柔軟物の操作の学習における報酬
• エントロピ正則された強化学習(Deep DynamicPolicy Programming)
• シミュレータの使用なしで学習
Tsurumine, Y., Cui, Y., Uchibe, E., and Matsubara, T. (2017). Deep dynamic policy programming for robot control
with raw images. In Proc. of IROS.
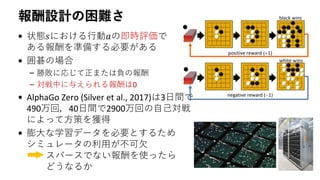
7.
シャツの折り畳みの場合
実用的な報酬を準備するのは
難しい
Tsurumine, Y., Cui,Y., Uchibe, E., and Matsubara, T. (2019). Deep reinforcement learning with smooth policy
update: Application to robotic cloth manipulation. Robotics and Autonomous Systems, 112: 72-83.
行動クローニングの問題点
• エキスパートと学習者の状態行動分布は異なる(共変量シフト)
• 行動し続けることで誤差が蓄積し,エキスパートの分布から逸脱
–元の分布に戻る手段がない
Ross, S. & Bagnell, J.A. (2010). Efficient Reductions for Imitation Learning. In Proc. of AISTATS, 9:661–668.
Osa, T., Pajarinen, J., Neumann, G., Bagnell, J.A., Abbeel, P.A., & Peters, J. (2018). An Algorithmic Perspective on
Imitation Learning. Foundations and Trends in Robotics 7, no. 1–2, 1–179.
14.
敵対的生成ネットワーク(Generative Adversarial
Network; GAN)
•生成器(Generator)と識別器(Discriminator)の競合によって
データを生成するモデル
https://deephunt.in/the-gan-zoo-79597dc8c347
識別器𝐷(𝑥)生成器𝐺(𝑧)
識別器𝐷(𝑥)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014).
Generative Adversarial Nets. NeurIPS 27, 2672–2680.
References
• Blondé, L.,& Kalousis, A. (2019). Sample-Efficient Imitation Learning via Generative Adversarial Nets.
Proc. of the 22nd International Conference on Artificial Intelligence and Statistics, 3138–48.
• Finn, C., Christiano, P., Abbeel, P., and Levine, S. (2016). A Connection Between Generative
Adversarial Networks, Inverse Reinforcement Learning, and Energy-Based Models. NIPS 2016
Workshop on Adversarial Training.
• Fu, J., Luo, K., and Levine, S. (2018). Learning robust rewards with adversarial inverse reinforcement
learning. In Proc. of ICLR.
• Fujimoto, S., van Hoof, H., & Meger, D. (2018). Addressing Function Approximation Error in Actor-
Critic Methods. Proc. of the 35th International Conference on Machine Learning.
• Henderson, P., Chang, W.-D., Bacon, P.-L., Meger, D., Pineau, J., & Precup, D. (2018). OptionGAN:
Learning Joint Reward-Policy Options using Generative Adversarial Inverse Reinforcement Learning.
In Proc. of AAAI.
• Hirakawa, T., Yamashita, T., Tamaki, T., Fujiyoshi, H., Umezu, Y., Takeuchi, I., Matsumoto, S., and
Yoda, K. (2018). Can AI predict animal movements? Filling gaps in animal trajectories using inverse
reinforcement learning. Ecosphere.
46.
References
• Ho, J.and Ermon, S. (2016). Generative adversarial imitation learning. NIPS29.
• Kalakrishnan, M., Pastor, P., Righetti, L., & Schaal, S. (2013). Learning objective functions for
manipulation. In Proc. of ICRA, 1331–1336.
• Kostrikov, I., Agrawal, K.K., Dwibedi, D., Levine, S., & Tompson, J. (2019). Discriminator-Actor-Critic:
Addressing Sample Inefficiency and Reward Bias in Adversarial Imitation Learning. Proc. of the 7th
