrain a GQN
A
Pretraining views
B
TruthPredictionObservation
Policy
view
C
GQN representation
Raw pixels
Oracle
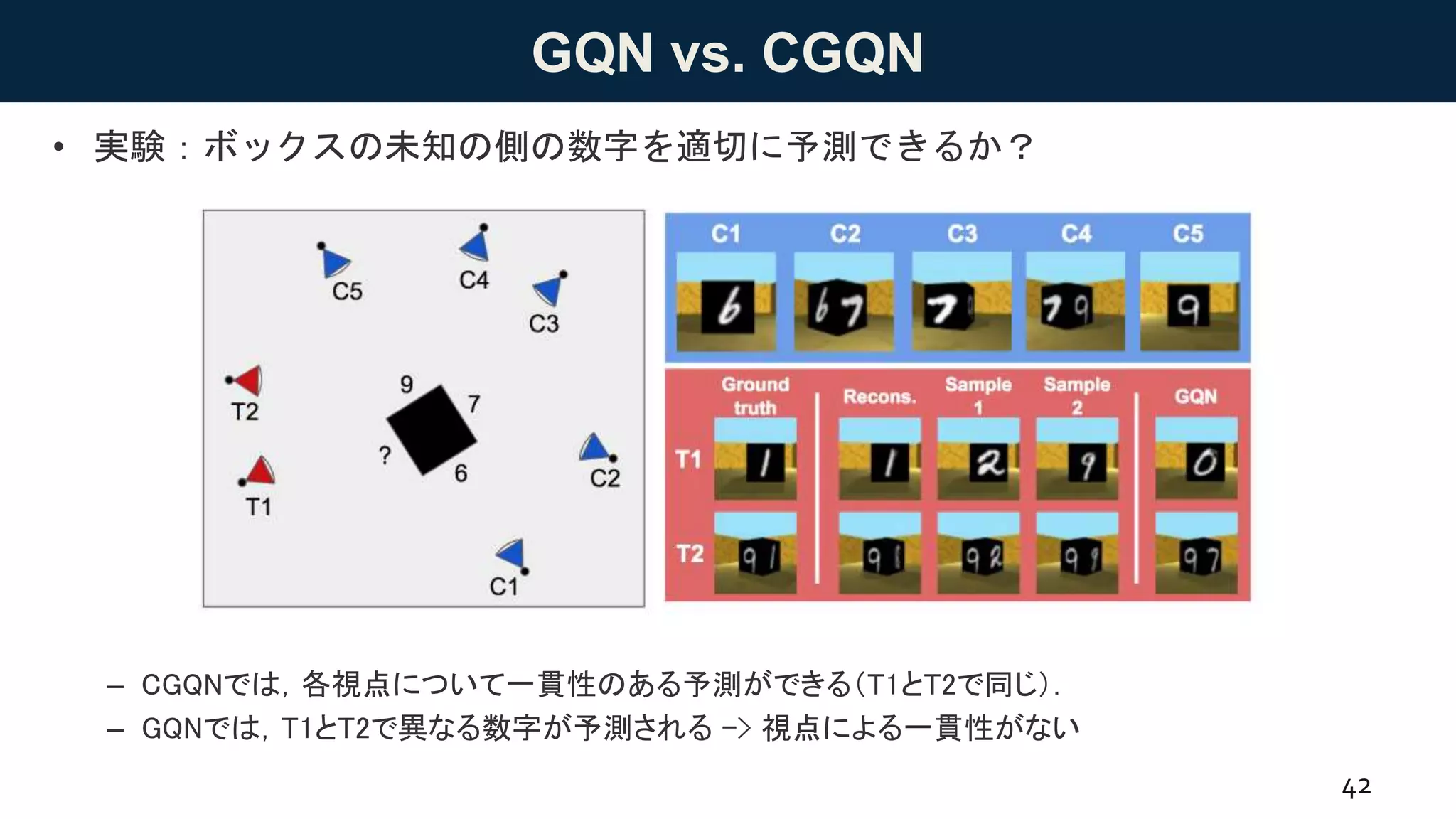
GQN vs. CGQN
•実験:ボックスの未知の側の数字を適切に予測できるか?
– CGQNでは,各視点について一貫性のある予測ができる(T1とT2で同じ).
– GQNでは,T1とT2で異なる数字が予測される -> 視点による一貫性がない
42
Figure 6: Test-set negativeELBO against number of training steps (lower isbetter).
Figure 7: A cube in a room, with MNIST digits engraved on each face (test-set scene). The blue
conesarewherethecontext frameswerecaptured from. Thered conesarewherethemodel isqueried.
The context frames seethreesides of thecube, but themodels aretasked to sample from thefourth,
unseen, side. GQN (right column) independently samples a0 and 7 for the unseen side, resulting in
an inconsistent scene. CGQN samples aconsistent digit (2 or 9) for the unseen cubeface.
