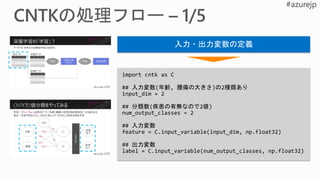
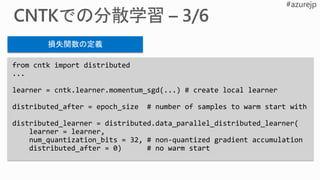
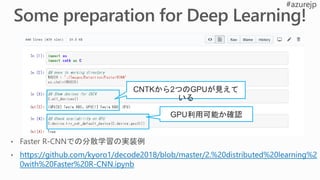
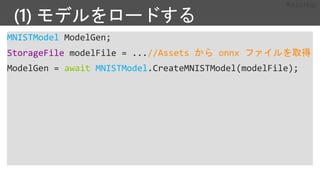
from cntk importdistributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 32, # non-quantized gradient accumulation
distributed_after = 0) # no warm start
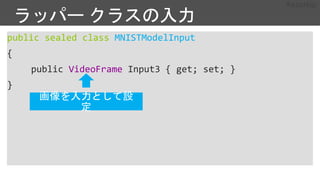
損失関数の定義
21.
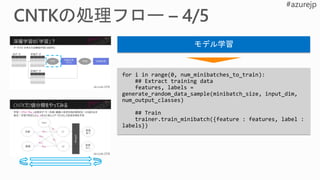
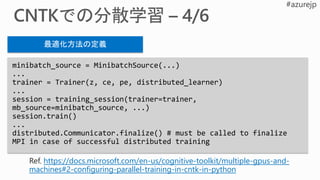
minibatch_source = MinibatchSource(...)
...
trainer= Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer,
mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize
MPI in case of successful distributed training
最適化方法の定義
https://docs.microsoft.com/en-us/cognitive-toolkit/multiple-gpus-and-
machines#2-configuring-parallel-training-in-cntk-in-python
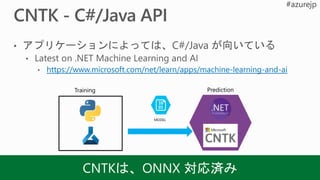
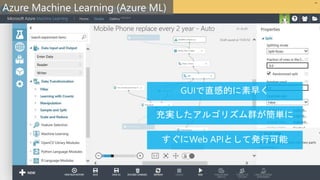
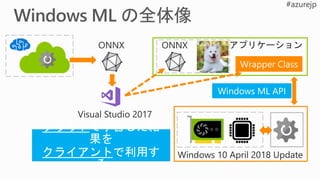
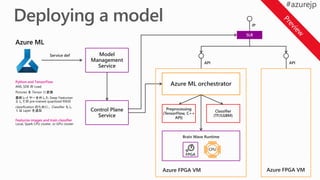
Azure ML integration
デプロイまでを含んだモデル ライフサイクル管理
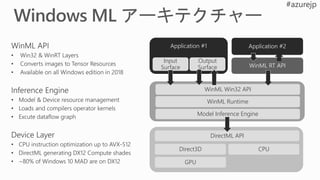
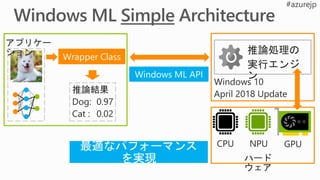
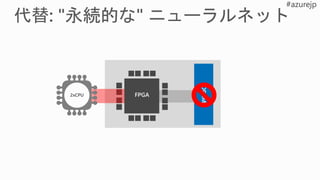
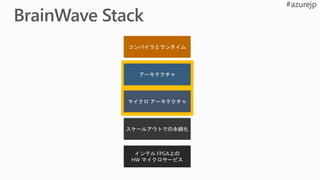
Hardware Accelerated
Model Gallery
Brainwave
Compiler & Runtime
“Brainslice” Soft
Neural Processing Unit
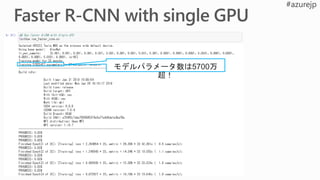
63.
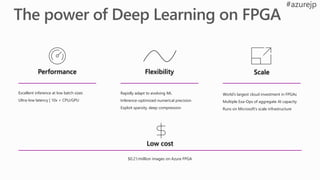
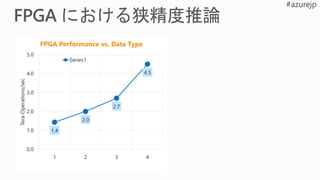
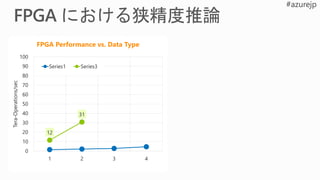
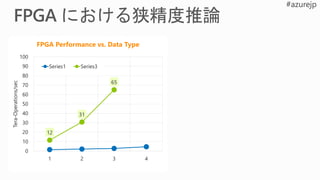
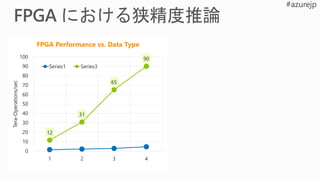
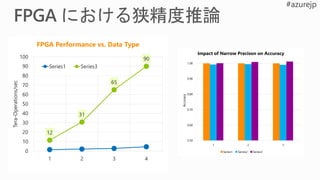
Performance Flexibility Scale
Rapidlyadapt to evolving ML
Inference-optimized numerical precision
Exploit sparsity, deep compression
Excellent inference at low batch sizes
Ultra-low latency | 10x < CPU/GPU
World’s largest cloud investment in FPGAs
Multiple Exa-Ops of aggregate AI capacity
Runs on Microsoft’s scale infrastructure
Low cost
$0.21/million images on Azure FPGA
64.
