Downloaded 31 times

![Outline
• Deep Fakesの種類
• Deep Fakesの検出法
• とりあえず [1,2] を読んだくらいで網羅性は保証しません
• [1] はアプローチが面白い、[2] は抑えておくべき論文
([2]の著者の研究室は長年この分野をやっている
http://www.niessnerlab.org/publications.html )
2
[1] S. Agarwal, et al., "Protecting World Leaders Against Deep Fakes," in Proc. of CVPR
Workshop on Media Forensics, 2019.
[2] A. Rossler, et al., "FaceForensics++: Learning to Detect Manipulated Facial Images," in Proc.
of ICCV, 2019.](https://image.slidesharecdn.com/20191213deepfakedetection-191213132838/75/Deep-Fakes-Detection-2-2048.jpg)
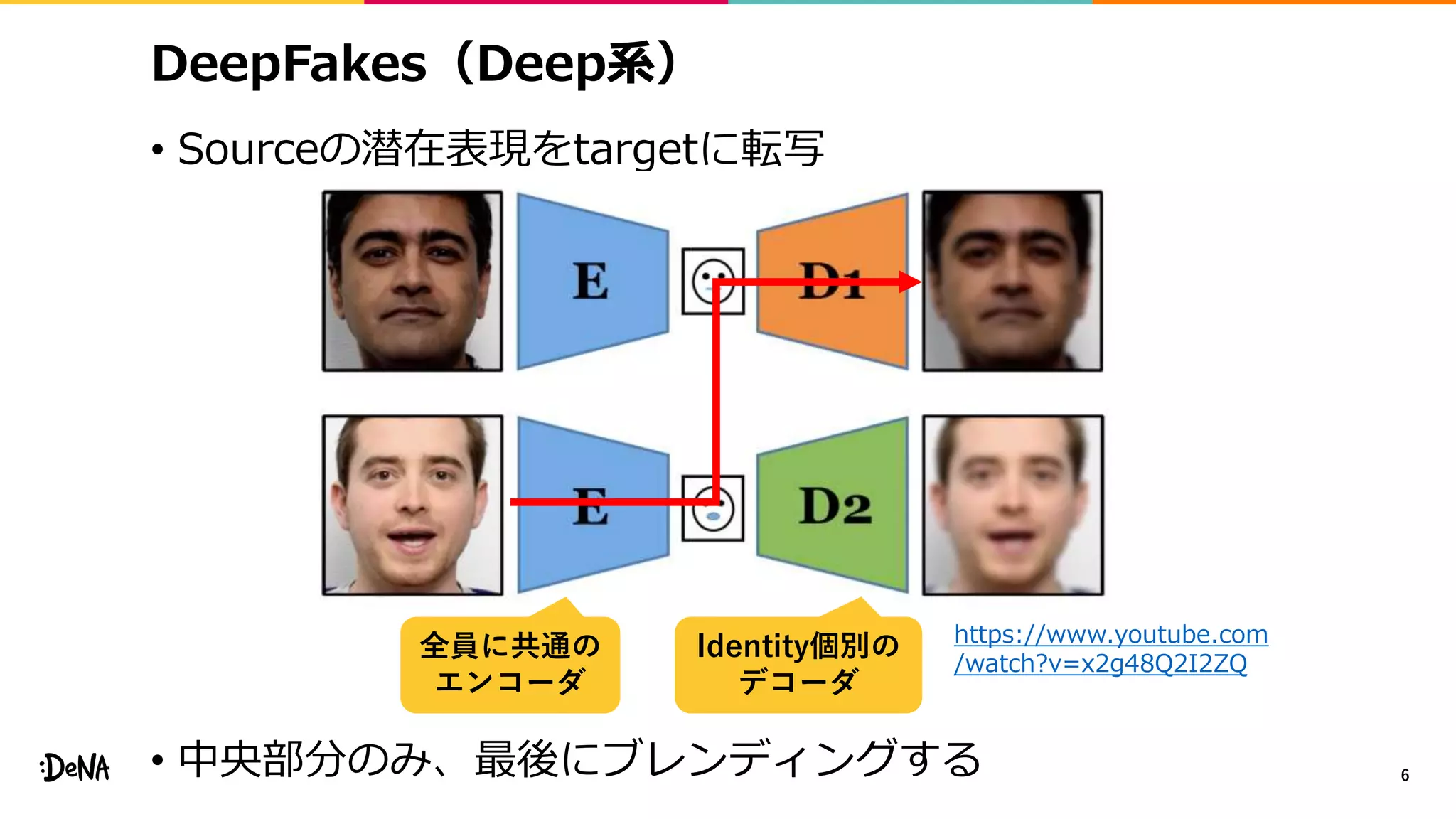
![Deep Fakesの種類 (1/2)
• [1] ではAI-synthesized mediaとも呼んでいる
• Deep fakesを3種類に分類
• face-swap
• 動画中の顔を別人に入れ替える
• lip-sync
• 口の領域を任意の音声に合うように変換する
• puppet-master
• 対象人物の顔、表情、視線をコントロールする
3
[1] S. Agarwal, et al., "Protecting World Leaders Against Deep Fakes," in Proc. of CVPR
Workshop on Media Forensics, 2019.](https://image.slidesharecdn.com/20191213deepfakedetection-191213132838/75/Deep-Fakes-Detection-3-2048.jpg)