SLIM
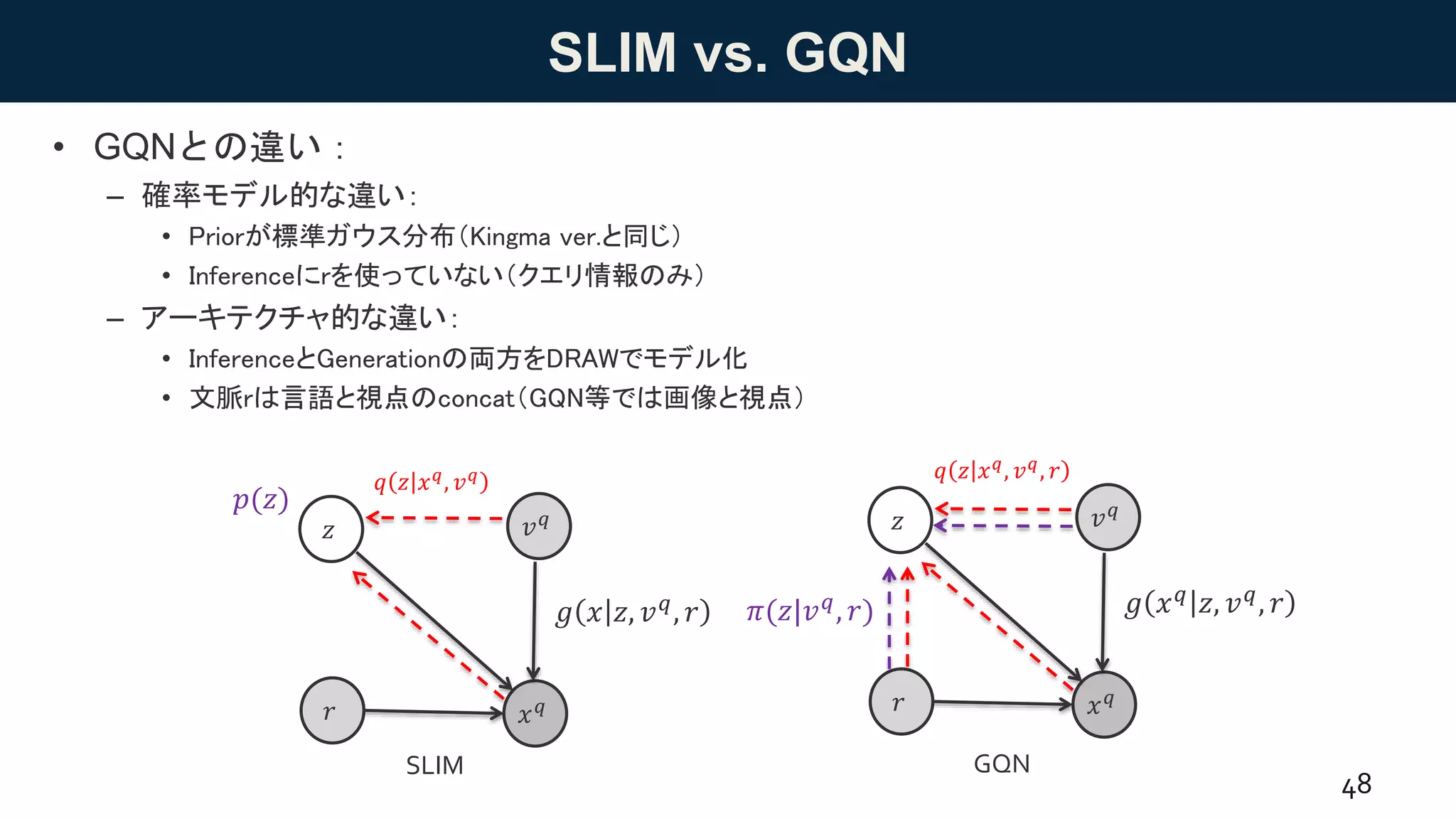
• Encoding SpatialRelations from Natural Language [Ramalho+ 18, DeepMind]
– GQNをベースに,言語の言い換えに対して同じ画像を生成する(不変性のある表現を獲得する)モデルであ
るSLIMを提案
46
Figure 2: Diagram of our model. A representation network parses multiple descriptions of ascene
from different viewpoints by taking in cameracoordinates and atextual caption. Therepresentations
for each viewpoint are aggregated into a scene representation vector r which is then used by a
– 自然言語𝑑1,…,𝑀
と視点𝑣1,…,𝑀
で構成される文脈r = 𝑓(𝑑1,…,𝑀
, 𝑣1,…,𝑀
)が与えられたとき, 未知の視点𝑣
𝑞
から
対応する画像𝑥
𝑞
を生成するように学習
• 上の図では,𝑐が視点
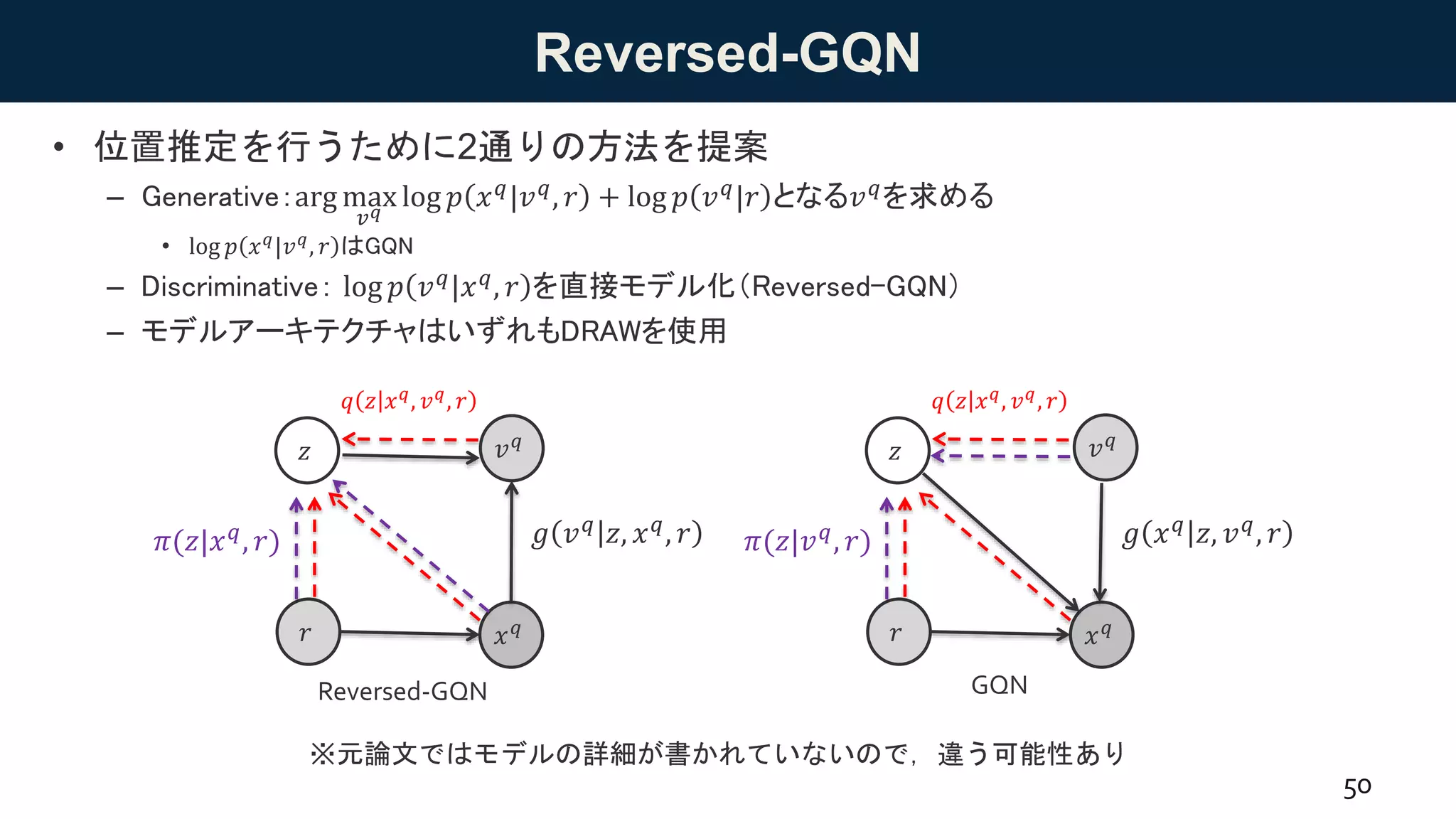
GQNによるカメラ位置の推定
• Learning modelsfor visual 3D localization with implicit mapping [Rosenbaum+ 18,
DeepMind]
– GQNを利用して,自己位置推定のタスクを解く
• Minecraftからシーンのデータを作成.
