Downloaded 570 times









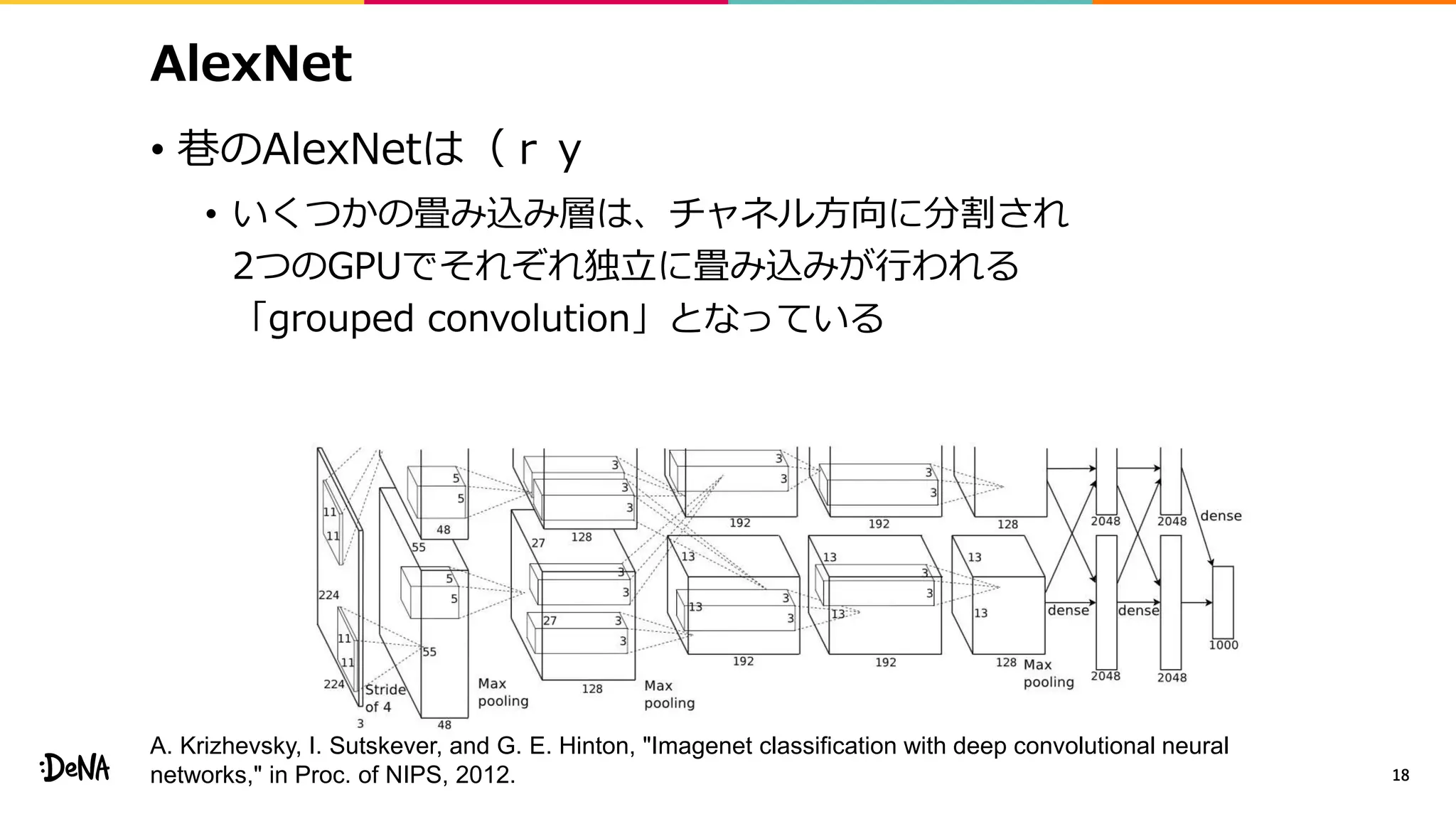














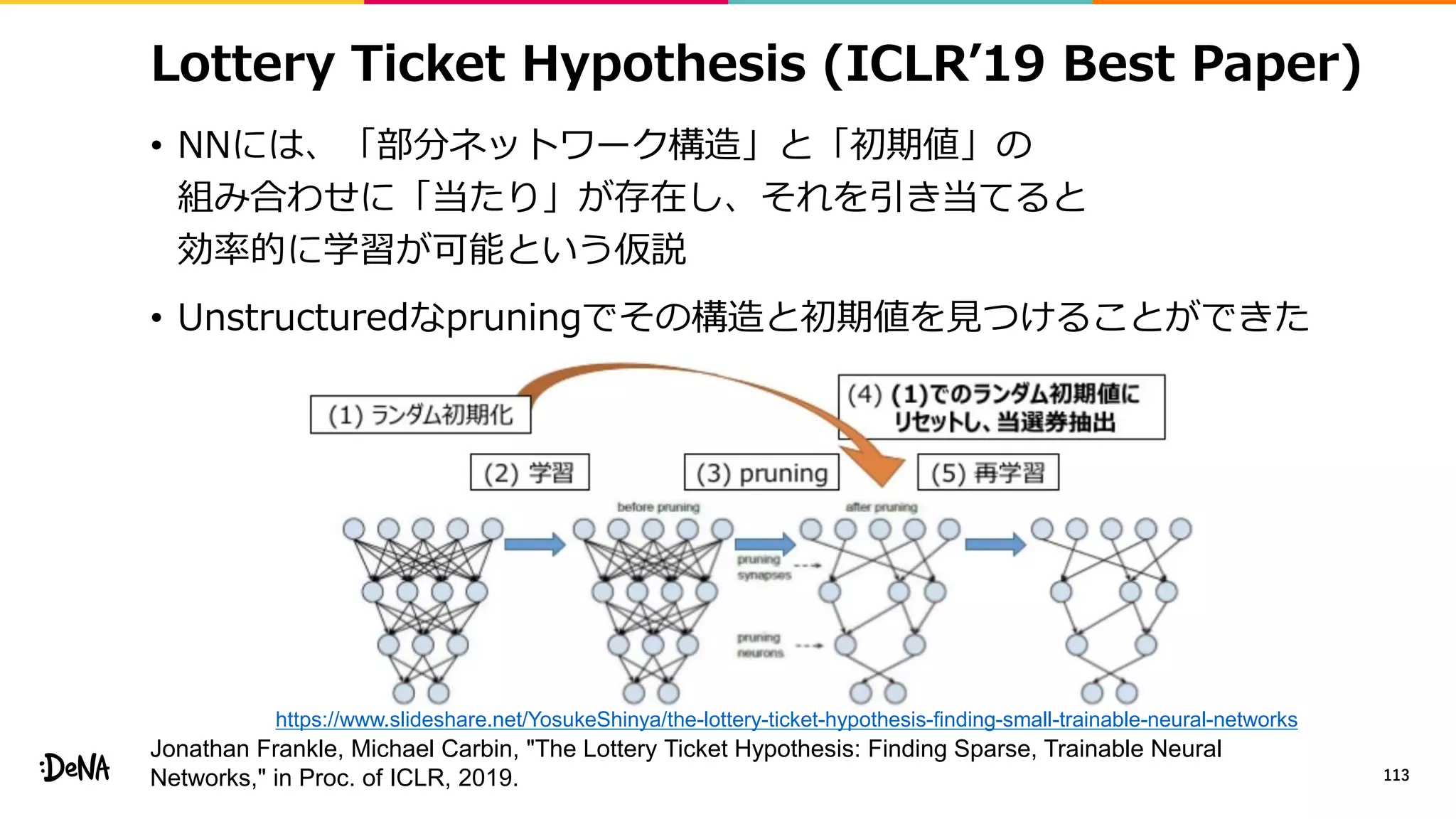
![Shake-Shake Regularization
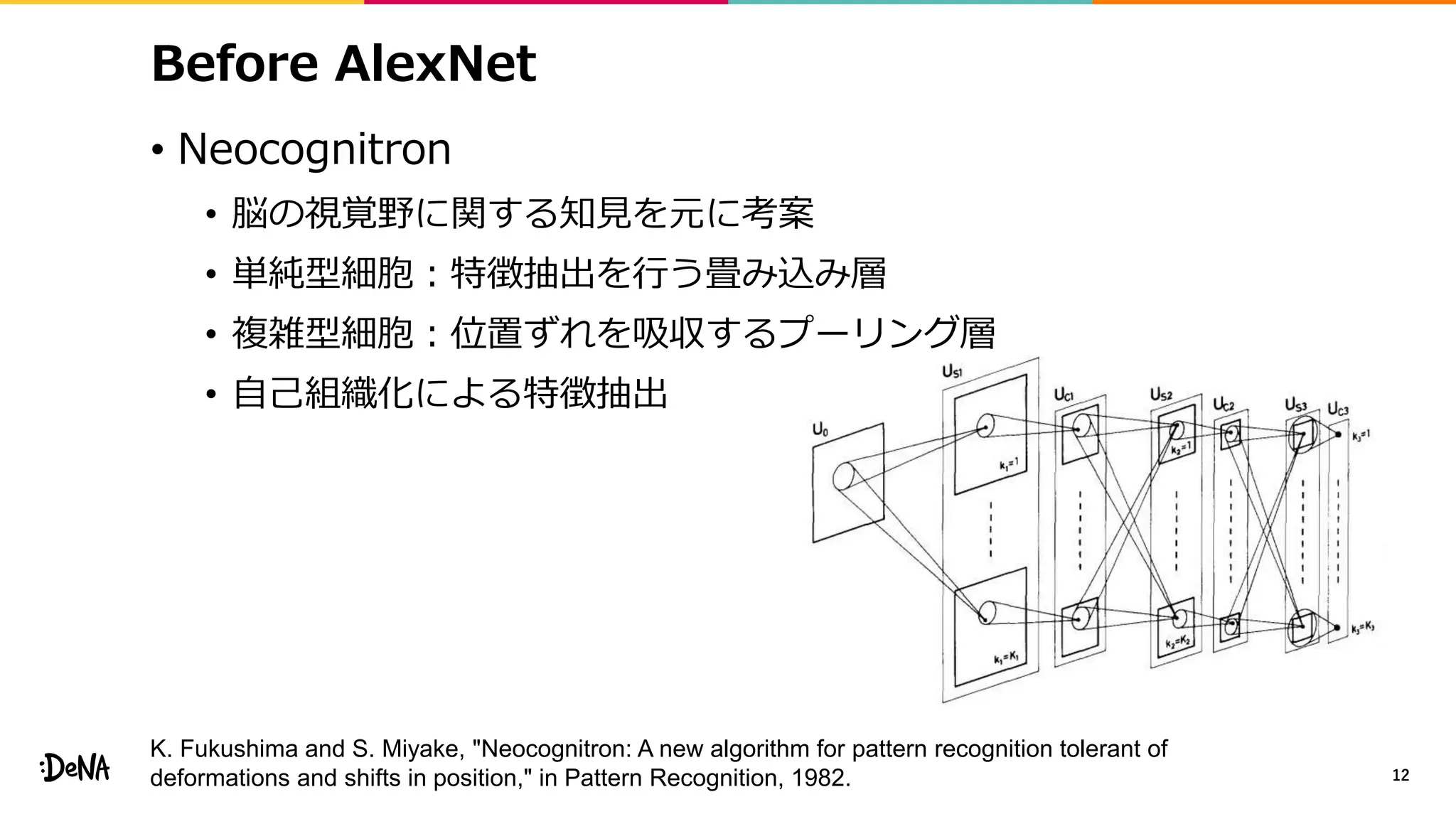
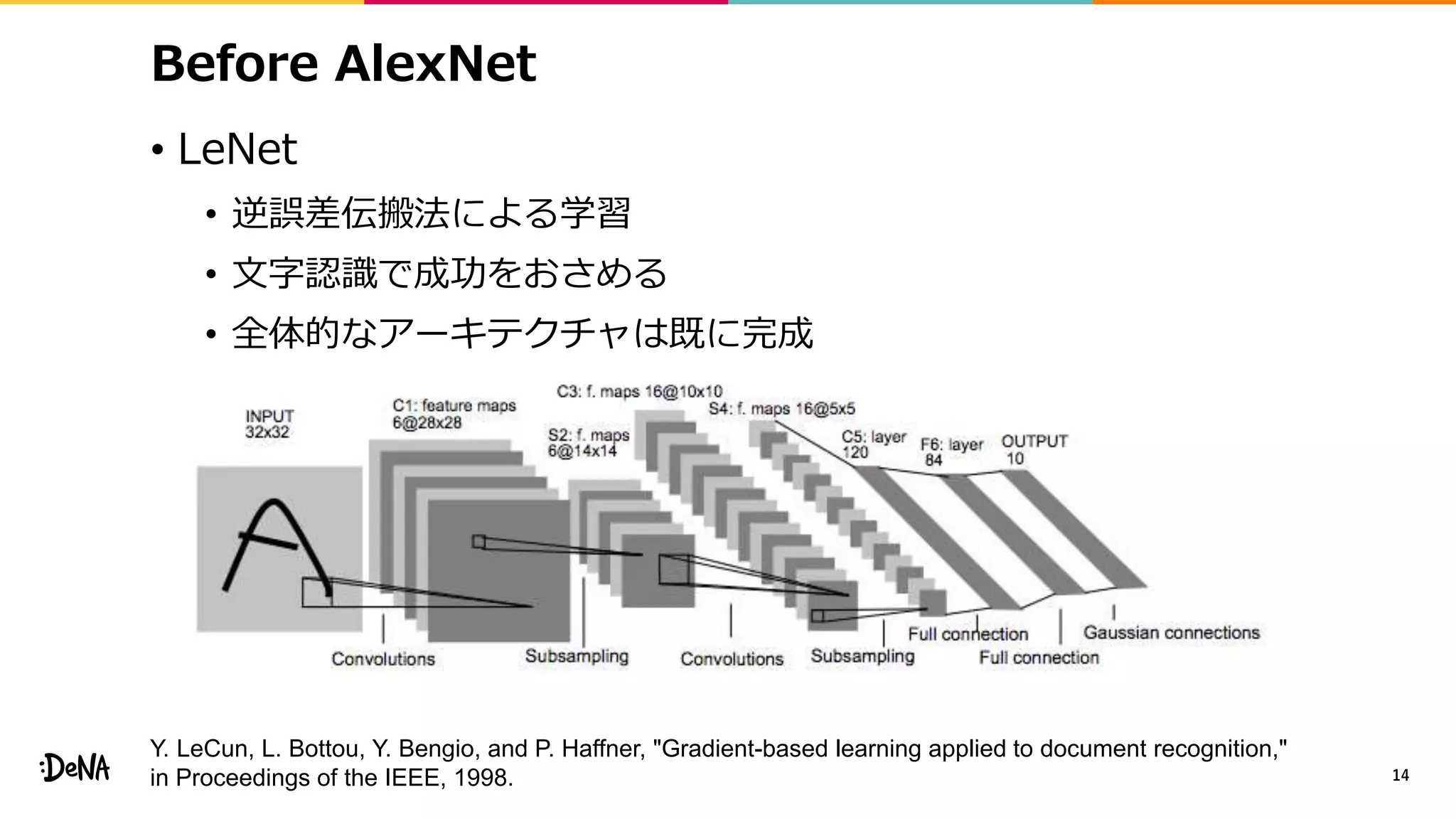
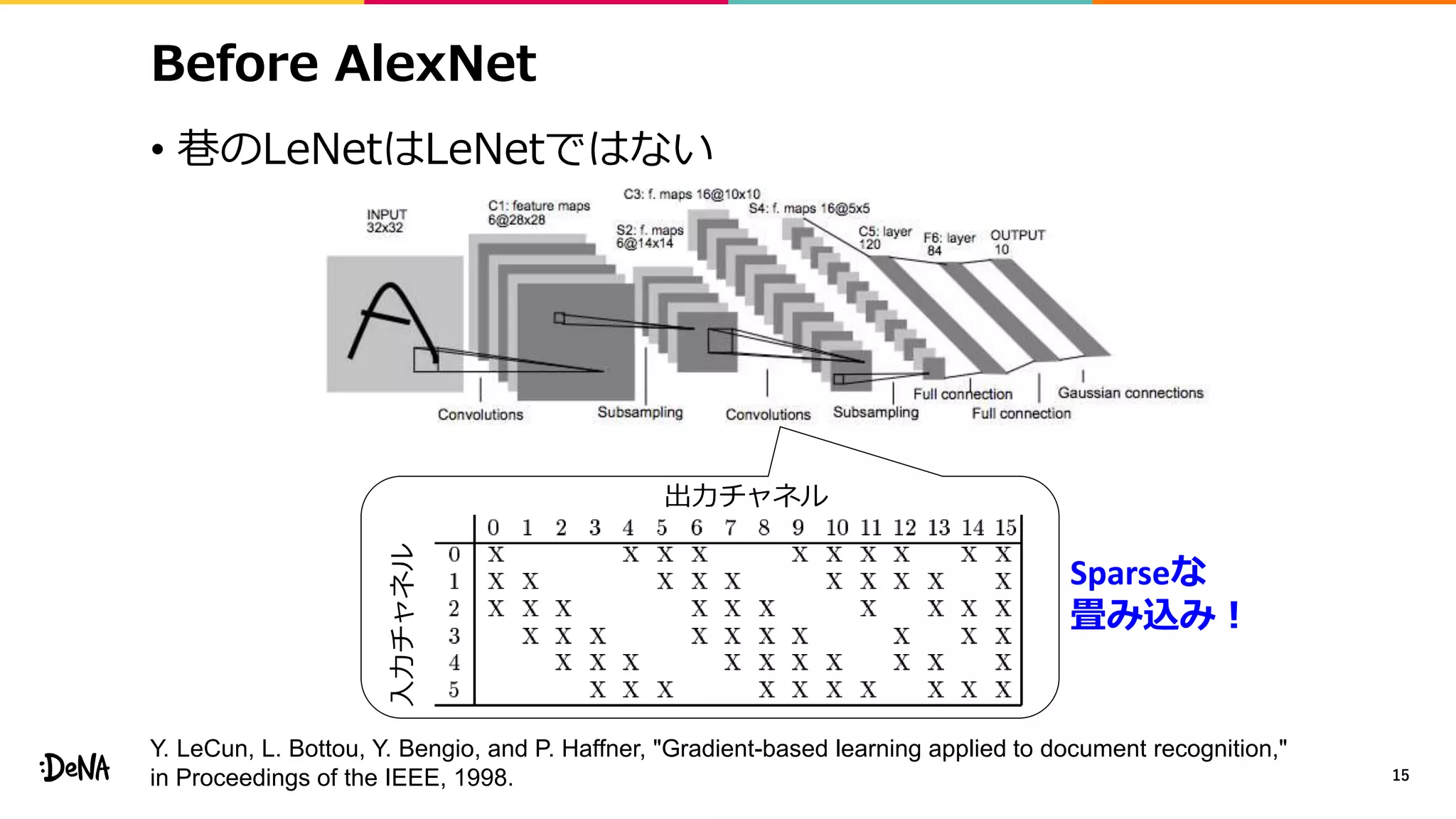
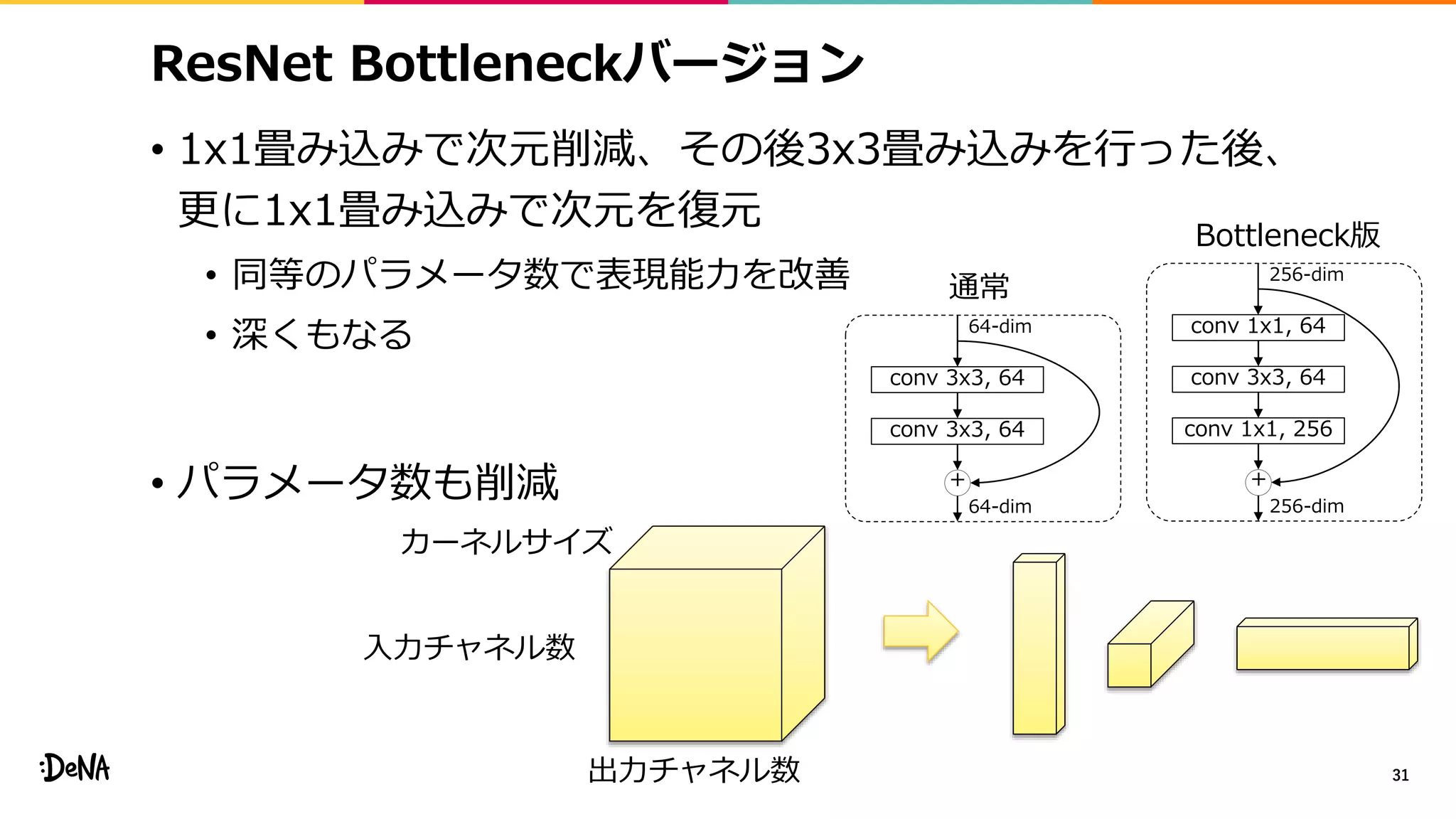
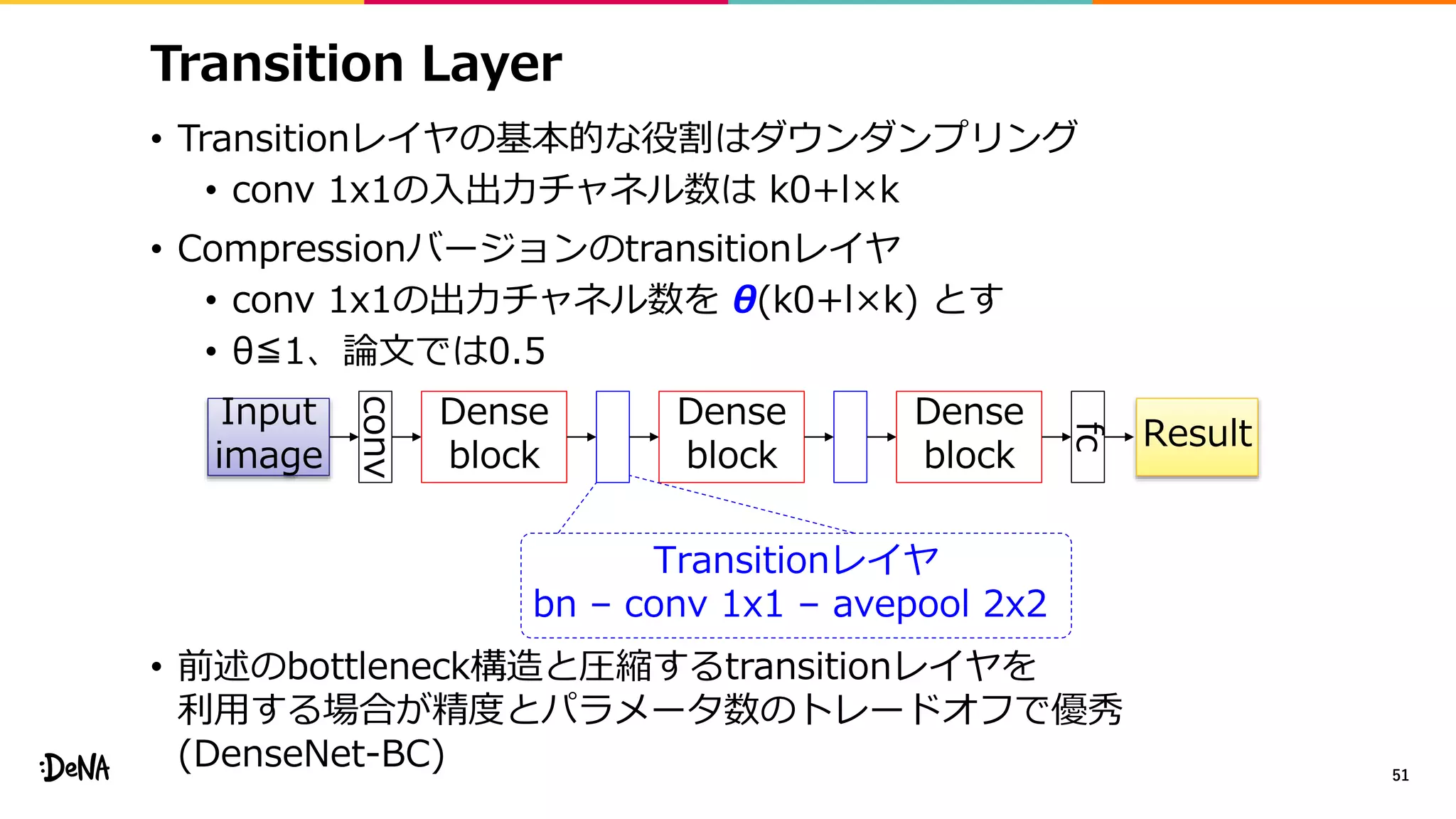
• 特徴マップレベルでのデータ拡張
• 画像レベルではcroppingをすることで画像内の物体の比率を変化させ、
その変化にロバストに。特徴マップレベルでも同じことができないか?
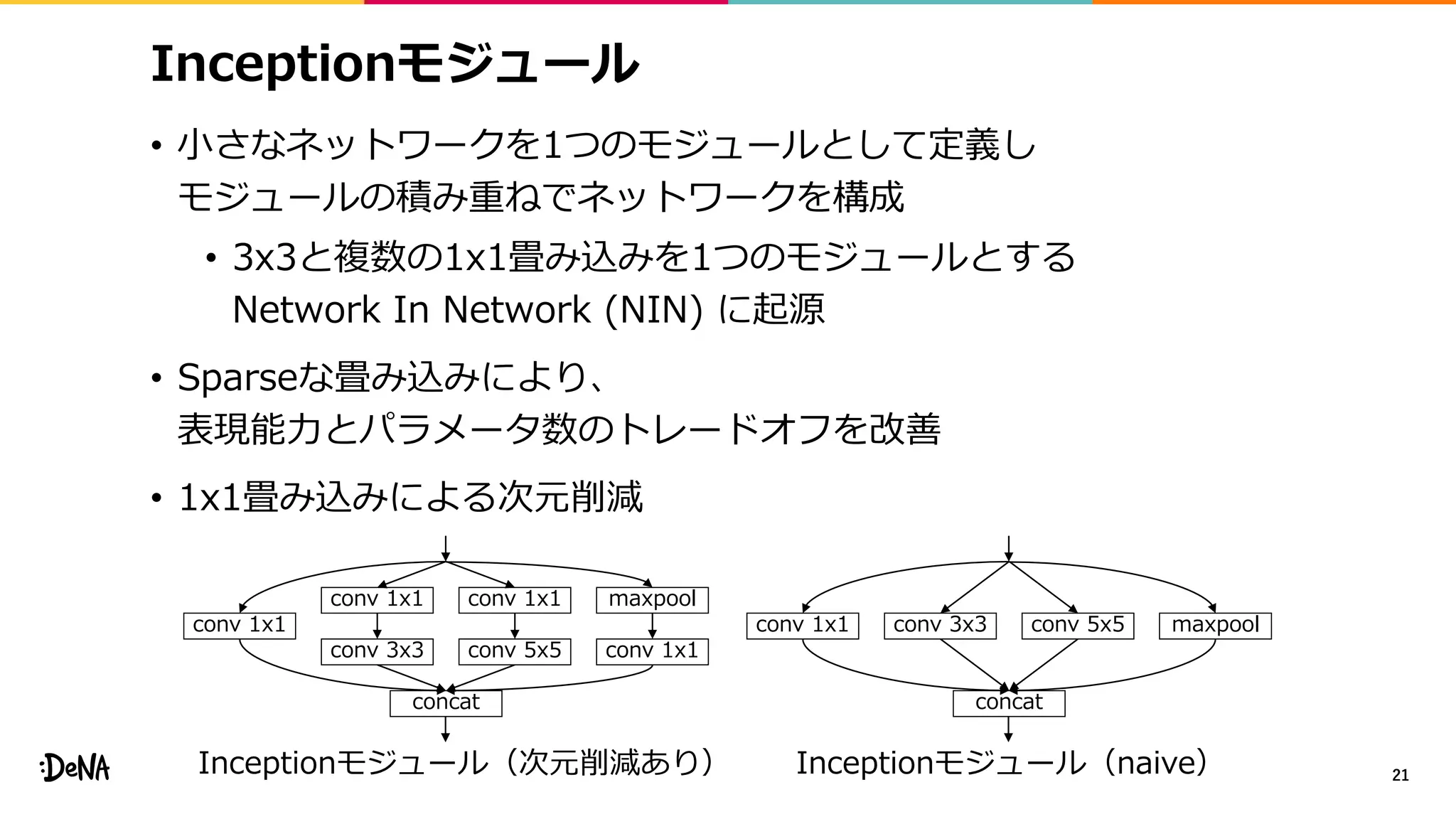
• モジュール内でネットワークを分岐させ画像レベルで
各分岐の出力をランダムな比率(α∈[0, 1])で混合する
• Backward時には違う比率βを利用する
55
conv 3x3
conv 3x3 conv 3x3
conv 3x3
+
** al 1-al
conv 3x3
conv 3x3 conv 3x3
conv 3x3
+
** bl 1-bl
conv 3x3
conv 3x3 conv 3x3
conv 3x3
+
** 0.5 0.5
Forward Backward Test