![Deep Fakesの種類 (2/2)
• [2] ではより具体的な手法を参照している
• FaceSwap
• https://github.com/MarekKowalski/FaceSwap/
• DeepFakes
• https://github.com/deepfakes/faceswap
• Face2Face [3]
• NeuralTextures [4]
4
[2] A. Rossler, et al., "FaceForensics++: Learning to Detect Manipulated Facial Images," in Proc.
of ICCV, 2019.
[3] J. Thies, et al., "Face2Face: Realtime Face Capture and Reenactment of RGB Videos," in Proc.
of CVPR, 2016.
[4] J. Thies, et al., "Deferred Neural Rendering: Image Synthesis Using Neural Textures," in
ACM TOG, 2019.](https://image.slidesharecdn.com/20191213deepfakedetection-191213132838/75/Deep-Fakes-Detection-4-2048.jpg)



![Deep fake検出手法 (1/3)
• まばたきの情報を利用 [5] (目の領域にCNN-LSTM)
• 初期のGANベースのdeep fakeはまばたきしない(学習
データに目つむりのものがない)→ でもすぐに
まばたきするように
• 顔の輪郭のlandmarkと、
顔の中心のlandmarkから
推測される顔向きの
整合性を利用 [6]
9
[5] Y. Li, et al., "In Ictu Oculi: Exposing AI Created Fake Videos by Detecting Eye Blinking," in Proc.
of WIFS, 2018.