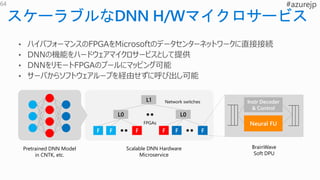
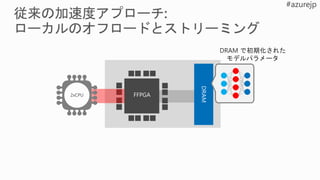
F F F
L0
L1
FF F
L0
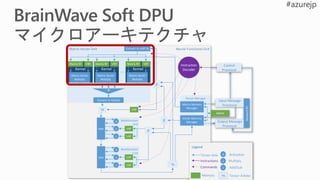
Pretrained DNN Model
in CNTK, etc.
Scalable DNN Hardware
Microservice
BrainWave
Soft DPU
Instr Decoder
& Control
Neural FU
64
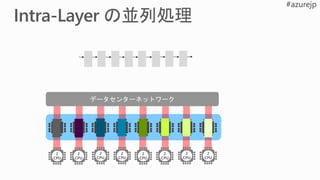
Network switches
FPGAs
65.
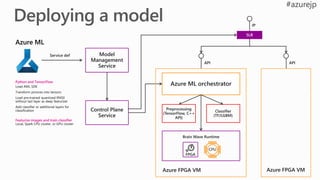
Model
Management
Service
Azure ML orchestratorPythonand TensorFlow
Featurize images and train classifier
Classifier
(TF/LGBM)
Preprocessing
(TensorFlow, C++
API)
Control Plane
Service
Brain Wave Runtime
FPGA
CPU
Web search
ranking
Traditional software(CPU) server plane
QPICPU
QSFP
40Gb/s ToR
FPGA
CPU
40Gb/s
QSFP QSFP
Hardware acceleration plane
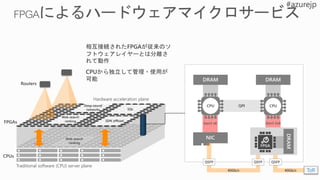
相互接続されたFPGAが従来のソ
フトウェアレイヤーとは分離さ
れて動作
CPUから独立して管理・使用が
可能
Web search
ranking
Deep neural
networks
SDN offload
SQL
CPUs
FPGAs
Routers
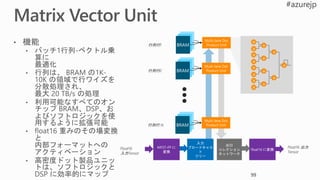
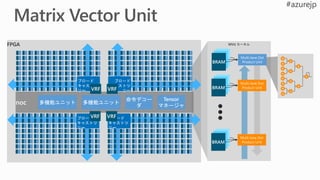
Neural Functional Unit
VRF
Instruction
Decoder
TA
TA
TA
TA
TA
Matrix-VectorUnit Convert to msft-fp
Convert to float16
Multifunction
Unit
xbar x
A
+ VRF
VRF
Multifunction
Unit
xbar x
+ VRF
VRF
Tensor Manager
Matrix Memory
Manager
Vector Memory
Manager
DRAM
x
A
+
Activation
Multiply
Add/Sub
Legend
Memory
Tensor data
Instructions
Commands
TA Tensor Arbiter
Input Message
Processor
Control
Processor
Output Message
Processor
A
Kernel
Matrix Vector
Multiply
VRFMatrix RF
+
Kernel
Matrix Vector
Multiply
VRFMatrix RF
Kernel
Matrix Vector
Multiply
VRFMatrix RF
NetworkIFC
...
Model
Management
Service
Azure ML orchestratorPythonand TensorFlow
Featurize images and train classifier
Classifier
(TF/LGBM)
Preprocessing
(TensorFlow, C++
API)
Control Plane
Service
Brain Wave Runtime
FPGA
CPU
110.
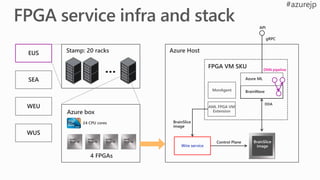
EUS
SEA
WEU
WUS
Stamp: 20 racks
Azurebox
24 CPU cores
4 FPGAs
BrainWave
Azure ML
Wire service
AML FPGA VM
Extension
Azure Host
MonAgent
DNN pipeline








