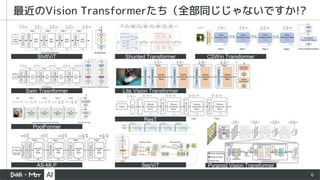
2
▪ ViT [1]の流行
▪ 画像もTransformer!でも大量データ(JFT-300M)必要
▪ DeiT [2]
▪ ViTの学習方法の確立、ImageNetだけでもCNN相当に
▪ MLP-Mixer [3]
▪ AttentionではなくMLPでもいいよ!
▪ ViTの改良やattentionの代替(MLP, pool, shift, LSTM) 乱立
背景
[1] A. Dosovitskiy, et al., "An Image is Worth 16x16 Words: Transformers for Image Recognition at
Scale," in Proc. of ICLR, 2021.
[2] H. Touvron, et al., "Training Data-efficient Image Transformers & Distillation Through Attention," in
Proc. of ICLR'21.
[3] I. Tolstikhin, et al., "MLP-Mixer: An all-MLP Architecture for Vision," in Proc. of NeurIPS'21.
3.
3
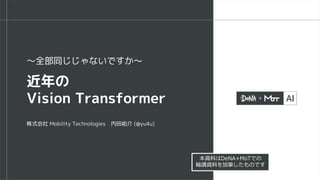
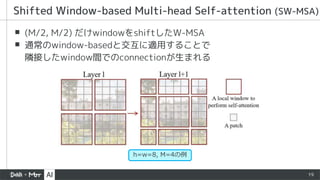
▪ Stride=2のdepthwise convでpooling
▪Deformable DETRベースの物体検出ではResNet50に負けている
初期の改良例:Pooling-based Vision Transformer (PiT)
B. Heo, et al., "Rethinking Spatial Dimensions of Vision Transformers," in Proc. of ICCV'21.
4.
4
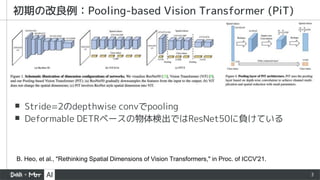
▪ Stage1, 2ではMBConv(MobileNetV2~やEffNetのメイン構成要素)
を利用、Stage3, 4ではattention(+rel pos embedding)を利用
▪ MBConvはstrided convで、attentionはpoolでdownsample
初期の改良例: CoAtNet
Z. Dai, et al., "CoAtNet: Marrying Convolution and Attention for All Data Sizes," in Proc. of NeurIPS'21.
identity residual
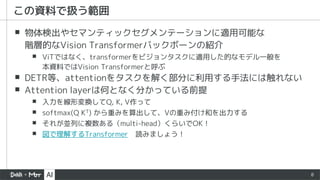
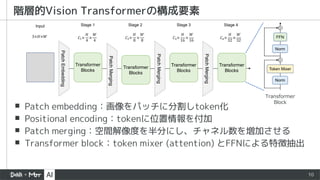
9
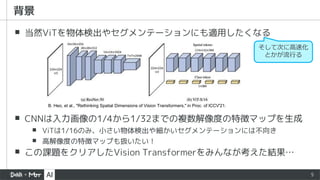
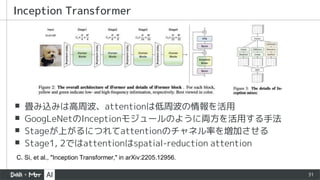
▪ 紹介するVision Transformerはほぼこの形で表現可能
▪Transformer blockのtoken mixerが主な違い
▪ MLP-Mixer, PoolFormer, ShiftViT等のattentionを使わないモデルも
token mixerが違うだけのViTと言える
▪ この構造を [1] ではMetaFormerと呼び、この構造が性能に寄与していると主張
階層的Vision Transformerの一般系(CNN的な階層構造)
Transformer
Block
[1] W. Yu, et al., "MetaFormer is Actually What You Need for Vision," in Proc. of CVPR’22.
12
▪ Transformer (attention)自体は集合のencoder (decoder)
▪ Positional encodingにより各tokenに位置情報を付加する必要がある
▪ 色々なアプローチがある
▪ Relative or absolute × 固定(sinusoidal) or learnable [1]
▪ Conditional positional encodings [2](面白いので本資料のappendixで紹介)
▪ FFNのconvで暗にembedする [3]
▪ Absolute positional encodingは入力のtokenに付加する
▪ オリジナルのViTはこれ
▪ Relative positional encodingはattentionの内積部分に付加
Positional Encoding
[1] K. Wu, et al., "Rethinking and Improving Relative Position Encoding for Vision Transformer," in Proc. of ICCV'21.
