基盤モデル | Foundationmodels
6
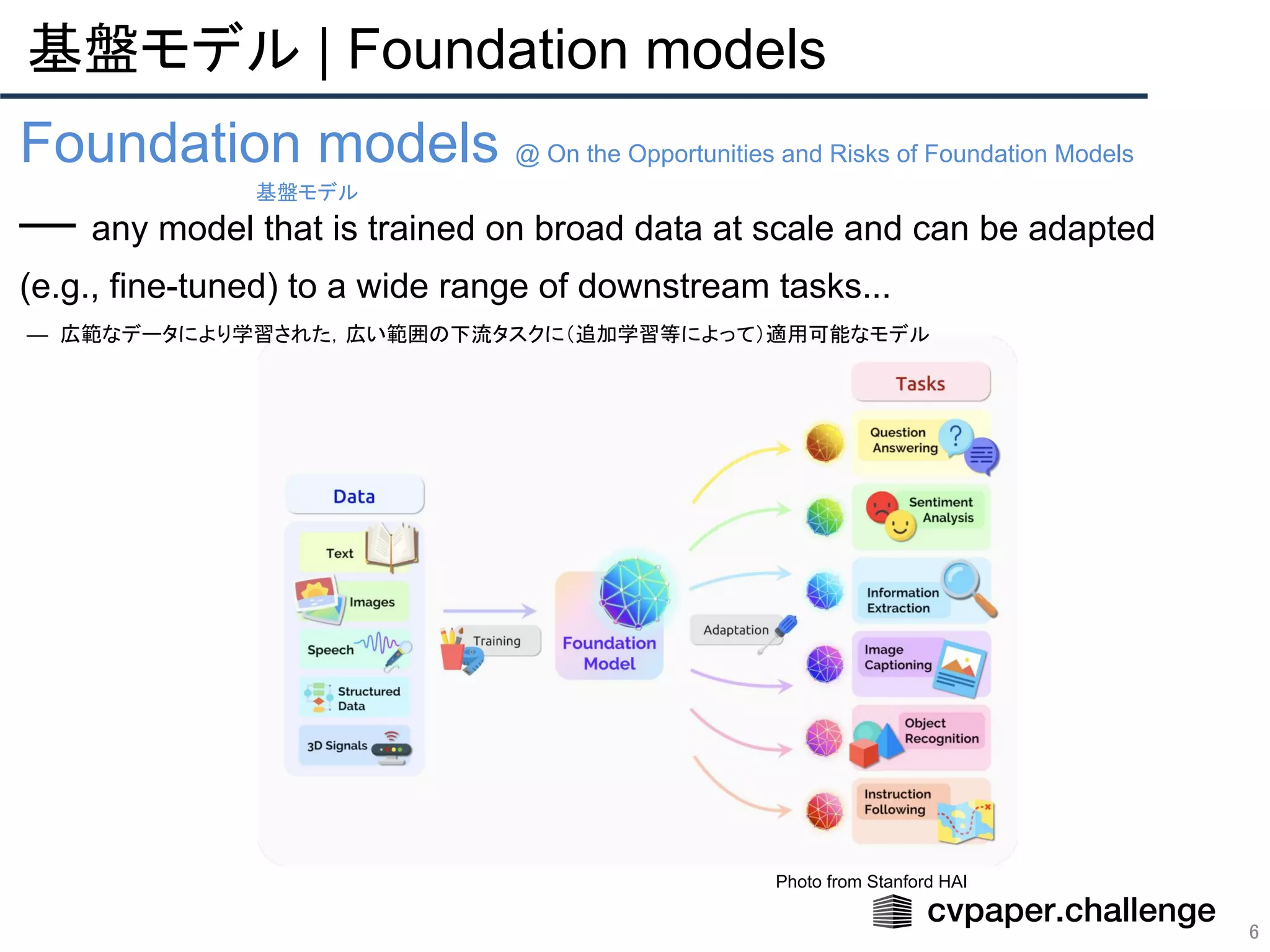
Foundation models @ On the Opportunities and Risks of Foundation Models
— any model that is trained on broad data at scale and can be adapted
(e.g., fine-tuned) to a wide range of downstream tasks...
— 広範なデータにより学習された,広い範囲の下流タスクに(追加学習等によって)適用可能なモデル
基盤モデル
Photo from Stanford HAI
7.
