More Related Content

PPTX
Curriculum Learning (関東CV勉強会) 
PDF
![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv... 
PDF
論文紹介 Pixel Recurrent Neural Networks 
PDF
Disentanglement Survey:Can You Explain How Much Are Generative models Disenta... ![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant... 
PDF
Bayesian Neural Networks : Survey What's hot

PDF

PDF

PDF

PPTX

PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ 
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料 
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces 
PDF
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX

PDF
![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]When Does Label Smoothing Help? 
PDF

PDF

PDF
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder 
PDF
![[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180720-180723071258-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions 
PDF

PPTX
【DL輪読会】Scaling Laws for Neural Language Models 
PDF
Similar to ELBO型VAEのダメなところ

PPTX
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2) 
PPTX
![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder ![[DL輪読会]Factorized Variational Autoencoders for Modeling Audience Reactions to...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180112-180115090630-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Factorized Variational Autoencoders for Modeling Audience Reactions to... 
PDF
![Infinite SVM [改] - ICML 2011 読み会](https://cdn.slidesharecdn.com/ss_thumbnails/isvm-icml11a-110719050617-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
Infinite SVM [改] - ICML 2011 読み会 
PDF

PPTX
![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw... 
PDF
![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Control as Inferenceと発展 
PPTX
猫でも分かるVariational AutoEncoder 
PDF

PDF
深層学習と確率プログラミングを融合したEdwardについて 
PPTX

PDF

PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太 
PDF
(DL hacks輪読) Variational Dropout and the Local Reparameterization Trick ![[DL輪読会]Variational Autoencoder with Arbitrary Conditioning](https://cdn.slidesharecdn.com/ss_thumbnails/190412nonakadlhacksv2-190422075347-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Variational Autoencoder with Arbitrary Conditioning 
PDF
Unified Expectation Maximization More from KCS Keio Computer Society

PPTX
Large scale gan training for high fidelity natural 
PPTX
Imagenet trained cnns-are_biased_towards 
PPTX

PPTX

PDF

PPTX

PDF

PDF
Vector-Based navigation using grid-like representations in artificial agents 
PDF