[2] X. Chu, et al., "Conditional Positional Encodings for Vision Transformers," in arXiv:2102.10882.
[3] Enze Xie, et a., "SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers," in Proc. of
NeurIPS'21.
17
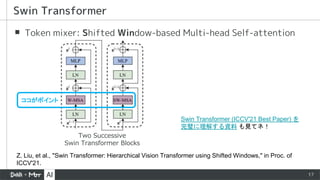
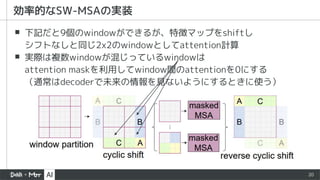
▪ Token mixer:Shifted Window-based Multi-head Self-attention
Swin Transformer
Two Successive
Swin Transformer Blocks
ココがポイント
Z. Liu, et al., "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows," in Proc. of
ICCV'21.
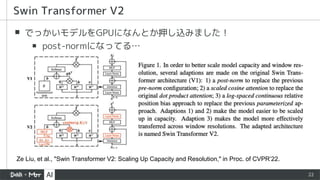
Swin Transformer (ICCV'21 Best Paper) を
完璧に理解する資料 も見てネ!
23
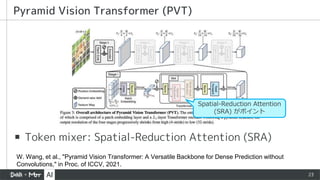
▪ Token mixer:Spatial-Reduction Attention (SRA)
Pyramid Vision Transformer (PVT)
W. Wang, et al., "Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without
Convolutions," in Proc. of ICCV, 2021.
Spatial-Reduction Attention
(SRA) がポイント
25
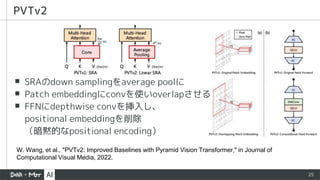
▪ SRAのdown samplingをaveragepoolに
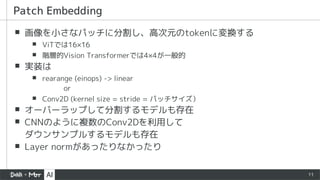
▪ Patch embeddingにconvを使いoverlapさせる
▪ FFNにdepthwise convを挿入し、
positional embeddingを削除
(暗黙的なpositional encoding)
PVTv2
W. Wang, et al., "PVTv2: Improved Baselines with Pyramid Vision Transformer," in Journal of
Computational Visual Media, 2022.
26.
26
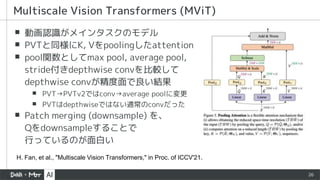
▪ 動画認識がメインタスクのモデル
▪ PVTと同様にK,Vをpoolingしたattention
▪ pool関数としてmax pool, average pool,
stride付きdepthwise convを比較して
depthwise convが精度面で良い結果
▪ PVT→PVTv2ではconv→average poolに変更
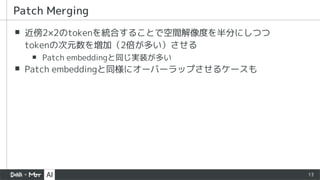
▪ PVTはdepthwiseではない通常のconvだった
▪ Patch merging (downsample) を、
Qをdownsampleすることで
行っているのが面白い
Multiscale Vision Transformers (MViT)
H. Fan, et al., "Multiscale Vision Transformers," in Proc. of ICCV'21.
27.
27
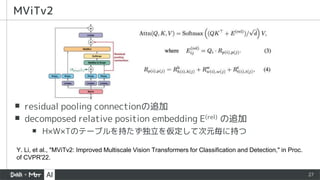
▪ residual poolingconnectionの追加
▪ decomposed relative position embedding E(rel) の追加
▪ H×W×Tのテーブルを持たず独立を仮定して次元毎に持つ
MViTv2
Y. Li, et al., "MViTv2: Improved Multiscale Vision Transformers for Classification and Detection," in Proc.
of CVPR'22.
28.