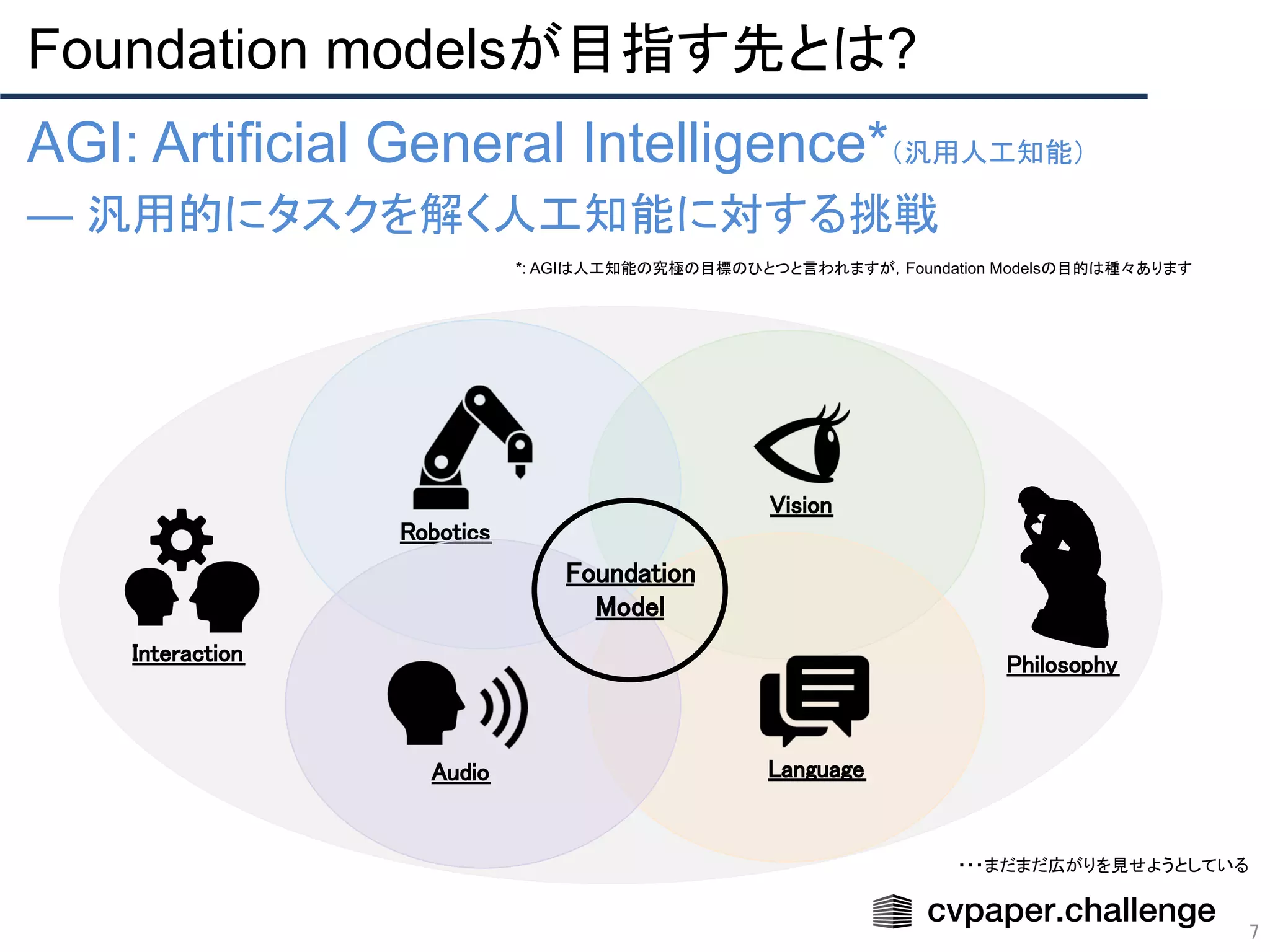
Foundation modelsが目指す先とは?