X. Gastaldi, "Shake-shake regularization of 3-branch residual networks," in Proc. of ICLR Workshop, 2017.](https://image.slidesharecdn.com/recentadvancesinconvolutionalneuralnetworksandacceleratingdnns-190515042518/75/slide-55-2048.jpg)
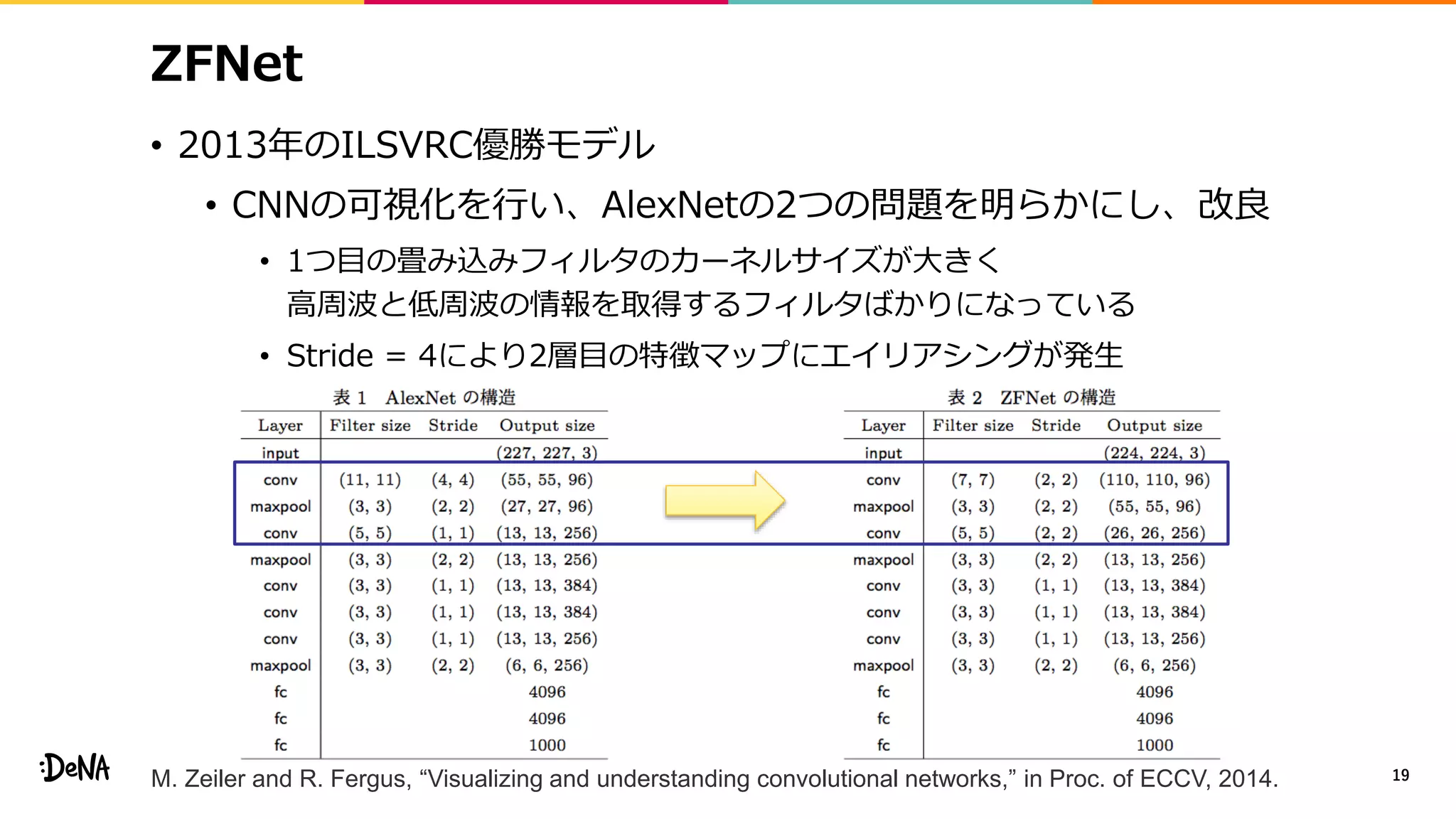
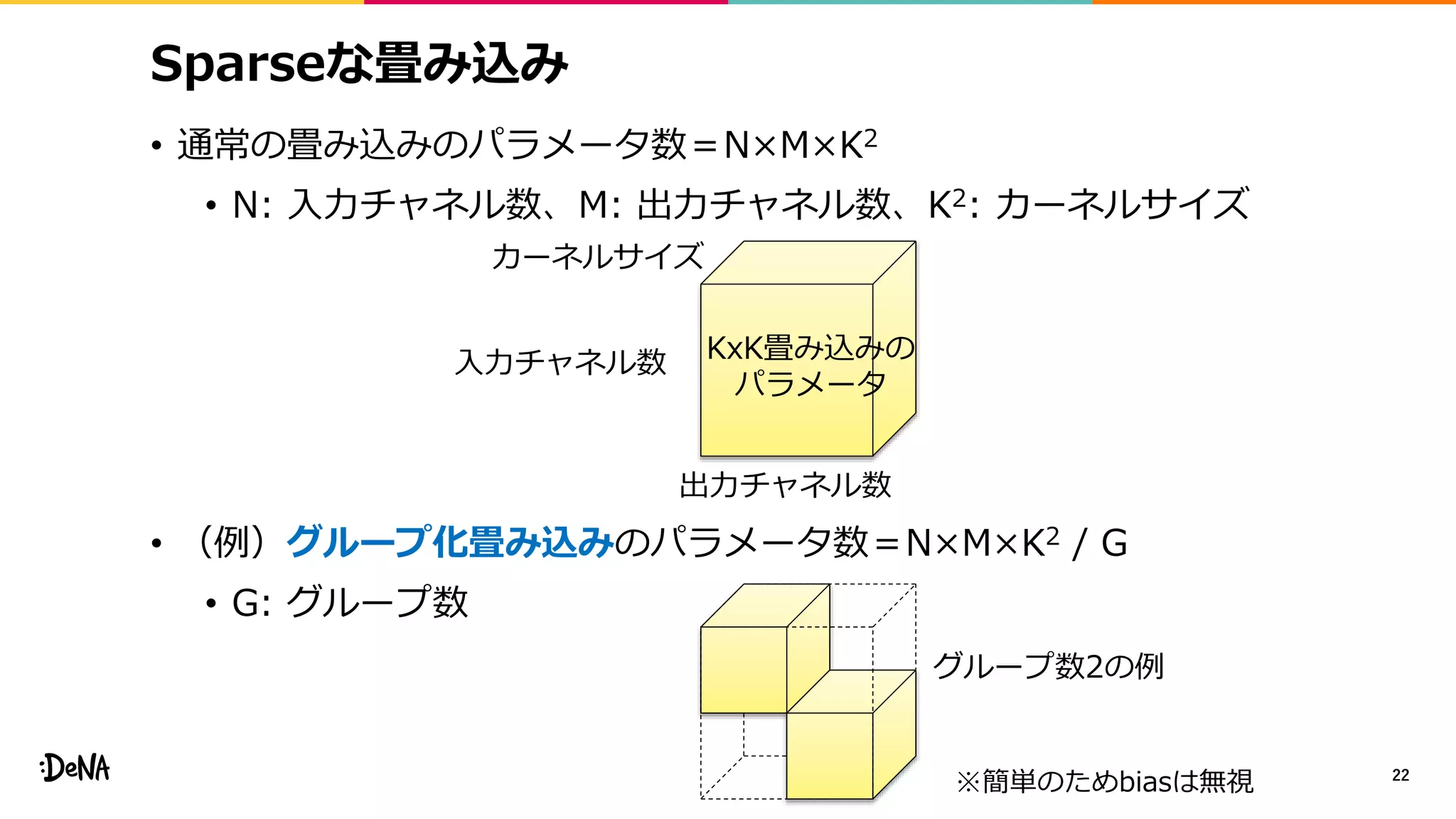
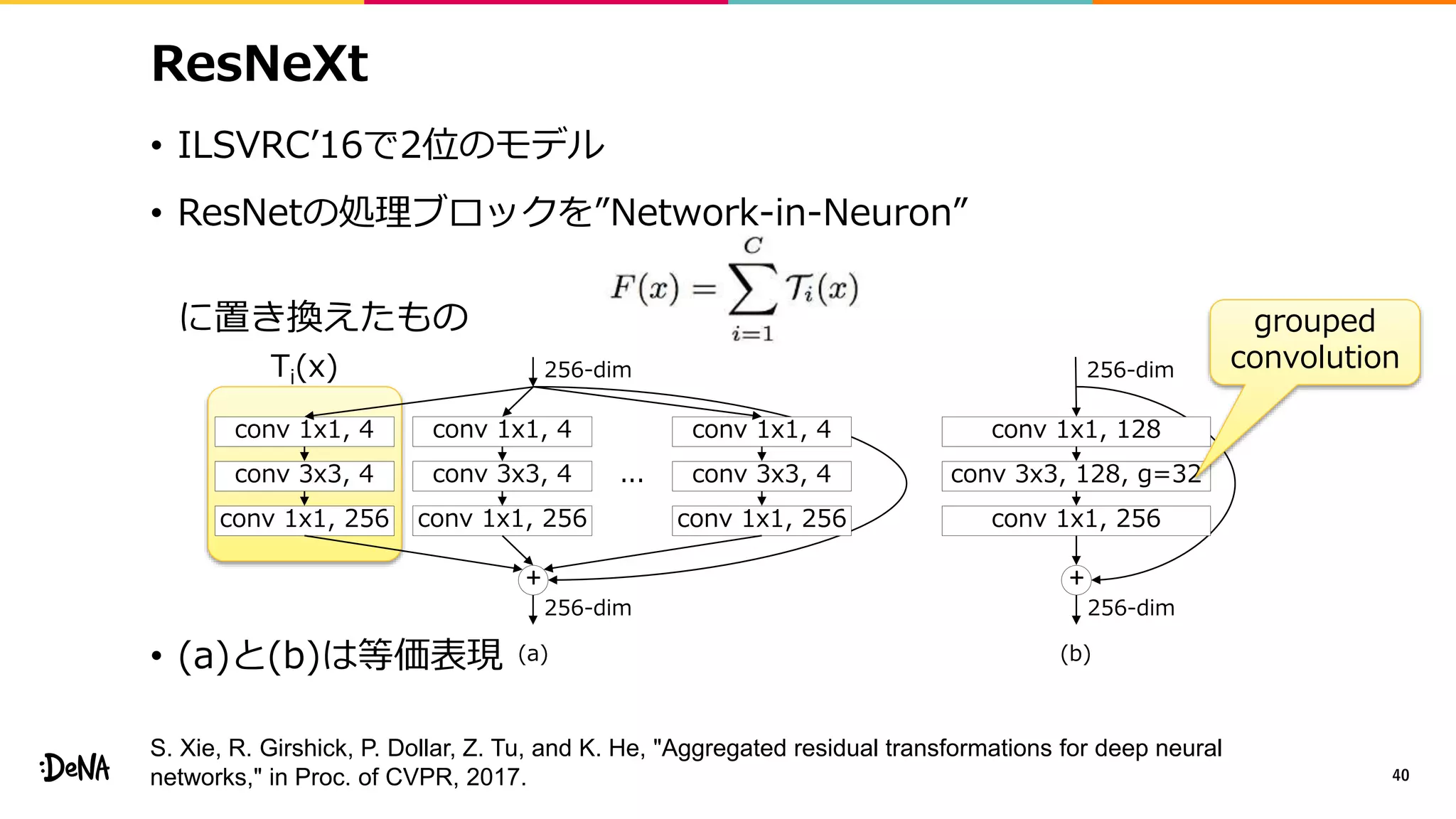
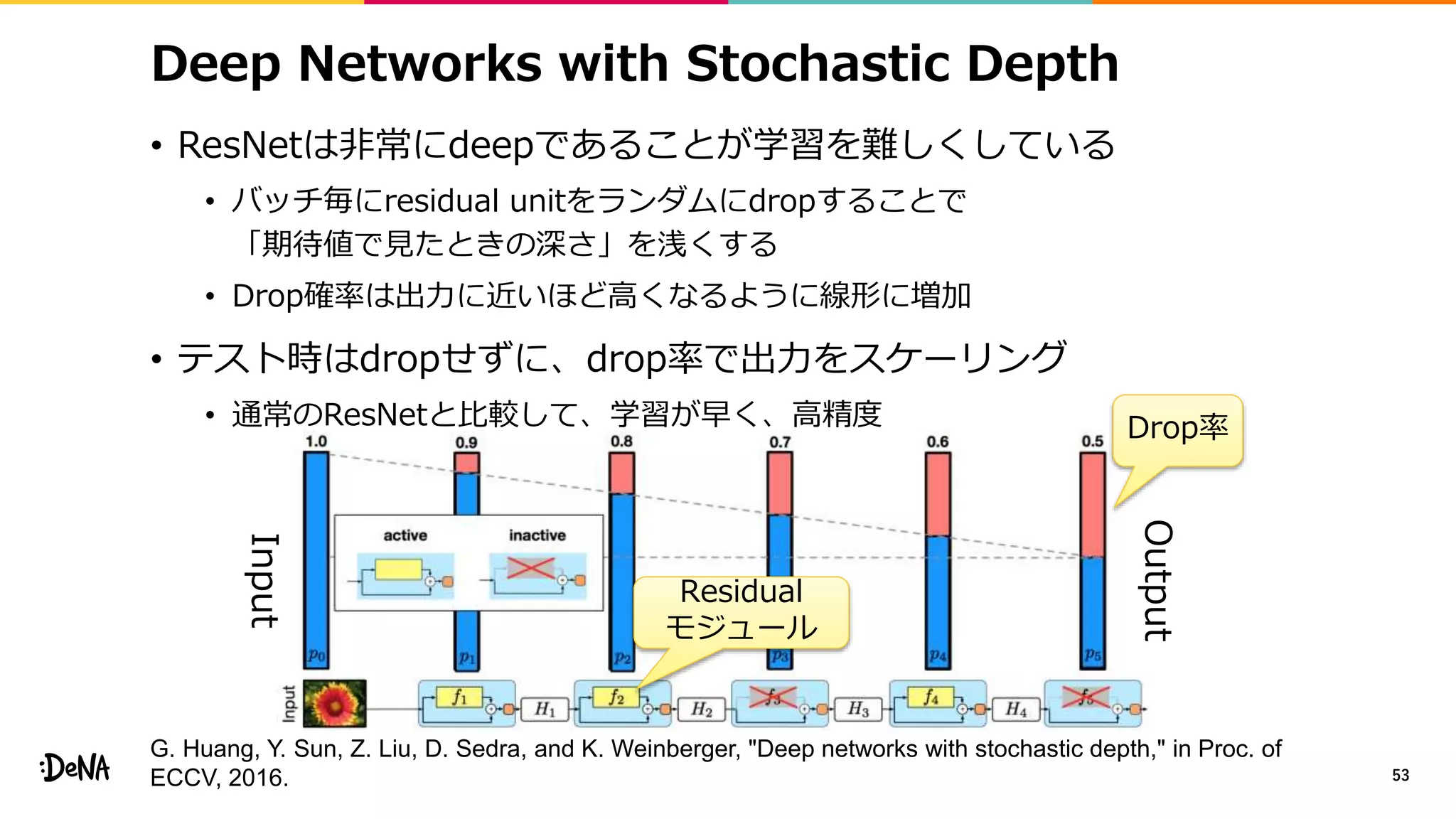
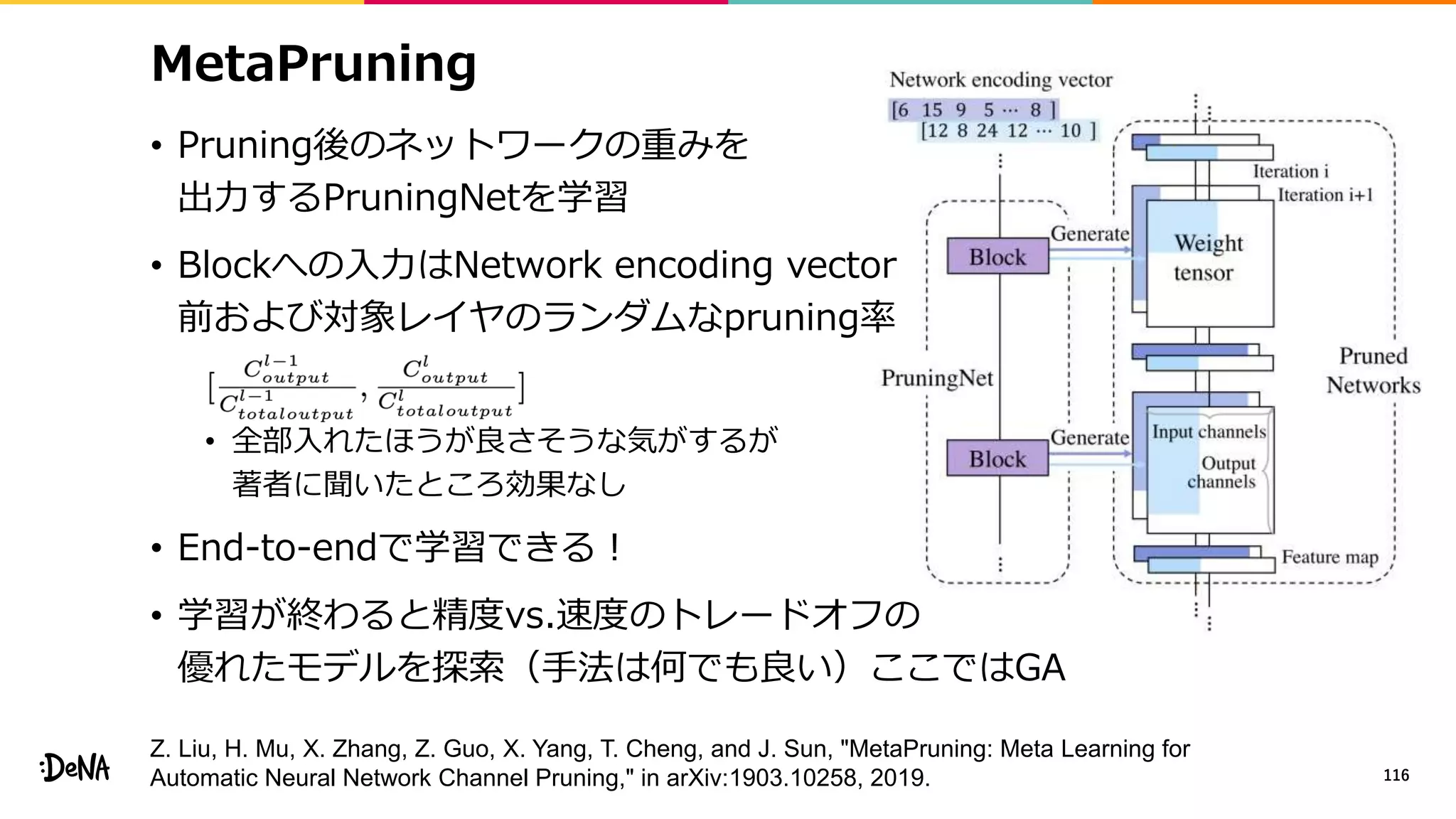
![ShakeDrop
• 分岐させずに特徴マップに対する外乱を加えられないか
• PyramidNetとShakeShakeの統合
• PyramidNetにおいてdropさせる代わりにShakeShakeのような
外乱を加える(forward α倍、backward β倍)
• α∈[−1,1]、β∈[0,1]、チャネルレベルの外乱が最も良い
56
conv 3x3
conv 3x3
** bl 1-bl
Forward
al*
+
conv 3x3
conv 3x3
** bl 1-bl
Backward
bl*
+
conv 3x3
conv 3x3
*
+
Test
E[bl +(1-bl )al ]
Y. Yamada, M. Iwamura, and K. Kise, "ShakeDrop regularization," in Proc. of ICLR Workshop, 2018.](https://image.slidesharecdn.com/recentadvancesinconvolutionalneuralnetworksandacceleratingdnns-190515042518/75/slide-56-2048.jpg)

