Recommended
PPTX
近年のHierarchical Vision Transformer
PPTX
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing
PPTX
Curriculum Learning (関東CV勉強会)
PDF
ガウス過程回帰の導出 ( GPR : Gaussian Process Regression )
PPTX
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models
PDF
論文紹介 Pixel Recurrent Neural Networks
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
PDF
[DL輪読会]Progressive Growing of GANs for Improved Quality, Stability, and Varia...
PDF
PPTX
PDF
PDF
PDF
PPTX
PPTX
StyleGAN解説 CVPR2019読み会@DeNA
PDF
文献紹介:TSM: Temporal Shift Module for Efficient Video Understanding
PDF
PDF
最新リリース:Optuna V3の全て - 2022/12/10 Optuna Meetup #2
PDF
PPTX
[DL輪読会]Neural Ordinary Differential Equations
PDF
PPTX
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
PPTX
PPTX
【DL輪読会】An Image is Worth One Word: Personalizing Text-to-Image Generation usi...
PDF
モデルアーキテクチャ観点からのDeep Neural Network高速化
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
PDF
PPTX
MIRU2014 tutorial deeplearning
PDF
SSII2019OS: 深層学習にかかる時間を短くしてみませんか? ~分散学習の勧め~
More Related Content
PPTX
近年のHierarchical Vision Transformer
PPTX
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing
PPTX
Curriculum Learning (関東CV勉強会)
PDF
ガウス過程回帰の導出 ( GPR : Gaussian Process Regression )
PPTX
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models
PDF
論文紹介 Pixel Recurrent Neural Networks
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
What's hot
PDF
[DL輪読会]Progressive Growing of GANs for Improved Quality, Stability, and Varia...
PDF
PPTX
PDF
PDF
PDF
PPTX
PPTX
StyleGAN解説 CVPR2019読み会@DeNA
PDF
文献紹介:TSM: Temporal Shift Module for Efficient Video Understanding
PDF
PDF
最新リリース:Optuna V3の全て - 2022/12/10 Optuna Meetup #2
PDF
PPTX
[DL輪読会]Neural Ordinary Differential Equations
PDF
PPTX
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
PPTX
PPTX
【DL輪読会】An Image is Worth One Word: Personalizing Text-to-Image Generation usi...
PDF
モデルアーキテクチャ観点からのDeep Neural Network高速化
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
PDF
Similar to DEEP LEARNING、トレーニング・インファレンスのGPUによる高速化
PPTX
MIRU2014 tutorial deeplearning
PDF
SSII2019OS: 深層学習にかかる時間を短くしてみませんか? ~分散学習の勧め~
PPTX
機械学習 / Deep Learning 大全 (2) Deep Learning 基礎編
PPTX
Deep Learningのための専用プロセッサ「MN-Core」の開発と活用(2022/10/19東大大学院「 融合情報学特別講義Ⅲ」)
PDF
PDF
エヌビディアが加速するディープラーニング ~進化するニューラルネットワークとその開発方法について~
PDF
PDF
DAシンポジウム2019招待講演「深層学習モデルの高速なTraining/InferenceのためのHW/SW技術」 金子紘也hare
PPTX
「機械学習とは?」から始める Deep learning実践入門
PPT
PPTX
Image net classification with Deep Convolutional Neural Networks
PDF
PDF
PDF
PDF
2値ディープニューラルネットワークと組込み機器への応用: 開発中のツール紹介
PDF
PPTX
PDF
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化
PDF
ディープラーニング最近の発展とビジネス応用への課題
PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
More from RCCSRENKEI
PDF
第15回 配信講義 計算科学技術特論B(2022)
PDF
第14回 配信講義 計算科学技術特論B(2022)
PDF
第12回 配信講義 計算科学技術特論B(2022)
PDF
第13回 配信講義 計算科学技術特論B(2022)
PDF
第11回 配信講義 計算科学技術特論B(2022)
PDF
第10回 配信講義 計算科学技術特論B(2022)
PDF
PDF
PPT
PPT
PDF
PPTX
Realization of Innovative Light Energy Conversion Materials utilizing the Sup...
PDF
Current status of the project "Toward a unified view of the universe: from la...
PPTX
Fugaku, the Successes and the Lessons Learned
PDF
PDF
PDF
PDF
PDF
PDF
第15回 配信講義 計算科学技術特論A(2021)
DEEP LEARNING、トレーニング・インファレンスのGPUによる高速化 1. 2. 3. 4. 5. CHASING 1060 CHEMICALCOMPOUNDS
Identifying molecules with desirable chemical properties is centralto many
industries. In the chemicalspace of 1060 conceivable compounds, only
108 have been synthesized.