7
AGI: ArtificialGeneral Intelligence*(汎用人工知能)
— 汎用的にタスクを解く人工知能に対する挑戦
Robotics
Vision
Language
Audio
Foundation
Model
Philosophy
Interaction
・・・まだまだ広がりを見せようとしている
*: AGIは人工知能の究極の目標のひとつと言われますが,Foundation Modelsの目的は種々あります
13
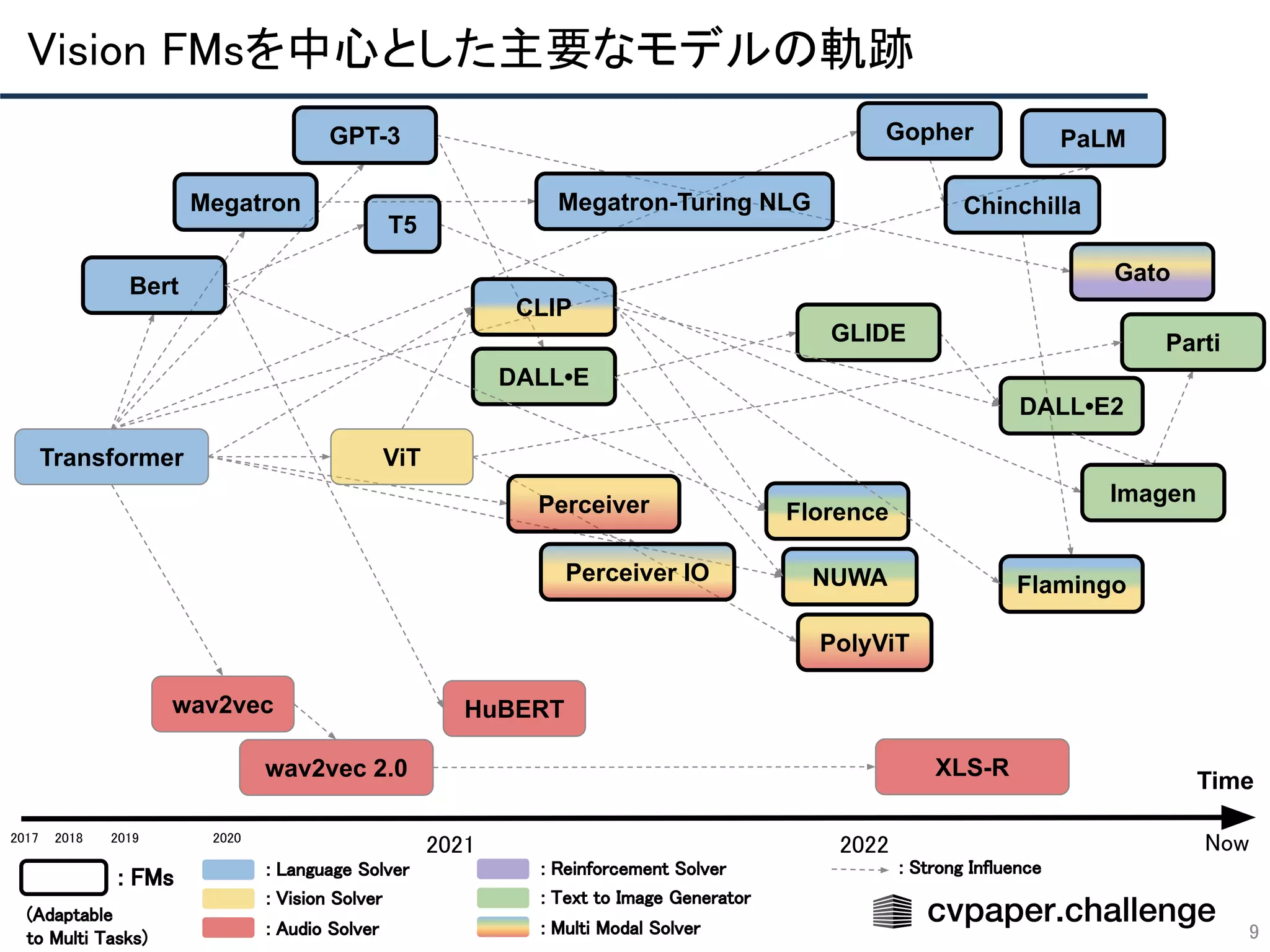
NLP分野にてTransformerが拡がる
● BERT(Bi-directional EncoderRepresentations from Transformers)
● 大量の汎用テキストデータで事前学習→タスクに合わせて追加学習
● 翻訳・予測などNLPのタスクを幅広く解くことができるモデル
● 文章の「意味を理解」することができるようになったと話題
● なぜBERTは躍進した?