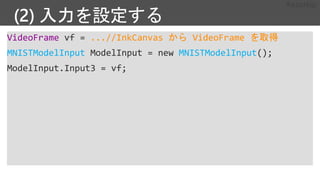
![ネットワークの定義
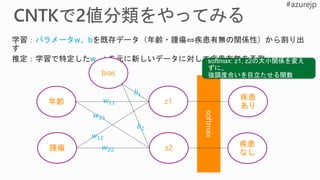
def linear_layer(input_var, output_dim):
input_dim = input_var.shape[0]
## Define weight W
weight_param = C.parameter(shape=(input_dim,
output_dim))
## Define bias b
bias_param = C.parameter(shape=(output_dim))
## Wx + b. Pay attention to the order of variables!!
return bias_param + C.times(input_var, weight_param)
z = linear_layer(input, num_outputs)](https://image.slidesharecdn.com/mfmn62fvts6j7sypnh5q-signature-8e85595b7892db5c3fb860713d633a0f31b999bcb2bc44dec3b2f8ed40493417-poli-180918214750/85/Deep-Learning-6-Library-13-320.jpg)
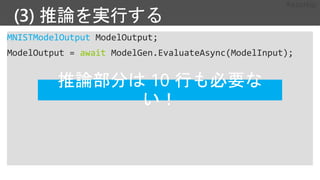
![損失関数、最適化方法の定義
## 損失関数
loss = C.cross_entropy_with_softmax(z, label)
## 分類エラー("分類として"当たっているか否か)
eval_error = C.classification_error(z, label)
## 最適化
learner = C.sgd(z.parameters, lr_schedule)
trainer = C.Trainer(z, (loss, eval_error), [learner])](https://image.slidesharecdn.com/mfmn62fvts6j7sypnh5q-signature-8e85595b7892db5c3fb860713d633a0f31b999bcb2bc44dec3b2f8ed40493417-poli-180918214750/85/Deep-Learning-6-Library-14-320.jpg)


