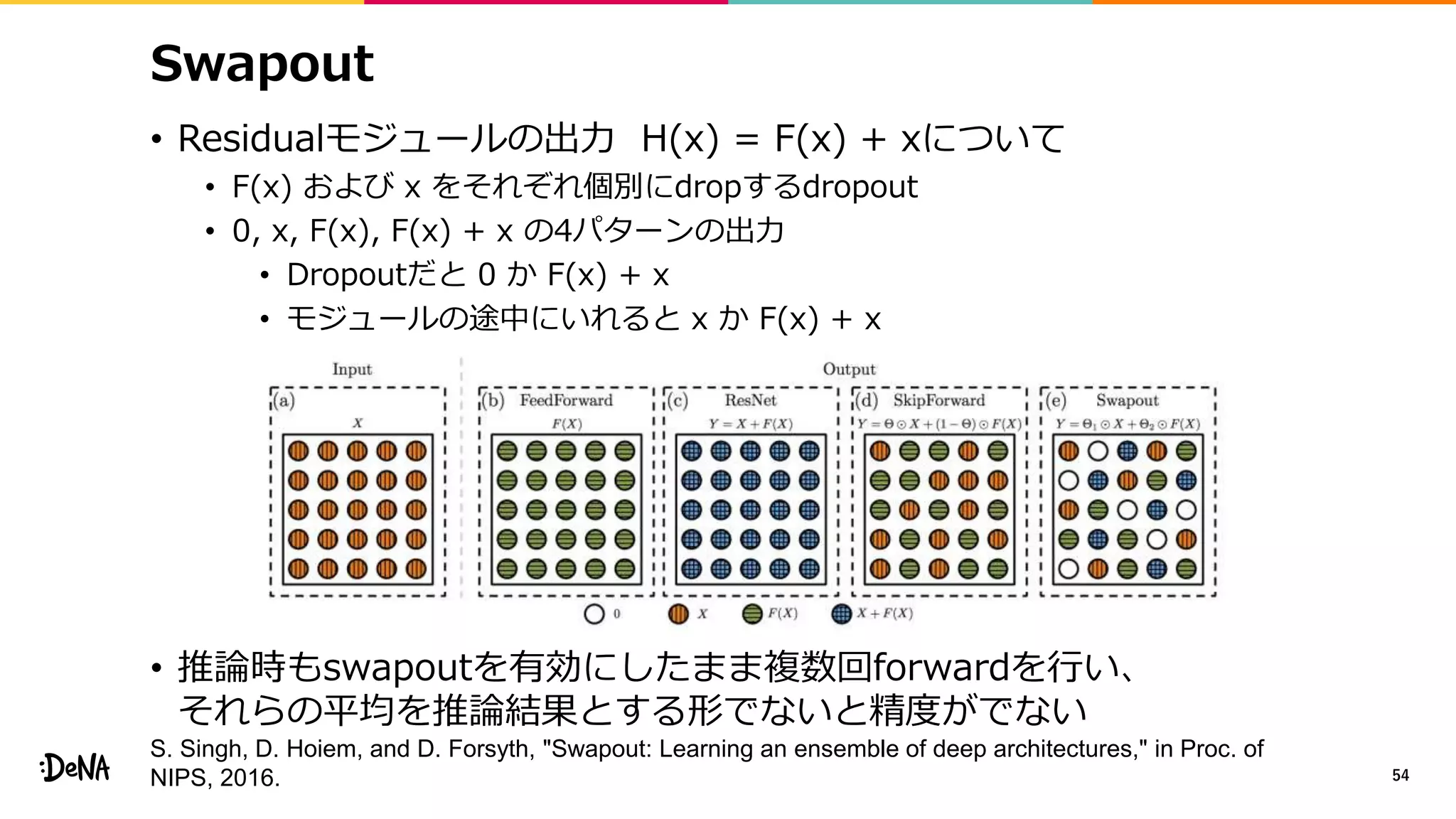
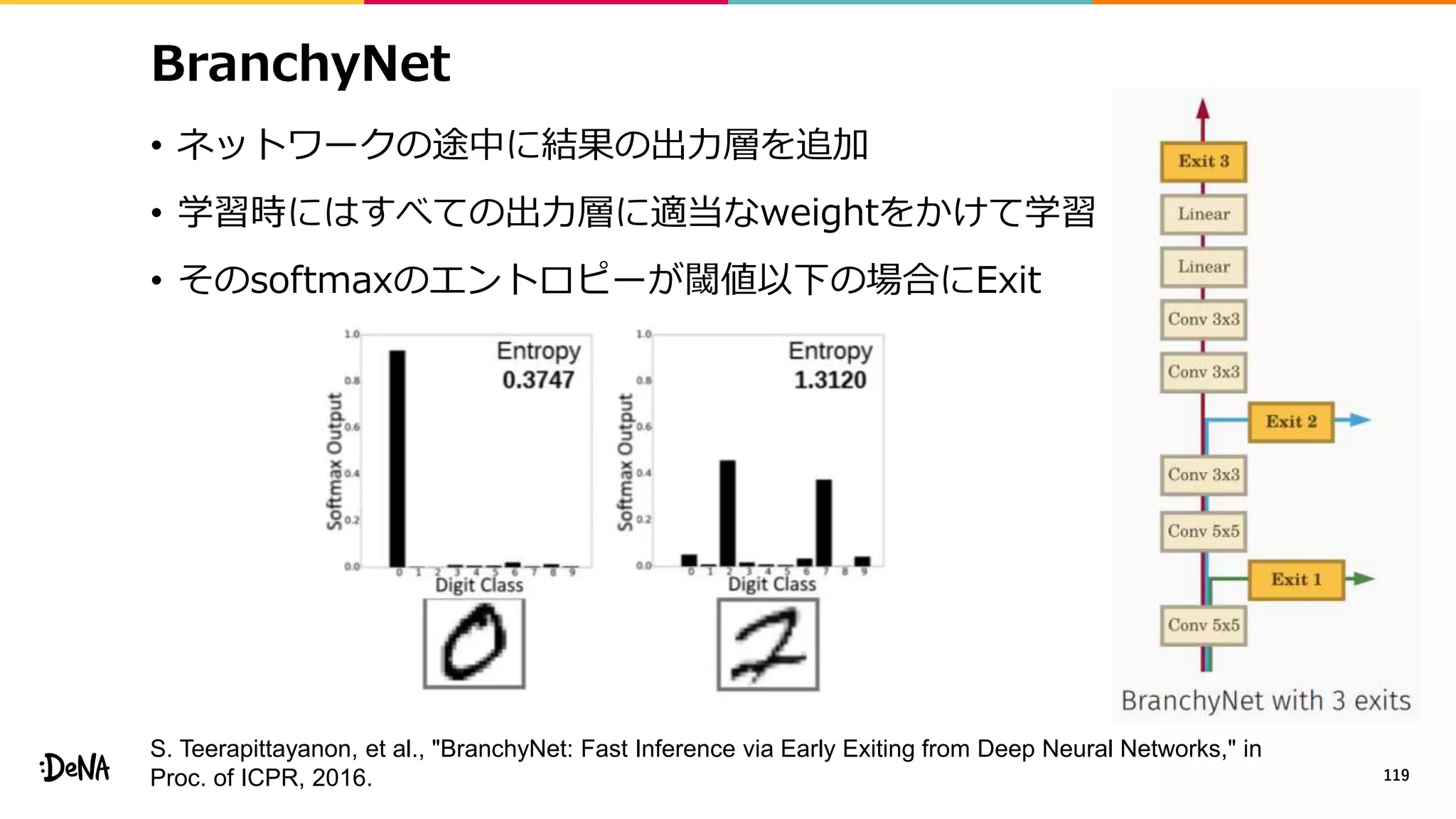
![Mixup* / Between-class Learning**
• データとラベルのペア(X1,y1), (X2,y2)から、新たな訓練サンプル(X,y)を
作成するデータ拡張手法
• X=λX1+(1−λ)X2
y=λy1+(1−λ)y2
• ここでラベルy1,y2はone-hot表現、
X1,X2は任意のベクトルやテンソル
• λ∈[0, 1]はベータ分布Be(α,α)から
サンプリングする
58
* H. Zhang, M. Cisse, Y. N. Dauphin, and D. LopezPaz. mixup, "Beyond empirical risk minimization," in
Proc. of ICLR, 2018
** Y. Tokozume, Y. Ushiku, and T. Harada, "Between-class Learning for Image Classification," in Proc. of
CVPR, 2018](https://image.slidesharecdn.com/recentadvancesinconvolutionalneuralnetworksandacceleratingdnns-190515042518/75/slide-58-2048.jpg)




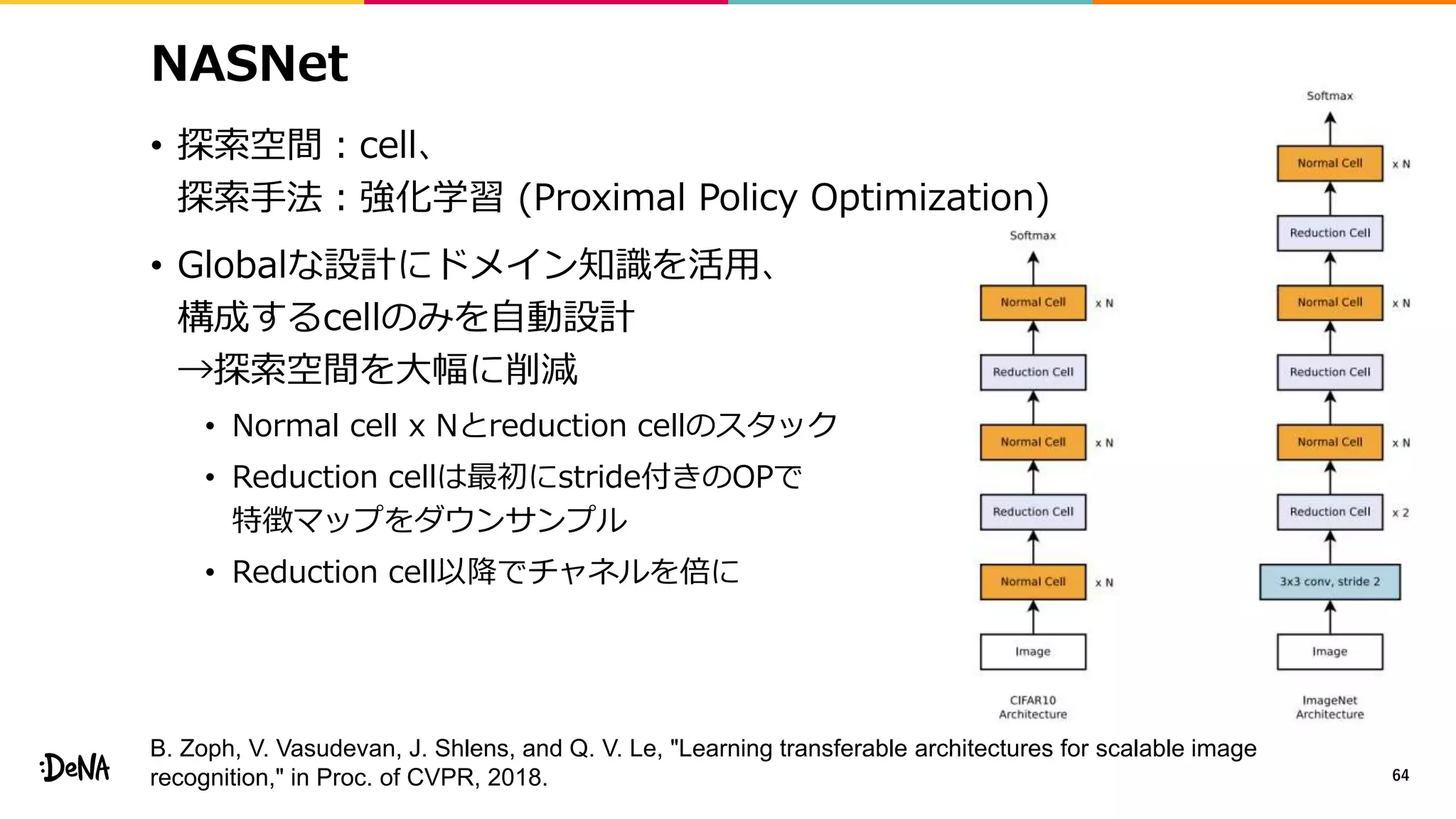
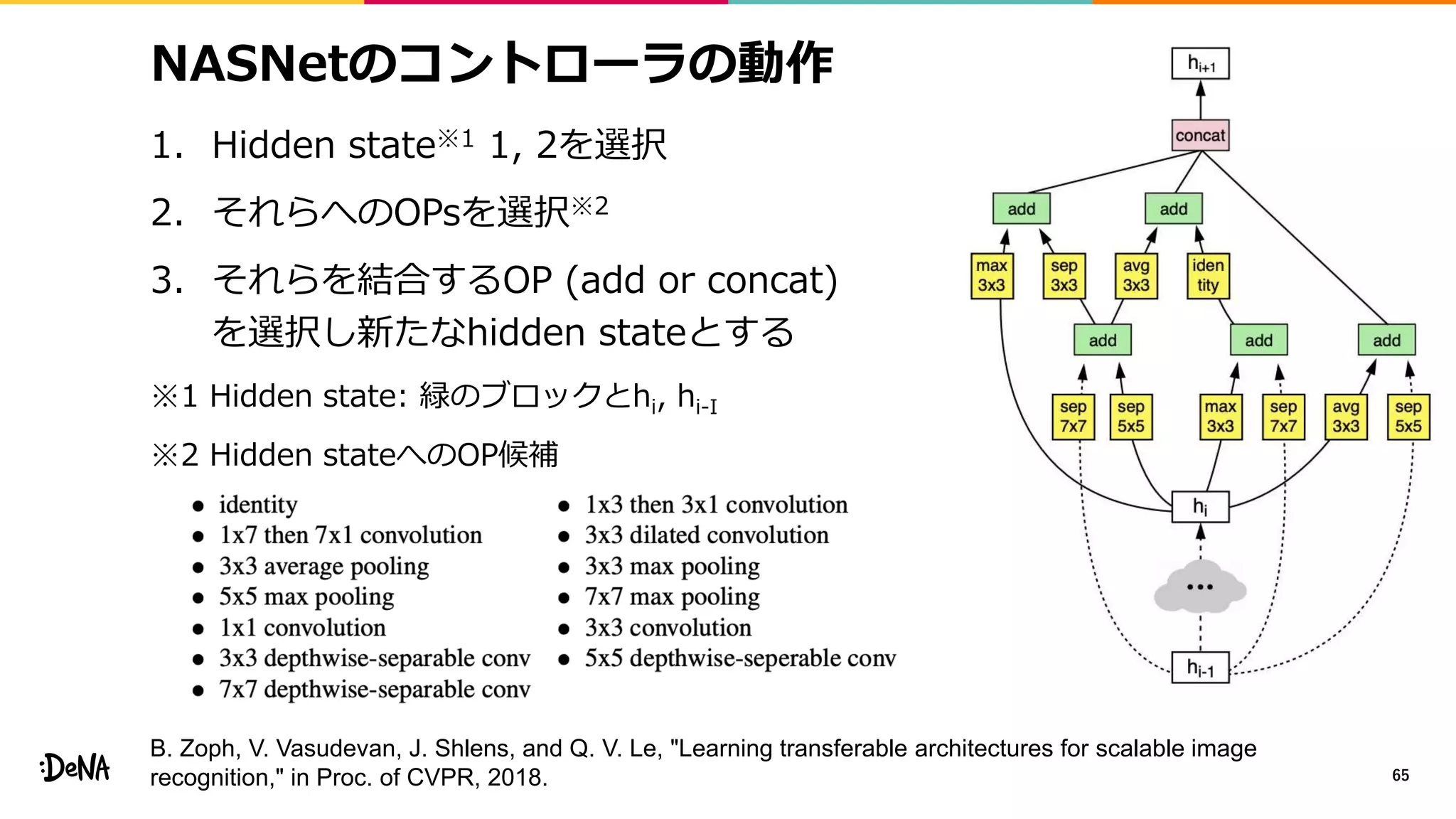
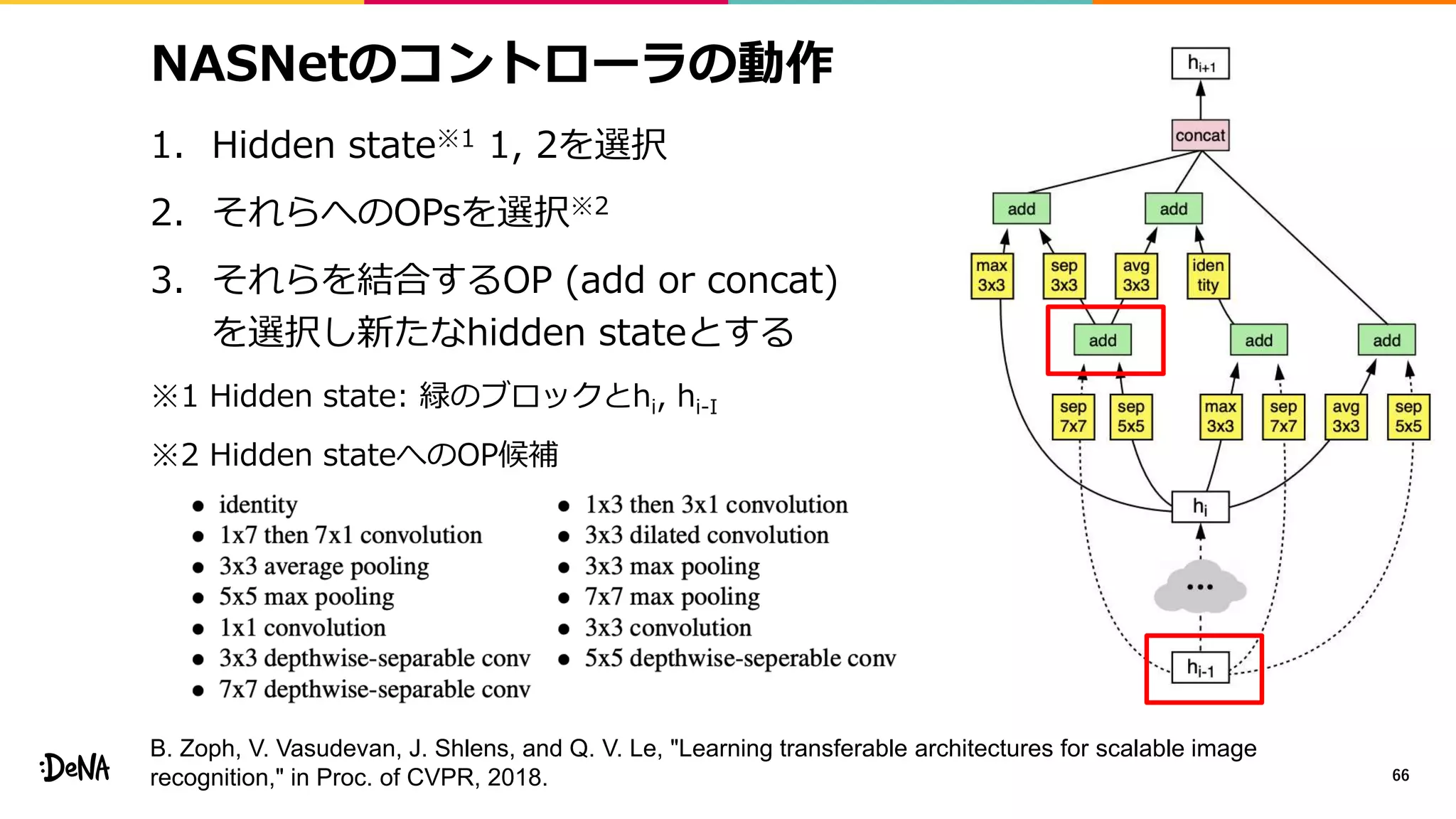
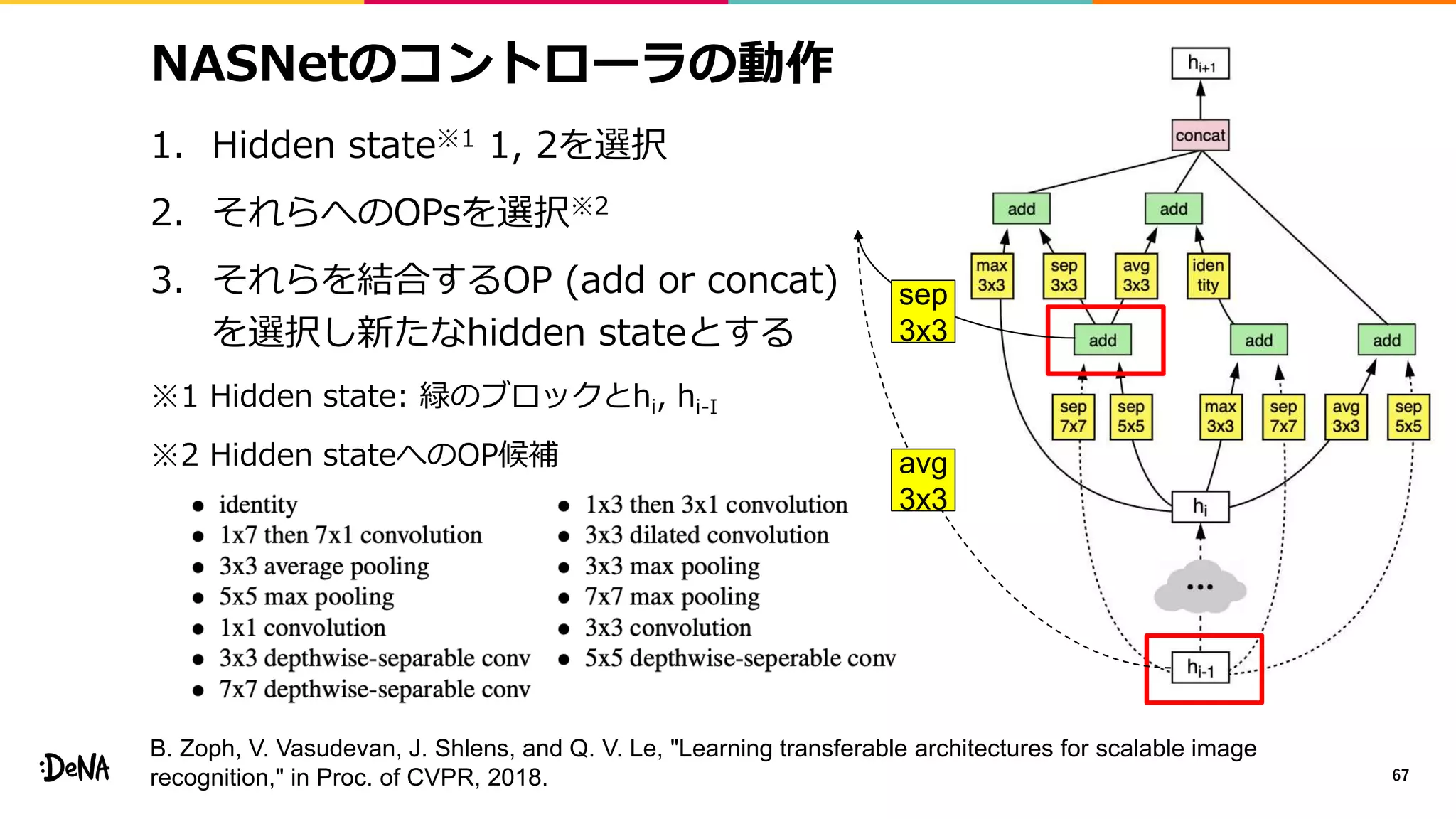
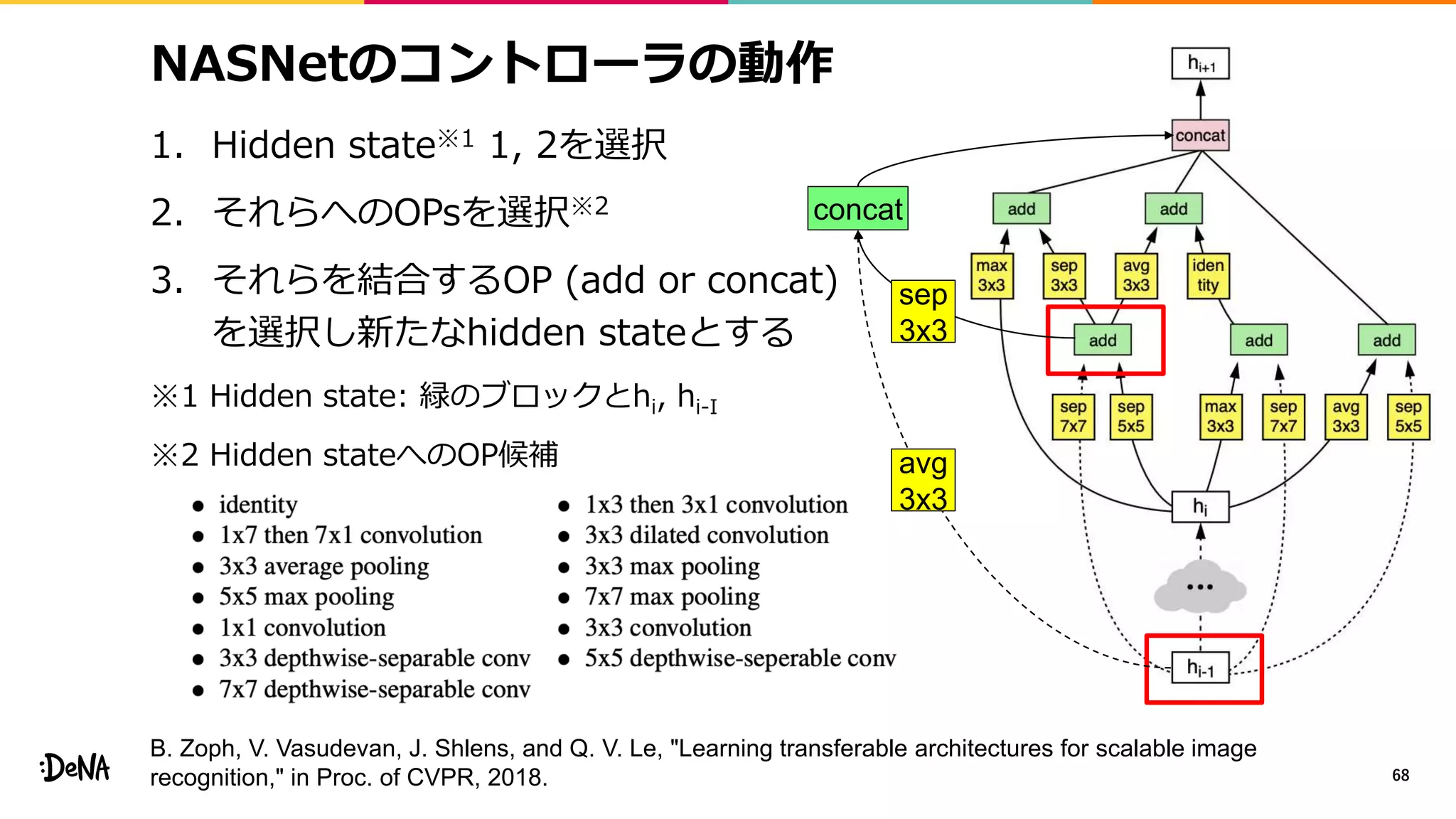
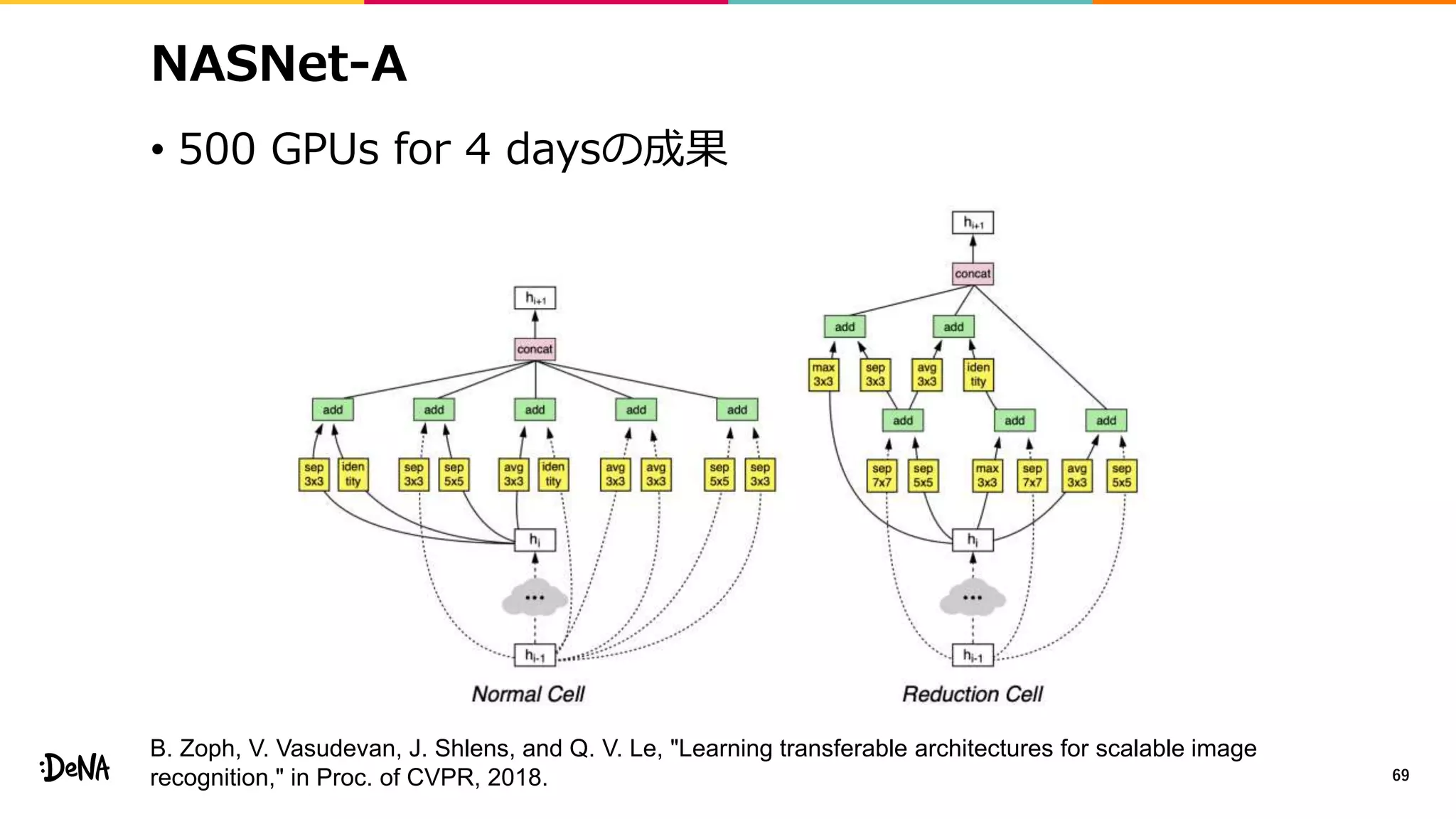
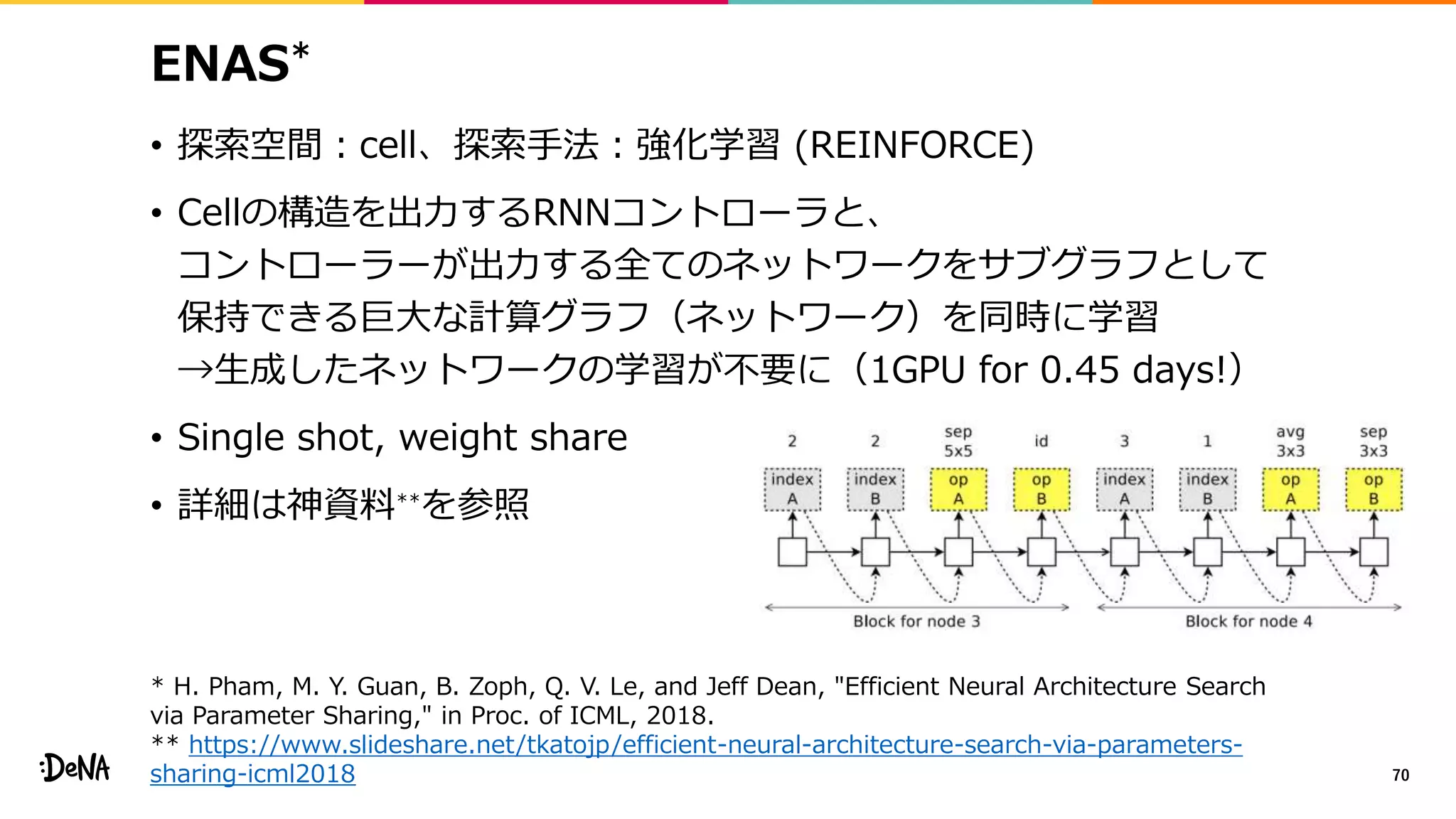