Screening even a small fraction of the remaining compounds with legacy
methods would take 100 node-seconds per compound.
Researchers at Dow are using GPU-powered deep learning to deliver
completely novelmolecular structures with specific properties.
The AI produced 3M promising chemicalleads in 1 day on an NVIDIA DGX.
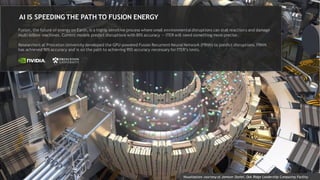
6. AI IS SPEEDING THE PATH TO FUSION ENERGY
Fusion, the future of energy on Earth, is a highly sensitive process where small environmentaldisruptions can stall reactions and damage
multi-billion machines. Current models predict disruptions with 85% accuracy — ITER will need something more precise.
Researchers at Princeton University developed the GPU-powered Fusion Recurrent NeuralNetwork (FRNN) to predict disruptions. FRNN
has achieved 90% accuracy and is on the path to achieving 95% accuracy necessary for ITER’s tests.
Visualization courtesy of Jamison Daniel, Oak Ridge Leadership Computing Facility
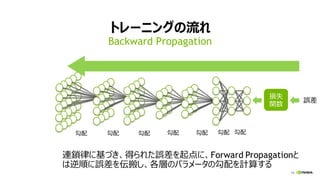
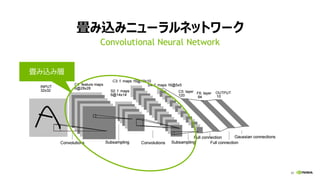
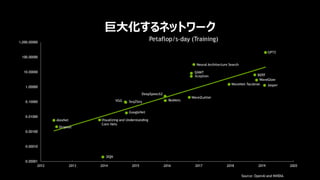
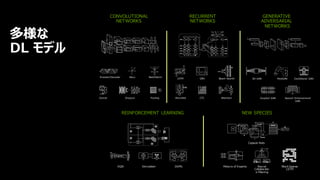
7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 33
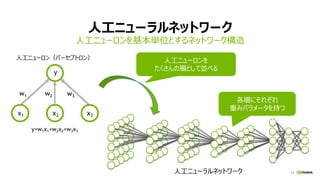
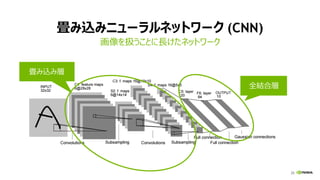
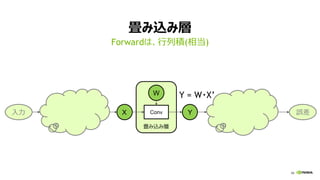
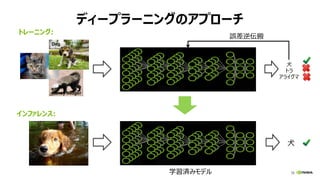
全結合層 (FULLY CONNECTED LAYER)
行列ベクトル積 (y = Wx)
Ny
計算量:
2 * 出力ノード数 (Ny)
* 入力ノード数 (Nx)
入力 x 出力 y重み W
Nx
重み W
入力 x
出力 y
Ny
Nx
Nx
[性能律速点]
メモリバンド幅
34. 34
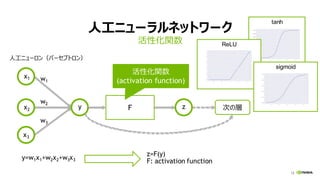
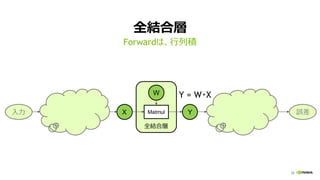
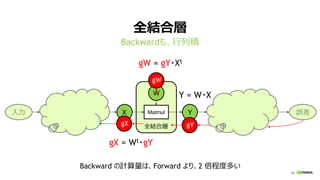
全結合層 (FULLY CONNECTED LAYER)
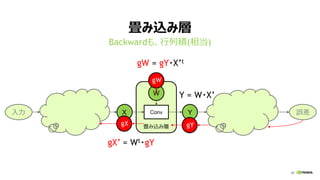
ミニバッチ学習で、行列積に (Y = W・X)
