13
DEEP LEARNING INSIGHT
従来のアルゴリズムディープラーニング
0%
20%
40%
60%
80%
100%
overall passenger
channel
indoor public area sunny day rainny day winter summer
Pedestrian detection Recall rate
Traditional Deep learning
70
75
80
85
90
95
100
vehicle color brand model sun blade safe belt phone calling
Vehicle feature accuracy increased by Deep Learning
traditional algorithm deep learning
監視カメラ
子供の成長の問題を
AI が検出
Detecting growth-relatedproblems in children
requires calculating their bone age. But it’s an
antiquated process that requires radiologists to
match X-rays with images in a 1950s textbook.
Massachusetts General Hospital, which conducts
the largest hospital-based research program in
the United States, developed an automated
bone-age analyzer built on NVIDIA cuDNN and the
NVIDIA DIGITS DevBox. The system is 99%
accurate and delivers test results in seconds
versus days.
15.
Deep Learning forearly detection of Age-
related Macular Degeneration
________________________________________
– UW developed a deep learning system to
read OCT scans and automatically detect
Age-related Macular Degeneration.
– There were 5.4 Million Scans in 2014
– In under one month of training, the
system is over 90% accurate
80% of people above 80 have Age-related
Macular Degeneration and it is treatable
-Aaron Lee, Assistant Professor of Ophthalmology,
University of Washington
0x
16x
32x
48x
64x
0 16 3248 64
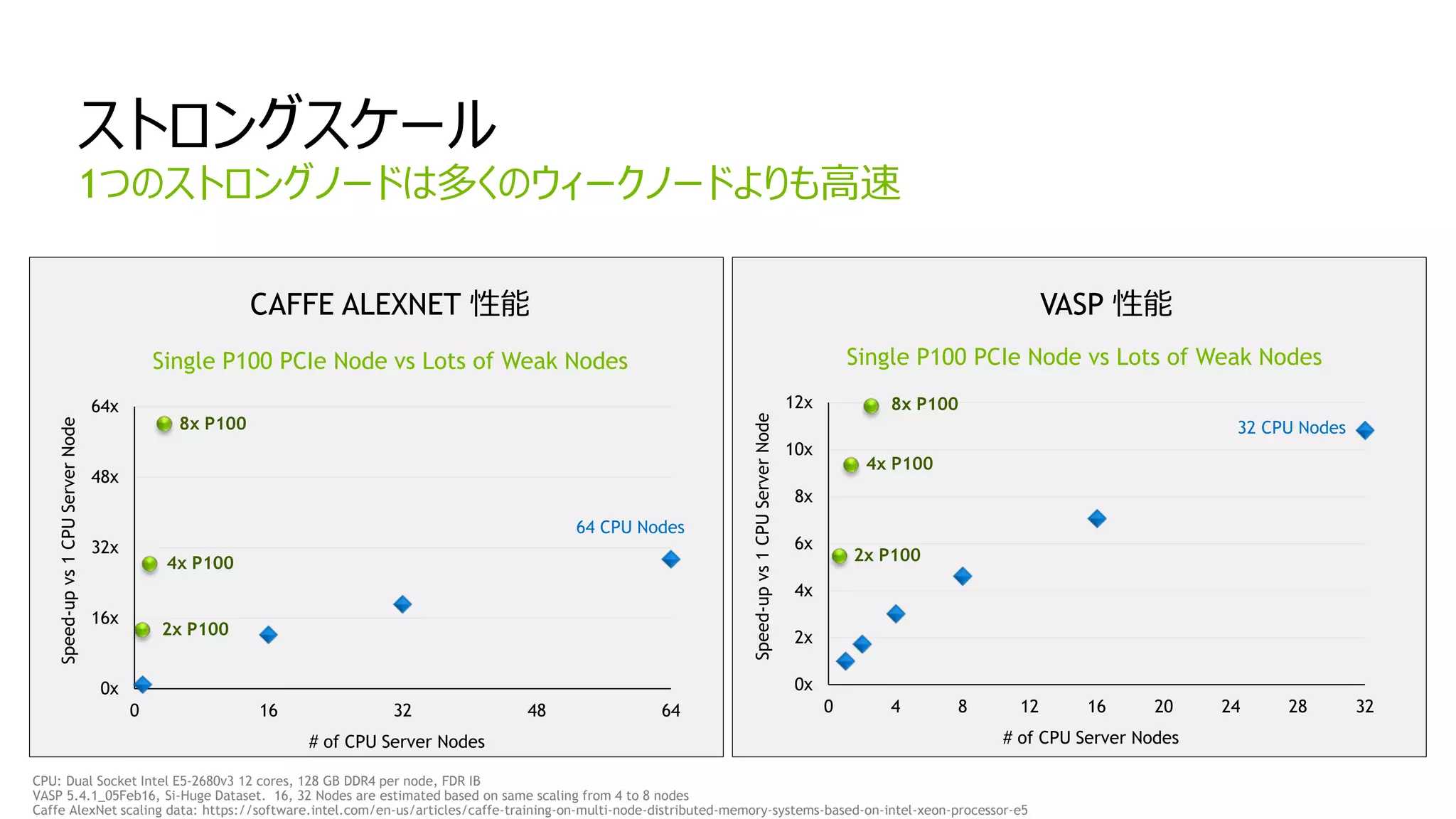
ストロングスケール
1つのストロングノードは多くのウィークノードよりも高速
VASP 性能
2x P100
CPU: Dual Socket Intel E5-2680v3 12 cores, 128 GB DDR4 per node, FDR IB
