DEEP LEARNING JP[DL Papers]
“YOLO9000: Better, Faster, Stronger” (CVPR’17 Best Paper)
And the History of Object Detection
Makoto Kawano, Keio University
http://deeplearning.jp/
1
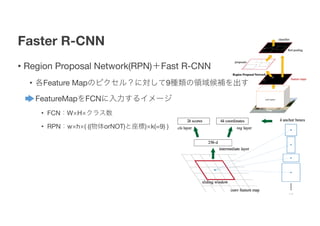
2.
書誌情報
• CVPR2017 BestPaper Award
• Joseph Redmon, Ali Farhadi(ワシントン大学)
• 選定理由:
• YOLOという前バージョン(同じ著者たち+α)の存在を知っていた
• バージョンアップして,ベストペーパーに選ばれたことを耳にしたから
• この論文を中心に物体検出の歴史みたいなものを話します
• R-CNN(2014)~Mask R-CNN(2017)
• R-CNN, SPPNet, Fast R-CNN, Faster R-CNN, YOLO, SSD, YOLO9000, (Mask R-CNNのさわりだけ)
• ほとんど触れたことがない分野で,宣言したことをものすごく後悔
• 結構独断と偏見に満ち溢れているので,間違ってたら指摘お願いします
2
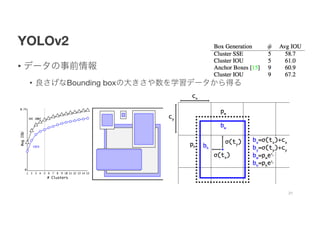
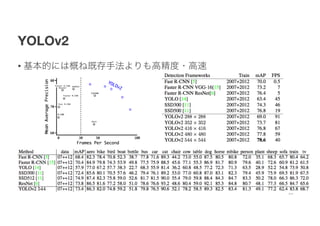
YOLOv2
• アーキテクチャの工夫
• ①全Conv層にBatchNormalizationを入れる
• 収束を速くし,正則化の効果を得る
• ②新しい構造Darknet-19にする
• VGG16のように3×3のフィルタサイズ
• Network In NetworkのGlobal Average Poolingを使う
• ③Passthroughを入れる(わからない)
• add a passthrough layer from the final 3 × 3 × 512
layer to the second to last convolutional layer
20
![DEEP LEARNING JP [DL Papers]
“YOLO9000: Better, Faster, Stronger” (CVPR’17 Best Paper)
And the History of Object Detection
Makoto Kawano, Keio University
http://deeplearning.jp/
1](https://image.slidesharecdn.com/dlreadingpaper20170804-170803075138/85/DL-YOLO9000-Better-Faster-Stronger-1-320.jpg)







![Region Proposal Methods
• Selective Search[]やEdgeBoxes[]など いずれも計算量が膨大
• SSの場合,ピクセルレベルで類似する領域をグルーピングしていく
• 似たような特徴を持つ領域を結合していき、1つのオブジェクトとして抽出する
9](https://image.slidesharecdn.com/dlreadingpaper20170804-170803075138/85/DL-YOLO9000-Better-Faster-Stronger-9-320.jpg)















![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...](https://cdn.slidesharecdn.com/ss_thumbnails/20210729kokiyamane-210730035349-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL Hacks]Semantic Instance Segmentation with a Discriminative Loss Function](https://cdn.slidesharecdn.com/ss_thumbnails/taniai20180528-180528084124-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/200515dlseminar-200515082345-thumbnail.jpg?width=640&height=640&fit=bounds)











