重み W
計算量:
2 * 出力ノード数 (Ny)
* 入力ノード数 (Nx)
* ミニバッチサイズ (Nb)
入力 X 出力 Y重み W
Nb * Nx Nb * Ny
入力 X
出力 Y
Ny
Nx
Nx
Nb
[性能律速点]
演算性能
35. 36. 37. 38. 39. 40. 40
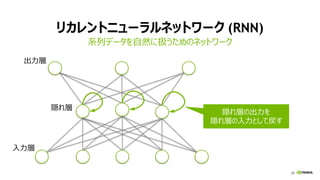
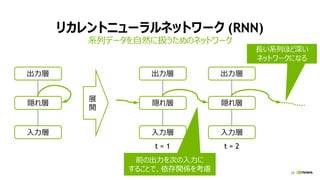
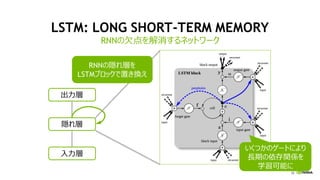
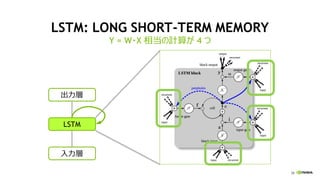
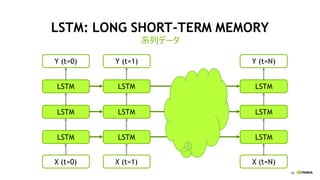
LSTM: LONG SHORT-TERM MEMORY
系列データ
40
LSTM
X (t=0)
LSTM
LSTM
Y (t=0)
LSTM
X (t=1)
LSTM
LSTM
Y (t=1)
LSTM
X (t=N)
LSTM
LSTM
Y (t=N)
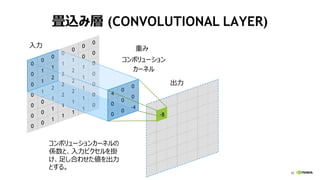
41. 42. 43. 43
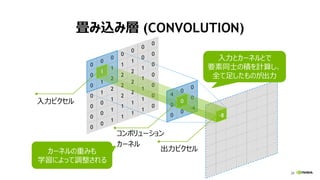
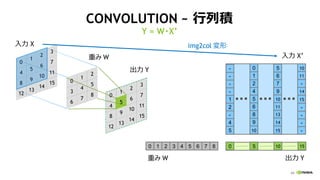
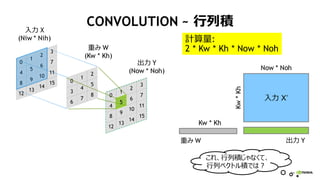
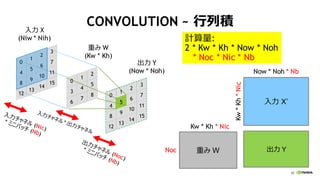
CONVOLUTION ~ 行列積
Y = W・X’
0
4
8
12
1
5
9
13
2
6
10
14
3
7
11
15
入力 X
出力 Y
0
3
6
1
4
7
2
5
8 0
4
8
12
1
9
13
2
6
10
14
3
7
11
15
5
重み W
0 1 2 3 4 5 6 7 8 0 5 10 15
5
4
-
2
1
-
-
-
-
9
8
6
5
4
2
1
0
9
7
6
5
-
-
-
-
10
10
11
13
14
15
10
11
14
15
-
重み W 出力 Y
入力 X’
img2col 変形
44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 56
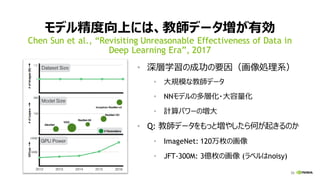
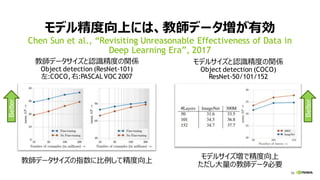
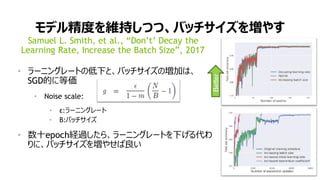
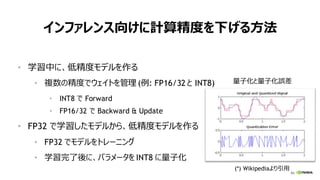
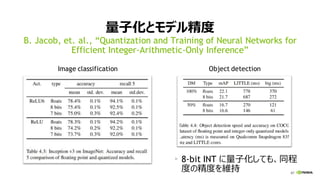
モデル精度向上には、教師データ増が有効
Chen Sun et al., “Revisiting Unreasonable Effectiveness of Data in
Deep Learning Era”, 2017
教師データサイズと認識精度の関係
Object detection (ResNet-101)
左:COCO, 右:PASCALVOC 2007
モデルサイズと認識精度の関係
Object detection (COCO)
ResNet-50/101/152
教師データサイズの指数に比例して精度向上
モデルサイズ増で精度向上
ただし大量の教師データ必要
Better
Better
57. 58. 59. 59
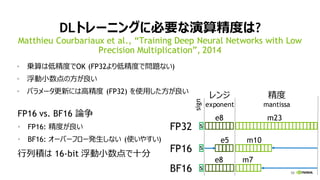
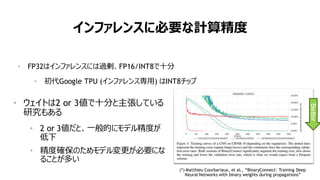
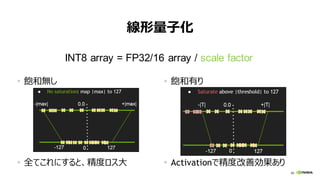
DLトレーニングに必要な演算精度は?