● 自己教師学習によりラベルなし文章を学習に適用可能
● 双方向モデルにつき,単語の前後から文脈を把握
BERTでは多くのタスクを単一モデルで解くことができ
るが,その学習は「文章のマスクと復元」の自己教師
あり学習により実施される
Attention is All You Need.(元データ)
↓ 意図的に欠損作成
Attention is All ___ Need.(復元前)
↓ BERTにより推定
Attention is All You Need.(復元後)
[Devlin(Google)+, NAACL19]
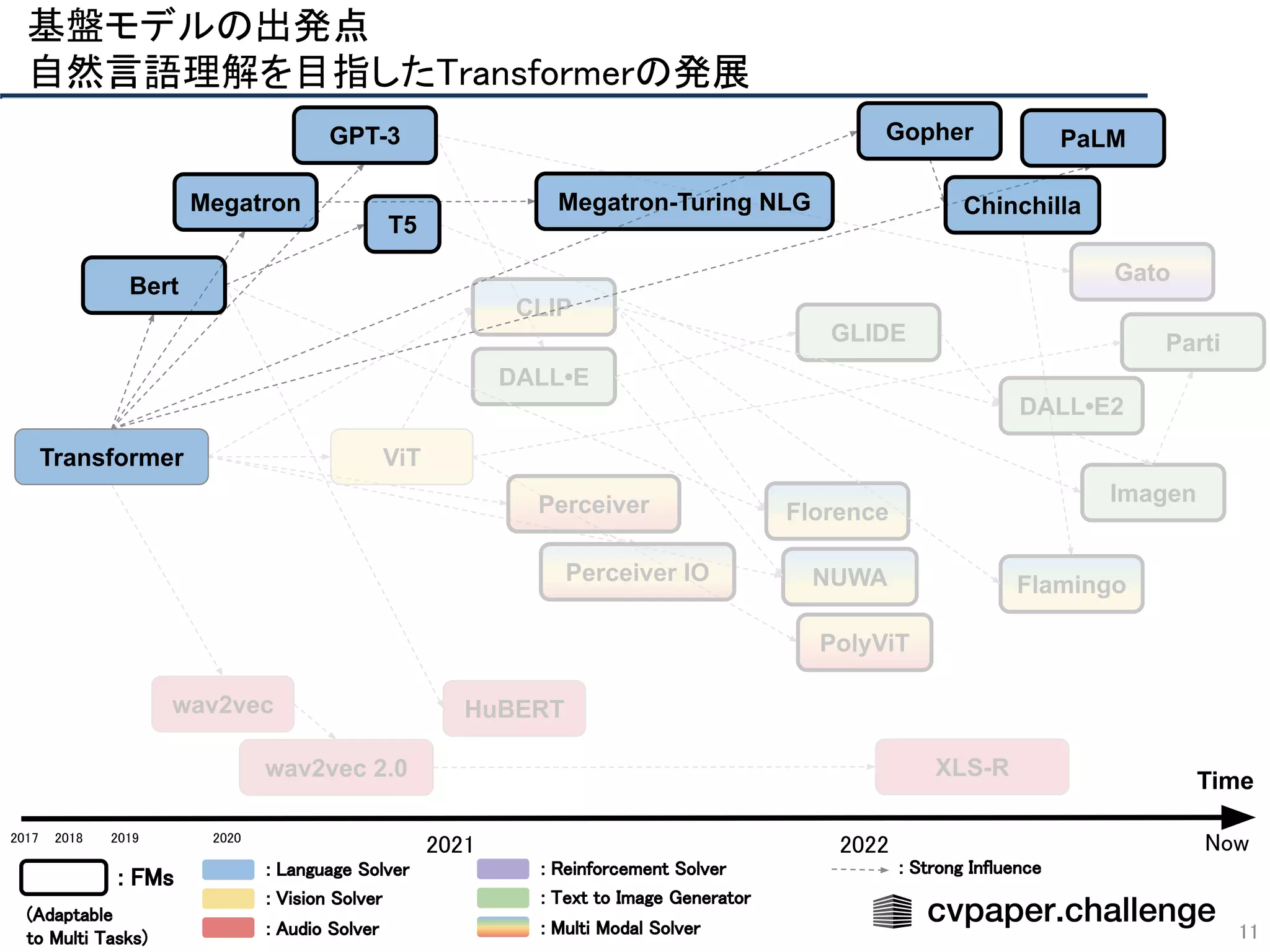
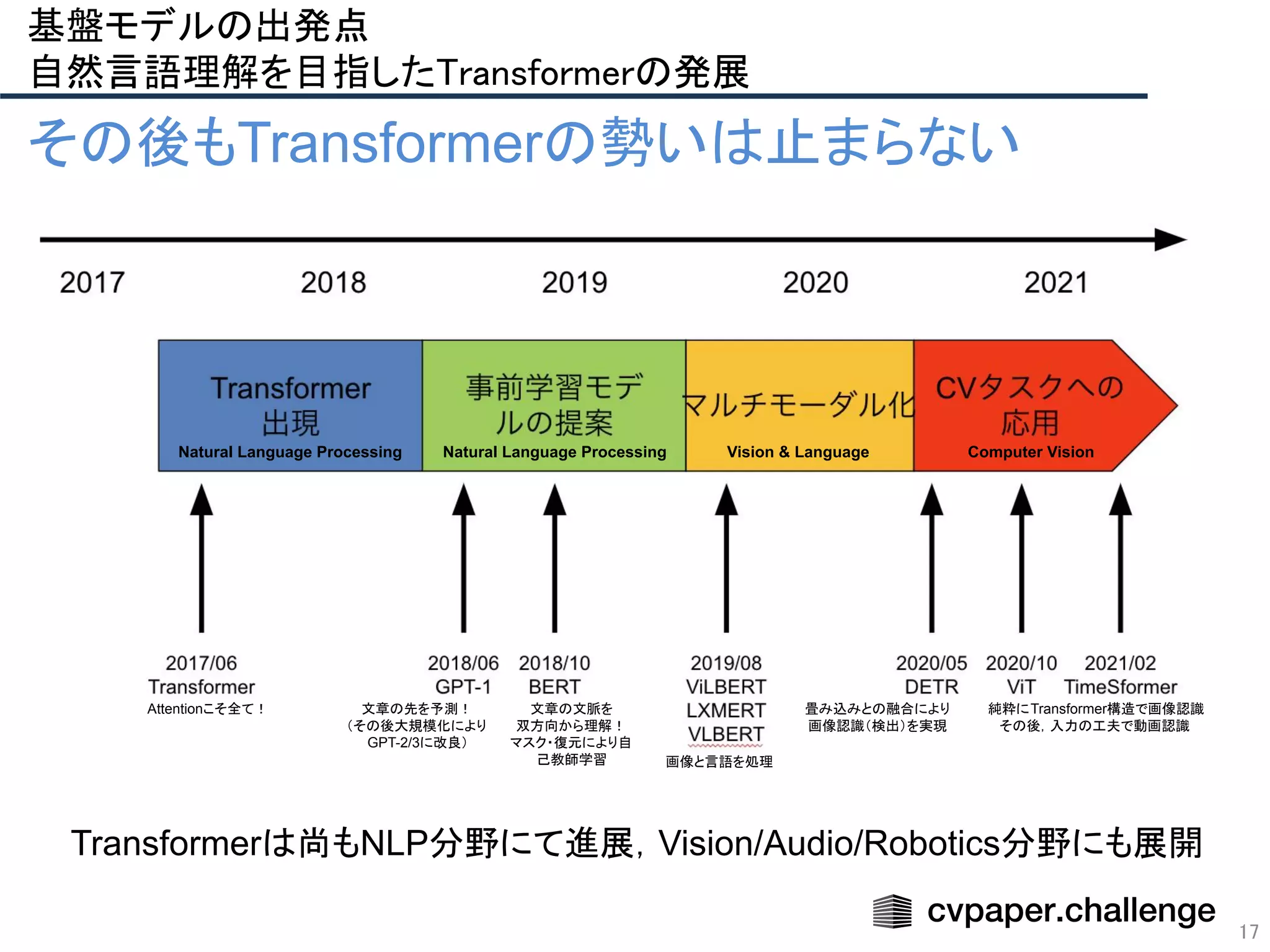
基盤モデルの出発点
自然言語理解を目指したTransformerの発展
Zero-Shot Text-to-Image Generation(DALL·E論文)
35
著者 : Aditya Ramesh, et al.
