Artificial Neuron (AN)
+
x0=1
x1
x2
xN
...w0 (Bias)
w1
w2
wN
f(u)
u y
xi: Input signal
wi: Weight
u: Internal state
f(u): Activation function
(Sigmoid, ReLU, etc.)
y: Output signal
y f (u)
u wi xi
i0
N
23
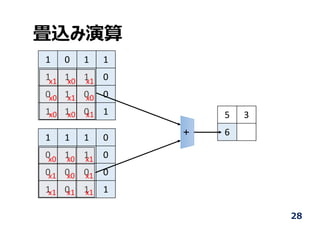
LeNet-5
• CNNのベース (1980年に福島先⽣がネオコグニトロ
ンをすでに発表済み!!)
•畳込み(特徴抽出)→フル結合(分類)
• 5層
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to
document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998. 25
2値化/3値化 on FPGAがトレンド
•FPT2016 (12⽉開催)
• E. Nurvitadhi (Intel) et al., “Accelerating Binarized Neural
Networks: Comparison of FPGA, CPU, GPU, and ASIC”
• H. Nakahara, “A Memory-Based Realization of a Binarized Deep
Convolutional Neural Network”
• ISFPGA2017 (先週開催)
• Ritchie Zhao et al., “Accelerating Binarized Convolutional Neural
Networks with Software-Programmable FPGAs”
• Y. Umuroglu (Xilinx) et al., FINN: A Framework for Fast,
Scalable Binarized Neural Network Inference
• H. Nakahara, H. Yonekawa, “A Batch Normalization Free
Binarized Convolutional Deep Neural Network on an FPGA”
• Y. Li et al., “A 7.663-TOPS 8.2-W Energy-efficient FPGA
Accelerator for Binary Convolutional Neural Networks,”
• G. Lemieux, “TinBiNN: Tiny Binarized Neural Network Overlay
in Less Than 5,000 4-LUTs,”
36
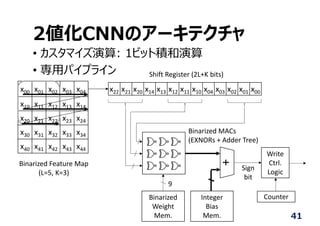
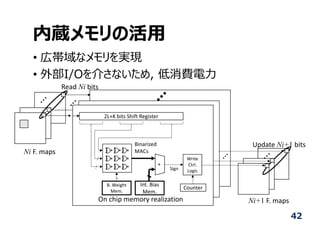
内蔵メモリの活⽤
• 広帯域なメモリを実現
• 外部I/Oを介さないため,低消費電⼒
42
v
v
v
v
v
v
+
B. Weight
Mem.
Int. Bias
Mem.
Write
Ctrl.
Logic
Counter
Binarized
MACs
Sign
2L+K bits Shift Register
v
v
Ni F. maps
Ni+1 F. maps
Read Ni bits
Update Ni+1 bits
On chip memory realization
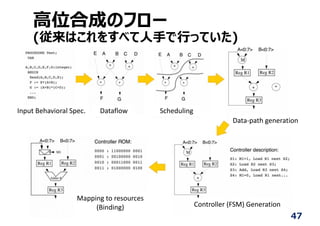
Conventional Design Flow
forthe Programmable SoC
48
①
②
④
③
1. Behavior design
2. Profile analysis
3. IP core generation by HLS
4. Bitstream generation by
FPGA CAD tool
5. Middle ware generation
49.
Modern System Design
49
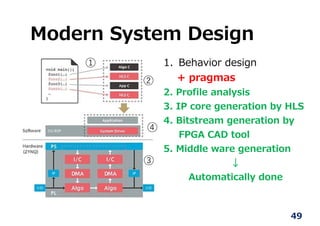
①
②
④
③
1.Behavior design
+ pragmas
2. Profile analysis
3. IP core generation by HLS
4. Bitstream generation by
FPGA CAD tool
5. Middle ware generation
↓
Automatically done
50.
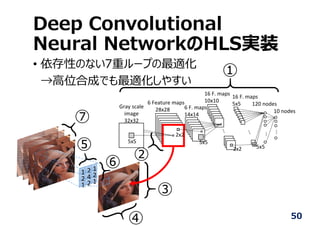
Deep Convolutional
Neural NetworkのHLS実装
•依存性のない7重ループの最適化
→⾼位合成でも最適化しやすい
...
...
120 nodes
10 nodes
16 F. maps
5x5
16 F. maps
10x10
6 F. maps
14x14
6 Feature maps
28x28
Gray scale
image
32x32
5x5
2x2
5x5
2x2 5x5
1 2 1
2 4 2
1 2 1
①
②
③
④
⑤
⑥
⑦
50