[6] X. Yang, et al., "Exposing Deep Fakes Using Inconsistent Head Poses," in Proc of ICASSP, 2019.](https://image.slidesharecdn.com/20191213deepfakedetection-191213132838/75/Deep-Fakes-Detection-9-2048.jpg)
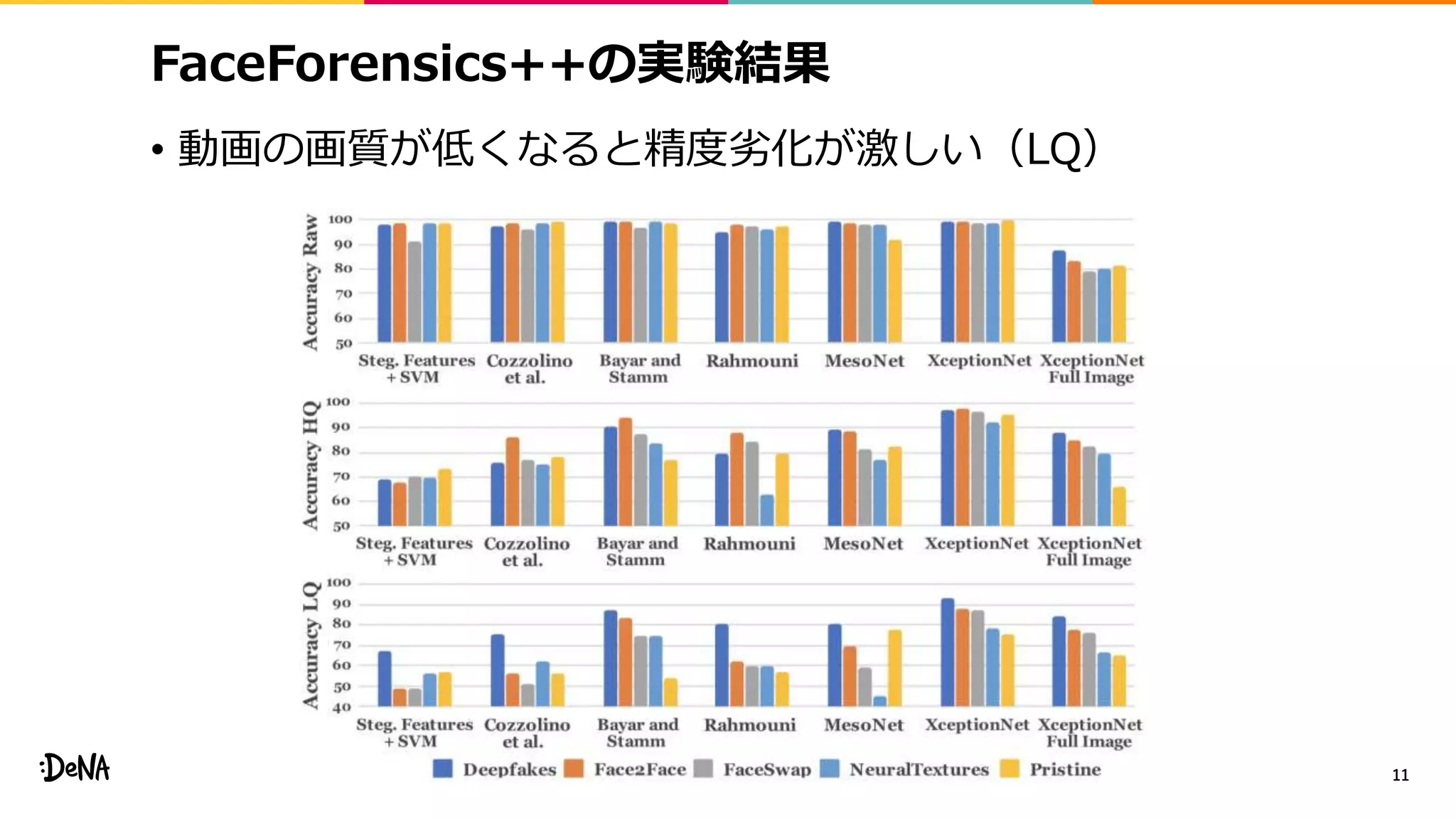
![Deep fake検出手法 (2/3)
• Domain-specific forgery detection [2]
• 顔領域をcropしてclassificationするだけ
• [2] の一番の貢献はデータセットの構築なので…
10
[2] A. Rossler, et al., "FaceForensics++: Learning to Detect Manipulated Facial Images," in Proc.
of ICCV, 2019.](https://image.slidesharecdn.com/20191213deepfakedetection-191213132838/75/Deep-Fakes-Detection-10-2048.jpg)
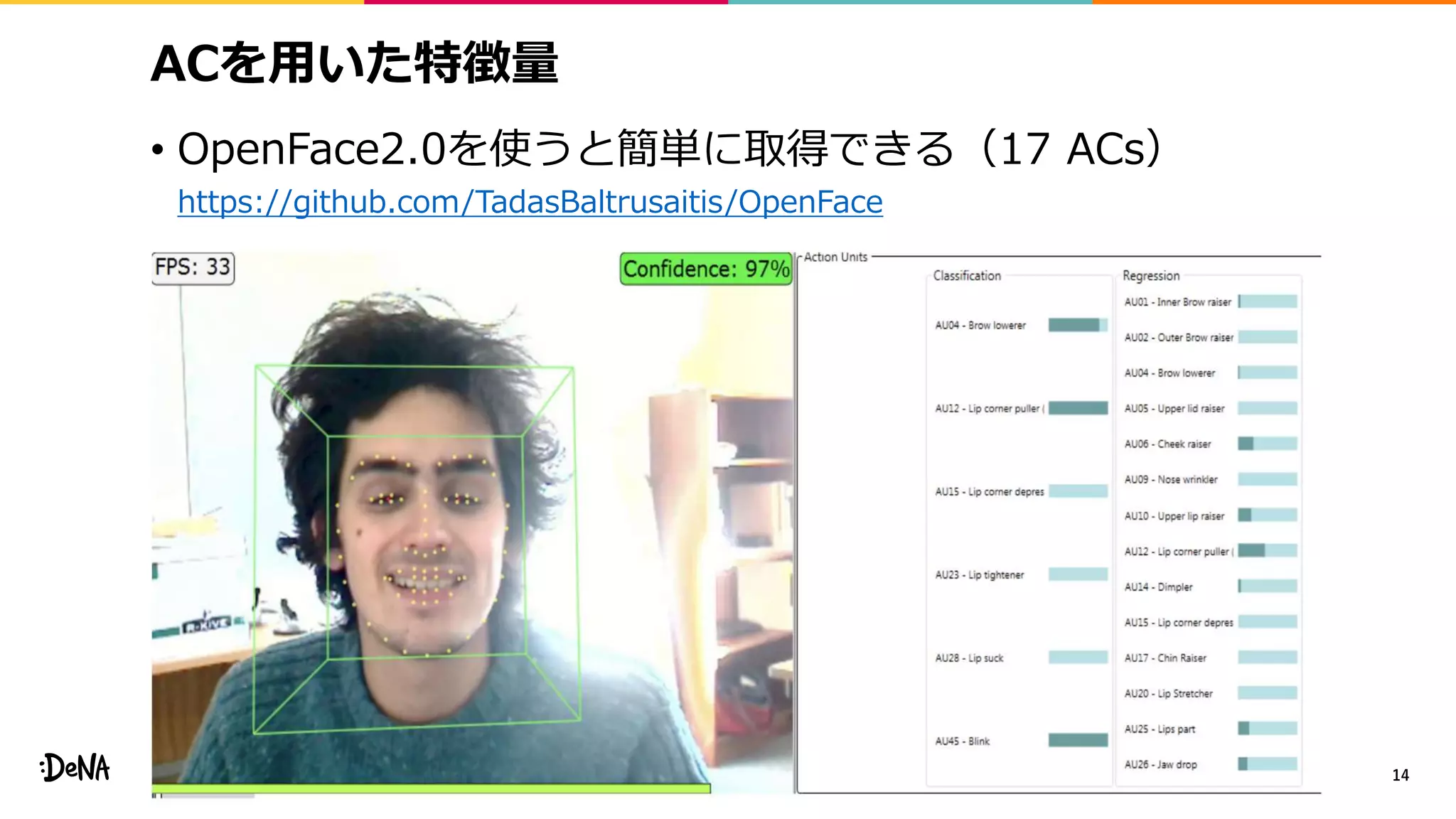
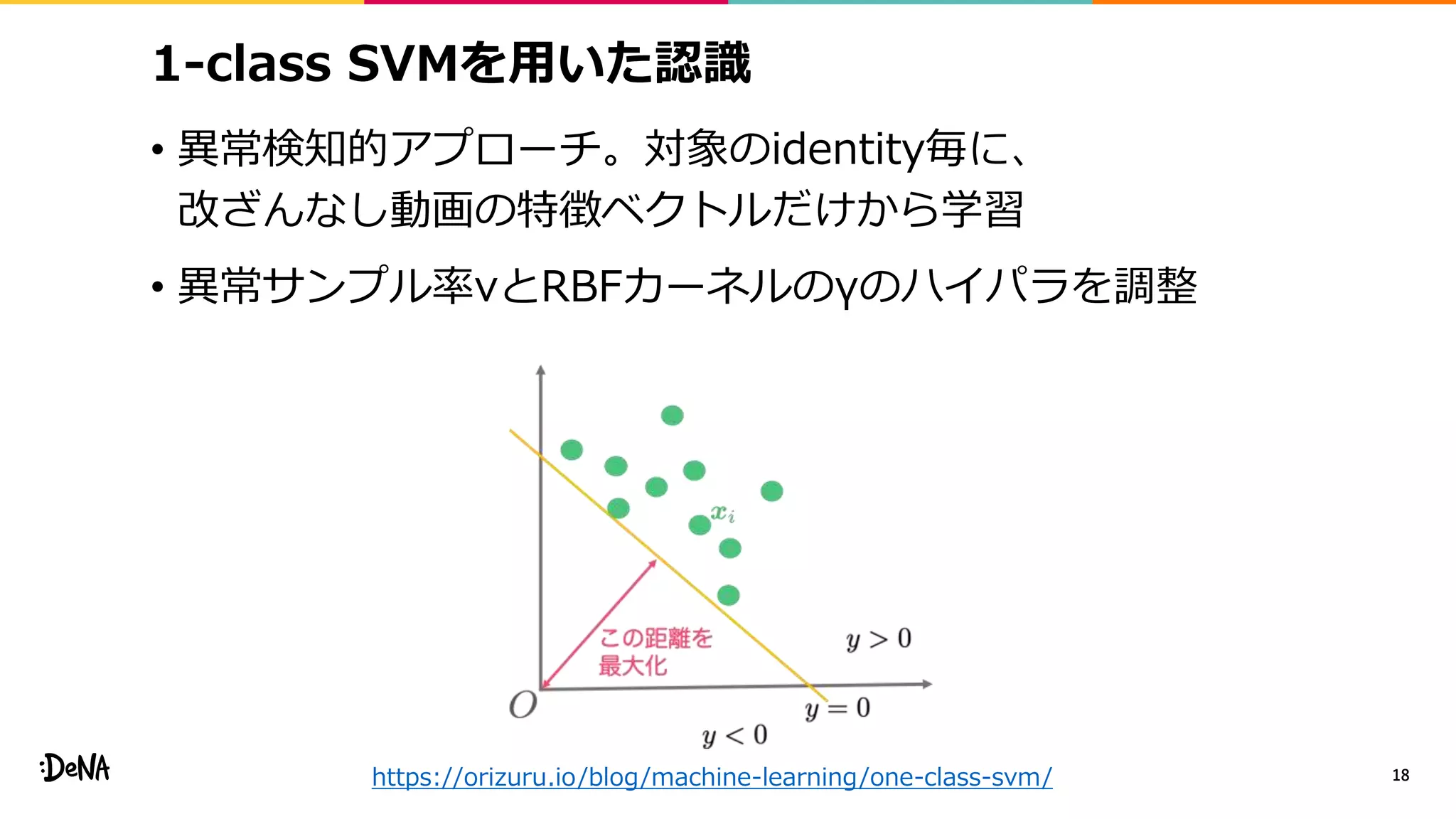
![Deep fake検出手法 (3/3)
• Action Unitの相関を特徴量にして異常検知的に解く [1]
• これまでの手法は、事前情報なく、単に画像や動画が
与えられた場合にその真贋を判定するタスクを解いていた
• [1] の手法は、特定のidentityの動画と分かっている場合
にそれの真贋を判定する手法
12
[1] S. Agarwal, et al., "Protecting World Leaders Against Deep Fakes," in Proc. of
CVPR Workshop on Media Forensics, 2019.](https://image.slidesharecdn.com/20191213deepfakedetection-191213132838/75/Deep-Fakes-Detection-12-2048.jpg)