VQ-VAE(dVAE) + Transformer(120億パラメータ)の構成で
約2.5億のテキスト-画像ペアで事前学習させ,
テキストから完成度の高い画像を自動生成
● VQ-VAEによって256×256のRGB画像を32×32(=1024)の画像トークンに変換(encode)
● BPE圧縮によってキャプションを256のテキストトークンに変換(encode)
● 上記のトークンをconcatしてembedding,Sparse Transformerを用いて各潜在変数を学習
● 画像生成時はTransformerで潜在変数を予測し,VQ-VAEによって画像を復元(decode)
○ CLIPによって入力テキストとの類似度でランキングして出力
● MS-COCOにおいて,zero-shotで既存手法に匹敵するFIDスコア達成
● 人間による評価実験において,
既存手法(DF-GAN)と比較してよりリアルで入力テキスト通りの画像を生成
ICML 2021 OpenAI 画像生成
テキスト-画像
pre-train zero-shot
text to image
Foundation Model
36.
VQGAN-CLIP: Open DomainImage Generation and Editing with
Natural Language Guidance
36
著者 : Katherine Crowson et al.
● 複雑な文章をもとにした画像生成システム
● CLIPを用いてテキスト・画像ペアの類似性を評価する損失関数を定義し、画像生成の潜在空間を更新すること
で画像を生成
● 実行時間はやや遅い(イテレーション回数が多い)が学習コストが不要
GitHub
https://github.com/eleutherai/vqgan-clip
Kaggle
https://www.kaggle.com/code/basu369vi
ctor/playing-with-vqgan-clip/notebook
arXiv 2022 EleutherAI 画像生成
テキスト-画像
pre-train zero-shot
text to image
Foundation Model
37.
GLIDE: Towards PhotorealisticImage Generation and Editing with Text-Guided Diffusion Models
37
著者 : Alex Nichol, et al.
テキストからの画像生成タスクにおいて
DALL-Eよりリアルであると評価された“GLIDE”
● パラメータ数35億+15億の誘導拡散モデルGLIDEを提案
● GLIDEを2種類の誘導方法からテキスト条件付き画像生成を行い比較
○ CLIP guidance:CLIP(ViT-L)の潜在空間の類似度を利用(classifierの知識を活用)
○ classifier-free guidance:確率的に条件付けを除外し分類も同時学習(
classifier不要)
● 比較の結果classifier-free guidanceの方が本物らしさとキャプション類似性について優位
● 独自フィルタによって生成画像の悪用を防止
● サンプリングがGANよりも大幅に遅いのがネック
ACL 2022 OpenAI 画像生成
テキスト-画像
pre-train zero-shot
text to image
Foundation Model
38.
Hierarchical Text-Conditional ImageGeneration with CLIP Latents (DALL·E 2 論文)
38
著者 : Aditya Ramesh, et al.
DDPM + CLIPで
約6.4億のテキスト-画像ペアで事前学習し,
GLIDEと比較してより多様性のある画像を生成
● 事前分布(prior)として拡散モデルを用いる
○ テキストからCLIP画像埋め込みを生成.自己回帰モデルも試したが拡散モデルの方が良い結果に
● デコーダとしてGLIDEとほぼ同じ35億パラメータの拡散確率モデルを用いる
○ CLIP画像埋め込みから画像を生成. GLIDEと同様にclassifier-free guidanceを使用
→unCLIPと総称
arXiv (2022) OpenAI 画像生成
テキスト-画像
pre-train zero-shot
text to image
Foundation Model
39.
Photorealistic Text-to-Image DiffusionModels with Deep Language
Understanding (Imagen 論文)
39
著者 : Chitwan Saharia, et al.
● テキストのみを事前学習し凍結させた大規模言語モデル(T5-XLL)が画像生成に有効
● DDPMをスケーリングするよりも,大規模言語モデルを拡張する方が効く
● DDPMは計約8.6億のテキスト-画像ペアで事前学習
● Efficient U-Netを導入し,計算効率・メモリ効率を向上させ,学習時間を短縮
COCOのFID指標においてDALLE•2を超える性能
arXiv (2022) Google 画像生成
テキスト-画像
pre-train zero-shot
text to image
Foundation Model
40.
Scaling Autoregressive Modelsfor Content-Rich Text-to-Image Generation
(Parti 論文)
40
arXiv (2022) Google 画像生成
テキスト-画像
pre-train zero-shot
text to image
Foundation Model
著者 : Jiahui Yu, et al.