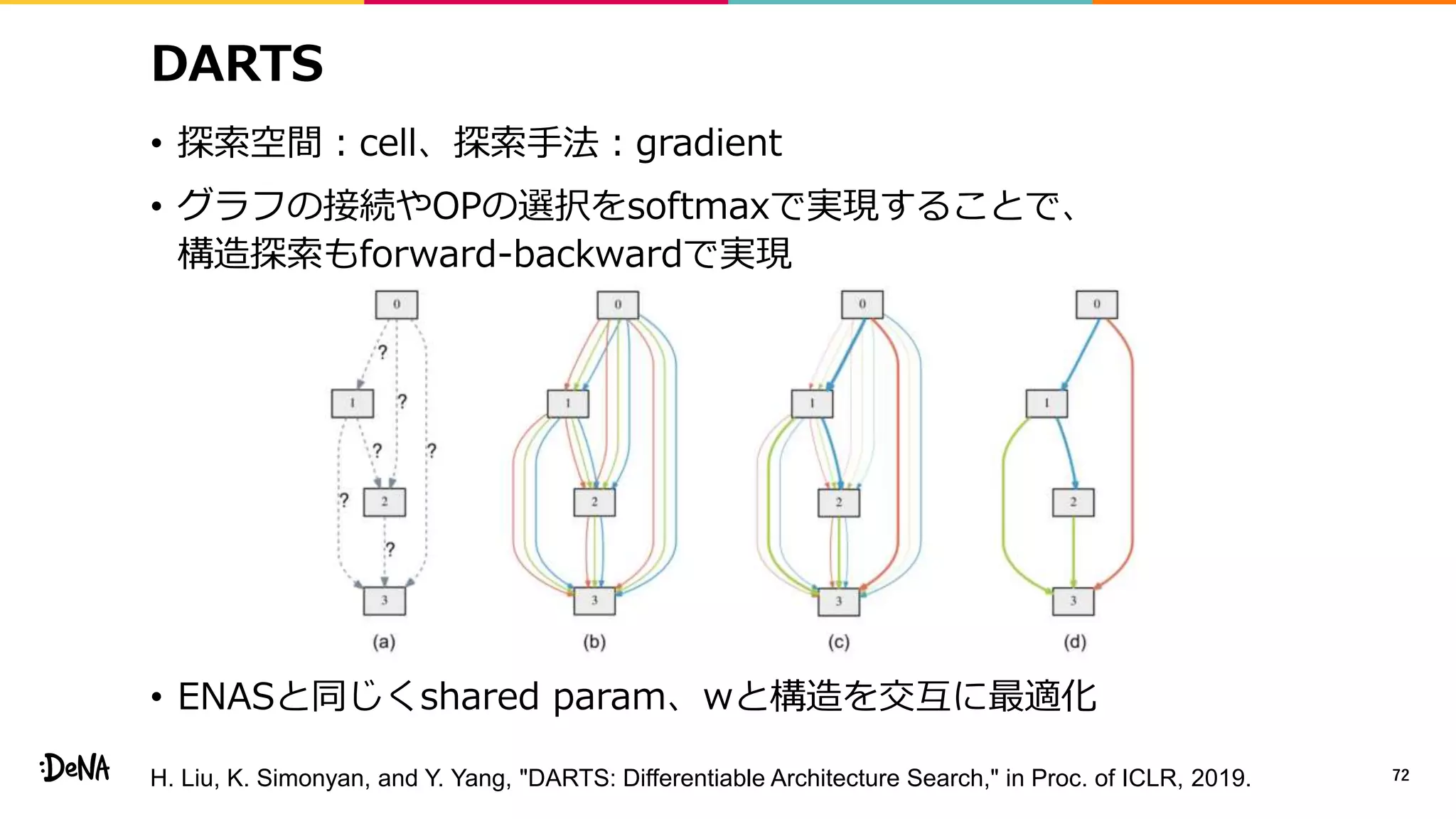


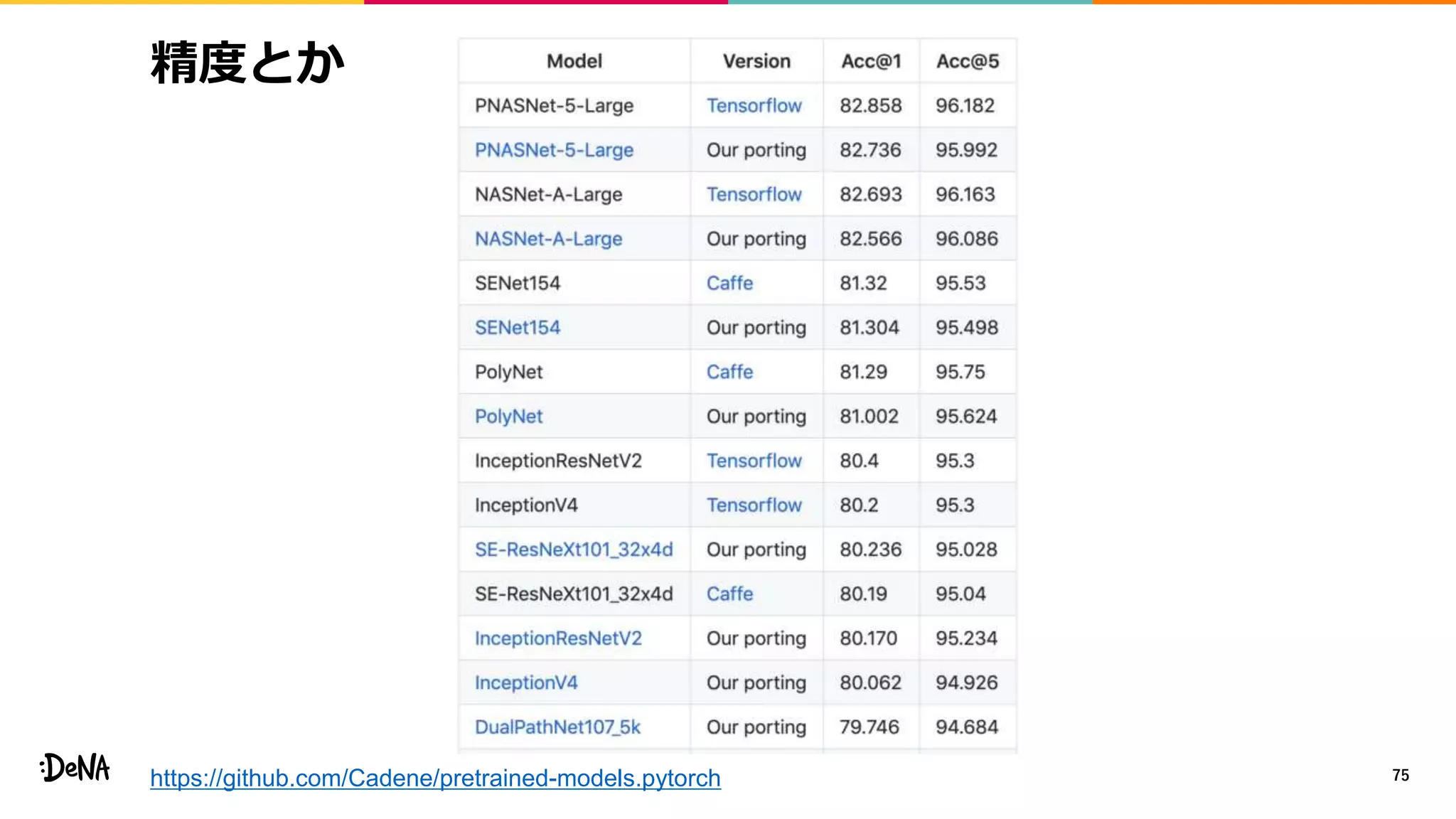
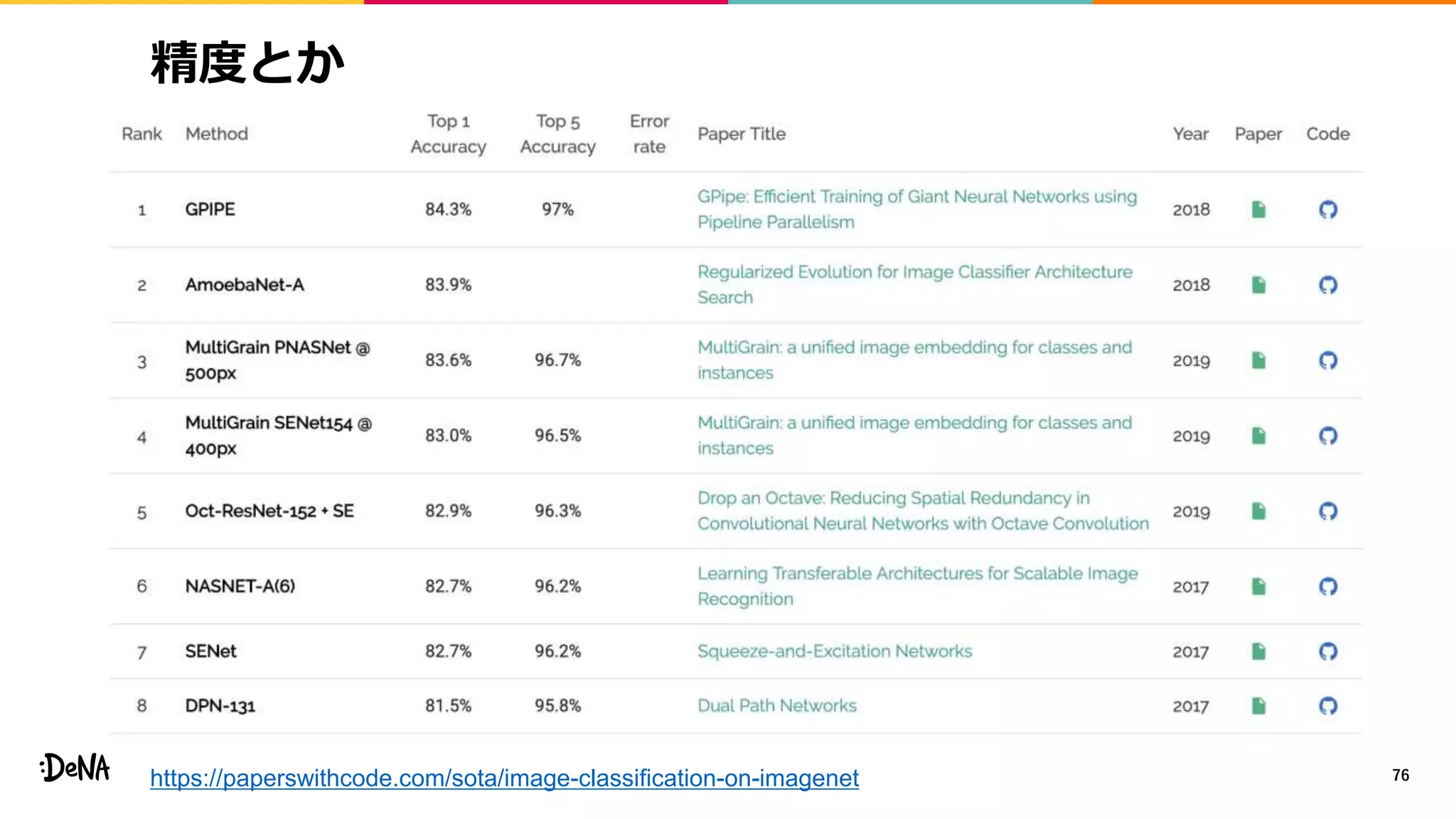