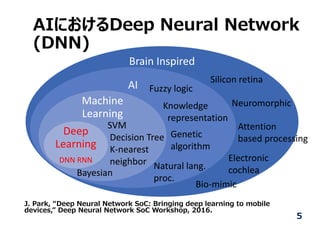
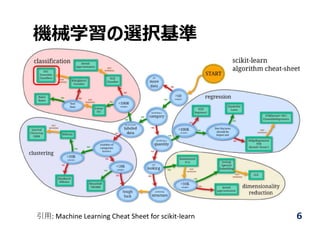
![Deep Neural Networkの
認識精度
7
0
5
10
15
20
25
30
2010 2011 2012 2013 2014 2015 Human
認識精度[%]
Year
Deep Convolutional
Neural Network (CNN)による
劇的な改善
⼈の認識精度を
上回る
O. Russakovsky et al. “ImageNet Top 5 Classification Error (%),” IJCV 2015.](https://image.slidesharecdn.com/sci1761v1-170528011159/85/2-7-320.jpg)
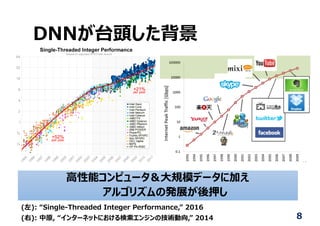


































![⾼位合成による⾃動合成
⾏列演算ライブラリの
中⾝をC/C++で書く
ただし、HDLよりは抽象的
Y=0;
for(i=0; i < m; i++){
for( j = 0; j < n; j++){
Y += X[i][j]*W[j][i];
}
}
FPGAベンダの
⾼位合成ツールが
HDLを⽣成
↓
従来のフローを通して
FPGAに実現
⾃動⽣成
ディープニューラルネットワークを
既存のフレームワークで設計
(学習はGPU上で)
学習済みCNNを
2値化に変換
(開発中)
51](https://image.slidesharecdn.com/sci1761v1-170528011159/85/2-51-320.jpg)



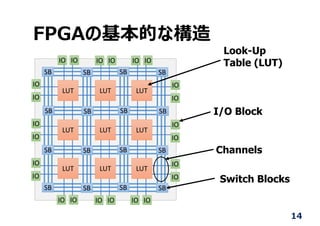
![GPU, CPUとの⽐較
Platform
Device
Quad‐core ARM
Cortex‐A57
256‐core
Maxwell GPU
Zynq UltraScale+
MPSoC
Clock Freq. 1.9 GHz 998 MHz 100 MHz
FPS 0.23 6.40 31.48
Power [W]
(ボード全体の電⼒)
7 17 22
(チップ単体はかなり低)
Efficiency [FPS/W] 0.032 0.376 1.431
Accuracy [%] 92.35 90.30
56
H. Yonekawa and H. Nakahara, “On‐chip Memory Based Binarized Convolutional Deep Neural Network Applying
Batch Normalization Free Technique on an FPGA”, IPDPSW 2017, (2017年5⽉29⽇発表).
NVIDIA Jetson TX1 Xilinx ZCU102](https://image.slidesharecdn.com/sci1761v1-170528011159/85/2-56-320.jpg)







![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning convolutional neural networks for graphs](https://cdn.slidesharecdn.com/ss_thumbnails/learningconvolutionalneuralnetworksforgraphs-170222032121-thumbnail.jpg?width=640&height=640&fit=bounds)





![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminarfunit-190517005148-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)

















