ICLR.
• Kozuno, T., Uchibe, E., and Doya, K. (2019). Theoretical analysis of efficiency and robustness of
softmax and gap-increasing operators in reinforcement learning. In Proc. of AISTATS.
• Li, Y., Song, J., & Ermon, S. (2017). InfoGAIL: Interpretable Imitation Learning from Visual
Demonstrations. NIPS30.
• Peng, X.B., Kanazawa, A., Toyer, S., Abbeel, P., & Levine, S. (2019). Variational Discriminator
Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow.
In Proc. of the 7th International Conference on Learning Representations. ICLR, 2019.
• Sasaki, F., Yohira, T., & Kawaguchi, A. (2019). Sample Efficient Imitation Learning for Continuous
Control. Proc. of the 7th International Conference on Learning Representations.
47.
References
• Schaul, T.,Horgan, D., Gregor, K., & Silver, D. (2015). Universal Value Function Approximators. In Proc.
of ICML, 1312–1320.
• Shimosaka, M., Kaneko, T., & Nishi, K. (2014). Modeling risk anticipation and defensive driving on
residential roads with inverse reinforcement learning. Proc. of the 17th International IEEE Conference
on Intelligent Transportation Systems, 1694–1700.
• Sugiyama, M., Suzuki, T., & Kanamori, T. (2012). Density ratio estimation in machine learning.
Cambridge University Press.
• Sun, M., & Ma, X. (2019). Adversarial Imitation Learning from Incomplete Demonstrations. In Proc. of
IJCAI, 2019.
• Suzuki, Y., Wee, W.M., & Nishioka, I. (2019). TV Advertisement Scheduling by Learning Expert
Intentions. In Proc. of the 25th ACM SIGKDD International Conference on Knowledge Discovery &
Data Mining, pp. 3071–81.
• Torabi, F., Warnell, G., & Stone, P. (2019). Generative Adversarial Imitation from Observation. ICML
2019 Workshop on Imitation, Intent, and Interaction.
• Uchibe, E. & Doya, K. (2014). Inverse reinforcement learning using dynamic policy programming. In
Proc. of ICDL and Epirob.
48.
References
• Uchibe, E.(2018). Model-Free Deep Inverse Reinforcement Learning by Logistic Regression. Neural
Processing Letters, 47(3): 891-905.
• 内部. (2019). エントロピ正則された強化学習を用いた模倣学習. 第33回人工知能学会全国大会
予稿集.
• Uchibe, E. (2019). Imitation learning based on entropy-regularized forward and inverse
reinforcement learning. Proc. of RLDM.
• Uchibe, E., & Doya, K. (in preparation). Imitation learning based on entropy-regularized forward and
inverse reinforcement learning.
• Wulfmeier, M., Rao, D., Wang, D.Z., Ondruska, P., & Posner, I. (2017). Large-scale cost function
learning for path planning using deep inverse reinforcement learning. International Journal of
Robotics Research, vol. 36, no. 10: 1073–1087.
• Yamaguchi, S., Honda, N., Ikeda, M., Tsukada, Y., Nakano, S., Mori, I., and Ishii, S. (2018).
Identification of animal behavioral strategies by inverse reinforcement learning. PLoS Computational
Biology.