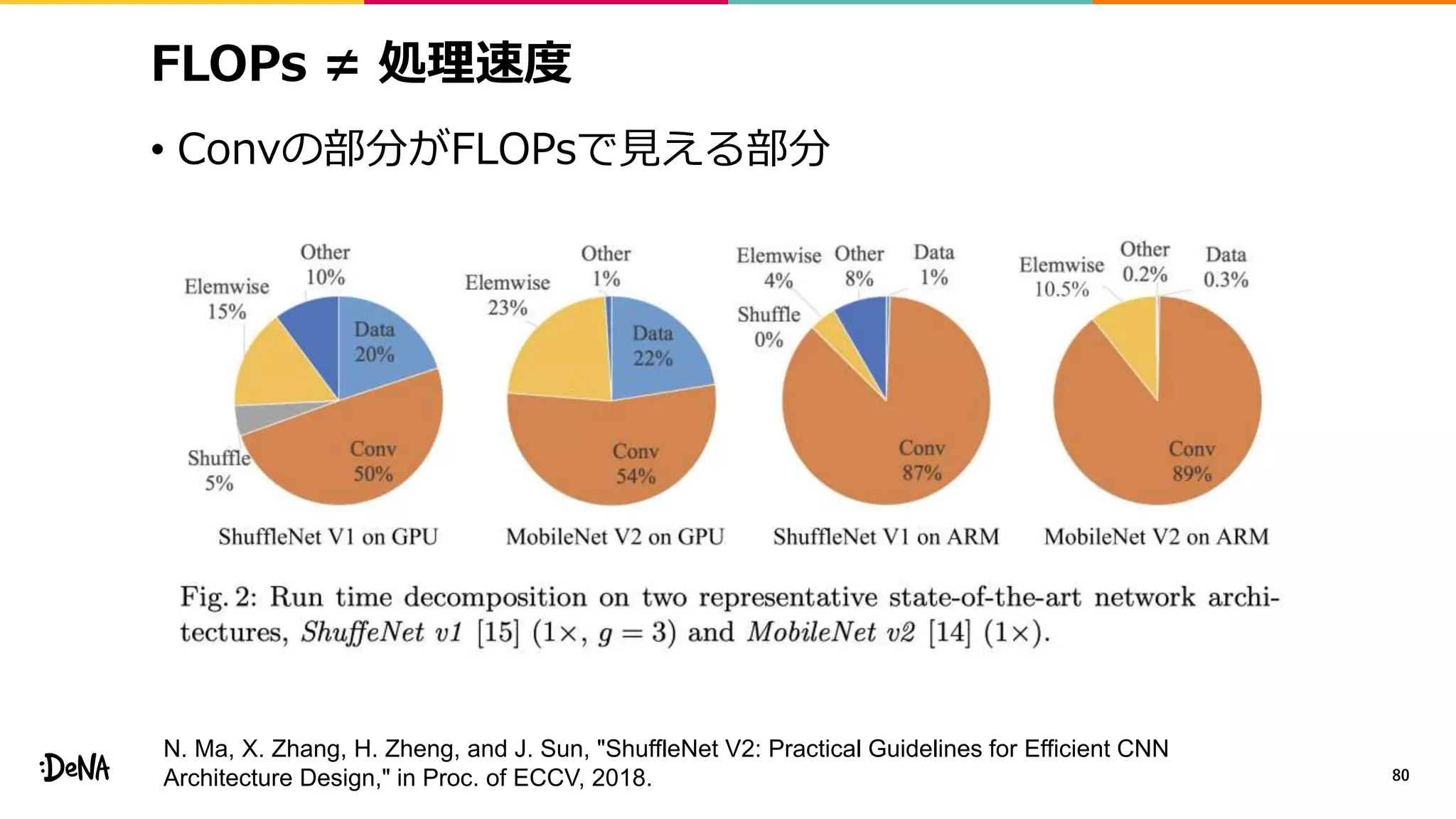
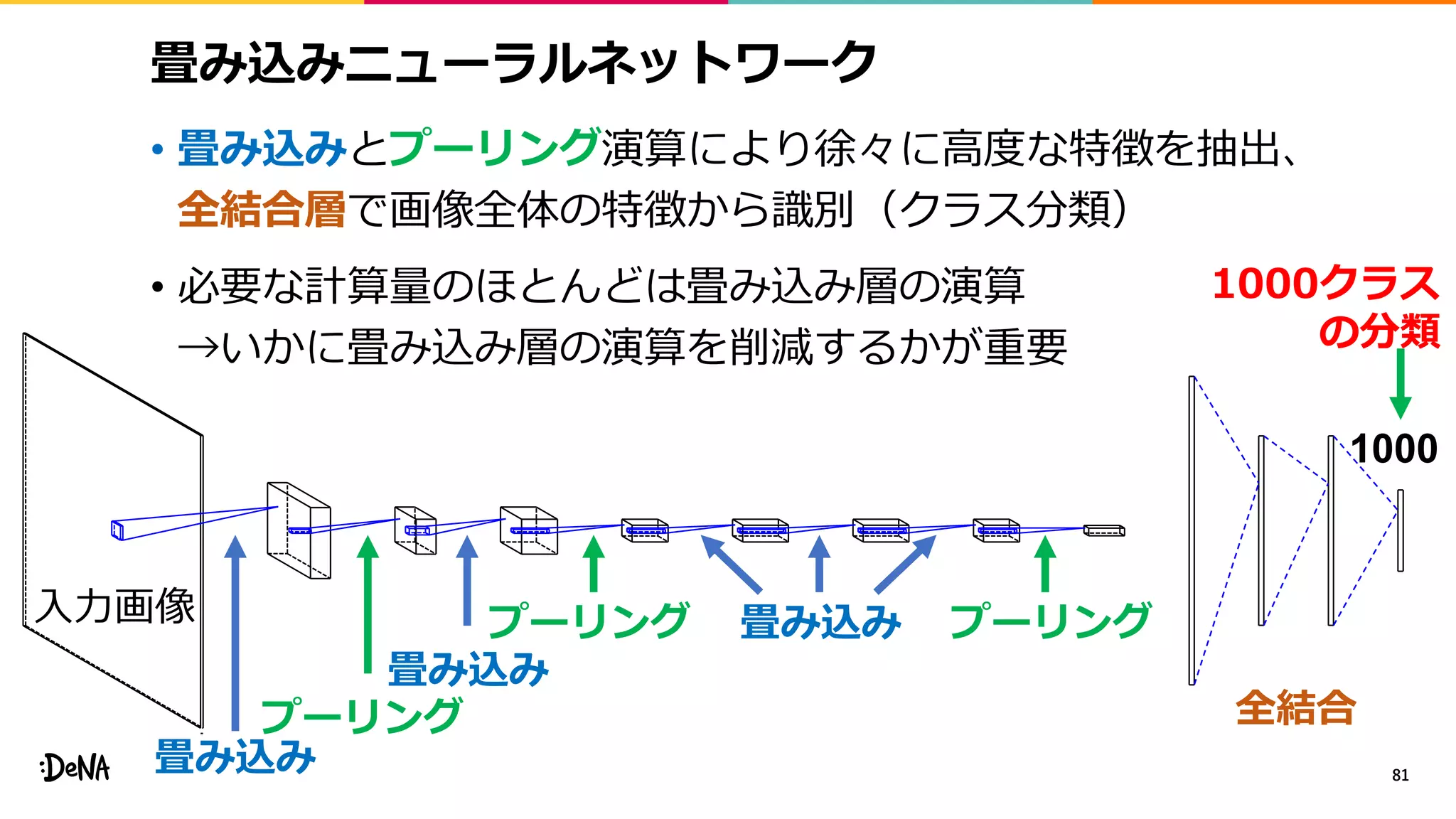


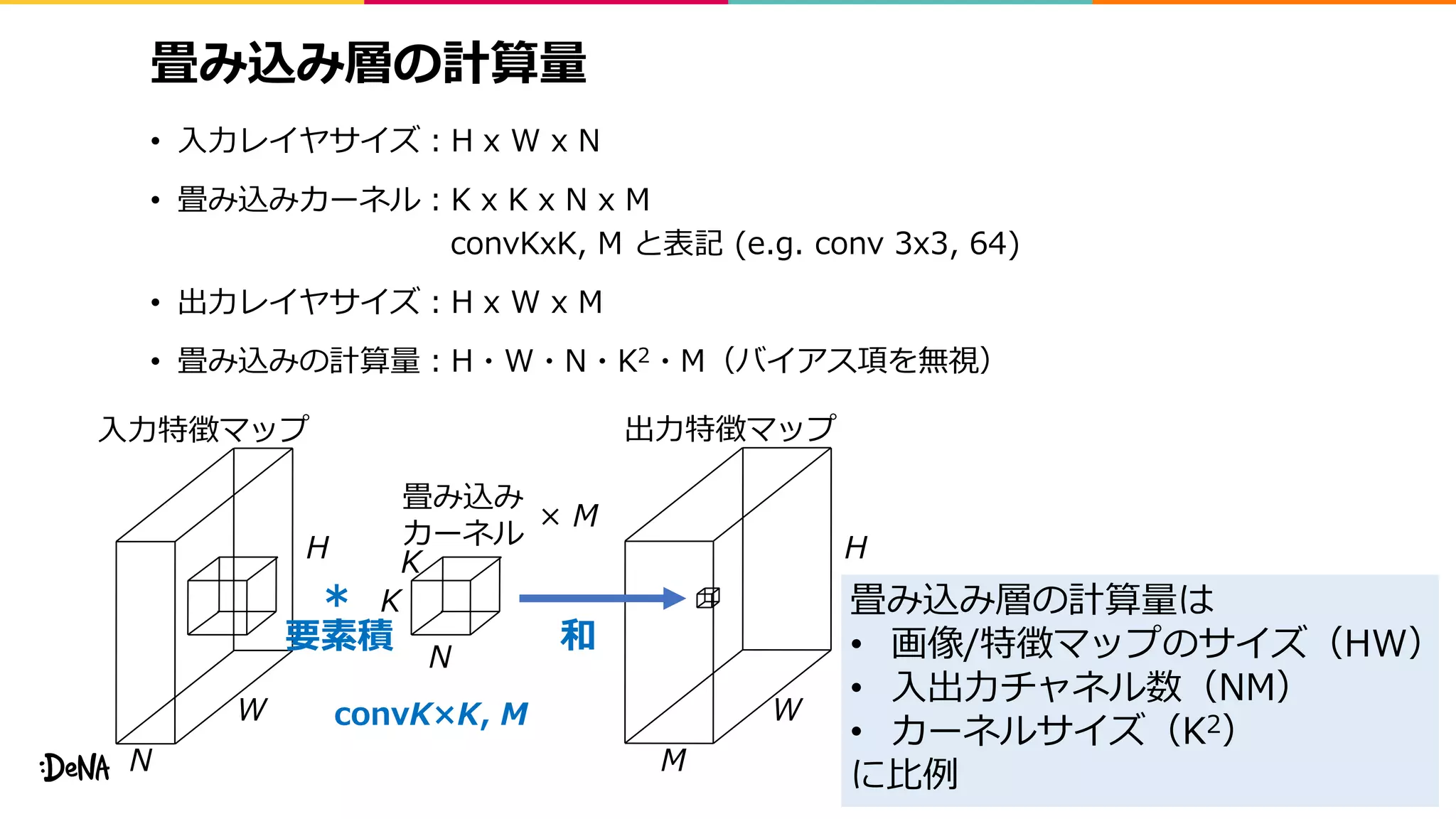
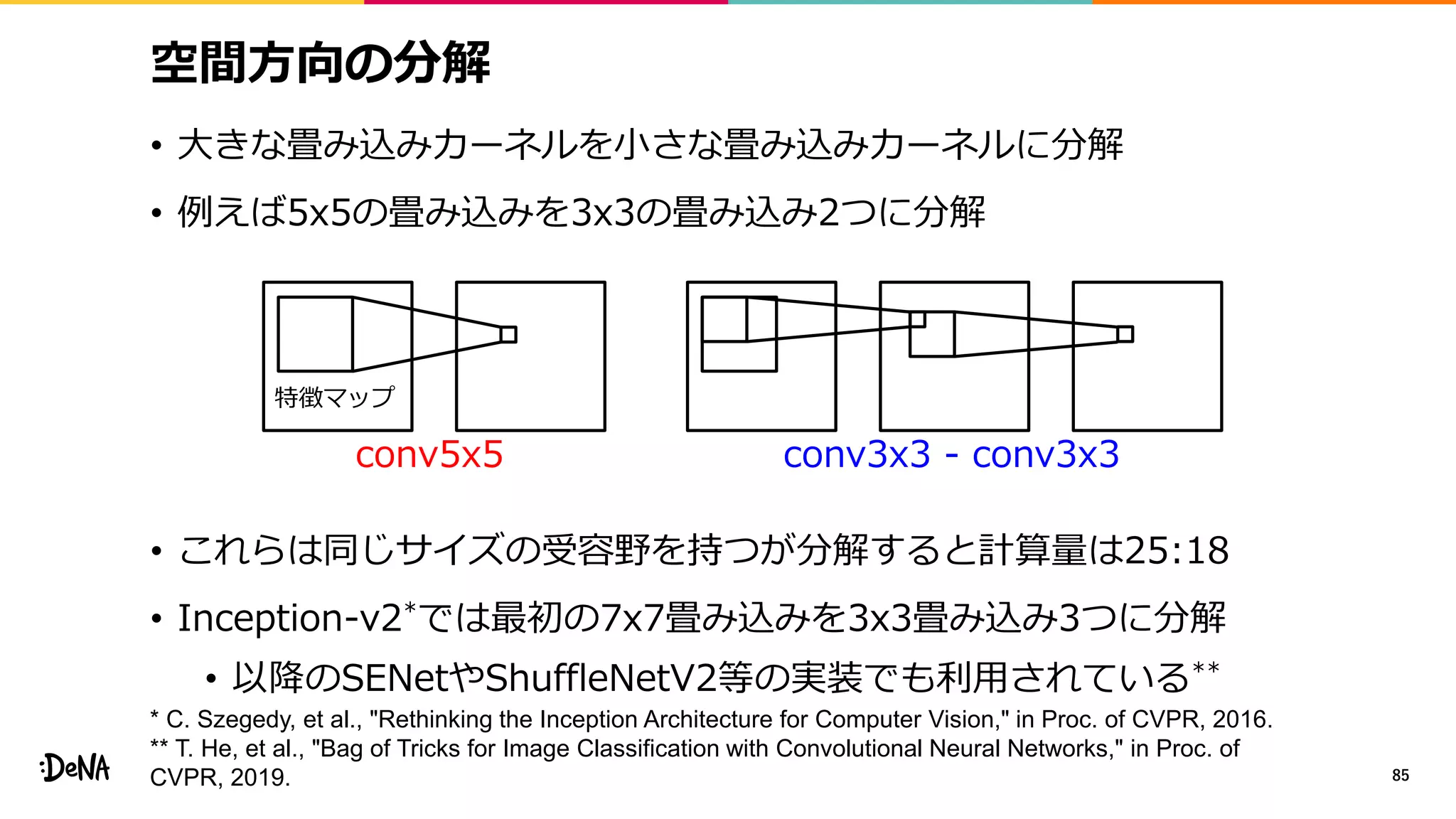
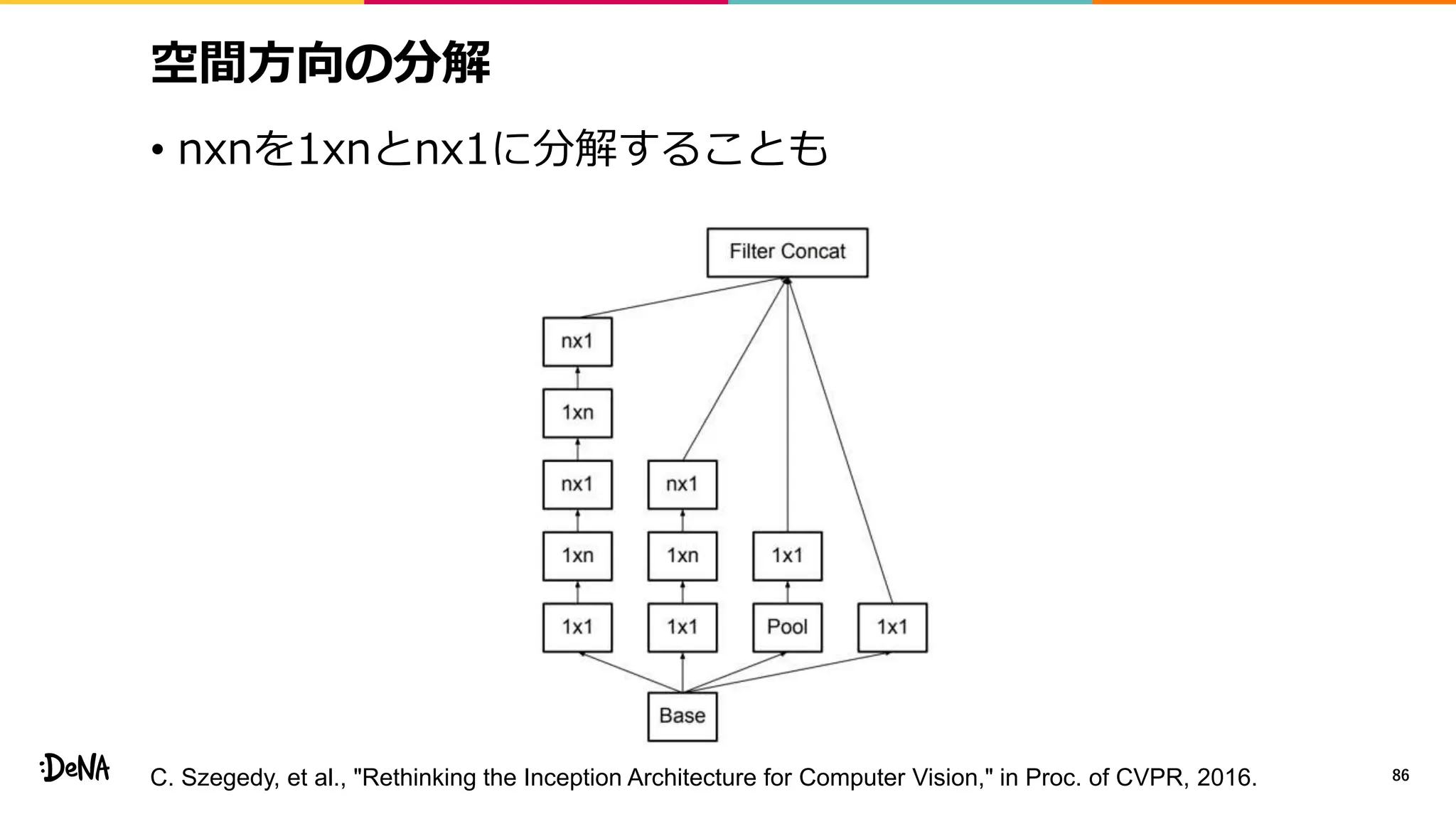
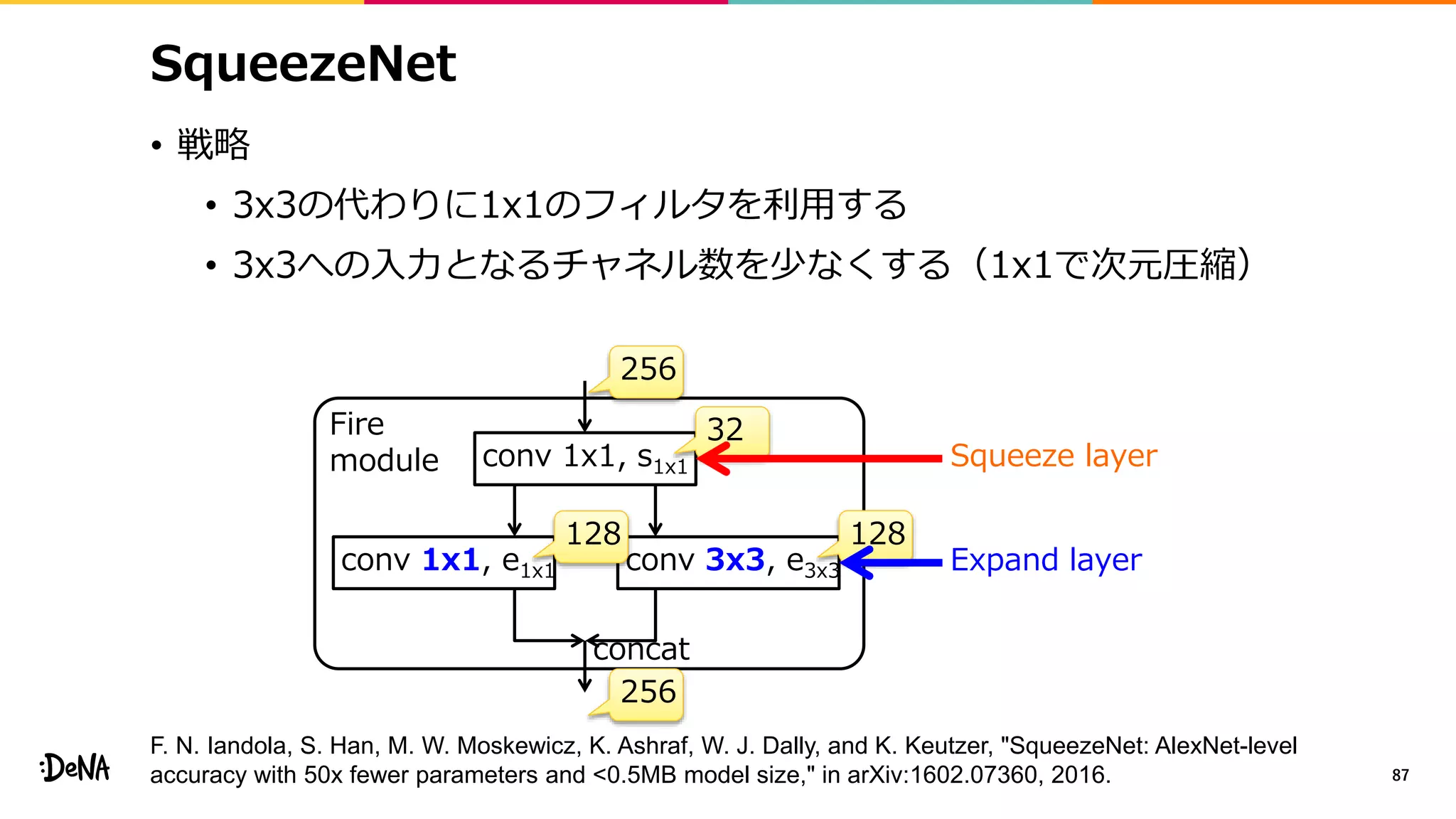
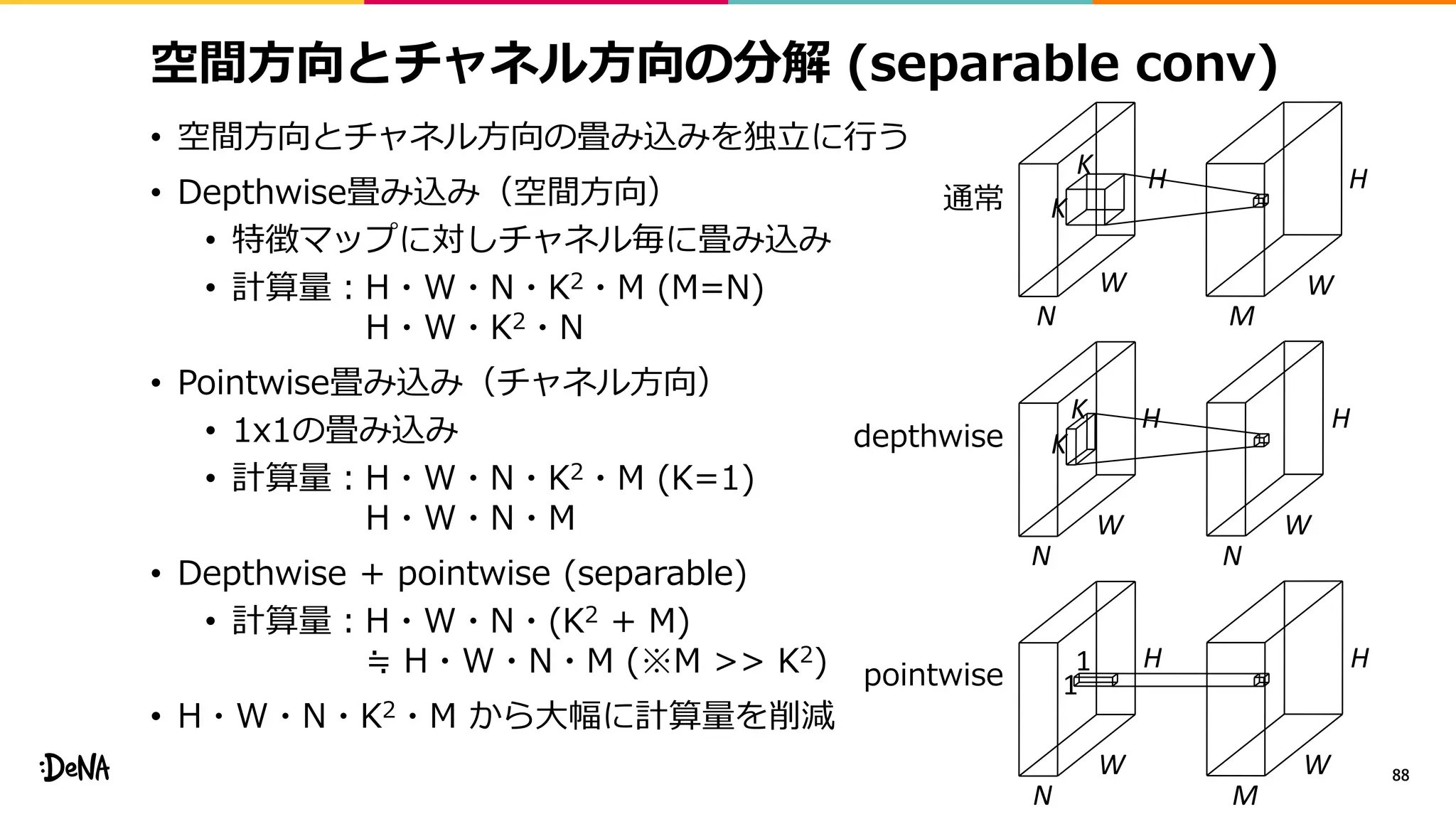
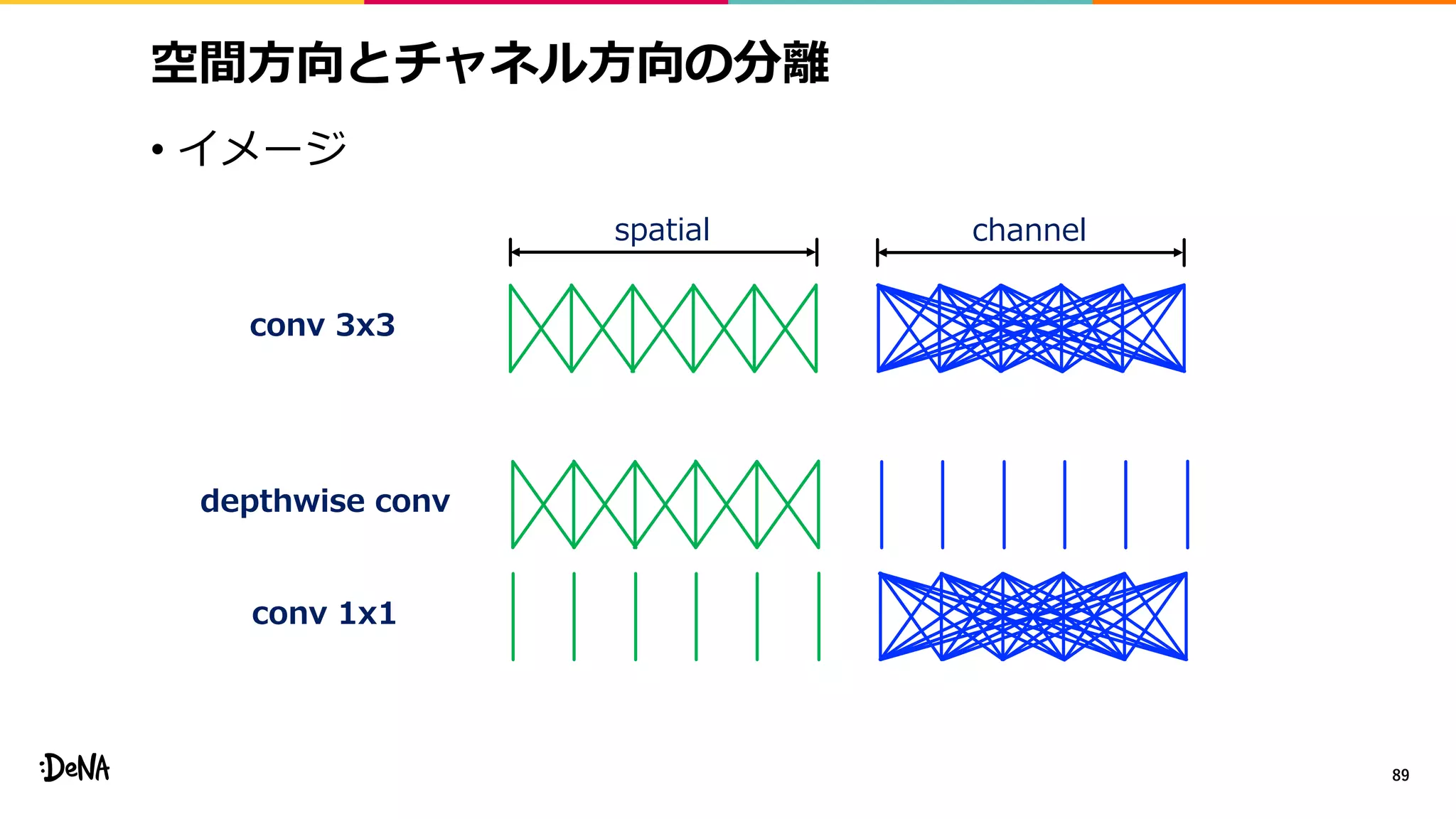
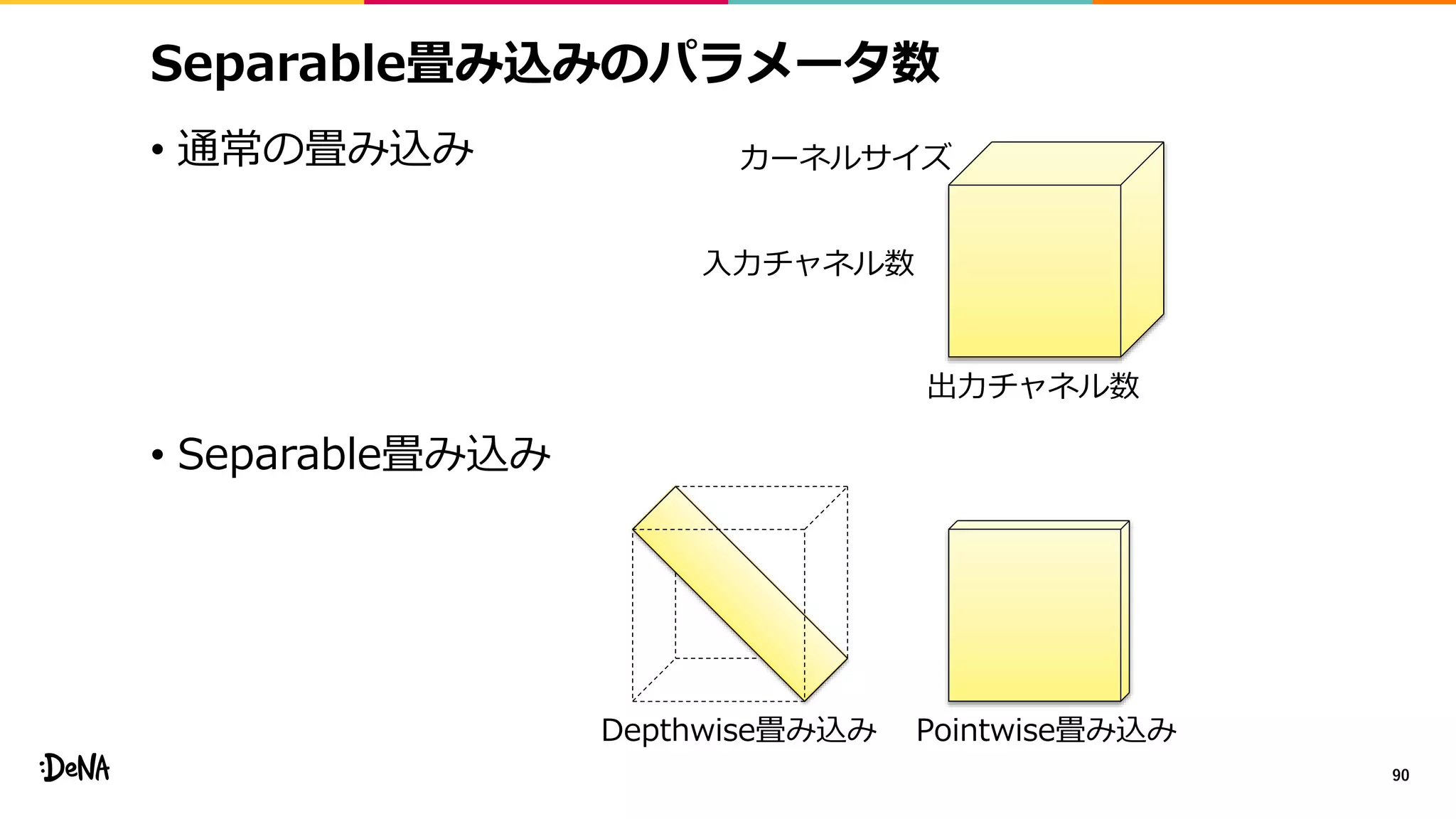
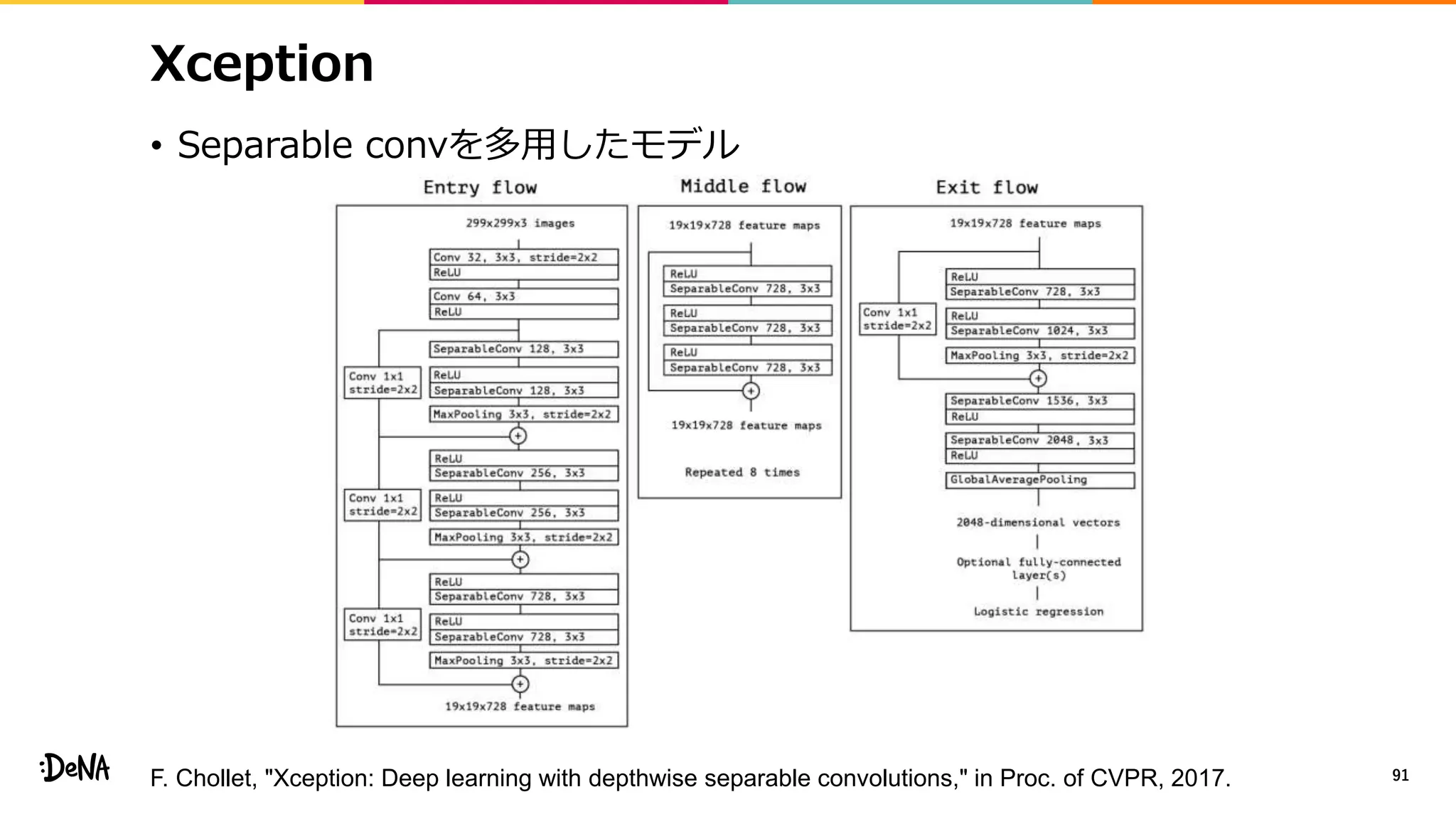

