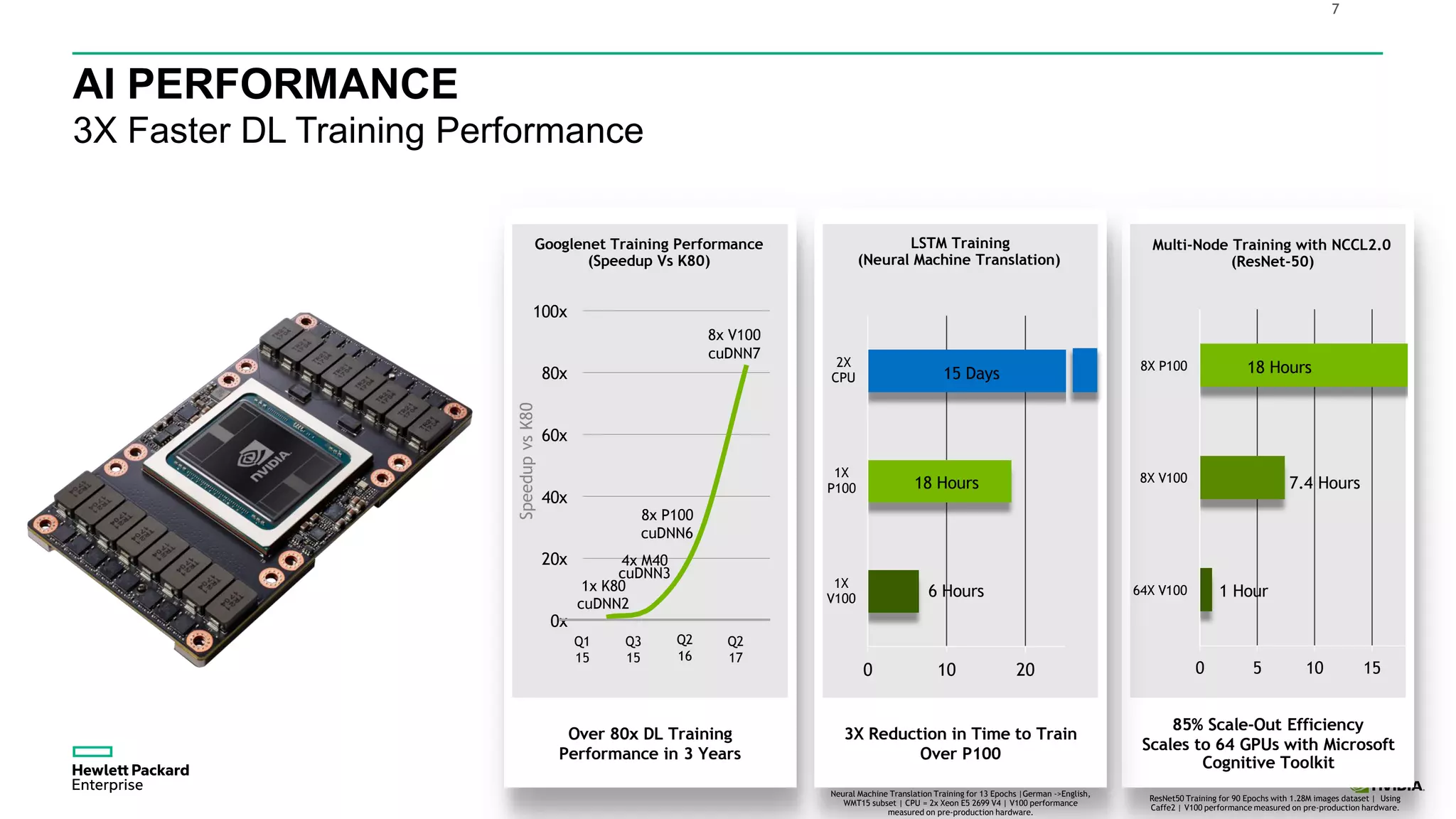
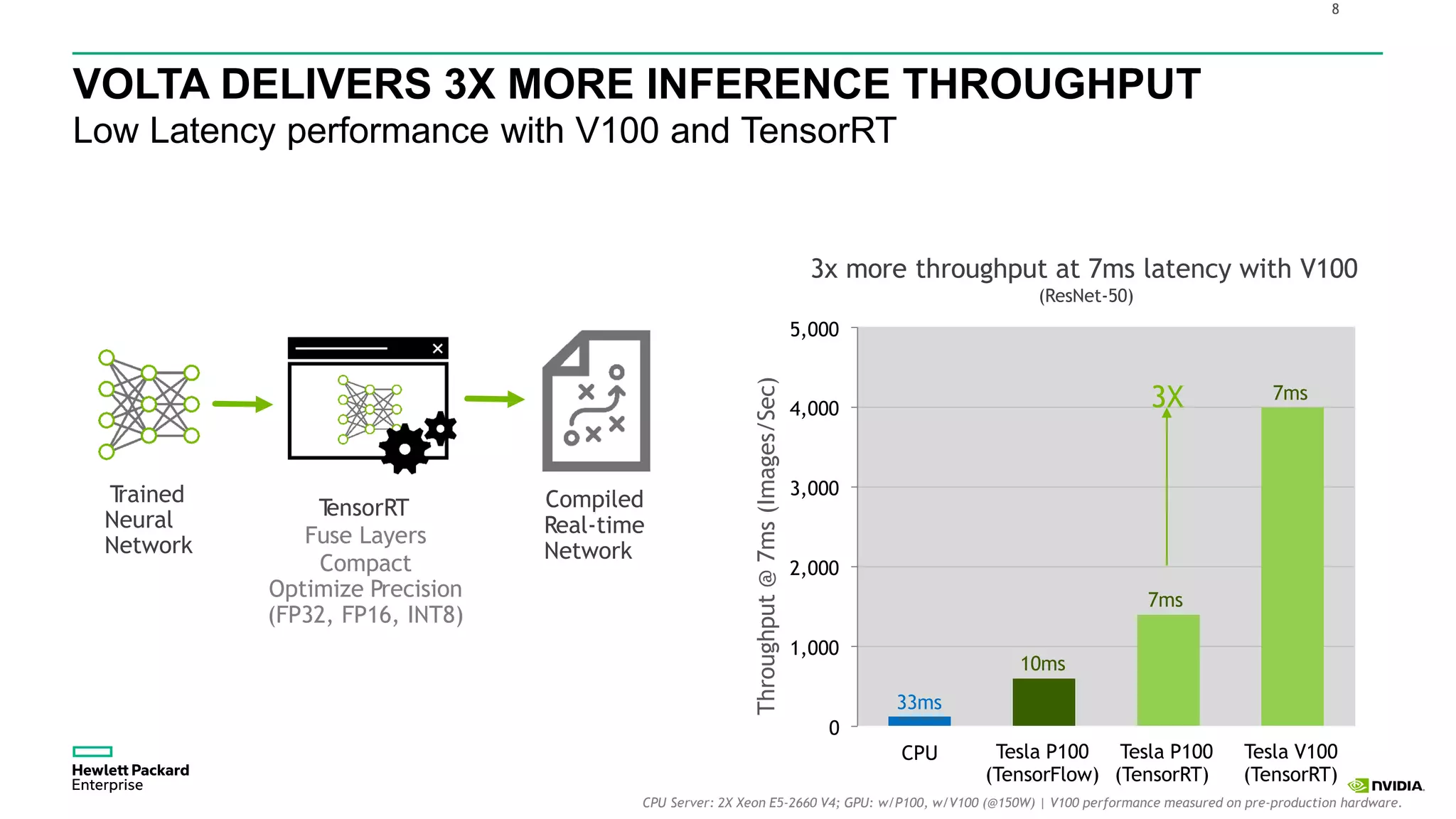
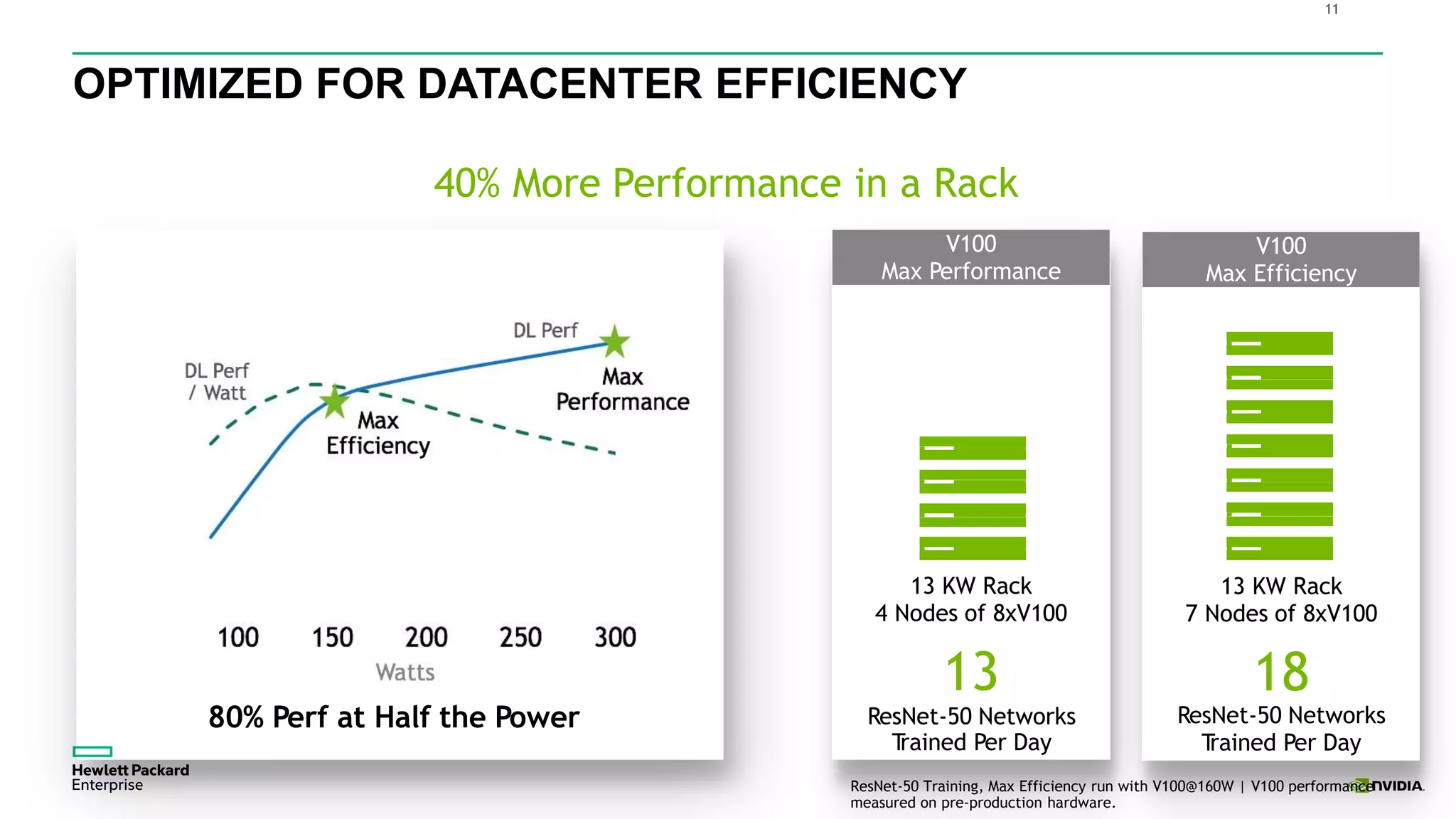
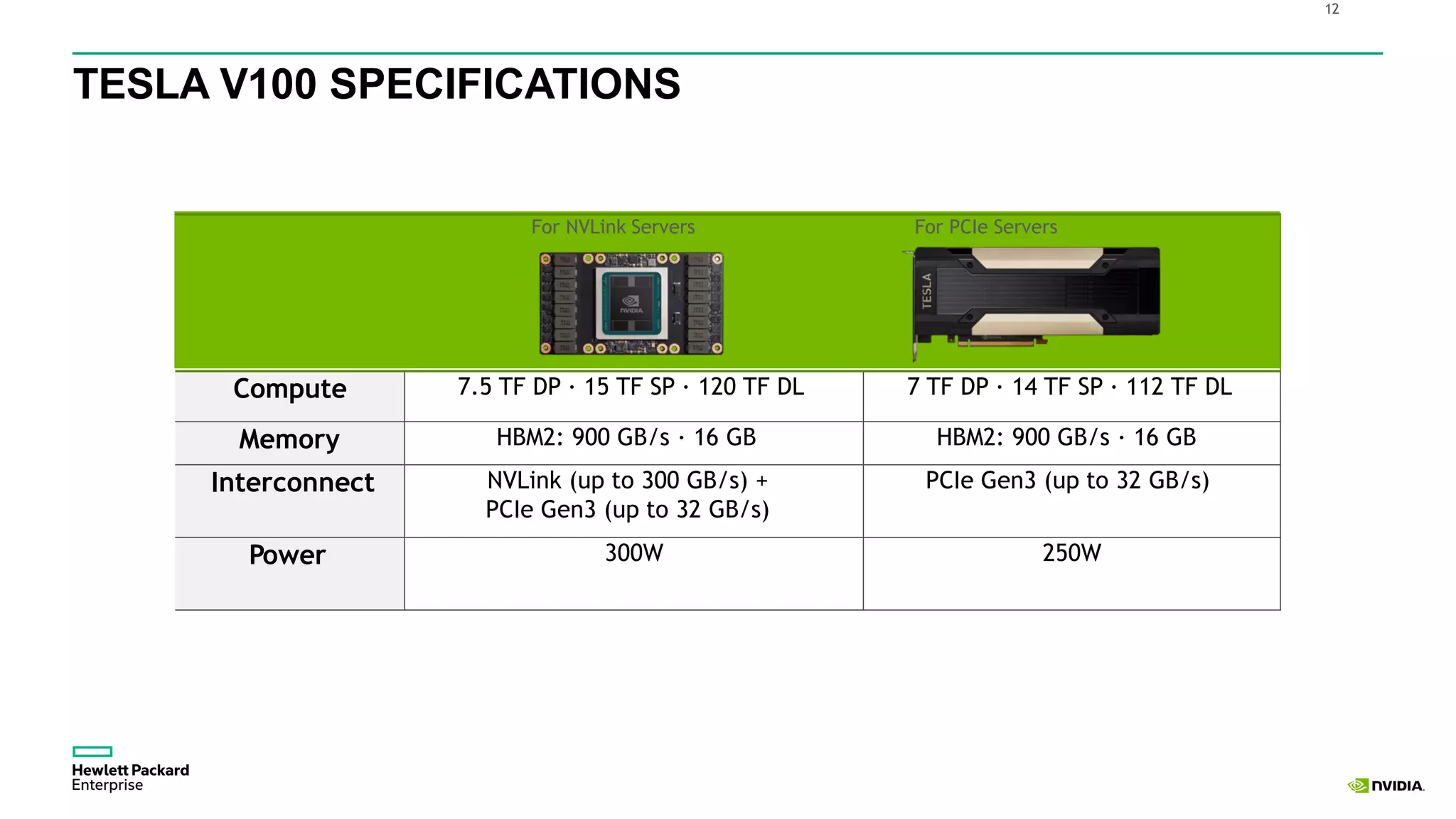