– 文脈とクエリ(目標)画像から,視点(位置)を推定する
• 普通のGQNと逆の設定.
• 右画像の緑が予測した視点.
49
Figure 1: The Minecraft random walk dataset for localization in 3D scenes. Wegenerate random
trajectories in the Minecraft environment, and collect images along the trajectory labelled by the
camera pose coordinates (x,y,z yaw and pitch). Bottom: Images from random scenes. Top: The
localization problem setting - for a new trajectory in a new scene, given a set of images along
thetrajectory and their corresponding cameraposes (the ‘context’), predict the camerapose of an
additional observed imagein thetrajectory (the‘target’, shown in green).
hasseen increased usefor localization and SLAM problemsin recent years[22, 6, 13], most methods
still rely on pre-specified map representations. Agentstrained with reinforcement learning havebeen
demonstrated to solvenavigation tasksthat implicitly require localization and mapping [11, 3, 1, 20],
suggesting that it ispossible to learn theseabilities without such pre-specification. Other methods
実験結果
• Generative(真ん中)とDiscriminative(下)の出力
– 文脈は20視点
–予測した確率の高いところに,正解の位置(緑)があることが確認できる.
52
ground
truth
samples
camera pose
probability
maps
Figure 5: Generated samples from the generativemodel (middle), and thewhole output distribution
for the discriminative model (bottom). Both were computed using the attention models, and each
imageand posemap isfrom adifferent sceneconditioned on 20 context images. Thesamplescapture
much of the structure of the scenes including the shape of mountains, the location of lakes, the
presence of largetrees etc. (seesupplementary video for moresamples). The distribution of camera
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
GQNと関連研究,世界モデルとの関係について
Presenter: Masahiro Suzuki, Matsuo Lab](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-1-2048.jpg)




![Variational Autoencoder
• Variational autoencoder (VAE) [Kingma+ 13][Rezende+ 14]
– Inference(encoder)𝑞(𝑧|𝑥) とGeneration(decoder)𝑝(𝑥|𝑧) によって構成される深層生成モデル
• 確率分布は,それぞれDNNでモデル化
– Inferenceで入力𝑥を𝑧にencodeし,Generationで𝑧から𝑥をdecode(再構成)する.
– 入力𝑥には画像や文書,音声情報などが使われる.
※DNNによる確率分布のパラメータ化方法や,reparameterization trickなどの話は省略します
7
𝑧Inference 𝑞(𝑧|𝑥) Generation 𝑝(𝑥|𝑧)𝑥 𝑥
再構成入力](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-7-2048.jpg)
![Variational Autoencoder
• グラフィカルモデル
8
• 変分下界(目的関数)
log 𝑝 𝑥
≥ 𝔼 𝑞 𝑧 𝑥 log
𝑝 𝑥 𝑧 𝑝(𝑧)
𝑞 𝑧 𝑥
= 𝔼 𝑞 𝑧 𝑥 log 𝑝(𝑥|𝑧) − 𝐾𝐿[𝑞 𝑧 𝑥 ||𝑝(𝑧)]
• ネットワーク構造
𝑥
𝑧
𝑞(𝑧|𝑥) 𝑝(𝑥|𝑧)
𝑝(𝑧)
𝑧Inference 𝑞(𝑧|𝑥) Generation 𝑝(𝑥|𝑧)𝑥 𝑥
再構成入力
Prior
Inference Generation
対数尤度
(負の)再構成誤差項 正則化項
-> 変分下界を最大化するように,𝑞と𝑝を学習](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-8-2048.jpg)
![潜在空間の学習
• 2次元の潜在空間の可視化(MNISTデータセット)
– 潜在変数𝑧の値を変更し,そのときの画像をGeneration 𝑝(𝑥|𝑧)によって生成
– 画像が連続的に変化しており,潜在空間上で多様体学習ができていることがわかる.
[Kingma+ 13]より](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-9-2048.jpg)
![生成画像
• ランダムな𝑧から画像𝑥をサンプリング
– 様々な𝑧からデータ集合に含まれない未知の画像𝑥を生成できる.
– (ただし,画像がぼやける傾向がある)
[Kingma+ 13]より @AlecRad](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-10-2048.jpg)
![Conditional Variational Autoencoder(Kingma ver.)
• Conditional Variational autoencoder (CVAE) [Kingma+ 14]
– VAEに任意の情報𝑦を「条件づけた(conditioned)」モデル
• 元論文ではM2モデルと呼ばれているもの
• ここでは,CVAE(Kingma ver.)と呼ぶ.
– 𝑦を操作することで,対応するxを生成することができる.
– 𝑧上では,𝑦に依存しない表現を獲得することができる.
• ただし,実際にはInferenceで依存関係が存在している.
11
𝑦
𝑧Inference 𝑞(𝑧|𝑥, 𝑦) Generation 𝑝(𝑥|𝑧, 𝑦)𝑥 𝑥
再構成入力](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-11-2048.jpg)
![Conditional Variational Autoencoder(Kingma ver.)
• グラフィカルモデル
12
• 変分下界(目的関数)
log 𝑝 𝑥|𝑦
≥ 𝔼 𝑞 𝑧 𝑥, 𝑦 log
𝑝 𝑥 𝑧, 𝑦 𝑝(𝑧)
𝑞 𝑧 𝑥, 𝑦
= 𝔼 𝑞 𝑧 𝑥, 𝑦 log 𝑝(𝑥|𝑧, 𝑦) − 𝐾𝐿[𝑞 𝑧 𝑥, 𝑦 ||𝑝(𝑧)]
• ネットワーク構造
入力
𝑥
再構成
𝑥
𝑧Encoder 𝑞(𝑧|𝑥, 𝑦) Decoder 𝑝(𝑥|𝑧, 𝑦)
𝑦
𝑥
𝑧
𝑞(𝑧|𝑥, 𝑦)
𝑝(𝑥|𝑧, 𝑦)
𝑦𝑝(𝑧)](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-12-2048.jpg)
![Conditional Variational Autoencoder(Sohn ver.)