28
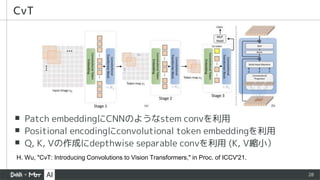
▪ Patch embeddingにCNNのようなstemconvを利用
▪ Positional encodingにconvolutional token embeddingを利用
▪ Q, K, Vの作成にdepthwise separable convを利用 (K, V縮小)
CvT
H. Wu, "CvT: Introducing Convolutions to Vision Transformers," in Proc. of ICCV'21.
29.
29
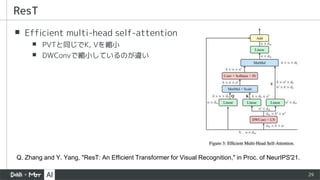
▪ Efficient multi-headself-attention
▪ PVTと同じでK, Vを縮小
▪ DWConvで縮小しているのが違い
ResT
Q. Zhang and Y. Yang, "ResT: An Efficient Transformer for Visual Recognition," in Proc. of NeurIPS'21.
30.
30
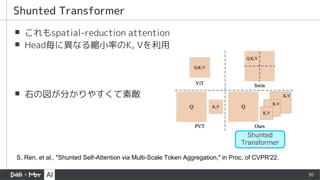
▪ これもspatial-reduction attention
▪Head毎に異なる縮小率のK, Vを利用
▪ 右の図が分かりやすくて素敵
Shunted Transformer
S. Ren, et al., "Shunted Self-Attention via Multi-Scale Token Aggregation," in Proc. of CVPR'22.
Shunted
Transformer
32
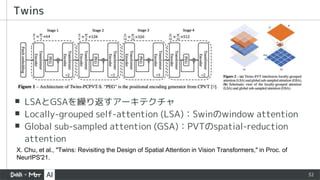
▪ LSAとGSAを繰り返すアーキテクチャ
▪ Locally-groupedself-attention (LSA):Swinのwindow attention
▪ Global sub-sampled attention (GSA):PVTのspatial-reduction
attention
Twins
X. Chu, et al., "Twins: Revisiting the Design of Spatial Attention in Vision Transformers," in Proc. of
NeurIPS'21.
33.
33
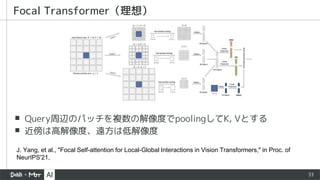
▪ Query周辺のパッチを複数の解像度でpoolingしてK, Vとする
▪近傍は高解像度、遠方は低解像度
Focal Transformer(理想)
J. Yang, et al., "Focal Self-attention for Local-Global Interactions in Vision Transformers," in Proc. of
NeurIPS'21.
34.
34
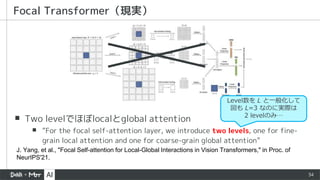
▪ Two levelでほぼlocalとglobalattention
▪ “For the focal self-attention layer, we introduce two levels, one for fine-
grain local attention and one for coarse-grain global attention”
Focal Transformer(現実)
J. Yang, et al., "Focal Self-attention for Local-Global Interactions in Vision Transformers," in Proc. of
NeurIPS'21.
Level数を L と一般化して
図も L=3 なのに実際は
2 levelのみ…
35.
35
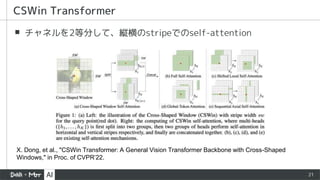
▪ SDA (windowattention) と、特徴マップを空間的にshuffleしてから
window attentionするLDAの組み合わせ
▪ 空間shuffleは [2] でも利用されている
▪ 古くはCNNにShuffleNetというものがあってじゃな…
CrossFormer [1]
[1] W. Wang, et al., "CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention," in
Proc. of ICLR'22.
[2] Z. Huang, et al., "Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer," in
arXiv:2106.03650.
37
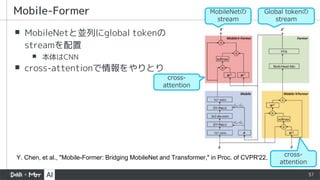
▪ MobileNetと並列にglobal tokenの
streamを配置
▪本体はCNN
▪ cross-attentionで情報をやりとり
Mobile-Former
Y. Chen, et al., "Mobile-Former: Bridging MobileNet and Transformer," in Proc. of CVPR'22.
MobileNetの
stream
Global tokenの
stream
cross-
attention
cross-
attention
38.