DeNA AIシステム部内の輪講で発表した資料です。Deep fakesの種類やその検出法の紹介です。 主に下記の論文の紹介 S. Agarwal, et al., "Protecting World Leaders Against Deep Fakes," in Proc. of CVPR Workshop on Media Forensics, 2019. A. Rossler, et al., "FaceForensics++: Learning to Detect Manipulated Facial Images," in Proc. of ICCV, 2019.


![[DL輪読会]SOM-VAE: Interpretable Discrete Representation Learning on Time Series](https://cdn.slidesharecdn.com/ss_thumbnails/190118nonakadlhacks-190118005053-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]EfficientDet: Scalable and Efficient Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/191122dlseminar-191122013544-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DeepLearning論文読み会] Dataset Distillation](https://cdn.slidesharecdn.com/ss_thumbnails/datasetdistillation-181114165952-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]SlowFast Networks for Video Recognition](https://cdn.slidesharecdn.com/ss_thumbnails/20191206slowfastnetworkkuboshizuma-191206010601-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]High-Quality Self-Supervised Deep Image Denoising](https://cdn.slidesharecdn.com/ss_thumbnails/high-qualityself-superviseddeepimagedenoising-200501014639-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators](https://cdn.slidesharecdn.com/ss_thumbnails/stylegan-nada-210813013304-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]FaceForensics++: Learning to Detect Manipulated Facial Images](https://cdn.slidesharecdn.com/ss_thumbnails/faceforensics-191004003836-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Face Recognition: A Survey](https://cdn.slidesharecdn.com/ss_thumbnails/20181221-181221023935-thumbnail.jpg?width=640&height=640&fit=bounds)











![[IBIS2017 講演] ディープラーニングによる画像変換](https://cdn.slidesharecdn.com/ss_thumbnails/ibis2017iizuka-171120134119-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning](https://cdn.slidesharecdn.com/ss_thumbnails/slidev2reduced-190422065109-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)



