• 乗算は低精度でOK (FP32より低精度で問題ない)
• 浮動小数点の方が良い
• パラメータ更新には高精度 (FP32) を使用した方が良い
Matthieu Courbariaux et al., “Training Deep Neural Networks with Low
Precision Multiplication”, 2014
レンジ
exponent
精度
mantissa
FP32
e8 m23
s
e8 m7
e5 m10
FP16 s
BF16 s
sign
FP16 vs. BF16 論争
• FP16: 精度が良い
• BF16: オーバーフロー発生しない (使いやすい)
行列積は 16-bit 浮動小数点で十分
60. 61. 62. 63. 64. 65. 65
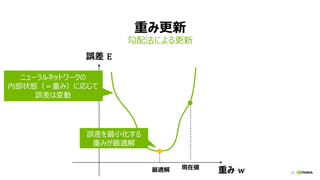
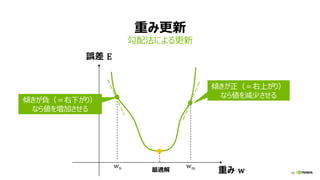
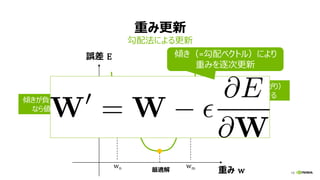
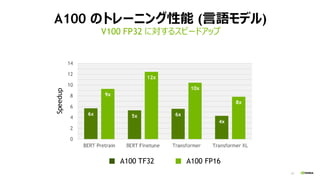
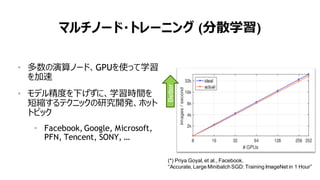
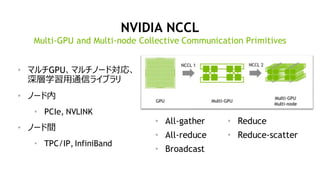
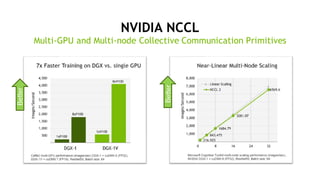
マルチノード・トレーニング (分散学習)
• 多数の演算ノード、GPUを使って学習
を加速
• モデル精度を下げずに、学習時間を
短縮するテクニックの研究開発、ホット
トピック
• Facebook, Google, Microsoft,
PFN, Tencent, SONY, …
(*) Priya Goyal, et al., Facebook,
“Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour”
Better
66. 67. 68. 68
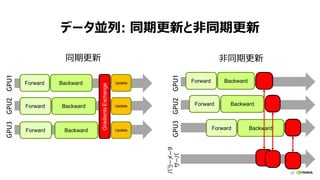
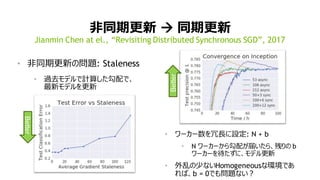
非同期更新 → 同期更新
• 非同期更新の問題: Staleness
• 過去モデルで計算した勾配で、
最新モデルを更新
Jianmin Chen at el., “Revisiting Distributed Synchronous SGD”, 2017
• ワーカー数を冗長に設定: N + b
• N ワーカーから勾配が届いたら、残りの b
ワーカーを待たずに、モデル更新
• 外乱の少ないHomogeneousな環境であ
れば、b = 0でも問題ない?Better
Better
69. 69
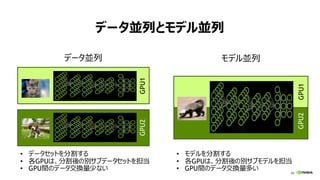
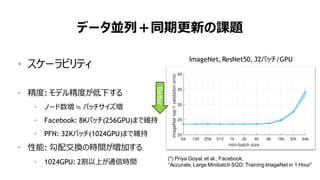
データ並列+同期更新の課題
• スケーラビリティ
• 精度: モデル精度が低下する
• ノード数増 ≒ バッチサイズ増
• Facebook: 8Kバッチ(256GPU)まで維持
• PFN: 32Kバッチ(1024GPU)まで維持
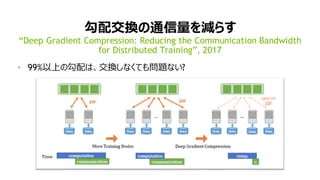
• 性能: 勾配交換の時間が増加する
• 1024GPU: 2割以上が通信時間
ImageNet, ResNet50, 32バッチ/GPU
(*) Priya Goyal, et al., Facebook,
“Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour”