38
▪ Attentionの代わりにshift operation
▪空間方向(上下左右)に1 pixelずらす
▪ なのでZERO FLOPs!!!
▪ S2-MLP [2] や AS-MLP [3] といった
先行手法が存在するが
ShiftViTは本当にshiftだけ
ShiftViT [1]
[1] G. Wang, et al., "When Shift Operation Meets Vision Transformer: An Extremely Simple Alternative to
Attention Mechanism," in Proc. of AAAI'22.
[2] T. Yu, et al., "S2-MLP: Spatial-Shift MLP Architecture for Vision," in Proc. of WACV'22.
[3] D. Lian, et al., "AS-MLP: An Axial Shifted MLP Architecture for Vision," in Proc. of ICLR'22.
39.
39
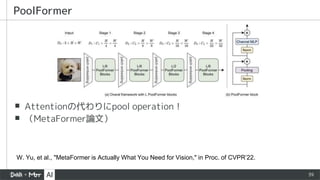
▪ Attentionの代わりにpool operation!
▪(MetaFormer論文)
PoolFormer
W. Yu, et al., "MetaFormer is Actually What You Need for Vision," in Proc. of CVPR’22.
43
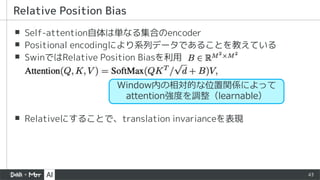
▪ Self-attention自体は単なる集合のencoder
▪ Positionalencodingにより系列データであることを教えている
▪ SwinではRelative Position Biasを利用
▪ Relativeにすることで、translation invarianceを表現
Relative Position Bias
Window内の相対的な位置関係によって
attention強度を調整(learnable)
44.
44
▪ 相対位置関係は縦横[−M +1, M −1]のrangeで(2M-1)2パターン
▪ このbiasとindexの関係を保持しておき、使うときに引く
実装
45.
45
▪ On PositionEmbeddings in BERT, ICLR’21
▪ https://openreview.net/forum?id=onxoVA9FxMw
▪ https://twitter.com/akivajp/status/1442241252204814336
▪ Rethinking and Improving Relative Position Encoding for Vision
Transformer, ICCV’21. thanks to @sasaki_ts
▪ CSWin Transformer: A General Vision Transformer Backbone with
Cross-Shaped Windows, arXiv’21. thanks to @Ocha_Cocoa
Positional Encodingの議論
46.
46
▪ 入力token依存、画像入力サイズに依存しない、translation-
invariance、絶対座標も何となく加味できるposition encoding(PE)
▪ 実装は単に特徴マップを2次元に再構築してzero padding付きのconvするだけ
▪ Zero pad付きconvによりCNNが絶対座標を特徴マップに保持するという報告 [2]
▪ これにinspireされ、PVTv2ではFFNにDWConvを挿入、PE削除
Conditional Positional Encoding (CPE) [1]
[1] X. Chu, et al., "Conditional Positional Encodings for Vision Transformers," in arXiv:2102.10882.
[2] M. Islam, et al., "How Much Position Information Do Convolutional Neural Networks Encode?," in
Proc. of ICLR'20.
![2
▪ ViT [1] の流行
▪ 画像もTransformer!でも大量データ(JFT-300M)必要
▪ DeiT [2]
▪ ViTの学習方法の確立、ImageNetだけでもCNN相当に
▪ MLP-Mixer [3]
▪ AttentionではなくMLPでもいいよ!
▪ ViTの改良やattentionの代替(MLP, pool, shift, LSTM) 乱立
背景
[1] A. Dosovitskiy, et al., "An Image is Worth 16x16 Words: Transformers for Image Recognition at
Scale," in Proc. of ICLR, 2021.
[2] H. Touvron, et al., "Training Data-efficient Image Transformers & Distillation Through Attention," in
Proc. of ICLR'21.