• CVAE(Sohn ver.)[Sohn+ 15]
– Priorを𝑝(𝑧)から𝑝(𝑧|𝑦)に変更.
• PriorもDNNでモデル化する.
• 最初に「CVAE」として提案されたのはこちら.
– 条件づけたPriorによって,次の利点がある.
• 生成モデルが,より柔軟な形になる.
• Priorを用いて,𝑦から直接潜在変数𝑧を推論できる(Inferenceでは𝑥と𝑦の両方が必要).
13
𝑦
𝑧Inference 𝑞(𝑧|𝑥, 𝑦) Generation 𝑝(𝑥|𝑧, 𝑦)𝑥 𝑥
再構成入力
𝑧Prior 𝑝(𝑧|𝑦)](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-13-2048.jpg)
![Conditional Variational Autoencoder(Sohn ver.)
• グラフィカルモデル
14
• 変分下界(目的関数)
log 𝑝 𝑥|𝑦
≥ 𝔼 𝑞 𝑧 𝑥, 𝑦 log
𝑝 𝑥 𝑧, 𝑦 𝑝(𝑧|𝑦)
𝑞(𝑧|𝑥, 𝑦)
= 𝔼 𝑞 𝑧 𝑥, 𝑦 log 𝑝(𝑥|𝑧, 𝑦) − 𝐾𝐿[𝑞(𝑧|𝑥, 𝑦)||𝑝(𝑧|𝑦)]
• ネットワーク構造
𝑥
𝑧
𝑞(𝑧|𝑥, 𝑦)
𝑝(𝑥|𝑧, 𝑦)
𝑝(𝑧|𝑦)
𝑦](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-14-2048.jpg)
![補足: 𝐾𝐿[𝑝(𝑧|𝑥, 𝑦)||𝑝(𝑧|𝑦)]の最小化について
• 𝐾𝐿[𝑝(𝑧|𝑥, 𝑦)||𝑝(𝑧|𝑦)]は,近づける先の分布𝑝(𝑧|𝑥, 𝑦)の方が不確かさが小さい
– 直感的には, 𝑝(𝑧|𝑦)は尖った分布に近づいてしまい,学習が安定しないと考えられる(左)
– 実際はKL項はデータ分布の期待値であり,式変形するとデータ分布での期待値𝑝 𝑎𝑣𝑔(𝑧|𝑦)と𝑝(𝑧|𝑦)の
KLダイバージェンスになる(右)
• そのため,学習は安定する.
• CVAE以外の利用:
– マルチモーダル学習では,単一モダリティ入力 𝑦のInference 𝑞(𝑧|𝑦)を学習するために導入されている.
• 初出はJMVAE [Suzuki+ 16],その後SCAN [Higgins+ 17]などでも利用されている.
• 上記の証明は, JMVAEの説明として[Vedantam+ 17]のAppendixに書かれている.
– 世界モデル研究では標準的な方法になりつつある.
• 最近では,TD-VAE [Gregor+ 18]でも同様の方法が使われている.
15
𝑝(𝑧|𝑥, 𝑦) 𝑝(𝑧|𝑦)
𝑝 𝑎𝑣𝑔(𝑧|𝑦) = 𝐸 𝑝 𝑑𝑎𝑡𝑎(𝑥|𝑦)[𝑝 𝑧 𝑥, 𝑦 ]
𝑝(𝑧|𝑦)](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-15-2048.jpg)
![CVAEの画像生成
• 数字のラベル情報で条件付けることにより「アナロジー」が生成できる[Kingma+
15]
– (𝑥, 𝑦)のペアからInferenceで𝑧を推論(𝑧~𝑞(𝑧|𝑥, 𝑦))
– ある𝑦 𝑞からGenerationを使って,対応する未知の画像𝑥 𝑞 ~𝑝(𝑥|𝑦 𝑞, 𝑧)を生成.
– このとき,推論した𝑧には(𝑥,𝑦)のペアに対応する「筆跡」のような情報が獲得されている.
(a) Handwriting styles for MNIST obtained by fixing theclass label and varying the2D latent variable z
(b) MNIST analogies (c) SVHN analogies
Figure 1: (a) Visualisation of handwriting styles learned by the model with 2D z-space. (b,c)](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-16-2048.jpg)
![条件付ける情報について
• 条件付ける情報はラベルのような単純なものでなくてもよい
– ただし,ある程度圧縮された表現に変換することが望ましい
• 属性で条件づけて画像生成 [Larsen+ 15]
• 文書で条件付けて画像生成 [Mansimov+ 16]
17](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-17-2048.jpg)


![Generative Query Network
• グラフィカルモデル
20
• 変分下界(目的関数)
log 𝑝 𝑥 𝑞|𝑣 𝑞, 𝑟
≥ 𝔼 𝑞 𝑧 𝑥 𝑞
, 𝑣 𝑞
, 𝑟 log
𝑔 𝑥 𝑞 𝑧, 𝑣 𝑞, 𝑟 𝜋(𝑧|𝑣 𝑞, 𝑟)
𝑞 𝑧 𝑥 𝑞
, 𝑣 𝑞
, 𝑟
= 𝔼 𝑞 𝑧 𝑥 𝑞
, 𝑣 𝑞
, 𝑟 log 𝑔 𝑥 𝑞 𝑧, 𝑣 𝑞, 𝑟
− 𝐾𝐿[𝑞 𝑧 𝑥 𝑞, 𝑣 𝑞, 𝑟 ||𝜋(𝑧|𝑣 𝑞, 𝑟)]
• Generative Query Network(GQN)
– 文脈r = 𝑓(𝑥1,…,𝑀
, 𝑣1,…,𝑀
) とクエリ視点𝑣
𝑞
で条件づけたCVAE(Sohn ver.)
• 𝑟と𝑣
𝑞
を前述の説明での𝑦と考えればよい
• 𝑓は表現ネットワーク(2ページ先で説明)
𝑥 𝑞
𝑧
𝑞 𝑧 𝑥 𝑞, 𝑣 𝑞, 𝑟
𝑔 𝑥 𝑞 𝑧, 𝑣 𝑞, 𝑟𝜋(𝑧|𝑣 𝑞, 𝑟)
𝑟
𝑣 𝑞
文脈とクエリ視点で条件づけた下での
クエリ画像の対数尤度
𝑥1,…,𝑀
, 𝑣1,…,𝑀
の情報を
含んだ「文脈」
確率モデル的には,このページを理解できればOK](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-20-2048.jpg)
![GQNの解釈
• 変分下界(目的関数):
• 第1項では,クエリの答え𝑥 𝑞を再構成するように学習
– Inferenceでは,文脈(様々な視点と対応する画像)𝑟とクエリ𝑣 𝑞,及びその答え𝑥 𝑞 から𝑧を推論
– 様々なシーン𝑖についても同じ𝑧空間に推論し,Generationで再構成するように学習する.