Better
70. 70
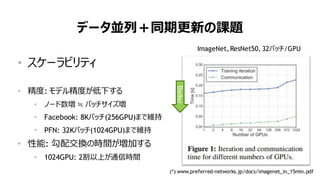
データ並列+同期更新の課題
• スケーラビリティ
• 精度: モデル精度が低下する
• ノード数増 ≒ バッチサイズ増
• Facebook: 8Kバッチ(256GPU)まで維持
• PFN: 32Kバッチ(1024GPU)まで維持
• 性能: 勾配交換の時間が増加する
• 1024GPU: 2割以上が通信時間
(*) www.preferred-networks.jp/docs/imagenet_in_15min.pdf
ImageNet, ResNet50, 32バッチ/GPU
Better
71. 72. 73. 74. 75. 75
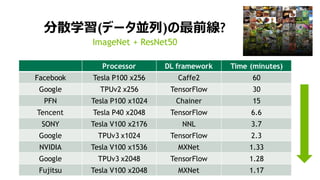
分散学習(データ並列)の最前線?
Processor DL framework Time (minutes)
Facebook Tesla P100 x256 Caffe2 60
Google TPUv2 x256 TensorFlow 30
PFN Tesla P100 x1024 Chainer 15
Tencent Tesla P40 x2048 TensorFlow 6.6
SONY Tesla V100 x2176 NNL 3.7
Google TPUv3 x1024 TensorFlow 2.3
NVIDIA Tesla V100 x1536 MXNet 1.33
Google TPUv3 x2048 TensorFlow 1.28
Fujitsu Tesla V100 x2048 MXNet 1.17
ImageNet + ResNet50
76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88. 89. 89
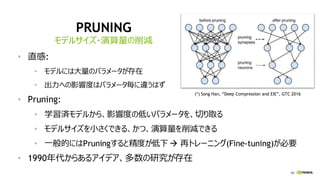
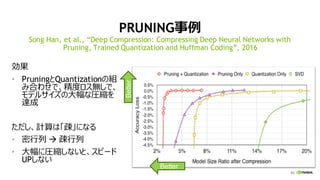
PRUNING
• 直感:
• モデルには大量のパラメータが存在
• 出力への影響度はパラメータ毎に違うはず
• Pruning:
• 学習済モデルから、影響度の低いパラメータを、切り取る
• モデルサイズを小さくできる、かつ、演算量を削減できる
• 一般的にはPruningすると精度が低下→ 再トレーニング(Fine-tuning)が必要
• 1990年代からあるアイデア、多数の研究が存在
モデルサイズ・演算量の削減
(*) Song Han, “Deep Compression and EIE”, GTC 2016
90. 90
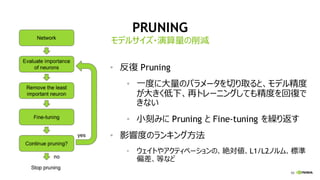
PRUNING
• 反復 Pruning
• 一度に大量のパラメータを切り取ると、モデル精度
が大きく低下、再トレーニングしても精度を回復で
きない
• 小刻みに Pruning と Fine-tuning を繰り返す
• 影響度のランキング方法
• ウェイトやアクティベーションの、絶対値、L1/L2ノルム、標準
偏差、等など
モデルサイズ・演算量の削減
91. 92. 93. 94. 94
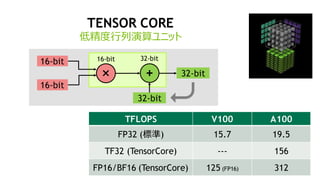
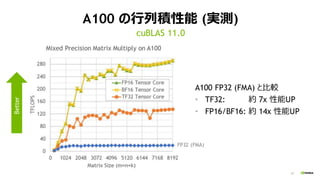
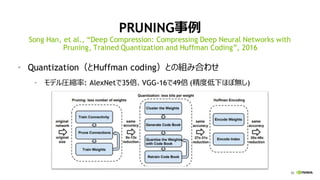
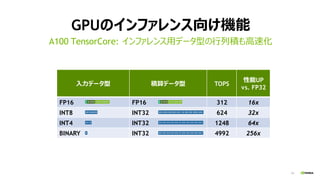
入力データ型 積算データ型 TOPS
性能UP