[3] I. Tolstikhin, et al., "MLP-Mixer: An all-MLP Architecture for Vision," in Proc. of NeurIPS'21.](https://image.slidesharecdn.com/hierarchicalvisiontransformer-220601082858-320dc415/85/Hierarchical-Vision-Transformer-2-320.jpg)
![9
▪ 紹介するVision Transformerはほぼこの形で表現可能
▪ Transformer blockのtoken mixerが主な違い
▪ MLP-Mixer, PoolFormer, ShiftViT等のattentionを使わないモデルも
token mixerが違うだけのViTと言える
▪ この構造を [1] ではMetaFormerと呼び、この構造が性能に寄与していると主張
階層的Vision Transformerの一般系(CNN的な階層構造)
Transformer
Block
[1] W. Yu, et al., "MetaFormer is Actually What You Need for Vision," in Proc. of CVPR’22.](https://image.slidesharecdn.com/hierarchicalvisiontransformer-220601082858-320dc415/85/Hierarchical-Vision-Transformer-9-320.jpg)
![12
▪ Transformer (attention) 自体は集合のencoder (decoder)
▪ Positional encodingにより各tokenに位置情報を付加する必要がある
▪ 色々なアプローチがある
▪ Relative or absolute × 固定(sinusoidal) or learnable [1]
▪ Conditional positional encodings [2](面白いので本資料のappendixで紹介)
▪ FFNのconvで暗にembedする [3]
▪ Absolute positional encodingは入力のtokenに付加する
▪ オリジナルのViTはこれ
▪ Relative positional encodingはattentionの内積部分に付加
Positional Encoding
[1] K. Wu, et al., "Rethinking and Improving Relative Position Encoding for Vision Transformer," in Proc. of ICCV'21.
[2] X. Chu, et al., "Conditional Positional Encodings for Vision Transformers," in arXiv:2102.10882.
[3] Enze Xie, et a., "SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers," in Proc. of
NeurIPS'21.](https://image.slidesharecdn.com/hierarchicalvisiontransformer-220601082858-320dc415/85/Hierarchical-Vision-Transformer-12-320.jpg)





![35
▪ SDA (window attention) と、特徴マップを空間的にshuffleしてから
window attentionするLDAの組み合わせ
▪ 空間shuffleは [2] でも利用されている
▪ 古くはCNNにShuffleNetというものがあってじゃな…
CrossFormer [1]
[1] W. Wang, et al., "CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention," in
Proc. of ICLR'22.
[2] Z. Huang, et al., "Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer," in
arXiv:2106.03650.](https://image.slidesharecdn.com/hierarchicalvisiontransformer-220601082858-320dc415/85/Hierarchical-Vision-Transformer-35-320.jpg)
![38
▪ Attentionの代わりにshift operation
▪ 空間方向(上下左右)に1 pixelずらす
▪ なのでZERO FLOPs!!!
▪ S2-MLP [2] や AS-MLP [3] といった
先行手法が存在するが
ShiftViTは本当にshiftだけ
ShiftViT [1]
[1] G. Wang, et al., "When Shift Operation Meets Vision Transformer: An Extremely Simple Alternative to
Attention Mechanism," in Proc. of AAAI'22.
[2] T. Yu, et al., "S2-MLP: Spatial-Shift MLP Architecture for Vision," in Proc. of WACV'22.
[3] D. Lian, et al., "AS-MLP: An Axial Shifted MLP Architecture for Vision," in Proc. of ICLR'22.](https://image.slidesharecdn.com/hierarchicalvisiontransformer-220601082858-320dc415/85/Hierarchical-Vision-Transformer-38-320.jpg)


![44
▪ 相対位置関係は縦横[−M + 1, M −1]のrangeで(2M-1)2パターン
▪ このbiasとindexの関係を保持しておき、使うときに引く
実装](https://image.slidesharecdn.com/hierarchicalvisiontransformer-220601082858-320dc415/85/Hierarchical-Vision-Transformer-44-320.jpg)

![46
▪ 入力token依存、画像入力サイズに依存しない、translation-
invariance、絶対座標も何となく加味できるposition encoding (PE)
▪ 実装は単に特徴マップを2次元に再構築してzero padding付きのconvするだけ
▪ Zero pad付きconvによりCNNが絶対座標を特徴マップに保持するという報告 [2]
▪ これにinspireされ、PVTv2ではFFNにDWConvを挿入、PE削除
Conditional Positional Encoding (CPE) [1]
[1] X. Chu, et al., "Conditional Positional Encodings for Vision Transformers," in arXiv:2102.10882.
[2] M. Islam, et al., "How Much Position Information Do Convolutional Neural Networks Encode?," in
Proc. of ICLR'20.](https://image.slidesharecdn.com/hierarchicalvisiontransformer-220601082858-320dc415/85/Hierarchical-Vision-Transformer-46-320.jpg)





![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)


