![強化学習とは
• 試行錯誤を通して方策(行動ルール)
を学ぶ人工知能技術
• 囲碁のチャンピオンに勝利したアルファ碁は
強化学習とディープラーニングの組み合わせ
ロボットなどの制御へ応用
• ヒトや動物の意思決定のモデルとしても
注目
脳科学の観点からの説明
[Nature Blog. The Go Files: AI
computer wraps up 4-1 victory …]
(Doya, 2007)
目的関数
(報酬)
強化学習
方策
(行動ルール)](https://image.slidesharecdn.com/stairlab20190920-190924073229/85/slide-3-320.jpg)




![逆強化学習とは
• 単純な報酬を使うと膨大な学習データと計算時間が必要
• 詳細な報酬を事前に設計するのは
困難
意図とは異なる行動を学習
• 熟練者の行動データをもとに
報酬を推定する技術が逆強化学習
– 不良設定問題 [OpenAI Blog. Faulty Reward …] [Sorta Insightful (Blog)]
目的関数
(報酬)
強化学習
逆強化学習
制御則または熟練者からの
行動データ](https://image.slidesharecdn.com/stairlab20190920-190924073229/85/slide-9-320.jpg)






![GAILの目的関数
• 𝐷(𝑠, 𝑎)は𝑠が実データか生成されたデータかを判定する
• 目的関数
–
• 𝔼 𝑠,𝑎 ∼𝜋 𝐸 ⋅ は未知のエキスパート方策𝜋 𝐸(𝑎 ∣ 𝑠)のもとで得られる
定常状態行動分布のもとでの期待値
– 𝔼 𝑠,𝑎 ∼𝜋[⋅]も同様
min
𝜋
max
𝐷
𝔼(𝑠,𝑎)∼𝜋 𝐸 ln 1 − 𝐷 𝑠, 𝑎 + 𝔼 𝑠,𝑎 ∼𝜋 ln 𝐷 𝑠, 𝑎 − 𝜆ℋ(𝜋)
𝐷 𝑠, 𝑎 = ൝
1 (𝑠, 𝑎)が学習者が生成データの場合
0 (𝑠, 𝑎)がエキスパートデータの場合
𝜋 𝐸
𝑠, 𝑎 = 𝜋 𝐸
(𝑎 ∣ 𝑠)
𝑡=0
∞
𝛾 𝑡
𝑃 𝑠𝑡 = 𝑠 𝜋 𝐸](https://image.slidesharecdn.com/stairlab20190920-190924073229/85/slide-16-320.jpg)




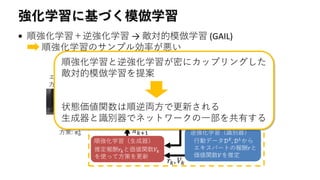

![提案手法のアイデア
• 対数密度比をサンプルから推定し,近似した目的関数を最小化
– 識別器𝐷 𝑠, 𝑎, 𝑠′
をエントロピ正則化強化学習の理論をもとに構造化
– ロジスティック回帰による密度比推定 逆強化学習
– KLダイバージェンス最小化 順強化学習
𝐽 𝜋 𝐿 = න 𝜋 𝐿 𝑠, 𝑎, 𝑠′ ln
𝜋 𝐿 𝑠, 𝑎, 𝑠′
𝜋 𝐸 𝑠, 𝑎, 𝑠′
d𝑠d𝑎d𝑠′
≈ න 𝜋 𝐿
𝑠, 𝑎, 𝑠′
ln
𝐷 𝑠, 𝑎, 𝑠′
1 − 𝐷 𝑠, 𝑎, 𝑠′
d𝑠d𝑎d𝑠′ density ratio trick
[Sugiyama et al., 2012]
内部 (2019). エントロピ正則された強化学習を用いた模倣学習. 第33回人工知能学会全国大会 (優秀賞)
Uchibe, E. (2019). Imitation learning based on entropy-regularized forward and inverse reinforcement learning.
Proc. of RLDM.](https://image.slidesharecdn.com/stairlab20190920-190924073229/85/slide-23-320.jpg)















![実験: 人の倒立振り子課題
• タスク: 振り子を振り上げ,3秒間倒立状態を
維持する
• 実験条件:
– 振り子の長さ: long (73 cm), short (29 cm)
– 各振り子ごとに15試行
– 1試行あたり最大40 [s]
– 被験者数: 7 (右利き: 5, 左利き: 2)
– 行動(𝐹𝑥, 𝐹𝑦)は観測されない
• 提案手法(ERIL)を以下の手法と比較
– GAIfO: GAN-based imitation
– C-BC: 条件つき行動クローニング
– LogReg-IRL (Uchibe, 2018):
𝐹𝑥
𝐹𝑦
𝜃
(𝑥, 𝑦)
• State: (𝑥, ሶ𝑥, 𝑦, ሶ𝑦, 𝜃, ሶ𝜃)
• Action: (𝐹𝑥, 𝐹𝑦)](https://image.slidesharecdn.com/stairlab20190920-190924073229/85/slide-39-320.jpg)










![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning Robust Rewards with Adversarial Inverse Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/180201dllearningrobustrewardswithadversarial3-180205170610-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Learn What Not to Learn: Action Elimination with Deep Reinforcement Le...](https://cdn.slidesharecdn.com/ss_thumbnails/learnwhatnottolearn-180914011647-thumbnail.jpg?width=640&height=640&fit=bounds)