vs. FP32
FP16 FP16 312 16x
INT8 INT32 624 32x
INT4 INT32 1248 64x
BINARY INT32 4992 256x
GPUのインファレンス向け機能
A100 TensorCore: インファレンス用データ型の行列積も高速化
95. 95
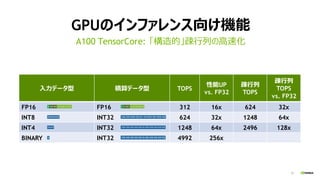
入力データ型 積算データ型 TOPS
性能UP
vs. FP32
疎行列
TOPS
疎行列
TOPS
vs. FP32
FP16 FP16 312 16x 624 32x
INT8 INT32 624 32x 1248 64x
INT4 INT32 1248 64x 2496 128x
BINARY INT32 4992 256x
GPUのインファレンス向け機能
A100 TensorCore: 「構造的」疎行列の高速化
96. 96
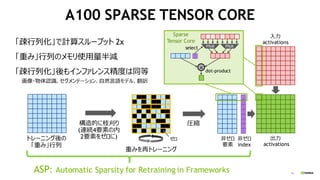
A100 SPARSE TENSOR CORE
構造的に枝刈り
(連続4要素の内
2要素をゼロに)
圧縮
非ゼロ
index
非ゼロ
要素
ゼロ
× dot-product
トレーニング後の
「重み」行列
入力
activations
mux
重みを再トレーニング
出力
activations
select
「疎行列化」で計算スループット 2x
「重み」行列のメモリ使用量半減
「疎行列化」後もインファレンス精度は同等
画像・物体認識、セグメンテーション、自然言語モデル、翻訳
Sparse
Tensor Core
mux
ASP: Automatic Sparsity for Retraining in Frameworks
97. 98.









![33
全結合層 (FULLY CONNECTED LAYER)
行列ベクトル積 (y = Wx)
Ny
計算量:
2 * 出力ノード数 (Ny)
* 入力ノード数 (Nx)
入力 x 出力 y重み W
Nx
重み W
入力 x
出力 y
Ny
Nx
Nx
[性能律速点]
メモリバンド幅](https://image.slidesharecdn.com/20200716-200715002417/85/DEEP-LEARNING-GPU-33-320.jpg)
![34
全結合層 (FULLY CONNECTED LAYER)
ミニバッチ学習で、行列積に (Y = W・X)
重み W
計算量:
2 * 出力ノード数 (Ny)
* 入力ノード数 (Nx)
* ミニバッチサイズ (Nb)
入力 X 出力 Y重み W
Nb * Nx Nb * Ny
入力 X
出力 Y
Ny
Nx
Nx
Nb
[性能律速点]
演算性能](https://image.slidesharecdn.com/20200716-200715002417/85/DEEP-LEARNING-GPU-34-320.jpg)





















![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Progressive Growing of GANs for Improved Quality, Stability, and Varia...](https://cdn.slidesharecdn.com/ss_thumbnails/kuboshizuma20180316-180525003941-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)














