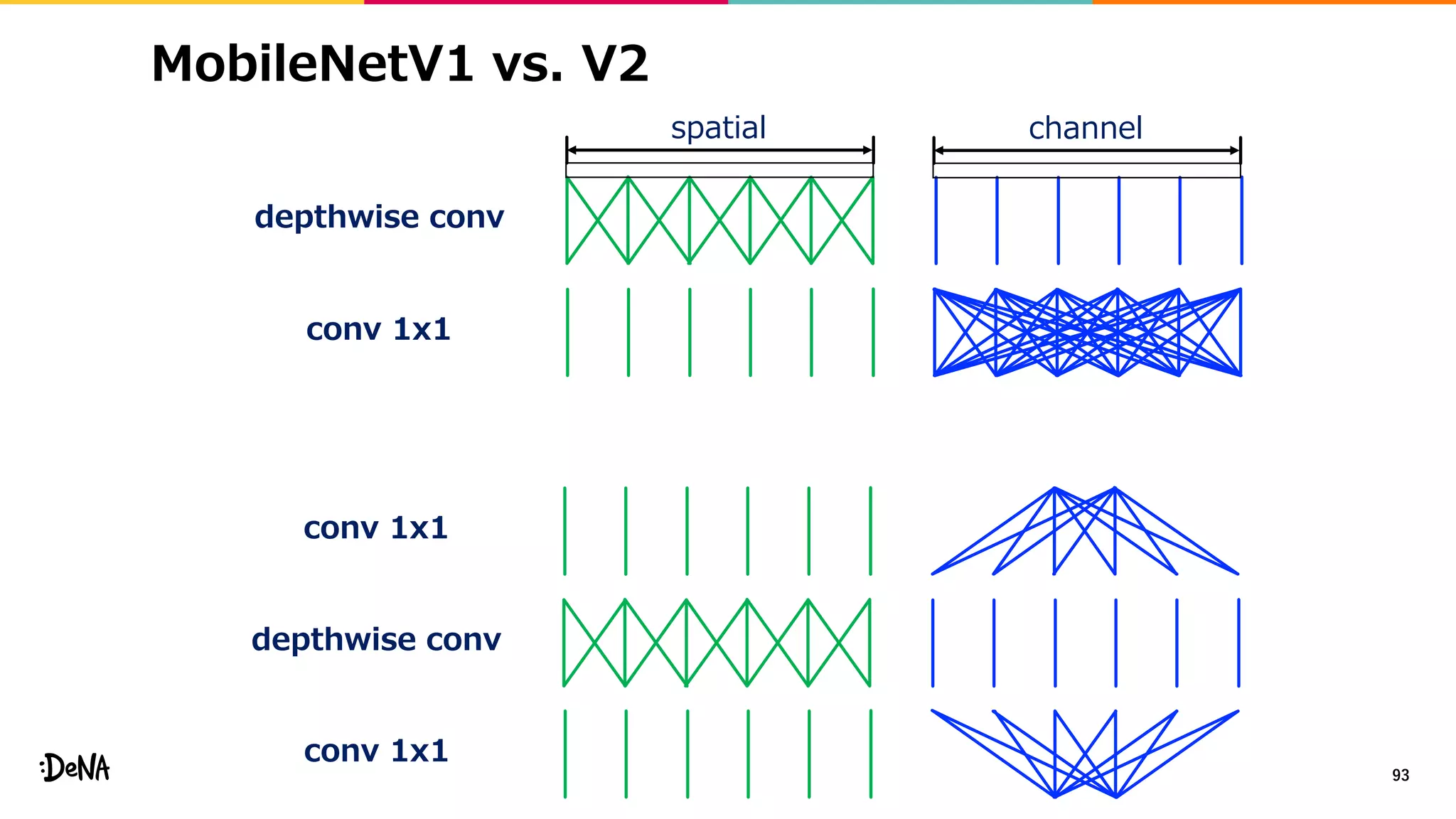


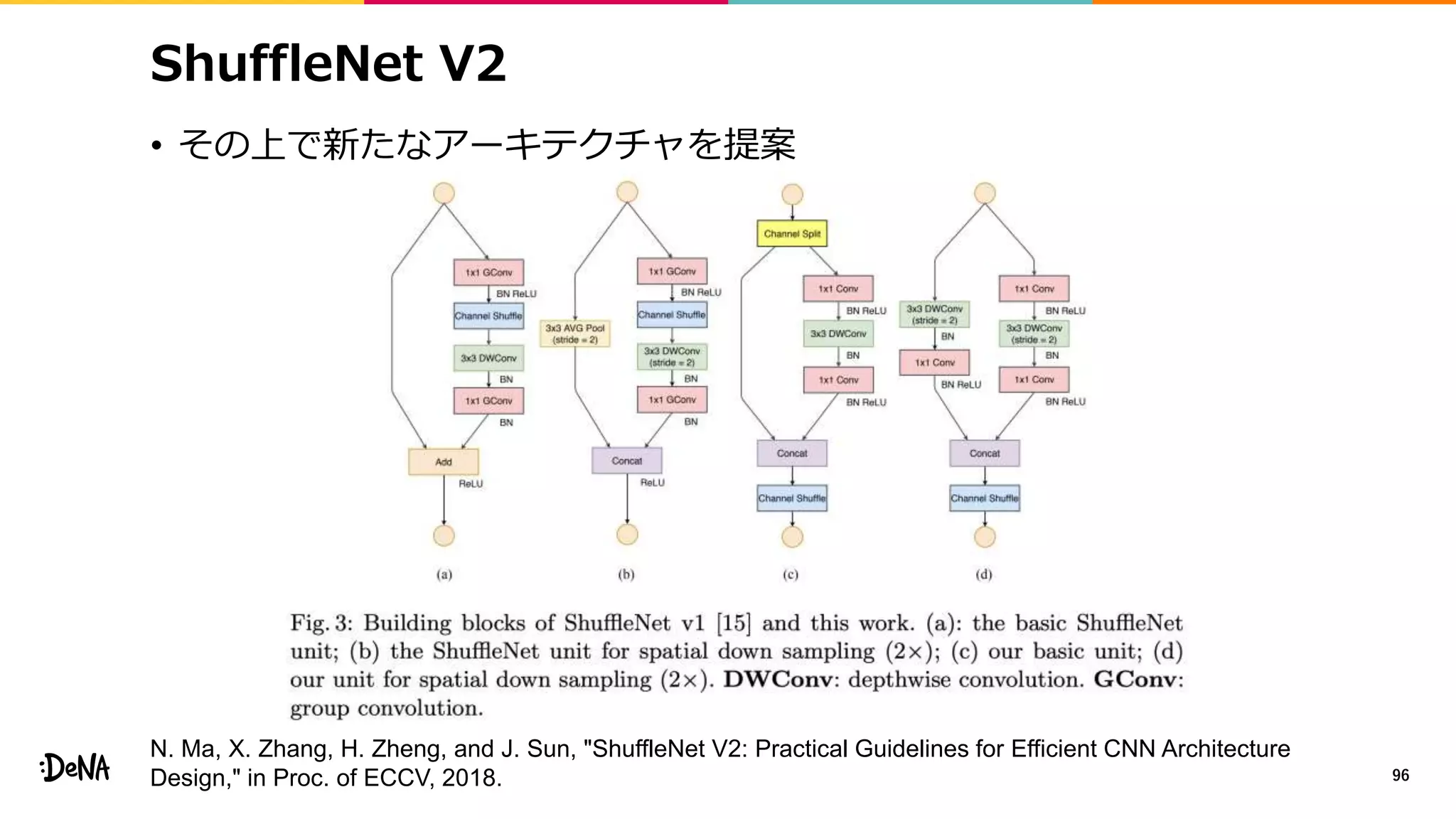
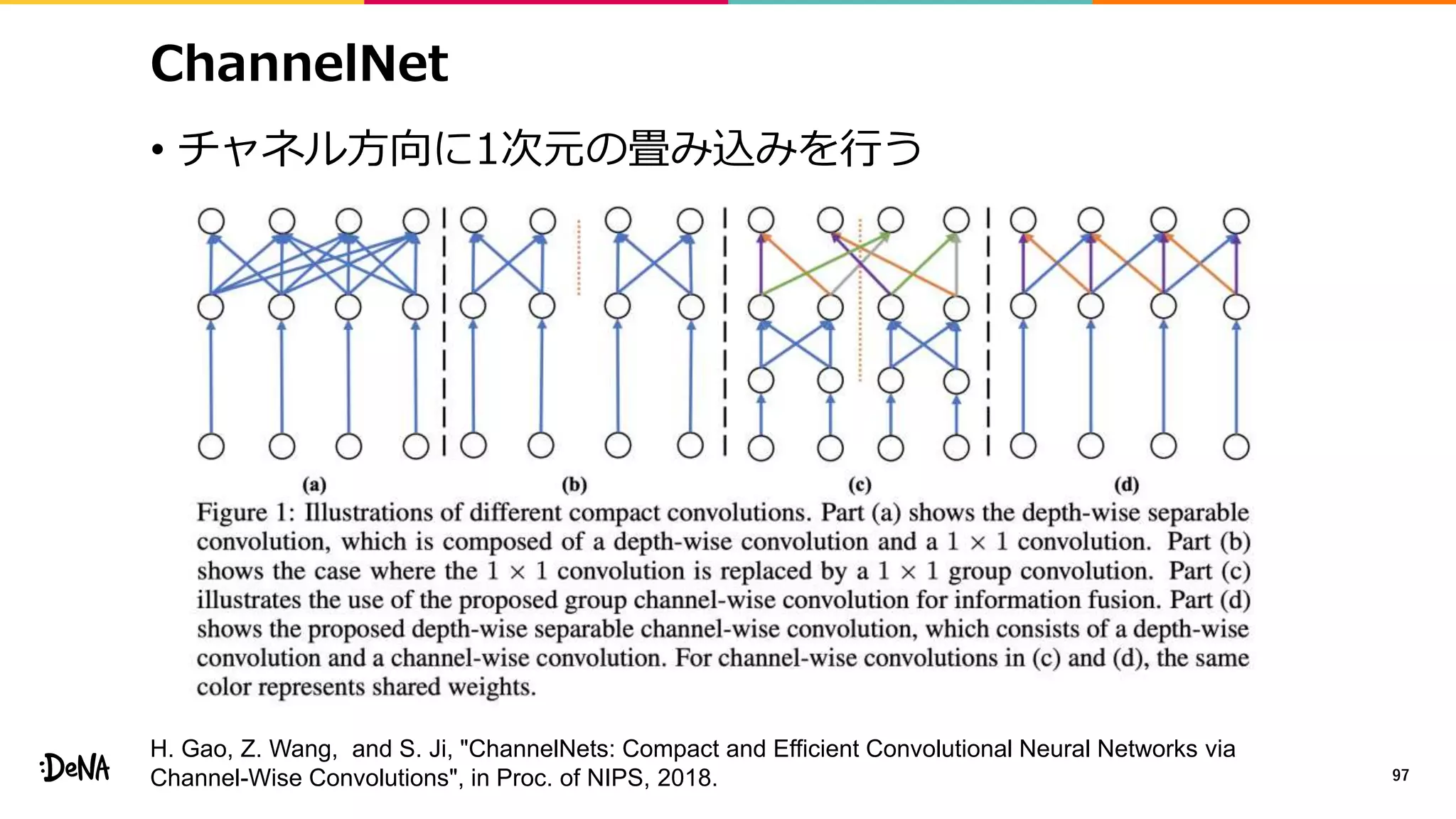
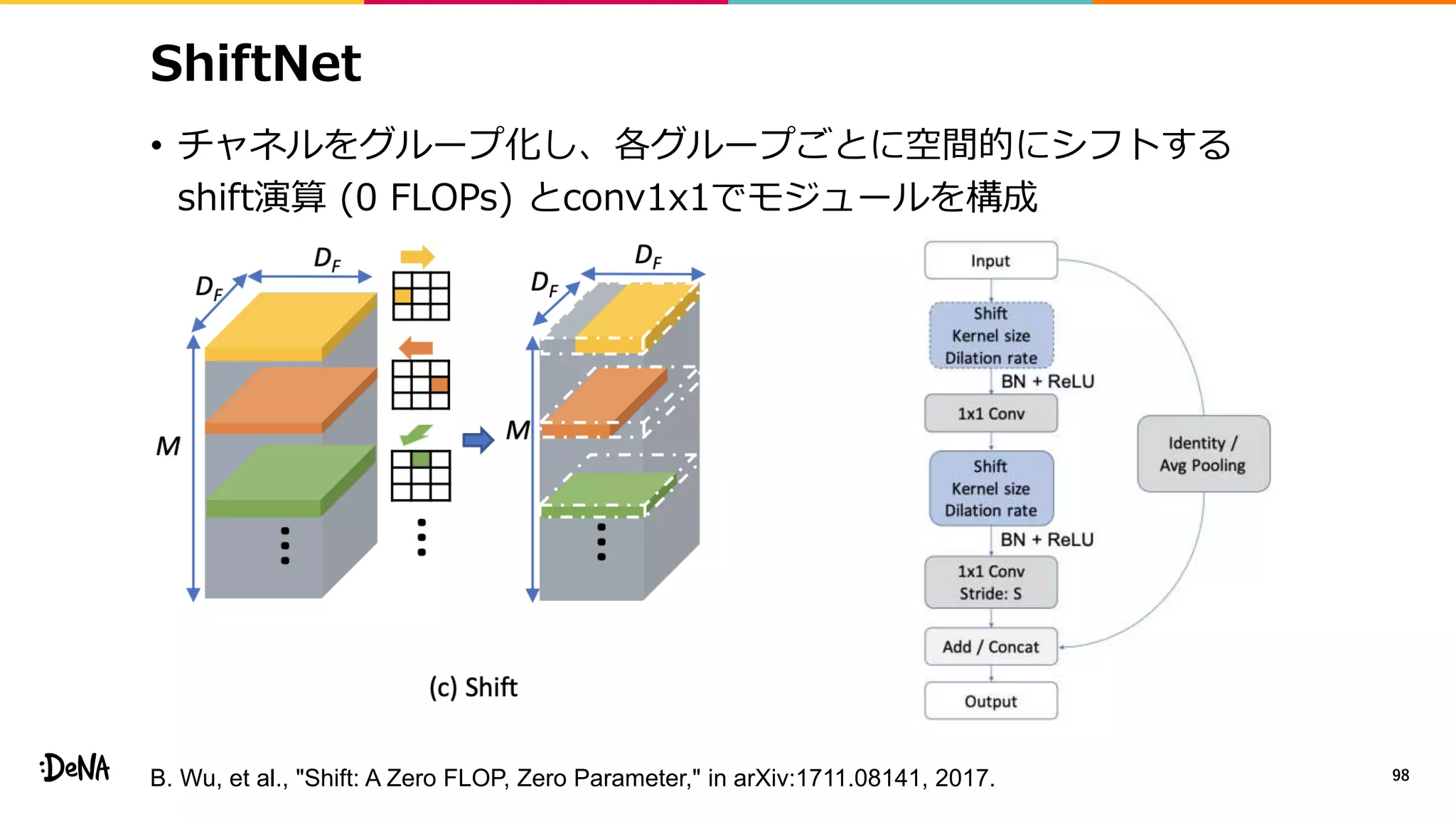

