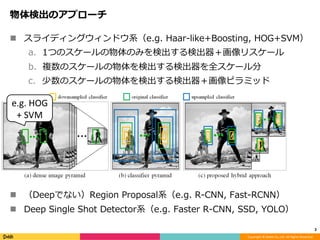
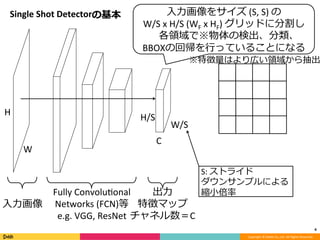
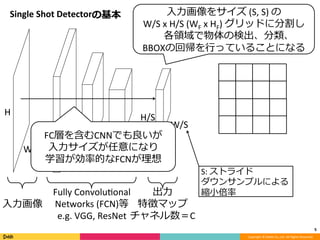
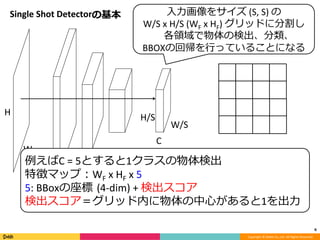
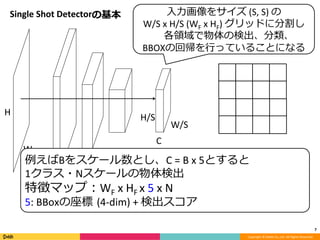
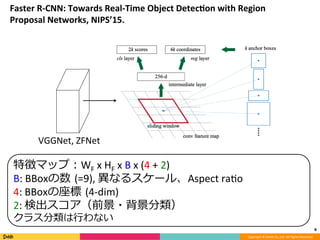
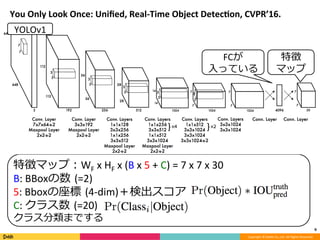
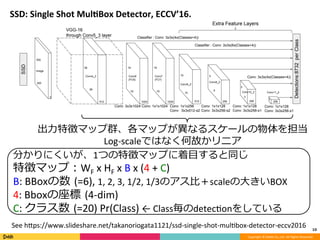
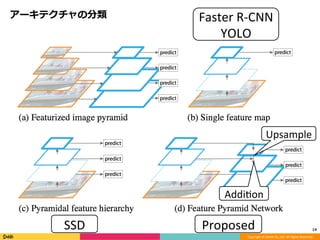
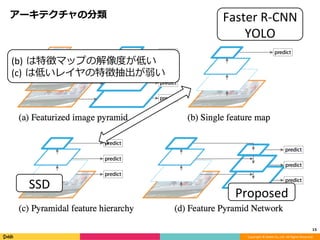
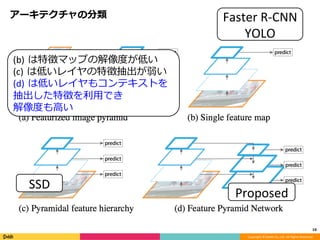
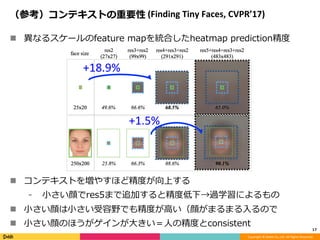
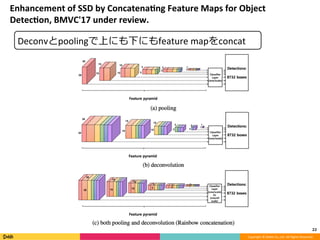
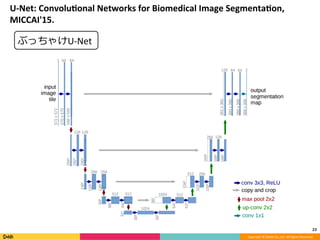
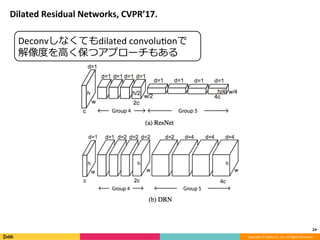
Feature Pyramid Networks for Object Detection, CVPR'17の内容と見せかけて、Faster R-CNN, YOLO, SSD系の最近のSingle Shot系の物体検出のアーキテクチャのまとめです。












![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/200515dlseminar-200515082345-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]YOLO9000: Better, Faster, Stronger](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20170804-170803075138-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)





![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Ridge-i] Deep Learning Lab - ディープラーニング 導入の課題と実例](https://cdn.slidesharecdn.com/ss_thumbnails/dll-20171024v2-171025013843-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL Hacks]OCNet: Object Context Networkfor Scene Parsing](https://cdn.slidesharecdn.com/ss_thumbnails/taniai20181123-181122101559-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)

![[cvpaper.challenge] 超解像メタサーベイ #meta-study-group勉強会](https://cdn.slidesharecdn.com/ss_thumbnails/metastudysr-190314071853-thumbnail.jpg?width=640&height=640&fit=bounds)

