PDF

PDF

PDF
Hindsight experience replay 
PDF

PDF

PDF
ゼロから作るDeepLearning 2~3章 輪読 
PDF

PDF

PDF
ゼロから作るDeepLearning 3.3~3.6章 輪読 ![[論文略説]Stochastic Thermodynamics Interpretation of Information Geometry](https://cdn.slidesharecdn.com/ss_thumbnails/aa-180330124241-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[論文略説]Stochastic Thermodynamics Interpretation of Information Geometry 
PPTX
Graph Convolutional Network 概説 ELBO型VAEのダメなところ
- 1.
- 2.
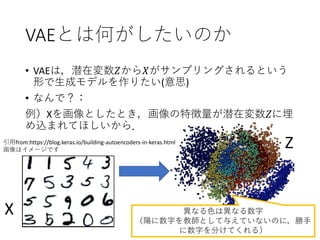
[pre]VAEとは何がしたいのか
• データ𝐷 =(𝑋 𝑖
, 𝑖 = 1, … , 𝑁)があります.
• 𝐷から生成モデル(generative model)を作りたい.
→生成モデルとは: 𝑋の母集団の確率分布𝑝 𝑅 𝑋 のこと.
または,𝑝 𝑅 𝑋 からサンプリングできる装置のこと.
• (有限の)𝐷からどうやって作るか→尤度最大化!
• 尤度最大化とは:
𝜃でパラメトライズされた確率分布 𝑝 𝜃(𝑋)を
𝐷を用いて𝑝 𝑅 𝑋 に近づけるためには, 𝜃を
𝜃 = argmax
𝜃
ෑ
𝑖
𝑝 𝜃(𝑋 𝑖)
とすればよいという考え方のこと(を尤度最大化という).
データ𝐷がサンプリング
される確率を高くする
という意味
- 3.
- 4.
VAEを作ろう
• 潜在変数の確率𝑝 𝑍と,その分布からサンプリングさ
れた𝑍から𝑋がサンプリングされる条件付確率𝑝(𝑋|𝑍)を
作ることで,潜在変数を元にしたサンプリングを行う.
• VAEでは,𝑝 𝑍 は固定の分布, 𝑝 𝜃(𝑋|𝑍)を学習する.
𝜃は学習されるべきパラメータ.
• 最尤推定をしよう:(対数尤度の勾配を求められればよい)
∇ 𝜃 log 𝑝 𝑋 𝑖 = ∇ 𝜃 log න 𝑝 𝜃 𝑋 𝑖|𝑍 𝑝 𝑍 𝑑𝑍
勾配を求めなければいけない項に解析的に求められな
い積分が含まれてしまっている...(ダメじゃん)
- 5.
VAEの秘策:ELBO
• log 𝑝(𝑋)は次のように分解できる:
log 𝑝 𝑋 =
log 𝑝 𝜃(𝑋|𝑍) 𝑞 𝜙(𝑍|𝑋) − 𝐷 𝐾𝐿 𝑞 𝜙(𝑍|𝑋)||𝑝 𝑍 + 𝐷 𝐾𝐿 𝑞 𝜙(𝑍|𝑋)||𝑝 𝜃 𝑍|𝑋
• ここで,𝑞 𝜙(𝑍|𝑋)はVAEの秘策のために導入された全く別の確率分布.
• もし, 𝑞 𝜙 𝑍 𝑋 = 𝑝 𝜃 𝑍|𝑋 になったとき, 𝐷 𝐾𝐿 𝑞 𝜙(𝑍|𝑋)||𝑝 𝜃 𝑍|𝑋 =0
• もし,𝑞 𝜙 𝑍 𝑋 = 𝑝 𝜃 𝑍|𝑋 でないとき,常に𝐷 𝐾𝐿 𝑞 𝜙(𝑍|𝑋)||𝑝 𝜃 𝑍|𝑋 > 0
• したがって,常に
log 𝑝 𝜃(𝑋|𝑍) 𝑞 𝜙(𝑍|𝑋) − 𝐷 𝐾𝐿 𝑞 𝜙(𝑍|𝑋)||𝑝 𝑍 ≤ log 𝑝 𝑋
(左項がlog 𝑝 𝑋 の下界になっている!)
• 左側の項を最大化すれば, log 𝑝 𝑋 も最大化されるのでは...?
• 𝐿ELBO = log 𝑝 𝜃(𝑋|𝑍) 𝑞 𝜙(𝑍|𝑋) − 𝐷 𝐾𝐿 𝑞 𝜙(𝑍|𝑋)||𝑝 𝑍
を最大化するのが,ELBO型VAE.(ELBO:Evidence Lower Bound)
- 6.
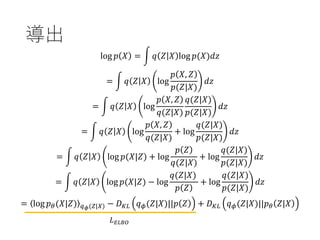
導出
log 𝑝 𝑋= න 𝑞 𝑍 𝑋 log 𝑝(𝑋)𝑑𝑧
= න 𝑞 𝑍 𝑋 log
𝑝 𝑋, 𝑍
𝑝(𝑍|𝑋)
𝑑𝑧
= න 𝑞 𝑍 𝑋 log
𝑝 𝑋, 𝑍
𝑞(𝑍|𝑋)
𝑞(𝑍|𝑋)
𝑝(𝑍|𝑋)
𝑑𝑧
= න 𝑞 𝑍 𝑋 log
𝑝 𝑋, 𝑍
𝑞(𝑍|𝑋)
+ log
𝑞(𝑍|𝑋)
𝑝(𝑍|𝑋)
𝑑𝑧
= න 𝑞 𝑍 𝑋 log 𝑝(𝑋|𝑍) + log
𝑝 𝑍
𝑞(𝑍|𝑋)
+ log
𝑞(𝑍|𝑋)
𝑝(𝑍|𝑋)
𝑑𝑧
= න 𝑞 𝑍 𝑋 log 𝑝(𝑋|𝑍) − log
𝑞(𝑍|𝑋)
𝑝 𝑍
+ log
𝑞(𝑍|𝑋)
𝑝(𝑍|𝑋)
𝑑𝑧
= log 𝑝 𝜃(𝑋|𝑍) 𝑞 𝜙(𝑍|𝑋) − 𝐷 𝐾𝐿 𝑞 𝜙(𝑍|𝑋)||𝑝 𝑍 + 𝐷 𝐾𝐿 𝑞 𝜙(𝑍|𝑋)||𝑝 𝜃 𝑍|𝑋
𝐿 𝐸𝐿𝐵𝑂
- 7.
ELBO型VAEの実装法
• 𝐿ELBO =log 𝑝 𝜃(𝑋|𝑍) 𝑞 𝜙(𝑍|𝑋) − 𝐷 𝐾𝐿 𝑞 𝜙(𝑍|𝑋)||𝑝 𝑍
を最大化
• 左項:𝑋 𝑖があって,分布qによって𝑍 𝑖に変換したものを,
分布pで𝑋′𝑖
に変換される確率(を高める)
→復元誤差についての項(復元誤差を小さく)
(左項のみ:AUTOENCODER)
• 右項:どんな𝑋 𝑖
から分布qによって得られる𝑍 𝑖
の分布も, 𝑝 𝑍 に近づかなければならない
→隠れ変数Zの分布を保証するための項
X Z X’
近づける 固定の分布に
積分が入らないので,
勾配法で解けます.
やったね.
- 8.
- 9.
- 10.
Z-X間の相互情報量が失われる
問題
• 𝐿ELBOは次の形に書き換えられる.
• 𝐿ELBO= −⟨𝐷 𝐾𝐿 𝑞 𝜙 𝑍 𝑋 𝑝 𝜃 𝑍 𝑋
𝑝 𝑅 𝑋
− 𝐷 𝐾𝐿 (𝑝 𝑅 (𝑋)||𝑝 𝜃 (𝑋))
ここで,𝑝 𝜃(𝑋)が十分に複雑な表現力を持てた場合,𝑝 𝑅(𝑋)を十
分近似できるため,右項はゼロになる.
そのとき,ELBOは
⟨𝐷 𝐾𝐿 𝑞 𝜙 𝑍 𝑋 𝑝 𝜃 𝑍 𝑋
𝑝 𝑅 𝑋
= 0
のとき最大となる.
• しかしながら, ⟨𝐷 𝐾𝐿 𝑞 𝜙 𝑍 𝑋 𝑝 𝜃 𝑍 𝑋
𝑝 𝑅 𝑋
は, 𝑍と𝑋の相
互情報量がゼロ,すなわち𝑍を知ることで𝑋の情報が得られな
い,というときにゼロとなってしまう.
→潜在変数Zとはなんだったのか...
大問題
- 11.
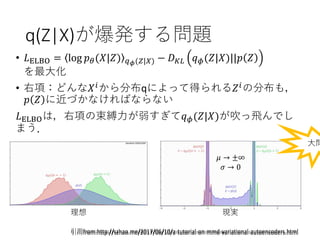
q(Z|X)が爆発する問題
• 𝐿ELBO =log 𝑝 𝜃(𝑋|𝑍) 𝑞 𝜙(𝑍|𝑋) − 𝐷 𝐾𝐿 𝑞 𝜙(𝑍|𝑋)||𝑝 𝑍
を最大化
• 右項:どんな𝑋 𝑖
から分布qによって得られる𝑍 𝑖
の分布も,
𝑝 𝑍 に近づかなければならない
𝐿ELBOは,右項の束縛力が弱すぎて𝑞 𝜙(𝑍|𝑋)が吹っ飛んでし
まう.
理想 現実
引用from:http://szhao.me/2017/06/10/a-tutorial-on-mmd-variational-autoencoders.html
大問
𝜇 → ±∞
𝜎 → 0
引用from:http://szhao.me/2017/06/10/a-tutorial-on-mmd-variational-autoencoders.html
- 12.