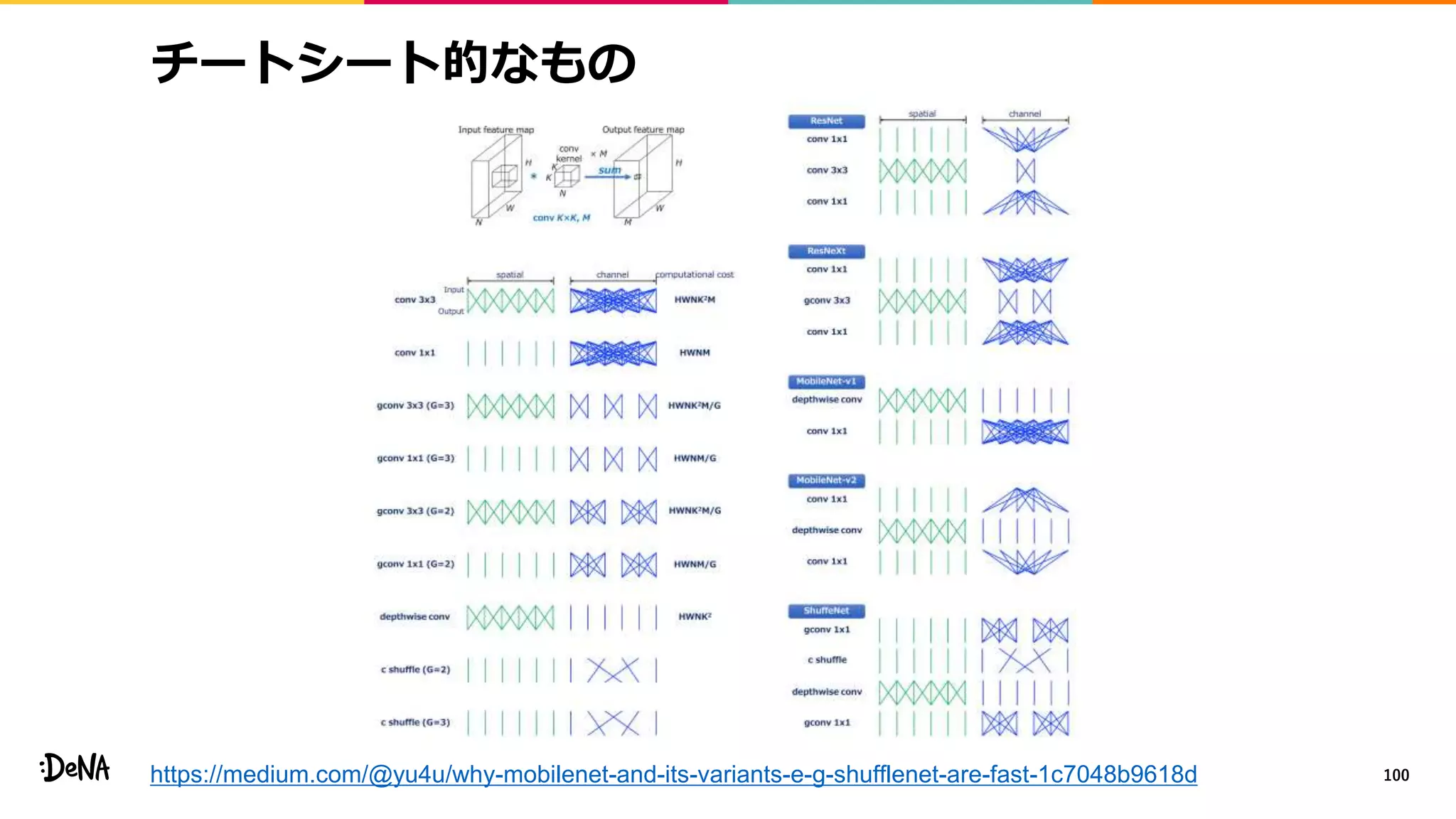


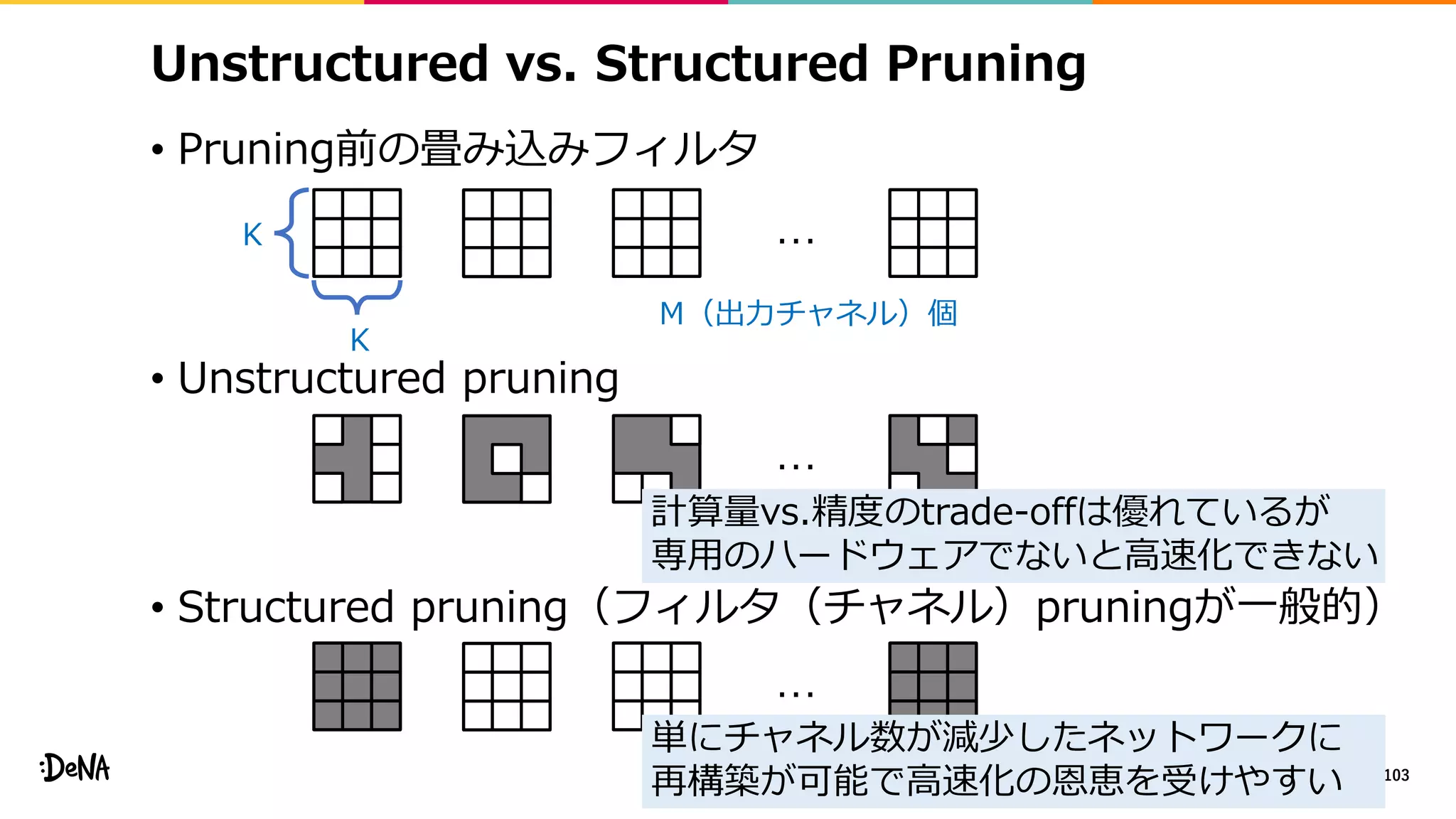


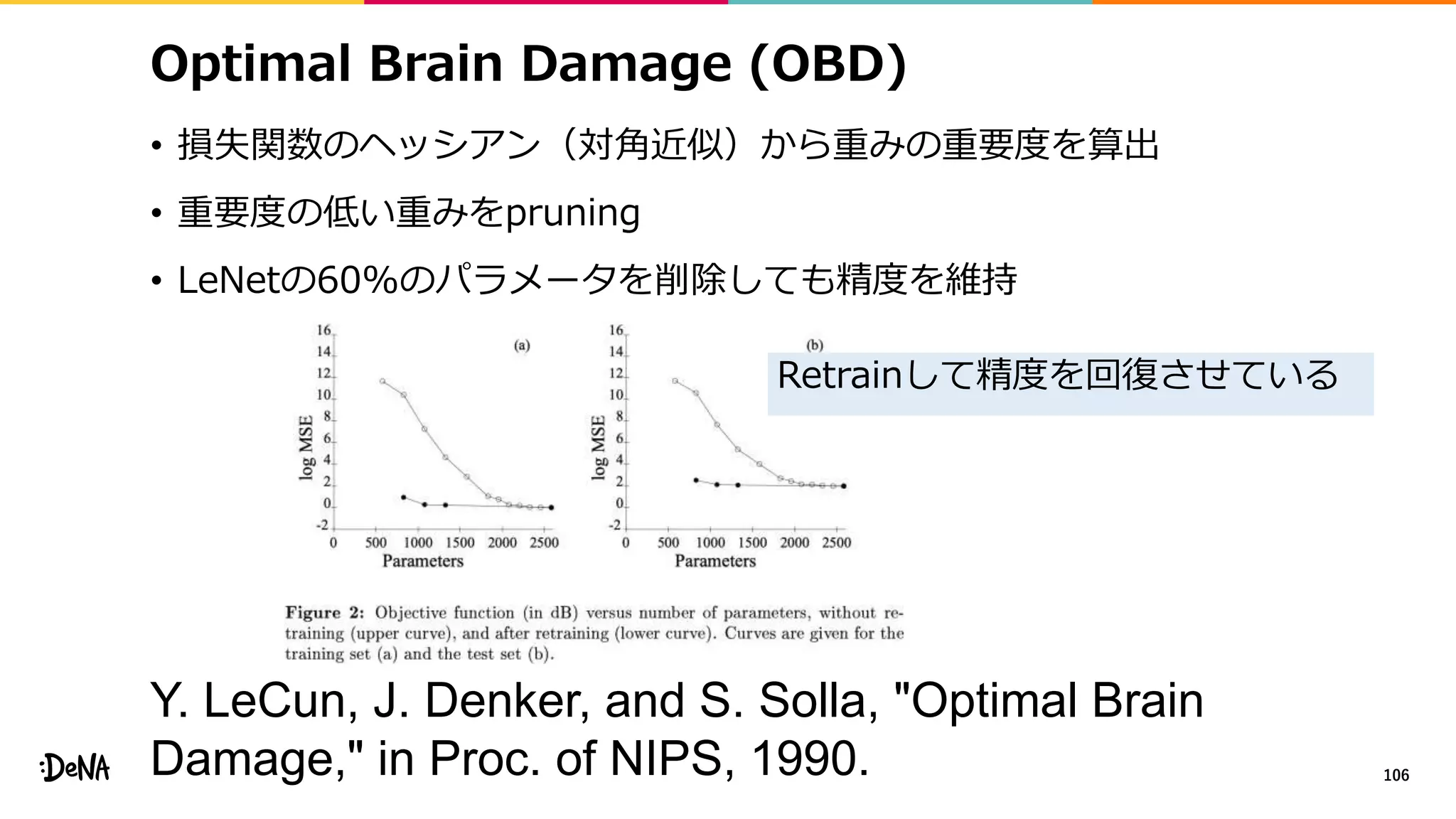
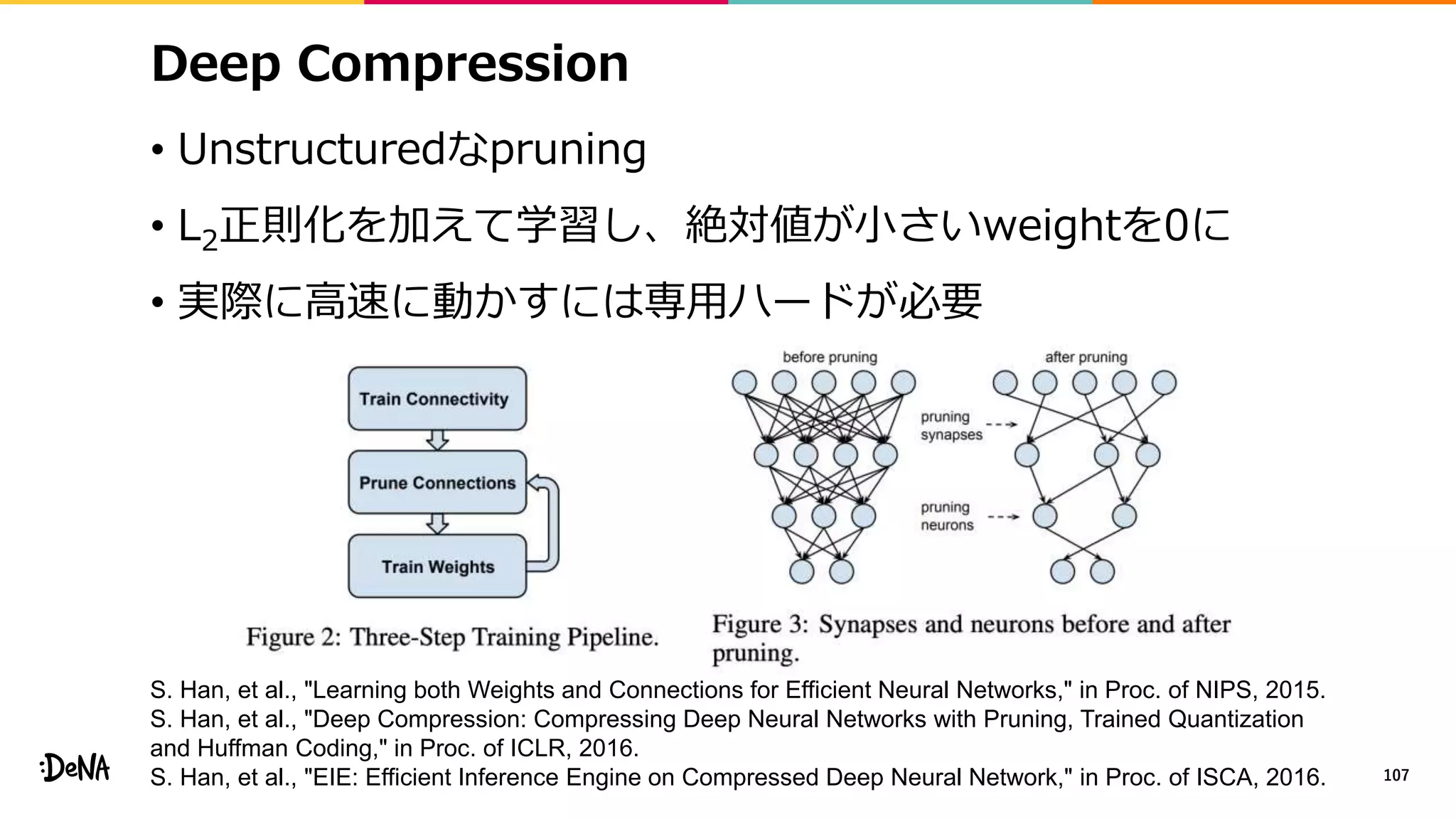

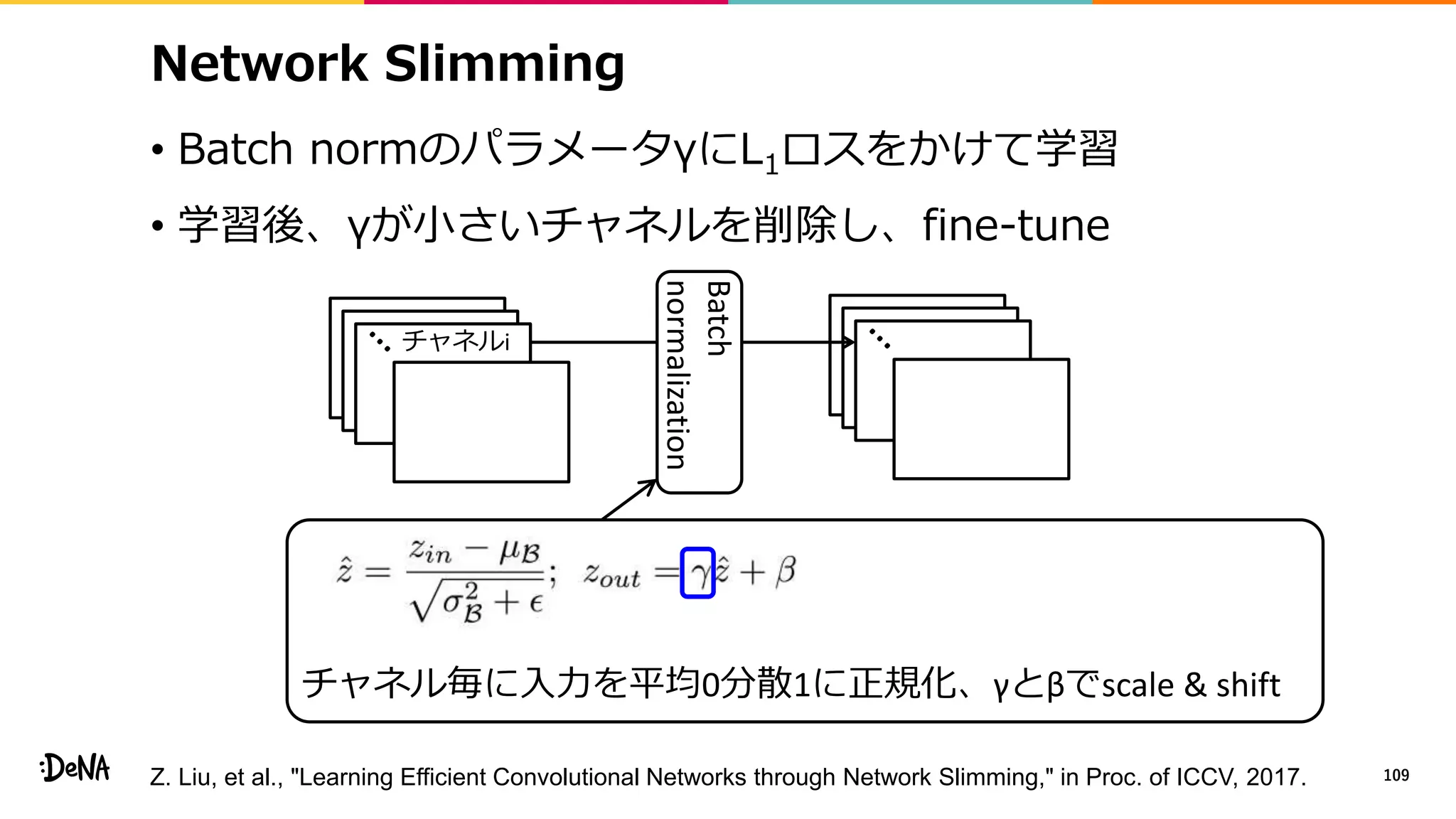
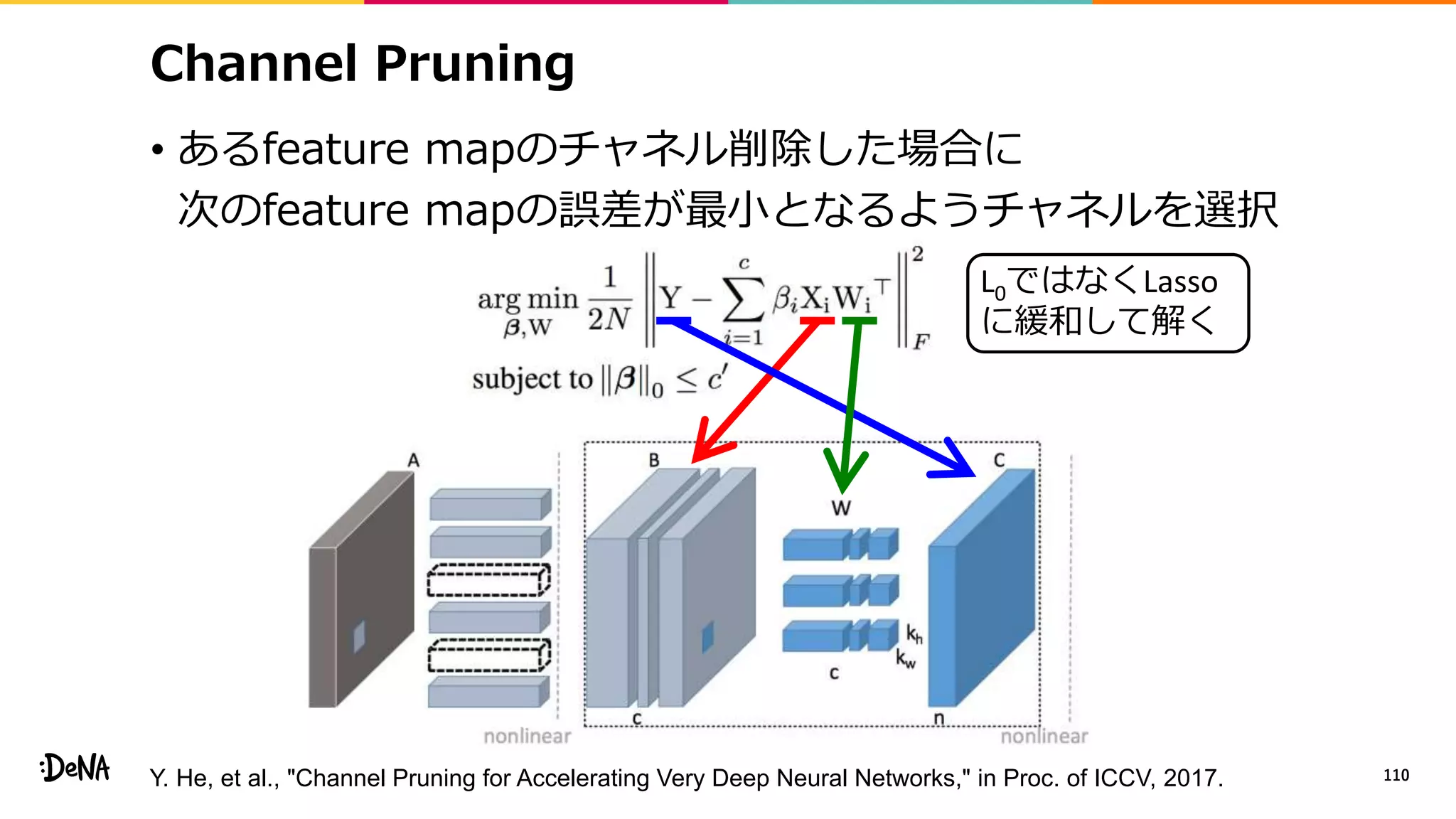
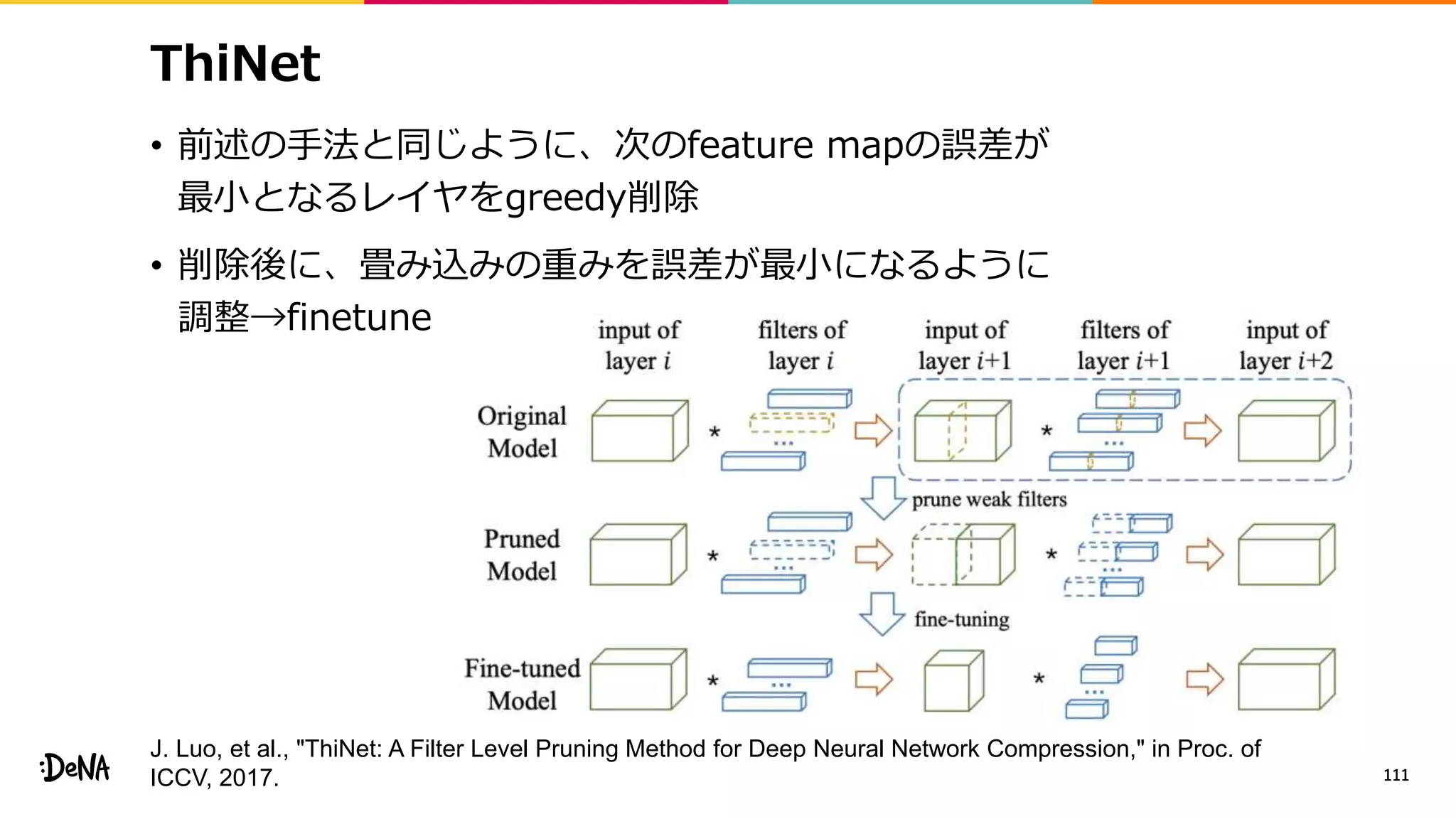
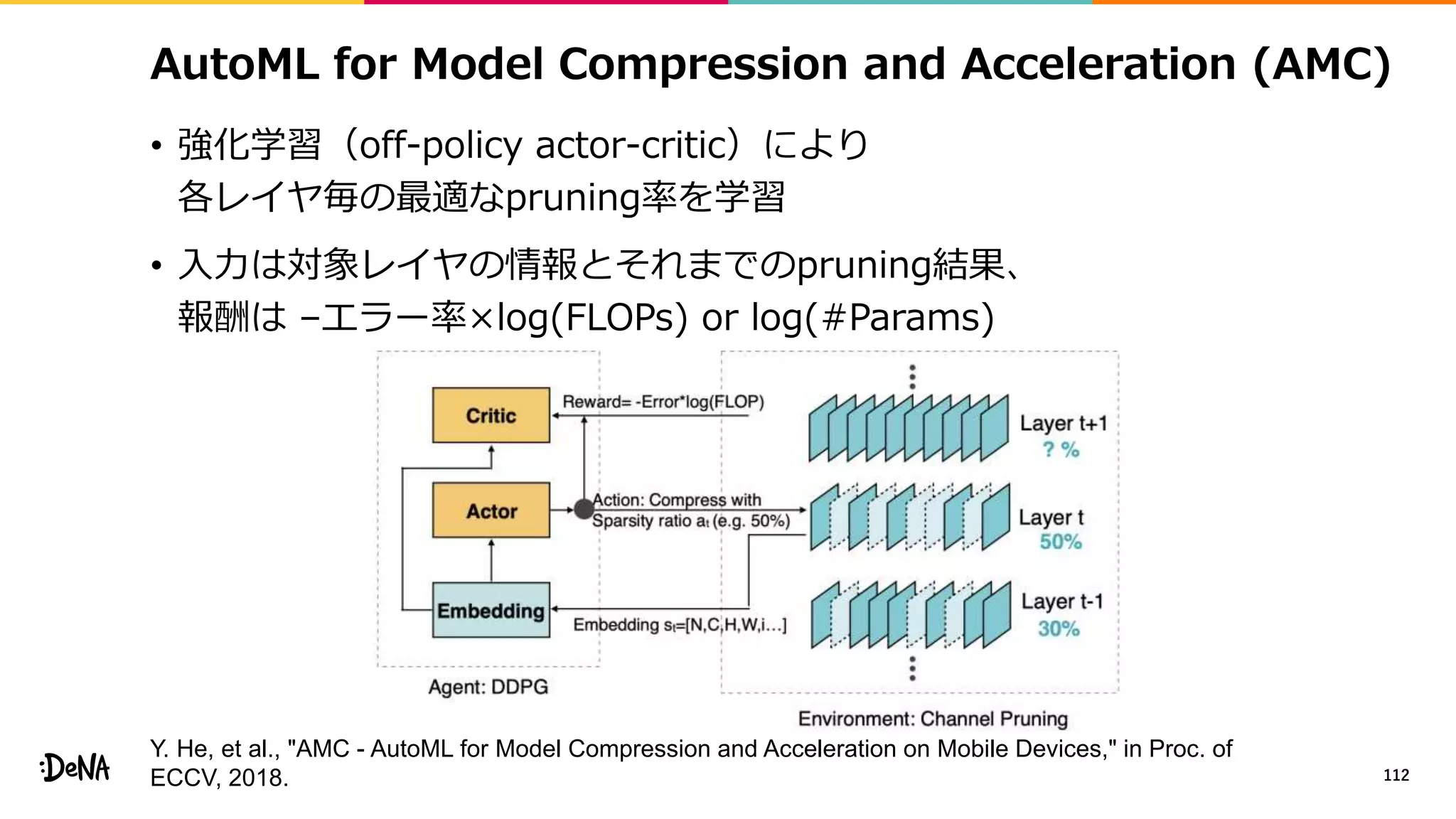