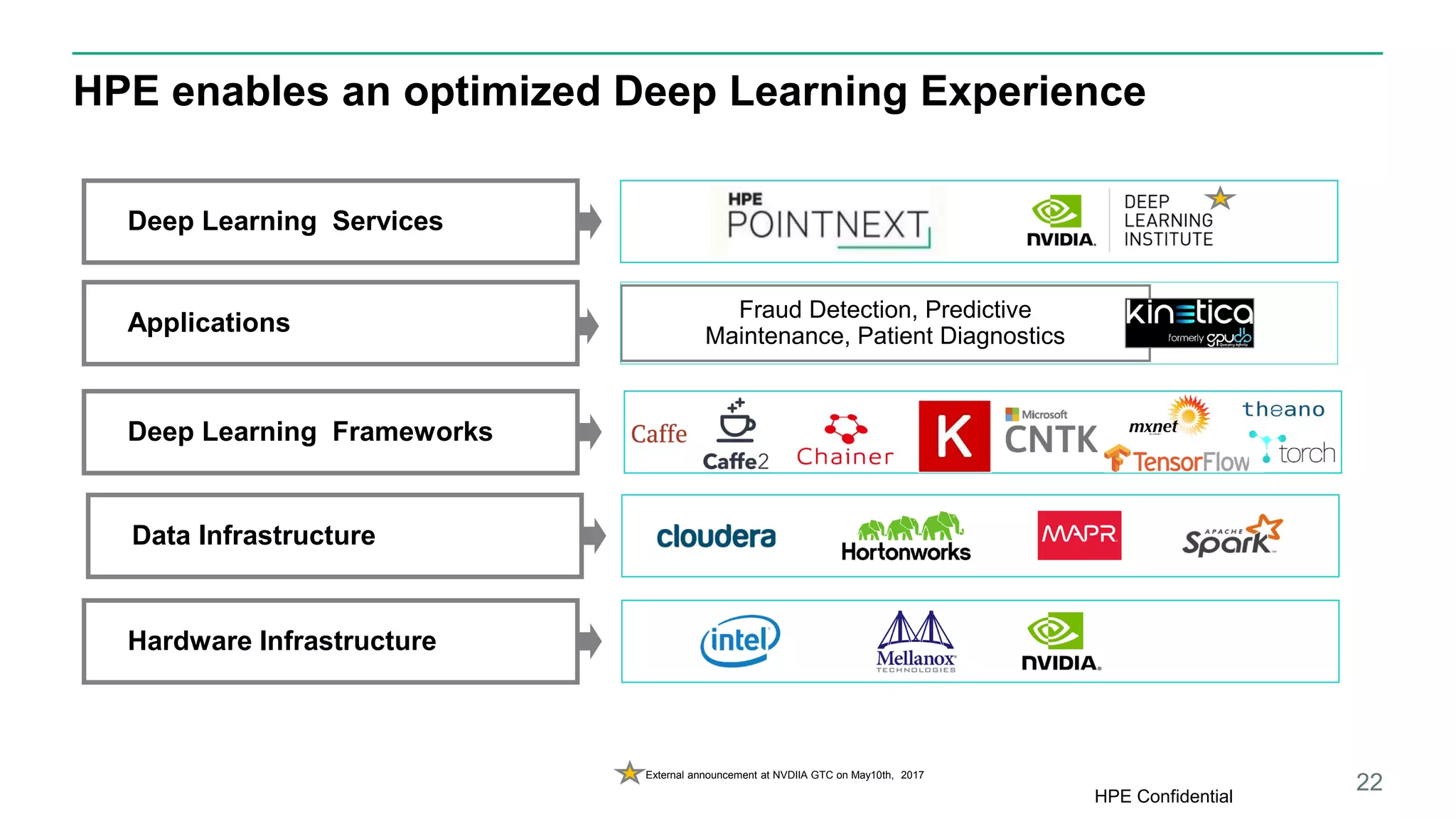
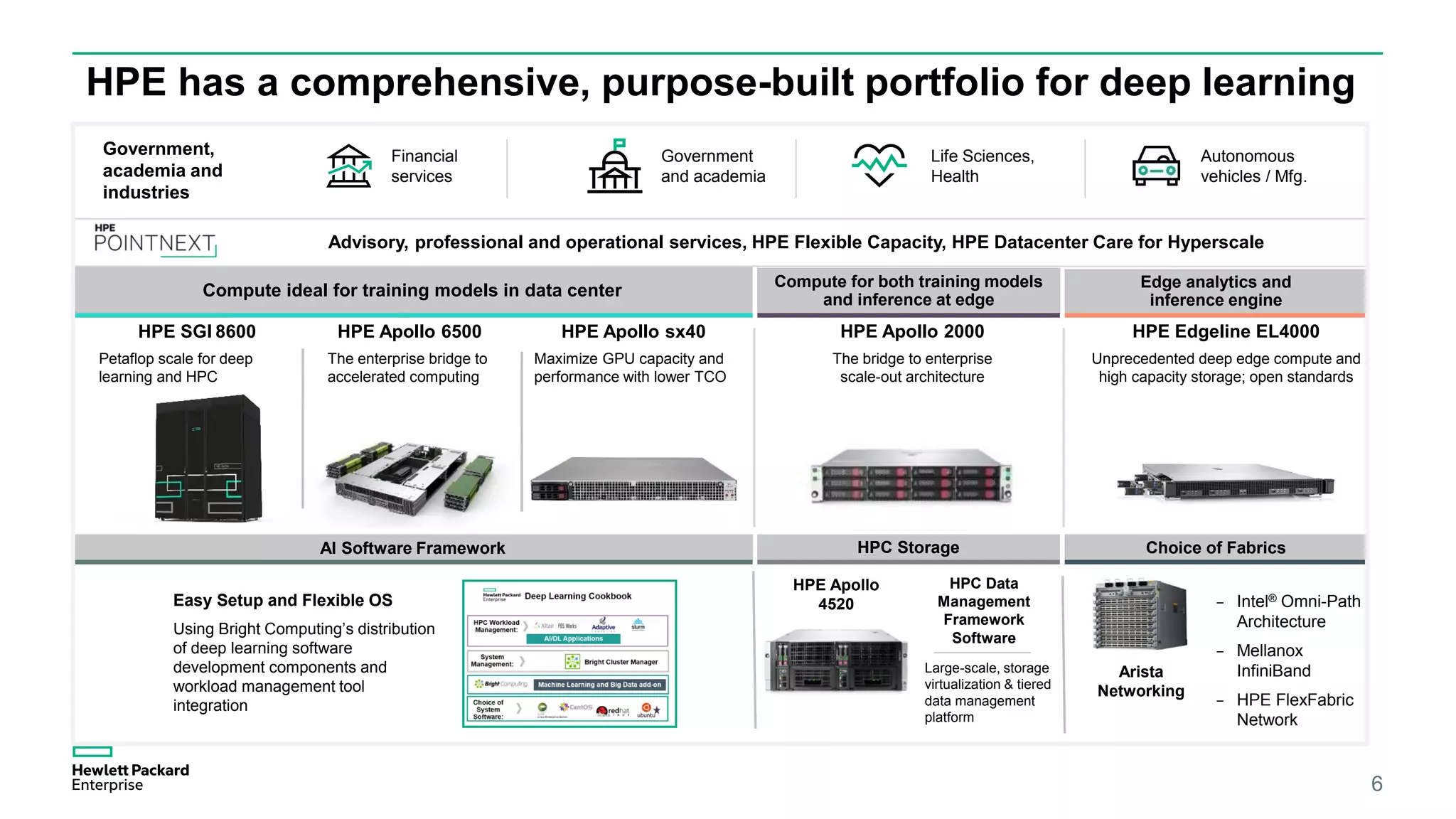
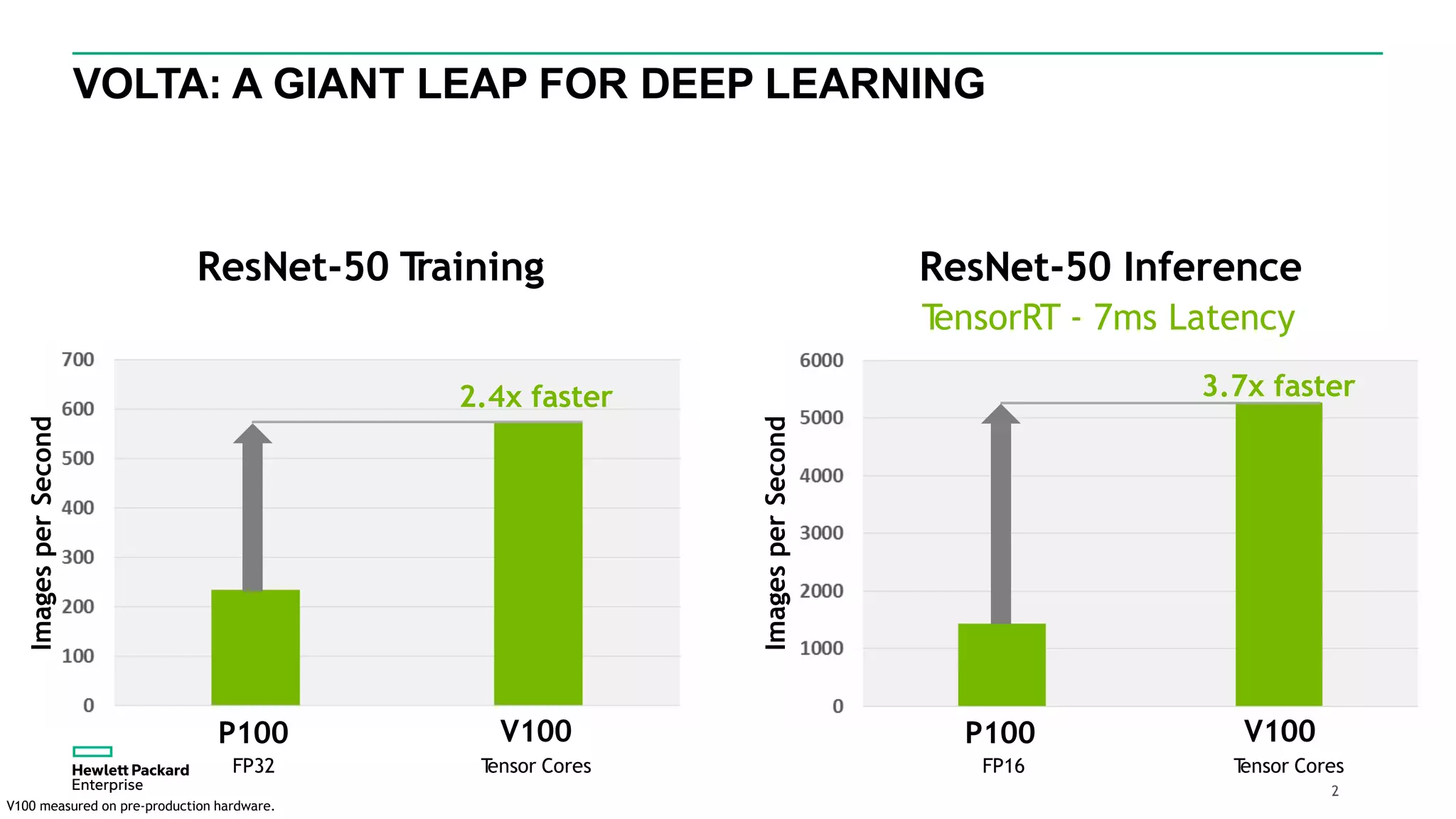
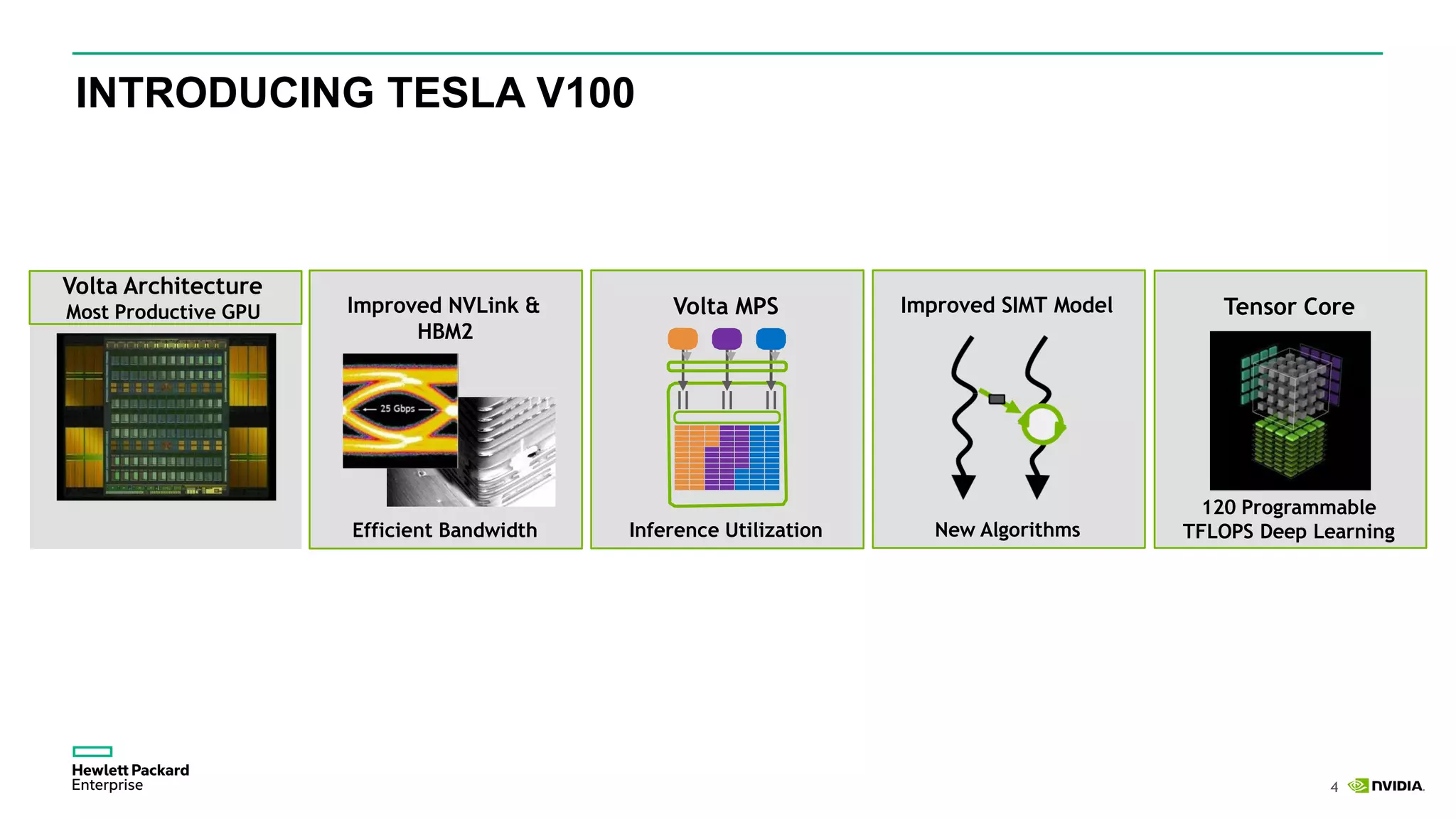