– すると,𝑧ではそのシーン全体を表すコンパクトな表現が獲得されるようになる.
• そういう意味では,シーン全体の3D表現に対応するような「何か」は学習されているといえる.
– ただし,3Dモデルそのものが学習できた訳ではないことに注意
• 訓練データ内で想定している視点とは大きく異なる or 補完できない視点の場合は,うまく画像が生成されない可能性が高
い.
• 同様に,訓練データと全く異なる物体 or 環境のシーンからの画像生成は困難.
21
𝔼 𝑞 𝑧 𝑥 𝑞, 𝑣 𝑞, 𝑟 log 𝑔 𝑥 𝑞 𝑧, 𝑣 𝑞, 𝑟 − 𝐾𝐿[𝑞 𝑧 𝑥 𝑞, 𝑣 𝑞, 𝑟 ||𝜋(𝑧|𝑣 𝑞, 𝑟)]](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-21-2048.jpg)
![GQNの解釈
• 変分下界(目的関数):
• 第2項では,InferenceとPriorが近づくように学習
– これによって,PriorとInferenceが同じような𝑧を推論できるようになる.
– テスト時にPriorを使えば,クエリの答え𝑥 𝑞を入れなくても,文脈𝑟とクエリ𝑣 𝑞 だけで対応する𝑧を推論でき
るようになる.
• つまり,デモ動画ではInferenceを使用していない
• 第2項がうまく学習できることはp15で説明したとおり.
22
𝔼 𝑞 𝑧 𝑥 𝑞, 𝑣 𝑞, 𝑟 log 𝑔 𝑥 𝑞 𝑧, 𝑣 𝑞, 𝑟 − 𝐾𝐿[𝑞 𝑧 𝑥 𝑞, 𝑣 𝑞, 𝑟 ||𝜋(𝑧|𝑣 𝑞, 𝑟)]](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-22-2048.jpg)

![自己回帰モデルによる潜在変数への推論
• VAEでは,複雑な入力から潜在変数を推論するために,様々な工夫が取られてい
る.
– 潜在変数の多層化 [Sønderby+ 16]
– Normalizing flow [Rezende+ 15]
– DRAW [Gregor+ 15](後ほど補足)
• GQNでは,自己回帰モデルによって𝑧への柔軟な推論を実現
– 自己回帰モデル:尤度を複数の条件付き分布の積で表現するモデル.
– 本論文では,潜在変数を𝐿個のグループに分けて,各分布の積で表現.
• PriorとInferenceが該当
25
𝑥 𝑞
𝑧
𝑞 𝑧 𝑥 𝑞
, 𝑣 𝑞
, 𝑟
𝜋(𝑧|𝑣 𝑞
, 𝑟)
𝑟
𝑣 𝑞
Prior:
Inference:](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-25-2048.jpg)

![補足:DRAW
• DRAW: A Recurrent Neural Network For Image Generation [Gregor+ 15]
28
– VAEのencoderとdecoderの両方を,RNNによって自己回帰的にモデル化(左下)
– 複雑な画像を生成するためにも使われる [Gregor+ 16]
• DRAWでは,画像が各ステップで逐次的に生成されていく(右下)
• ただし[Gregor+ 15]に書かれているattention機構は,殆ど使われていないので注意!!
– GQNの元論文ではDRAWは使われていない
• しかし,こちらのほうが実装が容易&複雑な画像を生成できるので,GQNの関連研究&再現実装(Tensorflow,
Pytorch)ではDRAWが採用されている.
• 逆に言うと,アーキテクチャ自体はそれほど本質ではないことを示している.](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-28-2048.jpg)


![実験結果
• Bayesian Surprise
– 𝑦が与えられた下で,𝑥を観測したときのSurpriseを次式で計算(information gain).
𝐼𝐺 𝑥, 𝑦 = 𝐾𝐿[𝑞(𝑧|𝑥, 𝑦)|𝑝(𝑧|𝑦)]
– 文脈の視点数を変更したときのSurprise度合いを確認.
• 視点数が増えるごとに,Surpriseが減少していることがわかる.
34
Held out
observation
Previous observations
B
=
Red
triangle
Blue
triangle
=
Blue
cylinder
Red
cylinder
=
West light
triangle
East light
triangle
Pred
Pred
Pred
dueto
obs2
dueto
obs5](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-34-2048.jpg)

![実験結果
• Predicted uncertainty
– Predicted information gain(information gainの期待値)を利用.
𝑃𝐼𝐺 𝑥, 𝑦 = 𝐸 𝑝 𝑥 𝑧, 𝑦 𝑝(𝑧|𝑦)[𝐼𝐺(𝑥, 𝑦)]
– 視点が増えるにつれて,不確実性が下がっていることがわかる.
