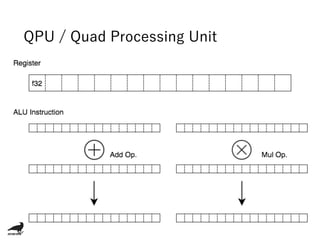
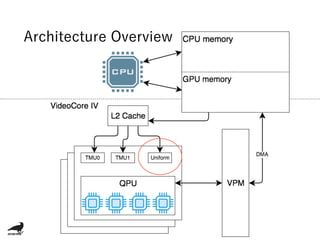
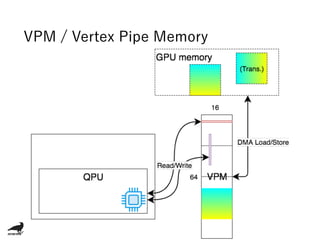
The document discusses using the Raspberry Pi GPU for deep neural network prediction on end devices. It provides an overview of the Raspberry Pi GPU architecture and benchmarks convolutional neural network models like GoogLeNet, ResNet50, and YOLO on the Raspberry Pi 3 and Zero. Optimization techniques discussed include specialized convolution implementations, instruction golfing to reduce operations, removing wasteful computations, and improving data locality.










































![Instruction Golf
rotate(broadcast, r1, -13)
fadd(rb[14], rb[14], r3).fmul(r3, r4, r5)
rotate(broadcast, r1, -14)
fadd(ra[14], ra[14], r3).fmul(r3, r4, r5)
iadd(null, element_number, -15, set_flags=True).rotate(broadcast, r1, -15)
isub(r2, r2, 1, cond='zs')
jzc(L.loop)
Decrement r2
Jump if non-0](https://image.slidesharecdn.com/usingraspberrypigpufordnn-170902113701/85/Using-Raspberry-Pi-GPU-for-DNN-47-320.jpg)
![Instruction Golf
rotate(broadcast, r1, -13)
fadd(rb[14], rb[14], r3).fmul(r3, r4, r5)
rotate(broadcast, r1, -14)
fadd(ra[14], ra[14], r3).fmul(r3, r4, r5)
iadd(null, element_number, -15, set_flags=True).rotate(broadcast, r1, -15)
isub(r2, r2, 1, cond='zs')
jzc(L.loop)
Add Op. Only
Mul Op. Only
Mul Op. Only](https://image.slidesharecdn.com/usingraspberrypigpufordnn-170902113701/85/Using-Raspberry-Pi-GPU-for-DNN-48-320.jpg)
![Instruction Golf
rotate(broadcast, r1, -13)
fadd(rb[14], rb[14], r3).fmul(r3, r4, r5)
rotate(broadcast, r1, -14)
fadd(ra[14], ra[14], r3).fmul(r3, r4, r5)
iadd(null, element_number, -15, set_flags=True).rotate(broadcast, r1, -15)
isub(r2, r2, 1, cond='zs')
jzc(L.loop)](https://image.slidesharecdn.com/usingraspberrypigpufordnn-170902113701/85/Using-Raspberry-Pi-GPU-for-DNN-49-320.jpg)
![Instruction Golf
rotate(broadcast, r1, -13)
fadd(rb[14], rb[14], r3).fmul(r3, r4, r5)
iadd(null, element_number, -14, set_flags=True).rotate(broadcast, r1, -14)
fadd(ra[14], ra[14], r3, set_flags=False).fmul(r3, r4, r5)
iadd(r2, r2, -1, cond='zs').rotate(broadcast, r1, -15)
jzc(L.loop)
rotate(broadcast, r1, -13)
fadd(rb[14], rb[14], r3).fmul(r3, r4, r5)
rotate(broadcast, r1, -14)
fadd(ra[14], ra[14], r3).fmul(r3, r4, r5)
iadd(null, element_number, -15, set_flags=True).rotate(broadcast, r1, -15)
isub(r2, r2, 1, cond='zs')
jzc(L.loop)](https://image.slidesharecdn.com/usingraspberrypigpufordnn-170902113701/85/Using-Raspberry-Pi-GPU-for-DNN-50-320.jpg)
![Instruction Golf
rotate(broadcast, r1, -13)
fadd(rb[14], rb[14], r3).fmul(r3, r4, r5)
iadd(null, element_number, -14, set_flags=True).rotate(broadcast, r1, -14)
fadd(ra[14], ra[14], r3, set_flags=False).fmul(r3, r4, r5)
iadd(r2, r2, -1, cond='zs').rotate(broadcast, r1, -15)
jzc(L.loop)
rotate(broadcast, r1, -13)
fadd(rb[14], rb[14], r3).fmul(r3, r4, r5)
rotate(broadcast, r1, -14)
fadd(ra[14], ra[14], r3).fmul(r3, r4, r5)
iadd(null, element_number, -15, set_flags=True).rotate(broadcast, r1, -15)
isub(r2, r2, 1, cond='zs')
jzc(L.loop)
Can t use 2 different Imm.Can t use 2 different Imm.](https://image.slidesharecdn.com/usingraspberrypigpufordnn-170902113701/85/Using-Raspberry-Pi-GPU-for-DNN-51-320.jpg)
![Instruction Golf
iadd(null, element_number, -13, set_flags=True).rotate(broadcast, r1, -13)
fadd(rb[14], rb[14], r3, set_flags=False).fmul(r3, r4, r5)
isub(r2, r2, -14, cond='zs', set_flags=False).rotate(broadcast, r1, -14)
fadd(ra[14], ra[14], r3, set_flags=False).fmul(r3, r4, r5)
iadd(r2, r2, -15, cond='zs').rotate(broadcast, r1, -15)
jzc(L.loop)
rotate(broadcast, r1, -13)
fadd(rb[14], rb[14], r3).fmul(r3, r4, r5)
rotate(broadcast, r1, -14)
fadd(ra[14], ra[14], r3).fmul(r3, r4, r5)
iadd(null, element_number, -15, set_flags=True).rotate(broadcast, r1, -15)
isub(r2, r2, 1, cond='zs')
jzc(L.loop)](https://image.slidesharecdn.com/usingraspberrypigpufordnn-170902113701/85/Using-Raspberry-Pi-GPU-for-DNN-52-320.jpg)
![Instruction Golf
iadd(null, element_number, -13, set_flags=True).rotate(broadcast, r1, -13)
fadd(rb[14], rb[14], r3, set_flags=False).fmul(r3, r4, r5)
isub(r2, r2, -14, cond='zs', set_flags=False).rotate(broadcast, r1, -14)
fadd(ra[14], ra[14], r3, set_flags=False).fmul(r3, r4, r5)
iadd(r2, r2, -15, cond='zs').rotate(broadcast, r1, -15)
jzc(L.loop)
rotate(broadcast, r1, -13)
fadd(rb[14], rb[14], r3).fmul(r3, r4, r5)
rotate(broadcast, r1, -14)
fadd(ra[14], ra[14], r3).fmul(r3, r4, r5)
iadd(null, element_number, -15, set_flags=True).rotate(broadcast, r1, -15)
isub(r2, r2, 1, cond='zs')
jzc(L.loop)
-1
-(-14)
-15](https://image.slidesharecdn.com/usingraspberrypigpufordnn-170902113701/85/Using-Raspberry-Pi-GPU-for-DNN-53-320.jpg)



































![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[DL輪読会]YOLO9000: Better, Faster, Stronger](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20170804-170803075138-thumbnail.jpg?width=640&height=640&fit=bounds)




















