VASP 5.4.1_05Feb16, Si-Huge Dataset. 16, 32 Nodes are estimated based on same scaling from 4 to 8 nodes
Caffe AlexNet scaling data: https://software.intel.com/en-us/articles/caffe-training-on-multi-node-distributed-memory-systems-based-on-intel-xeon-processor-e5
CAFFE ALEXNET 性能
4x P100
8x P100
Single P100 PCIe Node vs Lots of Weak Nodes
# of CPU Server Nodes
Speed-upvs1CPUServerNode
0x
2x
4x
6x
8x
10x
12x
0 4 8 12 16 20 24 28 32
2x P100
8x P100
Single P100 PCIe Node vs Lots of Weak Nodes
# of CPU Server Nodes
Speed-upvs1CPUServerNode
4x P100
64 CPU Nodes
32 CPU Nodes
59.
Fastest AI Supercomputerin TOP500
4.9 Petaflops Peak FP64 Performance
19.6 Petaflops DL FP16 Performance
124 NVIDIA DGX-1 Server Nodes
Most Energy Efficient Supercomputer
#1 on Green500 List
9.5 GFLOPS per Watt
2x More Efficient than Xeon Phi System
Rocket for Cancer Moonshot
CANDLE Development Platform
Optimized Frameworks
DGX-1 as Single Common Platform
INTRODUCING DGX SATURNV
World’s Most Efficient AI Supercomputer
60.
To speed advancesin the fight against cancer, the
Cancer Moonshot initiative unites the Department
of Energy, the National Cancer Institute and other
agencies with researchers at Oak Ridge, Lawrence
Livermore, Argonne, and Los Alamos National
Laboratories. NVIDIA is collaborating with the labs
to help accelerate their AI framework called
CANDLE as a common discovery platform, with
the goal of achieving 10X annual increases in
productivity for cancer researchers.
AI PLATFORM TO
ACCELERATE
CANCER RESEARCH
61.