38
Fig. 6. Partial observability and uncertainty. (A) The agent (GQN) records several
observations of a previously unencountered test maze (indicated by grey triangles). It is then
B
Predicted
uncertaintyObservationsViewpoints
1 2 3 0 1 2 30
Predicted
mapview
sample1
Predicted
mapview
sample2
A
Prediction Truth Prediction TruthObservations Observations
Decreasing uncertainty Decreasing uncertainty](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-38-2048.jpg)

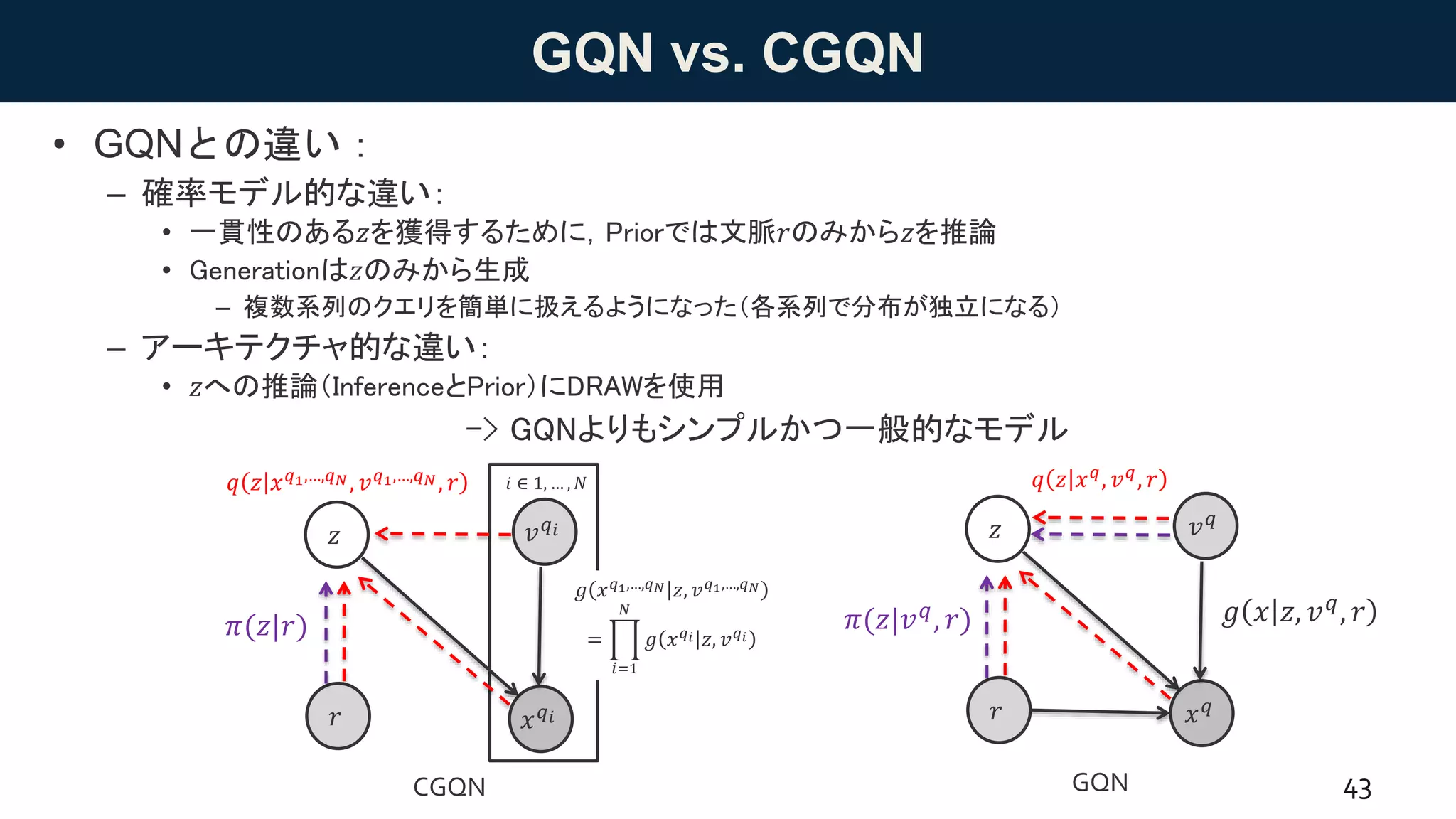
![Consistent GQN
• Consistent Generative Query Networks [Kumar+ 18, DeepMind]
– 背景:ビデオ予測などでは,入力と出力が連続的である必要がある.
– 任意の時間のフレームを生成できるモデルとしてCGQNを提案.
• 過去の文脈r = 𝑓(𝑥1,…,𝑀
, 𝑣1,…,𝑀
)と任意の時間𝑣 𝑞 𝑖からフレーム𝑥 𝑞 𝑖を予測
41
• グラフィカルモデル • 変分下界(目的関数)
log 𝑝 𝑥 𝑞1,…,𝑞 𝑁|𝑣 𝑞1,…,𝑞 𝑁, 𝑟
≥ 𝔼 𝑞 𝑧 𝑥 𝑞1,…,𝑞 𝑁, 𝑣 𝑞1,…,𝑞 𝑁, 𝑟 log
𝑔 𝑥 𝑞1,…,𝑞 𝑁 𝑧, 𝑣 𝑞1,…,𝑞 𝑁 𝜋(𝑧|𝑟)
𝑞 𝑧 𝑥 𝑞1,…,𝑞 𝑁, 𝑣 𝑞1,…,𝑞 𝑁, 𝑟
= 𝔼 𝑞 𝑧 𝑥 𝑞1,…,𝑞 𝑁, 𝑣 𝑞1,…,𝑞 𝑁, 𝑟 log
𝑖=1
𝑁
𝑔 𝑥 𝑞 𝑖 𝑧, 𝑣 𝑞 𝑖
− 𝐾𝐿[𝑞 𝑧 𝑥 𝑞1,…,𝑞 𝑁, 𝑣 𝑞1,…,𝑞 𝑁, 𝑟 ||𝜋(𝑧|𝑟)]𝑥 𝑞 𝑖
𝑧
𝑞 𝑧 𝑥 𝑞1,…,𝑞 𝑁, 𝑣 𝑞1,…,𝑞 𝑁, 𝑟
𝜋(𝑧|𝑟)
𝑟
𝑣 𝑞 𝑖
※比較しやすいように,notationはGQN論文に合わせています.