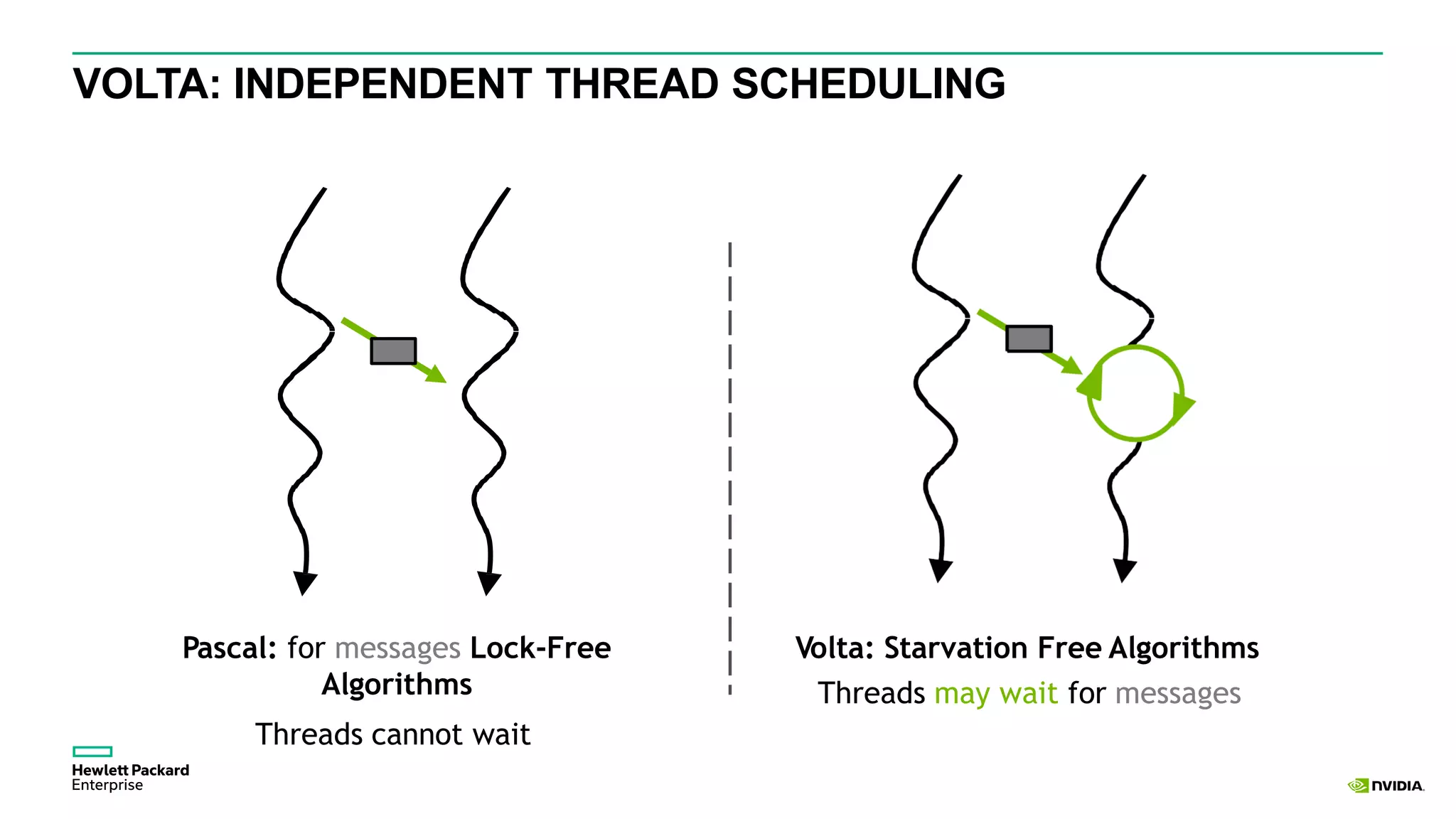
HPE presents its advancements in deep learning and artificial intelligence, outlining a comprehensive portfolio for enhanced analytics and insights across various sectors. The document highlights the capabilities of the Tesla V100 GPU, emphasizing its performance metrics and benefits for deep learning applications. HPE aims to provide organizations with optimized infrastructure and services to leverage AI for achieving competitive advantage.







![6
ALL MAJOR FRAMEWORKSVOLTA-OPTIMIZED cuDNN
MATRIX DATA OPTIMIZATION:
Dense Matrix of Tensor Compute
TENSOR-OP CONVERSION:
FP32 to Tensor Op Data for
Frameworks
VOLTA TENSOR CORE
4x4 matrix processing array
D[FP32] = A[FP16] * B[FP16] + C[FP32]
Optimized For Deep Learning
NEW TENSOR CORE BUILT FOR AI
Delivering 120 TFLOPS of DL Performance](https://image.slidesharecdn.com/hpegpu-171110085115/75/HPC-DAY-2017-NVIDIA-Volta-Architecture-Performance-Efficiency-Availability-16-2048.jpg)