エヌビディア ディープラーニング プラットフォーム
COMPUTERVISION SPEECH AND AUDIO BEHAVIOR
Object Detection Voice Recognition Translation
Recommendation
Engines
Sentiment Analysis
DEEP LEARNING MATH LIBRARIES
cuBLAS cuSPARSE
GPU-INTERCONNECT
NCCLcuFFT
Mocha.jl
Image Classification
DEEP LEARNING
SDK
FRAMEWORKS
APPLICATIONS
GPU PLATFORM
CLOUD GPU
Tesla
P100
Tesla
K80/M40/M4
P100/P40/P4
Jetson TX1
SERVER
DGX-1
TensorRT
DRIVEPX2































![CNN: CONVOLUTION NEURAL NETWORK
LeNet5 [LeCun et al.,1998]](https://image.slidesharecdn.com/miiconference177nvidia-170130041707/75/MII-conference177-nvidia-35-2048.jpg)

![FULL CONNECTION
𝑦𝑦 𝑖𝑖 = 𝐹𝐹 �
𝑗𝑗
(𝑤𝑤 𝑖𝑖 𝑗𝑗 × 𝑥𝑥 𝑗𝑗 )
x[N] y[M]
w[N][M]](https://image.slidesharecdn.com/miiconference177nvidia-170130041707/75/MII-conference177-nvidia-37-2048.jpg)
![FULL CONNECTION
x[N] y[M]
w[N][M]
x =
w[N][M] x[N] y[M]
Matrix Vector
𝑦𝑦 𝑖𝑖 = 𝐹𝐹 �
𝑗𝑗
(𝑤𝑤 𝑖𝑖 𝑗𝑗 × 𝑥𝑥 𝑗𝑗 )
メモリバンド幅で性能が決まる
Xeon E5-2690v3 Tesla M40
68GB/s 288 GB/s](https://image.slidesharecdn.com/miiconference177nvidia-170130041707/75/MII-conference177-nvidia-38-2048.jpg)