![[pre]VAEとは何がしたいのか
• データ𝐷 = (𝑋 𝑖
, 𝑖 = 1, … , 𝑁)があります.
• 𝐷から生成モデル(generative model)を作りたい.
→生成モデルとは: 𝑋の母集団の確率分布𝑝 𝑅 𝑋 のこと.
または,𝑝 𝑅 𝑋 からサンプリングできる装置のこと.
• (有限の)𝐷からどうやって作るか→尤度最大化!
• 尤度最大化とは:
𝜃でパラメトライズされた確率分布 𝑝 𝜃(𝑋)を
𝐷を用いて𝑝 𝑅 𝑋 に近づけるためには, 𝜃を
𝜃 = argmax
𝜃
ෑ
𝑖
𝑝 𝜃(𝑋 𝑖)
とすればよいという考え方のこと(を尤度最大化という).
データ𝐷がサンプリング
される確率を高くする
という意味](https://image.slidesharecdn.com/elbodame-180516122610/85/ELBO-VAE-2-320.jpg)




![ELBO型VAEについて
ELBO型VAEの問題点として,論文[1]は
1. Z-X間の相互情報量が失われる問題
2. q(Z|X)が爆発する問題
の2つを挙げている.
これらの問題について簡単に述べる
[1]Zhao, Shengjia, Jiaming Song, and Stefano Ermon. "Infovae: Information maximizing variational
autoencoders." arXiv preprint arXiv:1706.02262 (2017).](https://image.slidesharecdn.com/elbodame-180516122610/85/ELBO-VAE-9-320.jpg)

![ではこれら問題を解決するには
• これらの問題に関して、InfoVAE [1]では真に驚
くべき解決法を提案したが、45分でそれを発表
するには短すぎる.
→ [1]の論文を参照のこと(丸投げ)
[1]Zhao, Shengjia, Jiaming Song, and Stefano Ermon. "Infovae: Information maximizing
variational autoencoders." arXiv preprint arXiv:1706.02262 (2017).](https://image.slidesharecdn.com/elbodame-180516122610/85/ELBO-VAE-12-320.jpg)