𝑔 𝑥 𝑞1,…,𝑞 𝑁 𝑧, 𝑣 𝑞1,…,𝑞 𝑁
=
𝑖=1
𝑁
𝑔 𝑥 𝑞 𝑖 𝑧, 𝑣 𝑞 𝑖
𝑖 ∈ 1, … , 𝑁](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-41-2048.jpg)
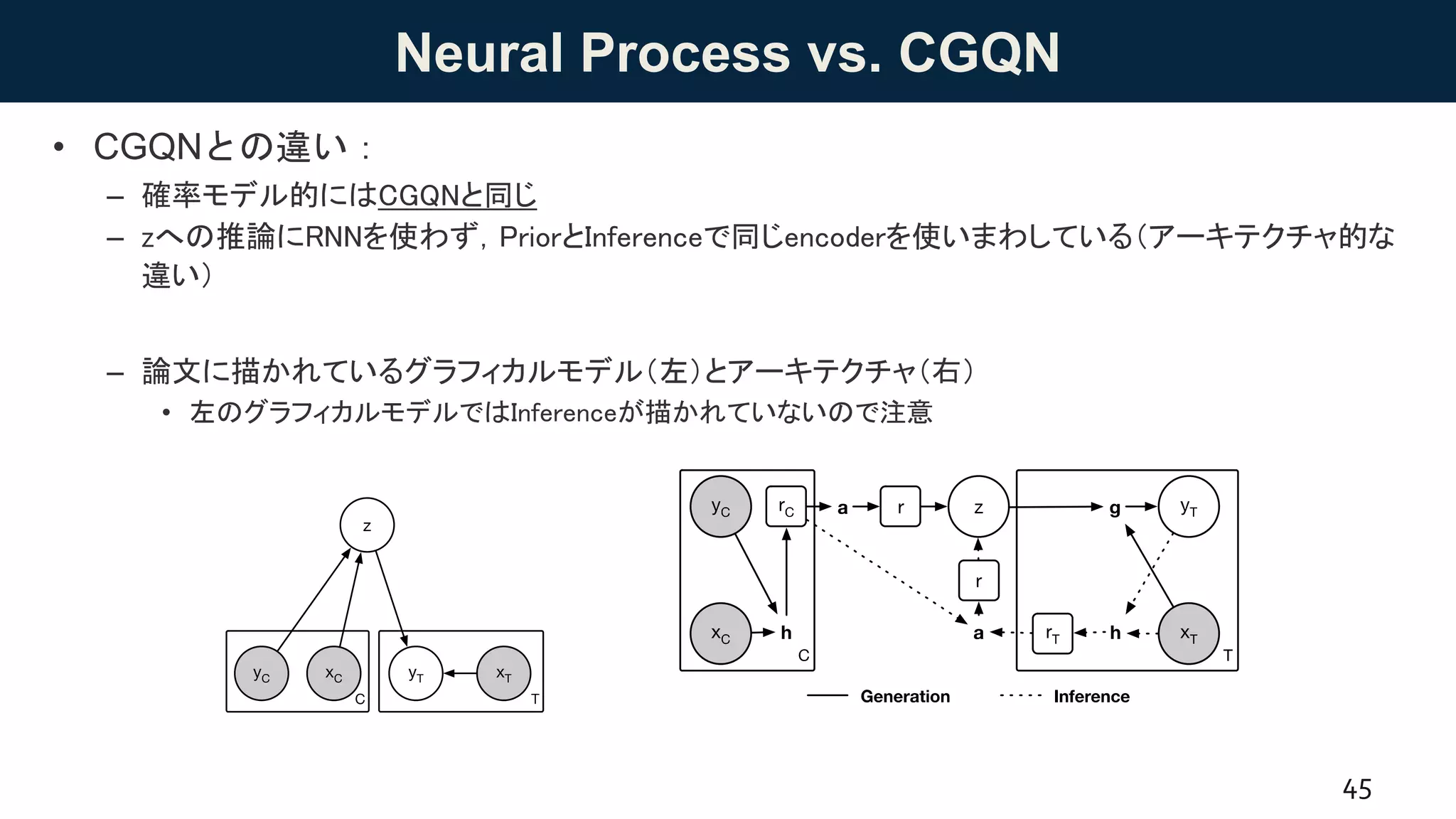
![Neural Processes
• Neural Processes [Garnelo+ 18, DeepMind]
– (ざっくりいうと)Gaussian ProcessのカーネルをDNNに置き換えたモデル
• Globalな潜在変数を導入していることが特徴.
• 詳しくはこちらのスライドを参照(DL輪読会資料):
https://www.slideshare.net/DeepLearningJP2016/dlconditional-neural-
processes?ref=https://deeplearning.jp/neural-processes/
– 複数の任意の点とその値(文脈)が与えられた下で,未知の点の値を予測する.
• あれ,GQNっぽい
44
Neural Processes
10 100 300 784
Number of context points
ContextSample1Sample2Sample3
15 30 90 1024
Number of context points
ContextSample1Sample2Sample3
Figure 4. Pixel-wise regression on MNIST and CelebA The diagram on the left visualises how pixel-wise image completion can
任意の文脈を与えたときの回帰予測
(文脈が増えると分散が小さくなる)
任意の文脈を与えたときの画像生成
(文脈が増えると画像のバリエーションが小さくなる)](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-44-2048.jpg)
![SLIM
• Encoding Spatial Relations from Natural Language [Ramalho+ 18, DeepMind]
– GQNをベースに,言語の言い換えに対して同じ画像を生成する(不変性のある表現を獲得する)モデルであ
るSLIMを提案
46
Figure 2: Diagram of our model. A representation network parses multiple descriptions of ascene
from different viewpoints by taking in cameracoordinates and atextual caption. Therepresentations
for each viewpoint are aggregated into a scene representation vector r which is then used by a
– 自然言語𝑑1,…,𝑀
と視点𝑣1,…,𝑀
で構成される文脈r = 𝑓(𝑑1,…,𝑀
, 𝑣1,…,𝑀
)が与えられたとき, 未知の視点𝑣
𝑞
から
対応する画像𝑥
𝑞
を生成するように学習
• 上の図では,𝑐が視点](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-46-2048.jpg)
![SLIMのグラフィカルモデルと変分下界
– 自然言語𝑑1,…,𝑀
と視点𝑣1,…,𝑀
で構成される文脈r = 𝑓(𝑑1,…,𝑀
, 𝑣1,…,𝑀
)が与えられたとき, 未知
の視点𝑣
𝑞
から対応する画像𝑥
𝑞
を生成するように学習
– 元論文では自然言語と画像の両方に𝑑が使われていたり,図(前ページ)と文中の説明があってなかった
りして分かりづらいので,あっているか微妙
47
• グラフィカルモデル
• 変分下界(目的関数)
log 𝑝 𝑥 𝑞|𝑣 𝑞, 𝑟
≥ 𝔼 𝑞 𝑧 𝑥 𝑞, 𝑣 𝑞 log
𝑔 𝑥 𝑞 𝑧, 𝑣 𝑞, 𝑟 𝑝(𝑧)
𝑞 𝑧 𝑥 𝑞
, 𝑣 𝑞
= 𝔼 𝑞 𝑧 𝑥 𝑞, 𝑣 𝑞 log 𝑔 𝑥 𝑞
𝑧, 𝑣 𝑞
, 𝑟
− 𝐾𝐿[𝑞 𝑧 𝑥 𝑞, 𝑣 𝑞 ||𝑝(𝑧)]𝑥 𝑞
𝑧
𝑞 𝑧 𝑥 𝑞
, 𝑣 𝑞
𝑔 𝑥 𝑧, 𝑣 𝑞, 𝑟
𝑟
𝑣 𝑞
𝑝(𝑧)](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-47-2048.jpg)
![GQNによるカメラ位置の推定
• Learning models for visual 3D localization with implicit mapping [Rosenbaum+ 18,
DeepMind]
– GQNを利用して,自己位置推定のタスクを解く
• Minecraftからシーンのデータを作成.