![A Cloud-Scale Acceleration Architecture [MICRO’16]](https://image.slidesharecdn.com/mfmn62fvts6j7sypnh5q-signature-8e85595b7892db5c3fb860713d633a0f31b999bcb2bc44dec3b2f8ed40493417-poli-180918214750/85/Deep-Learning-6-Library-68-320.jpg)





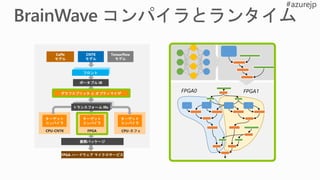
![Pretrained DNN モデル を ソフト DPU にコンパイルするため
の
フレームワーク中立の連合コンパイラとランタイム
狭精度 DNN 推論のための適応型 ISA
高速変化する AI アルゴリズムをサポートする柔軟性と拡張性
BrainWave Soft DPU マイクロアーキテクチャ
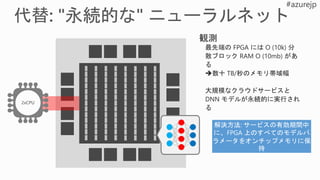
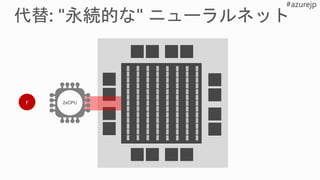
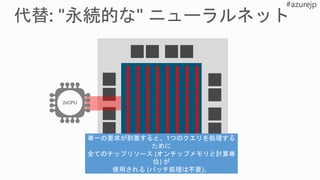
狭精度、低遅延バッチに最適
FPGA 上でモデルパラメータを完全に永続化するオンチップ
メモリは、
多数の FPGA にまたがってスケーリングすることにより、
大規模なモデルをサポート
Intel の FPGA を スケールする HW マイクロサービスに展開
[マイクロ ' 16]](https://image.slidesharecdn.com/mfmn62fvts6j7sypnh5q-signature-8e85595b7892db5c3fb860713d633a0f31b999bcb2bc44dec3b2f8ed40493417-poli-180918214750/85/Deep-Learning-6-Library-74-320.jpg)


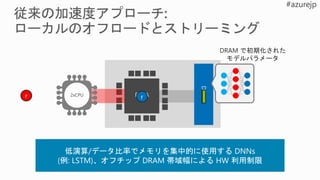
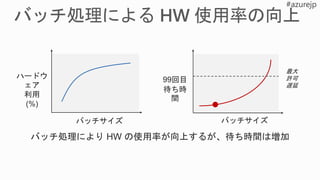
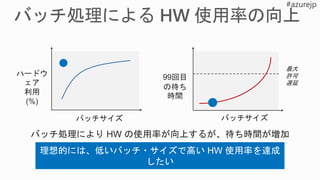












![[基調講演] DLL_RealtimeAI](https://cdn.slidesharecdn.com/ss_thumbnails/dllabdaykeynotesakakibara-180710072423-thumbnail.jpg?width=640&height=640&fit=bounds)











![[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018optimizingdeeplearningwithpfnseiyatokui-181009073509-thumbnail.jpg?width=640&height=640&fit=bounds)






![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)




![[AI05] 目指せ、最先端 AI 技術の実活用!Deep Learning フレームワーク 「Microsoft Cognitive Toolkit 」...](https://cdn.slidesharecdn.com/ss_thumbnails/ai05-170602095345-thumbnail.jpg?width=640&height=640&fit=bounds)














![[第2版]Python機械学習プログラミング 第15章](https://cdn.slidesharecdn.com/ss_thumbnails/15-190318023254-thumbnail.jpg?width=640&height=640&fit=bounds)



