![FULL CONNECTION (MINI-BATCH)
x[N] y[M]
w[N][M]
x =
w[N][M] x[N] y[M]
Matrix Vector
𝑦𝑦 𝑖𝑖 = 𝐹𝐹 �
𝑗𝑗
(𝑤𝑤 𝑖𝑖 𝑗𝑗 × 𝑥𝑥 𝑗𝑗 )](https://image.slidesharecdn.com/miiconference177nvidia-170130041707/75/MII-conference177-nvidia-39-2048.jpg)
![FULL CONNECTION (MINI-BATCH)
x[K][N] y[K][M]
w[N][M]
x =
w[N][M] x[K][N] y[K][M]
Matrix Matrix
高い演算能力を発揮できる
𝑦𝑦[𝑘𝑘] 𝑖𝑖 = 𝐹𝐹 �
𝑗𝑗
(𝑤𝑤 𝑖𝑖 𝑗𝑗 × 𝑥𝑥[𝑘𝑘] 𝑗𝑗 )
Xeon E5-2690v3 Tesla M40
0.88 TFLOPS 7.0 TFLOPS](https://image.slidesharecdn.com/miiconference177nvidia-170130041707/75/MII-conference177-nvidia-40-2048.jpg)
![CNN: CONVOLUTION NEURAL NETWORK
LeNet5 [LeCun et al.,1998]](https://image.slidesharecdn.com/miiconference177nvidia-170130041707/75/MII-conference177-nvidia-41-2048.jpg)
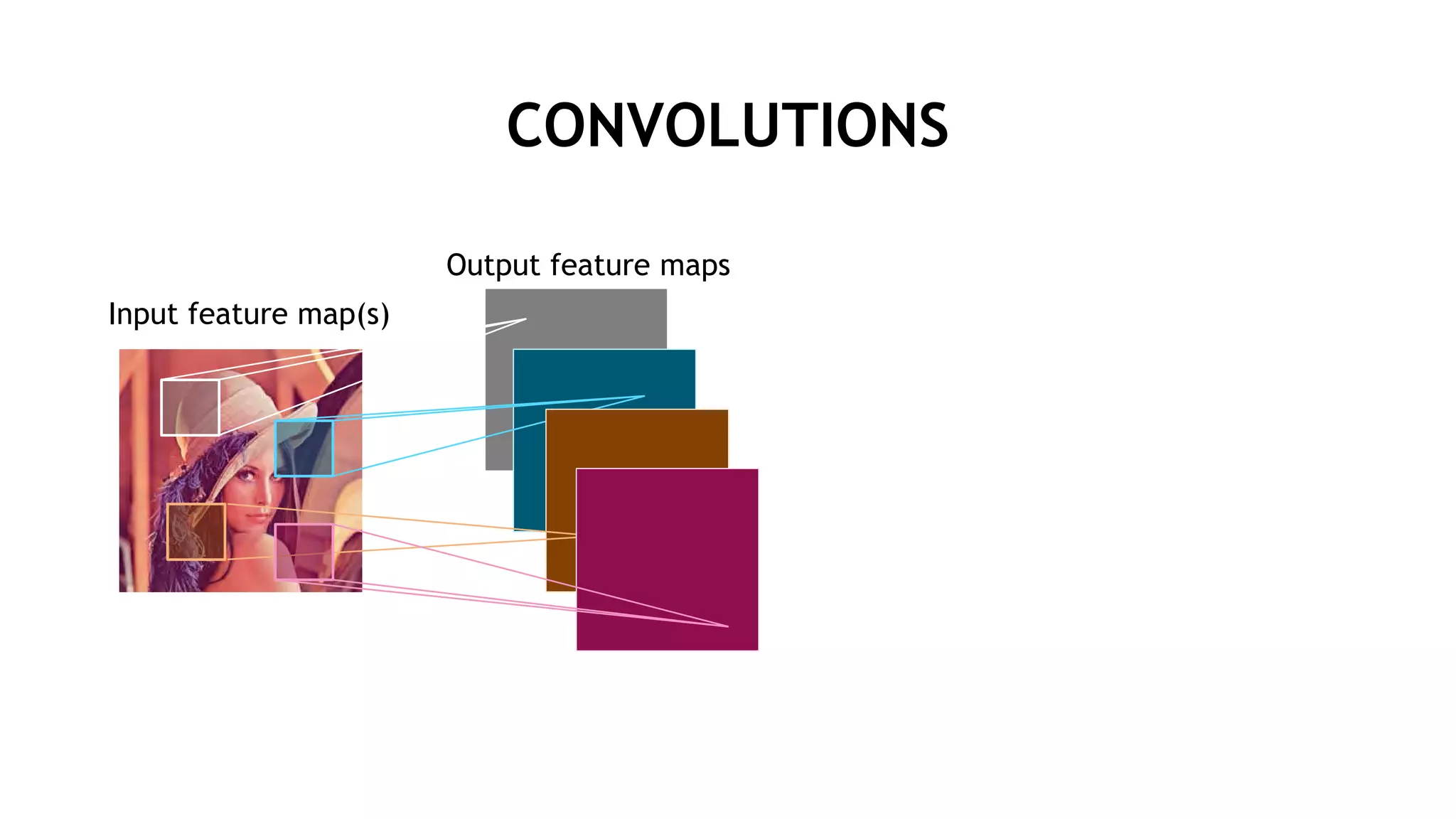
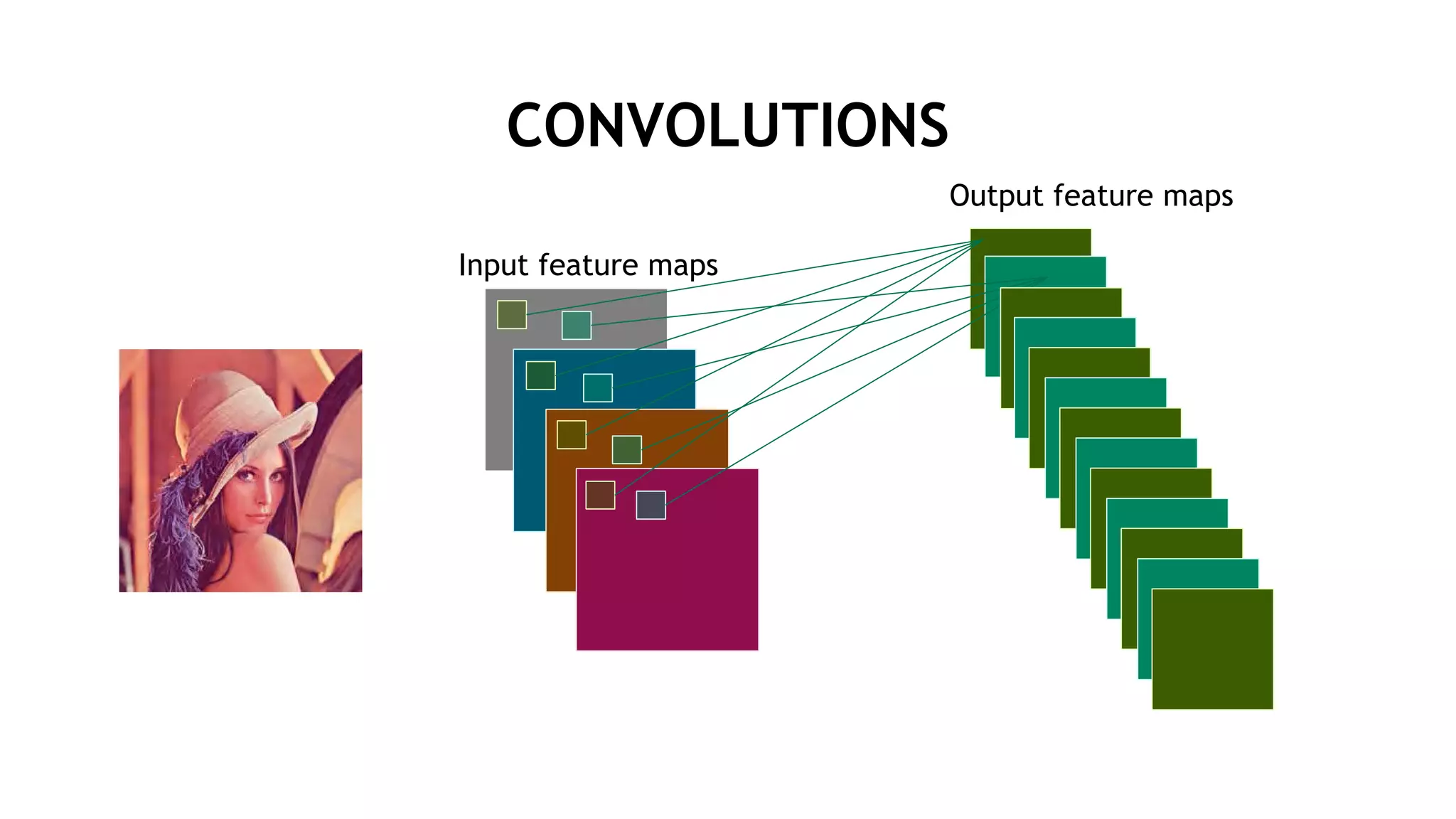

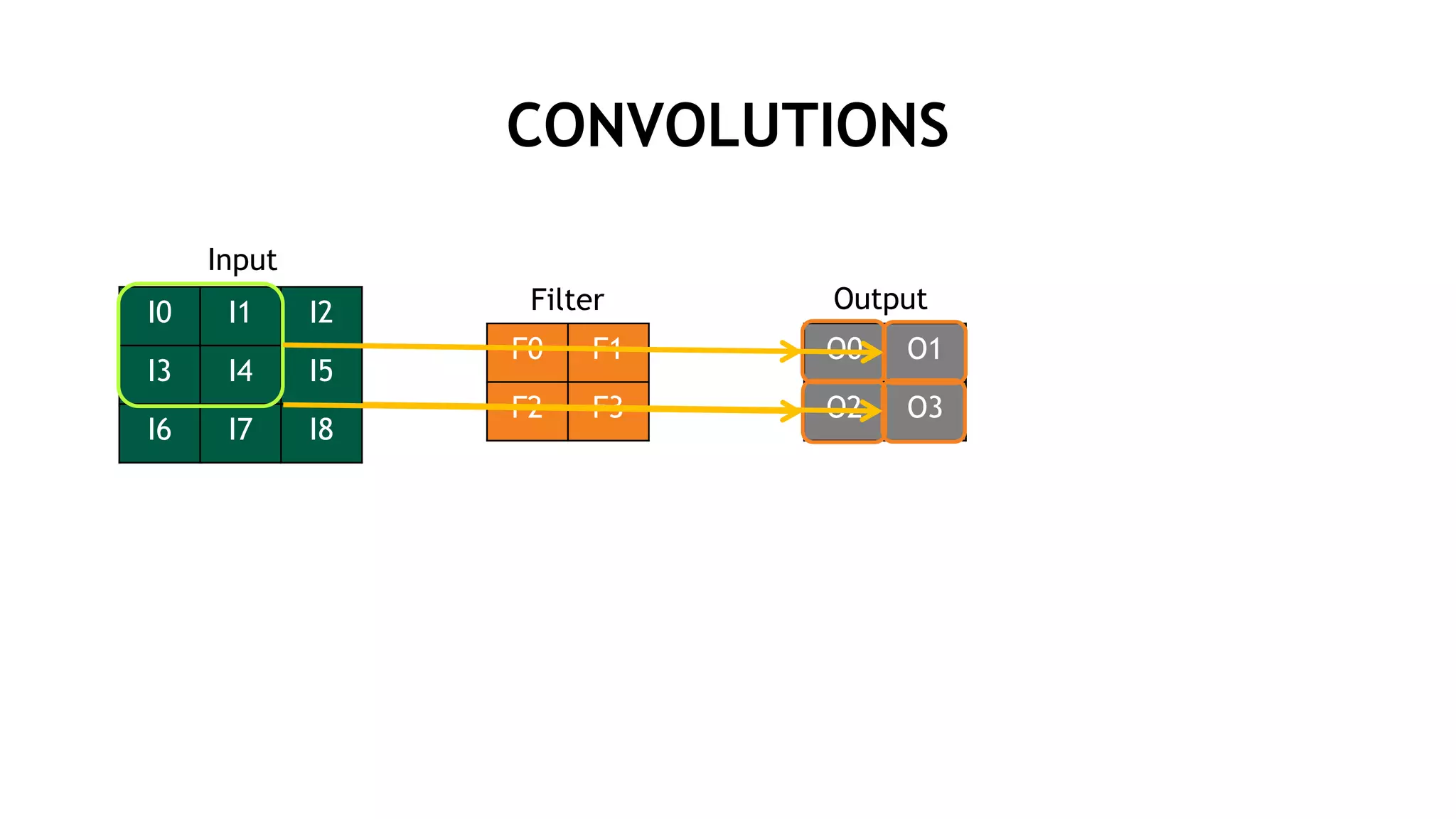
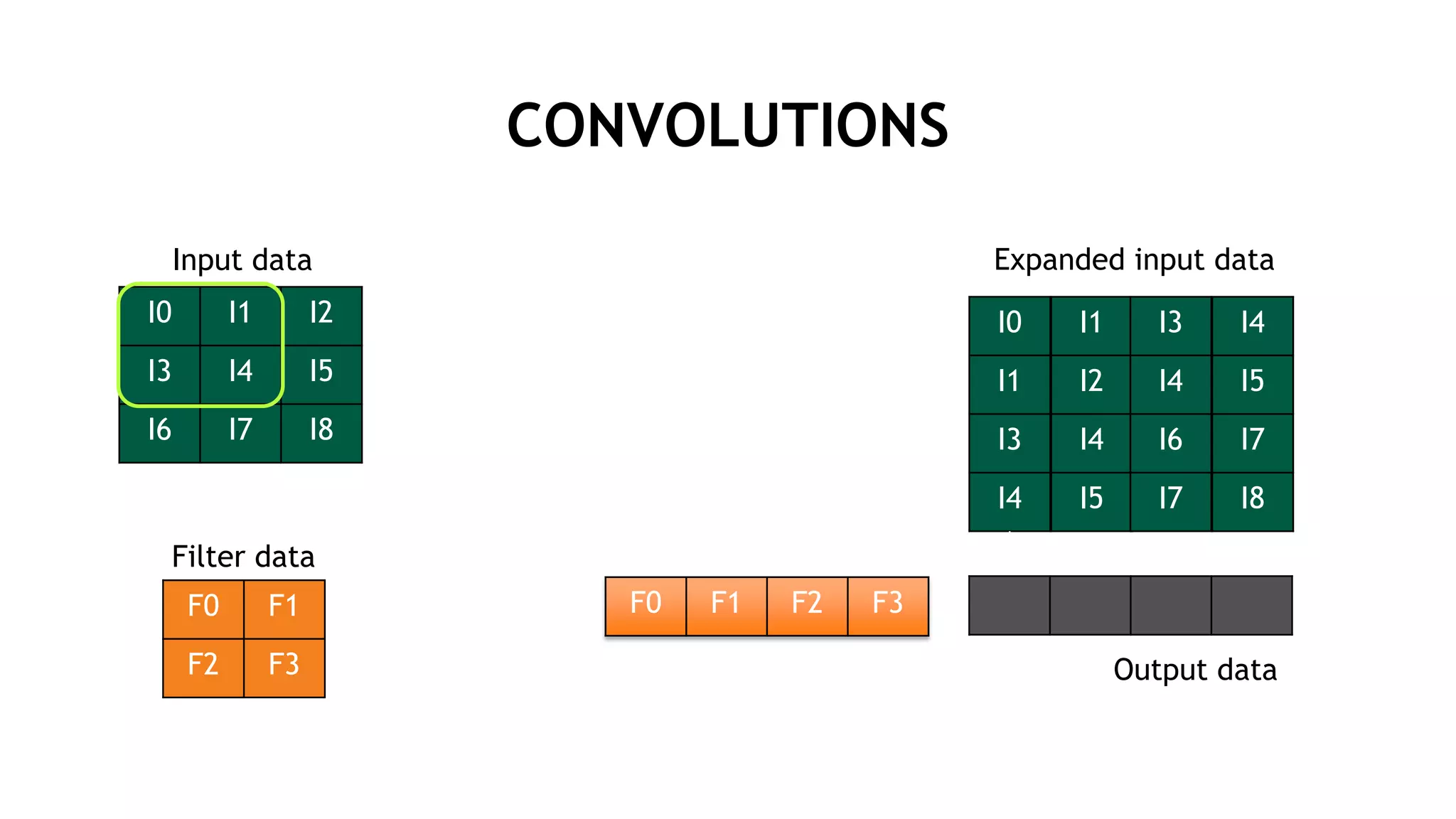


![行列演算のサイズ (LENET5)
LeNet5 [LeCun et al.,1998]
OutputsFilter
(Expanded)
Inputs
16
100 * batch size
150
150](https://image.slidesharecdn.com/miiconference177nvidia-170130041707/75/MII-conference177-nvidia-49-2048.jpg)
![行列演算のサイズ (GOOGLENET)
GoogLeNet [Szegedy et al.,2014]
OutputsFilter
(Expanded)
Inputs
192
3136 * batch size
576
576](https://image.slidesharecdn.com/miiconference177nvidia-170130041707/75/MII-conference177-nvidia-50-2048.jpg)


























































![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)


