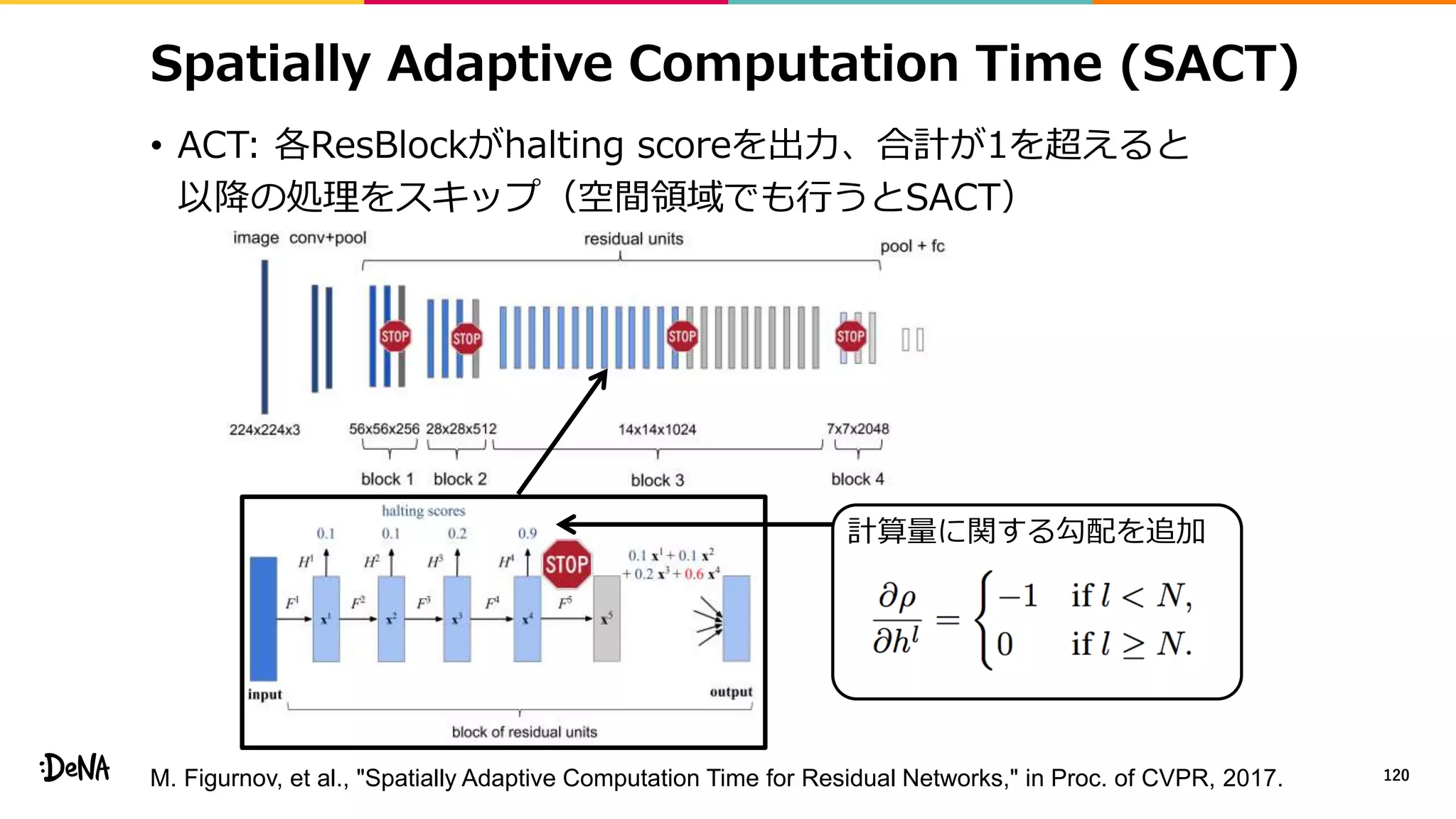







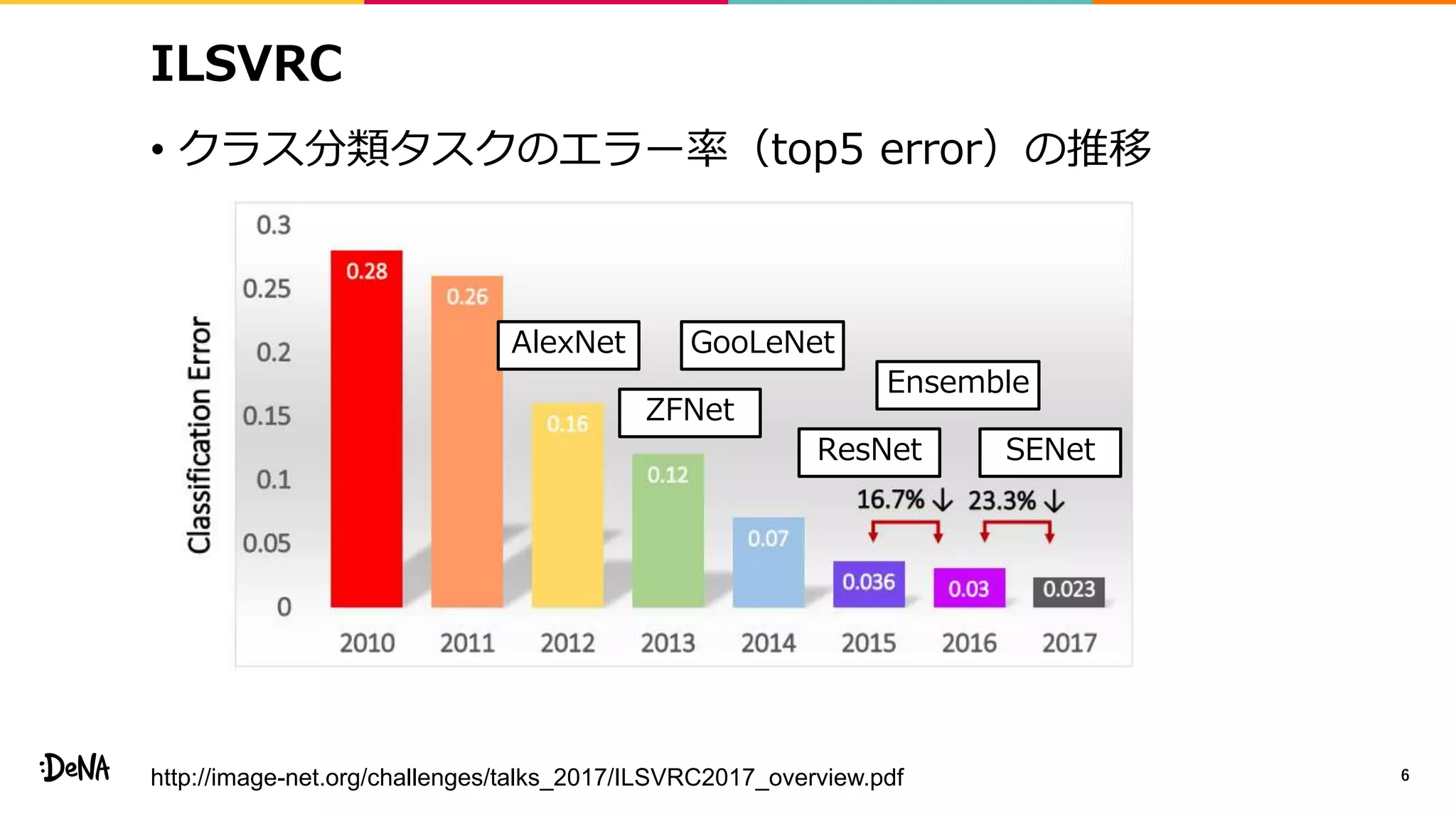
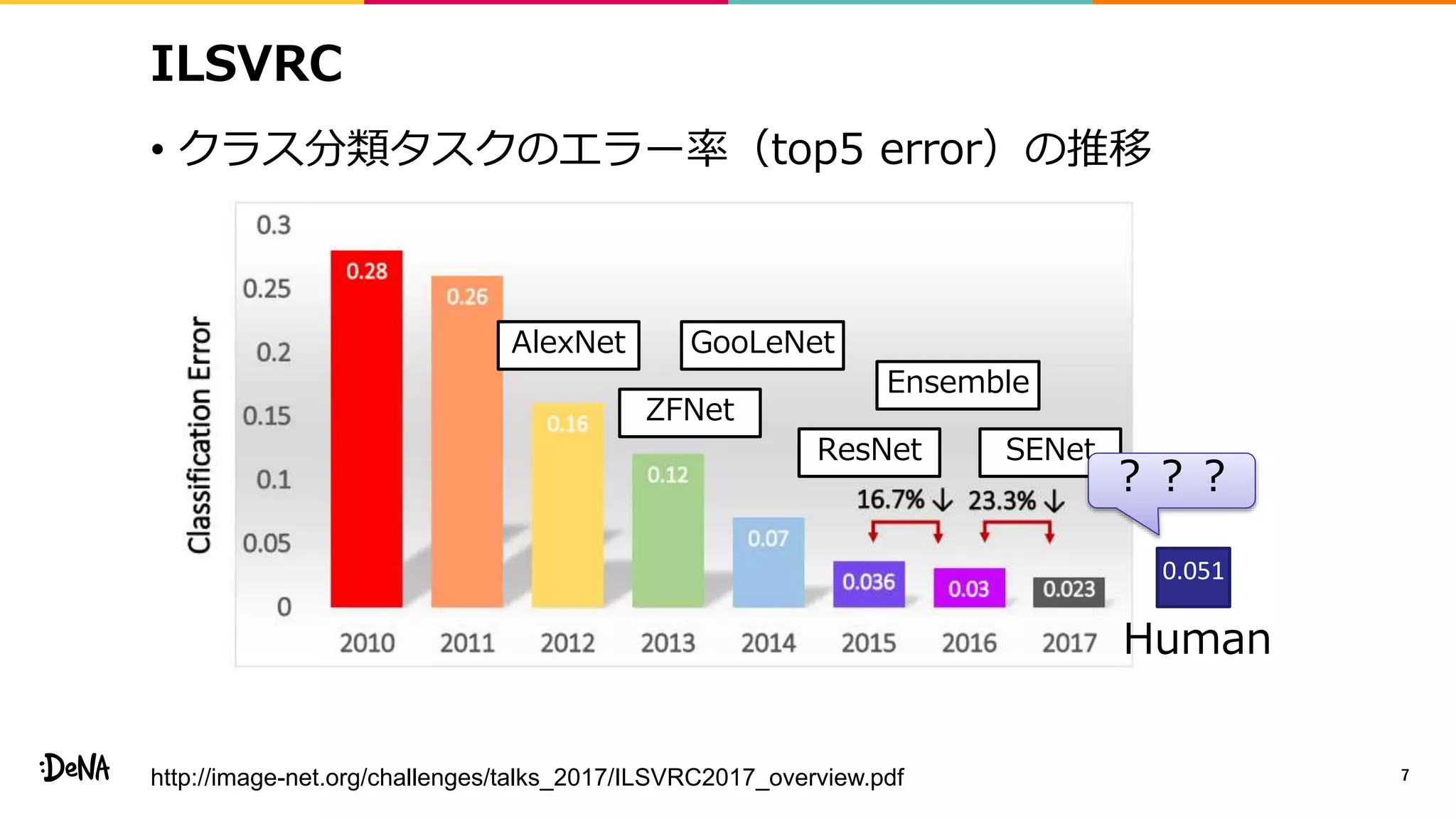
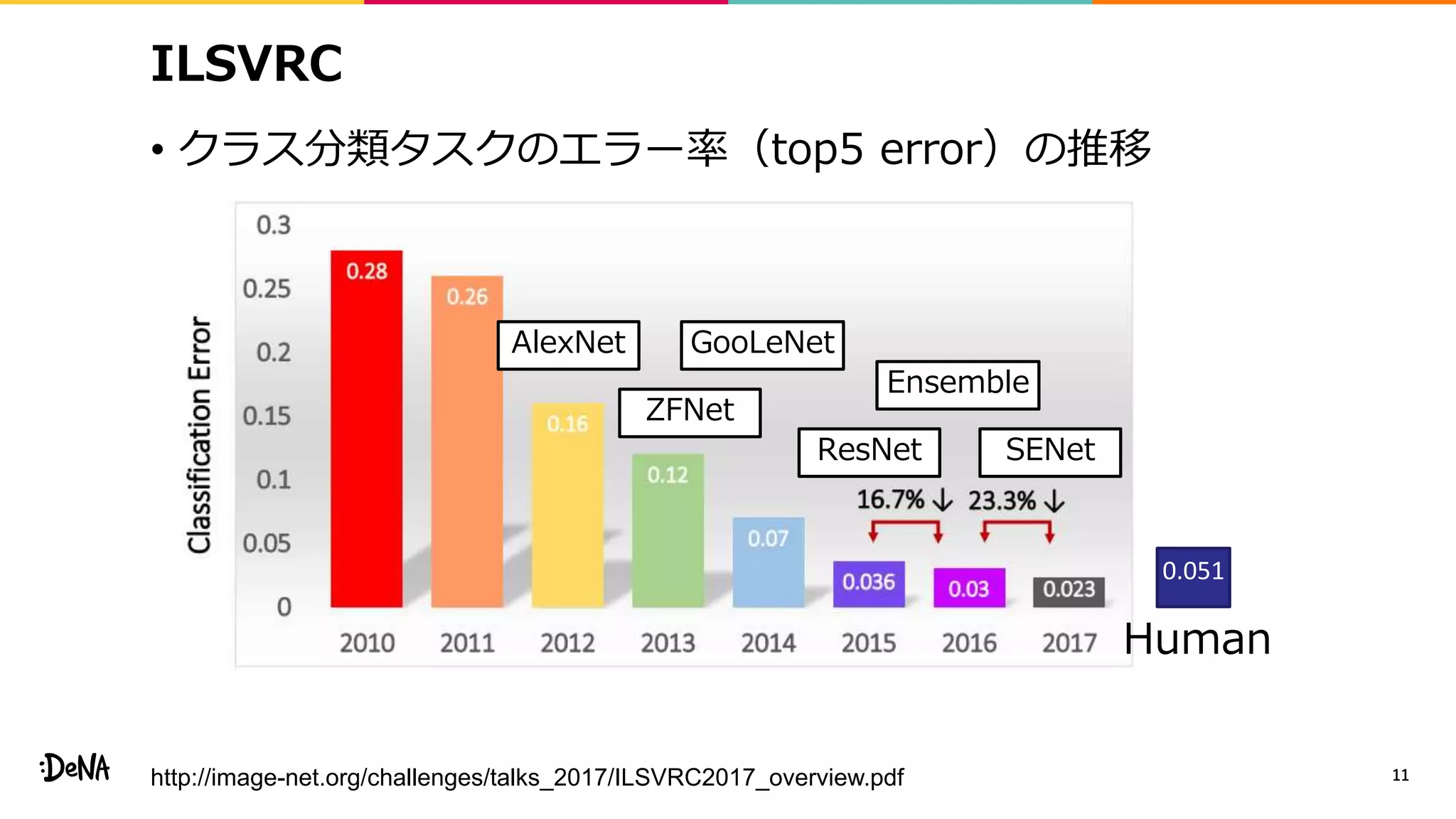
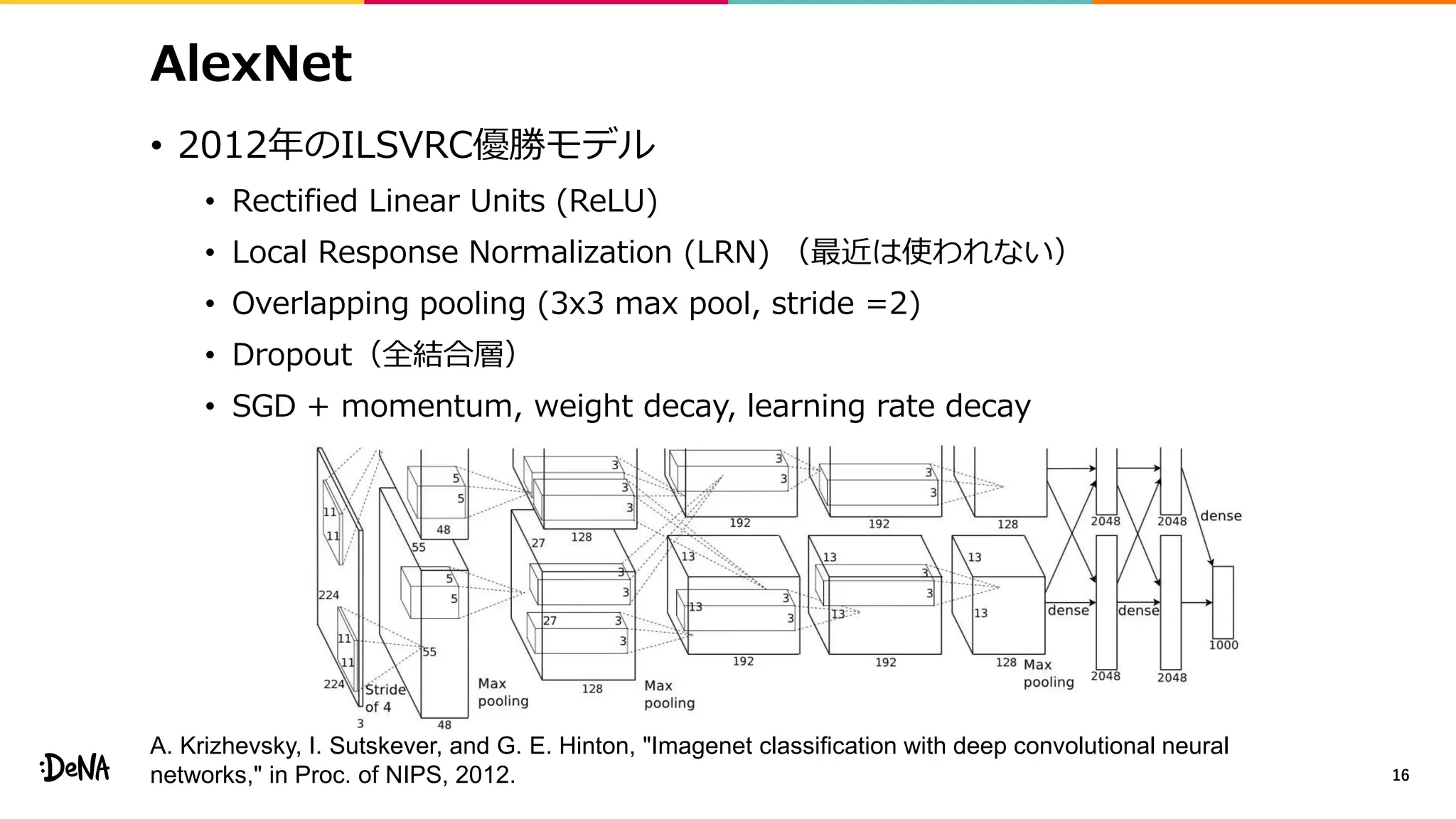
2012年の画像認識コンペティションILSVRCにおけるAlexNetの登場以降,画像認識においては畳み込みニューラルネットワーク (CNN) を用いることがデファクトスタンダードとなった.CNNは画像分類だけではなく,セグメンテーションや物体検出など様々なタスクを解くためのベースネットワークとしても広く利用されてきている.本講演では,AlexNet以降の代表的なCNNの変遷を振り返るとともに,近年提案されている様々なCNNの改良手法についてサーベイを行い,それらを幾つかのアプローチに分類し,解説する.更に,実用上重要な高速化手法について、畳み込みの分解や枝刈り等の分類を行い,それぞれ解説を行う. Recent Advances in Convolutional Neural Networks and Accelerating DNNs 第21回ステアラボ人工知能セミナー講演資料 https://stair.connpass.com/event/126556/





![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)








![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)


