– 文脈とクエリ(目標)画像から,視点(位置)を推定する
• 普通のGQNと逆の設定.
• 右画像の緑が予測した視点.
49
Figure 1: The Minecraft random walk dataset for localization in 3D scenes. Wegenerate random
trajectories in the Minecraft environment, and collect images along the trajectory labelled by the
camera pose coordinates (x,y,z yaw and pitch). Bottom: Images from random scenes. Top: The
localization problem setting - for a new trajectory in a new scene, given a set of images along
thetrajectory and their corresponding cameraposes (the ‘context’), predict the camerapose of an
additional observed imagein thetrajectory (the‘target’, shown in green).
hasseen increased usefor localization and SLAM problemsin recent years[22, 6, 13], most methods
still rely on pre-specified map representations. Agentstrained with reinforcement learning havebeen
demonstrated to solvenavigation tasksthat implicitly require localization and mapping [11, 3, 1, 20],
suggesting that it ispossible to learn theseabilities without such pre-specification. Other methods](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-49-2048.jpg)
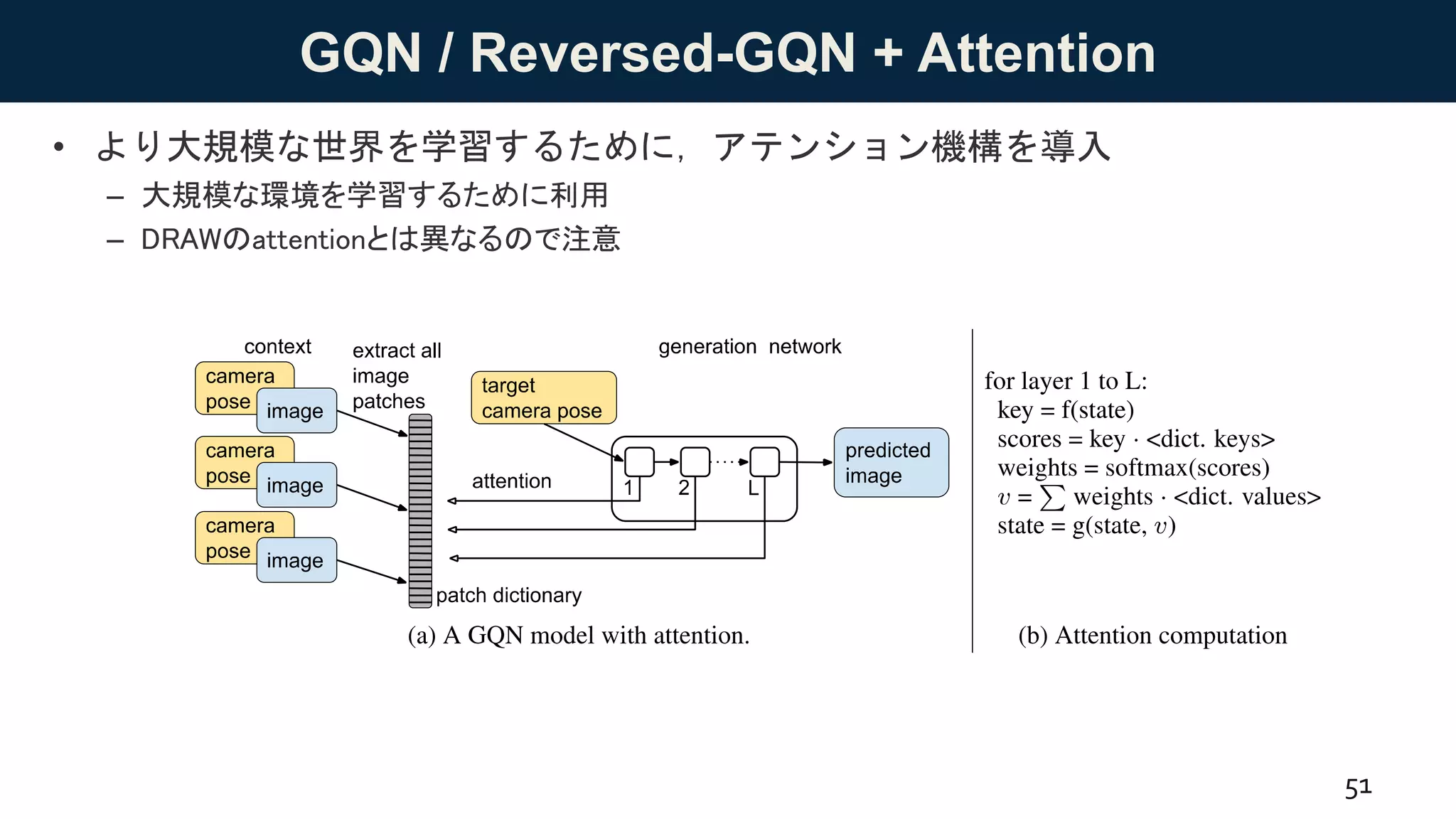


![GQNと世界モデル
• これらのGQN系論文は「世界モデル」研究の一分野と考えることができる.
• 世界モデル(world model):
– 外界からの刺激を元に,外界世界をシミュレートするモデル
– 内部モデル(internal model)や力学モデル(dynamics model)もほぼ同じ概念
– Haらの論文タイトル[Ha+ 18]としても有名
• 説明スライド: https://www.slideshare.net/masa_s/ss-97848402
• GQN系は,視点(と画像)で条件付けた世界モデルを学習している.
– 世界全体をそのままモデル化するよりも効率的
– [Ha+ 18]では,条件付せずにそのまま学習していた(なので1つの小規模なシーンしか学習できな
かった)
54
刺激
世界モデル](https://image.slidesharecdn.com/20180817-180827085537/75/DL-GQN-54-2048.jpg)





![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...](https://cdn.slidesharecdn.com/ss_thumbnails/20210806journalclub-210806023711-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0401-220405031053-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]GENESIS: Generative Scene Inference and Sampling with Object-Centric L...](https://cdn.slidesharecdn.com/ss_thumbnails/20191206genesis-191206004127-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Relational inductive biases, deep learning, and graph networks](https://cdn.slidesharecdn.com/ss_thumbnails/180629dlseminarrelationalinductivebias-180706003755-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]HoloGAN: Unsupervised learning of 3D representations from natural images](https://cdn.slidesharecdn.com/ss_thumbnails/hologanslideshare-190906010228-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=640&height=640&fit=bounds)





