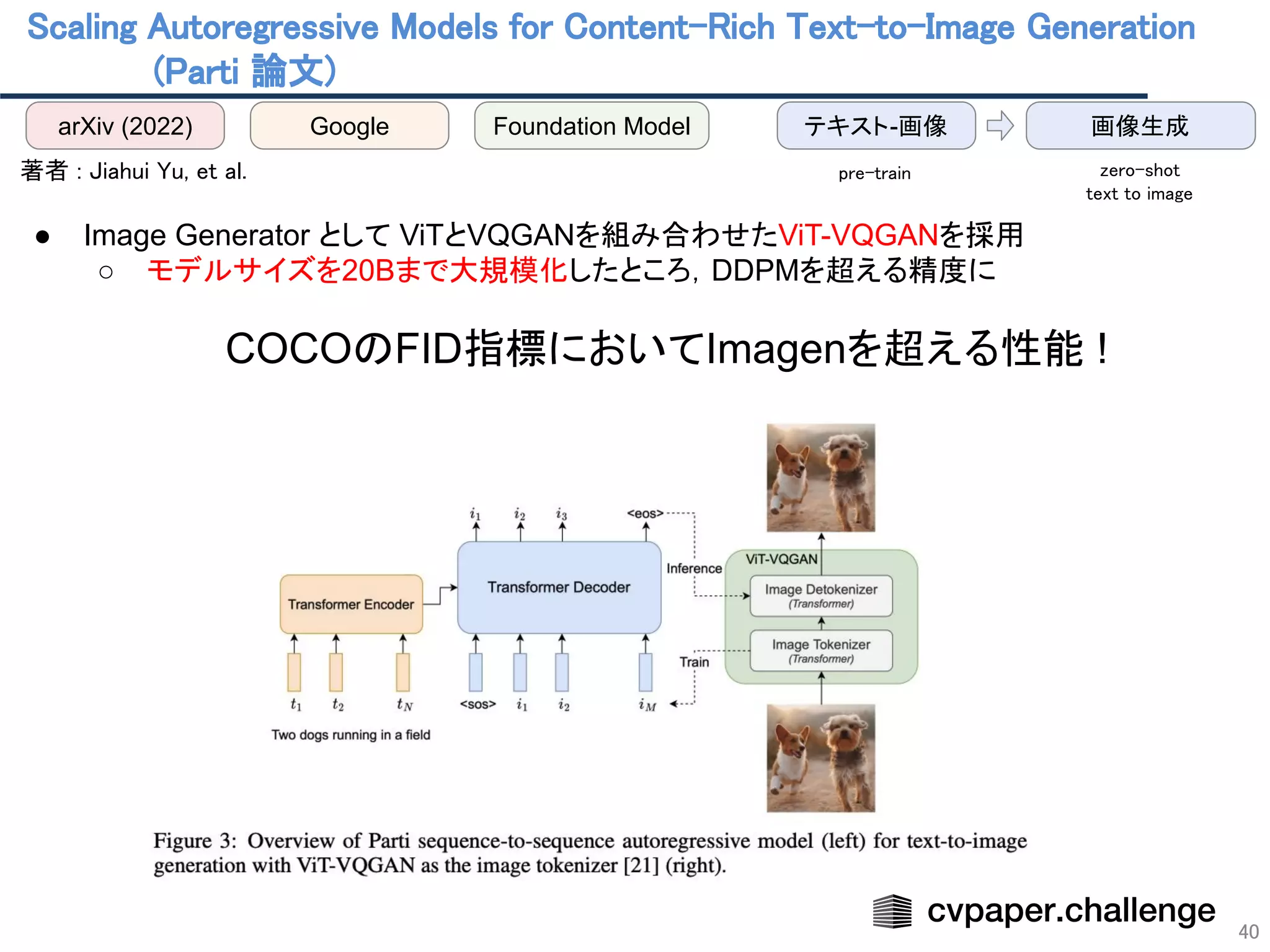
● Image Generator として ViTとVQGANを組み合わせたViT-VQGANを採用
○ モデルサイズを20Bまで大規模化したところ,DDPMを超える精度に
COCOのFID指標においてImagenを超える性能 !
55
学習データの権利・倫理関係問題
○ Web上の大量データで学習→含むバイアスも大量
特定の集団に対して不公平/有害な出力を招くリスク
Maybe Microsoft’sTay AI didn’t have a meltdown…
https://medium.com/@thepathtochange/maybe-microsoft-s-tay-ai-didn-t-have-a-meltdown-4291b9
10a37c
Google's Artificial Intelligence Hate Speech
Detector Is 'Racially Biased,' Study Finds
https://www.forbes.com/sites/nicolemartin1/2019/08/13/googles-artificial-intelligence-hate-s
peech-detector-is-racially-biased/#1418e6d8326c
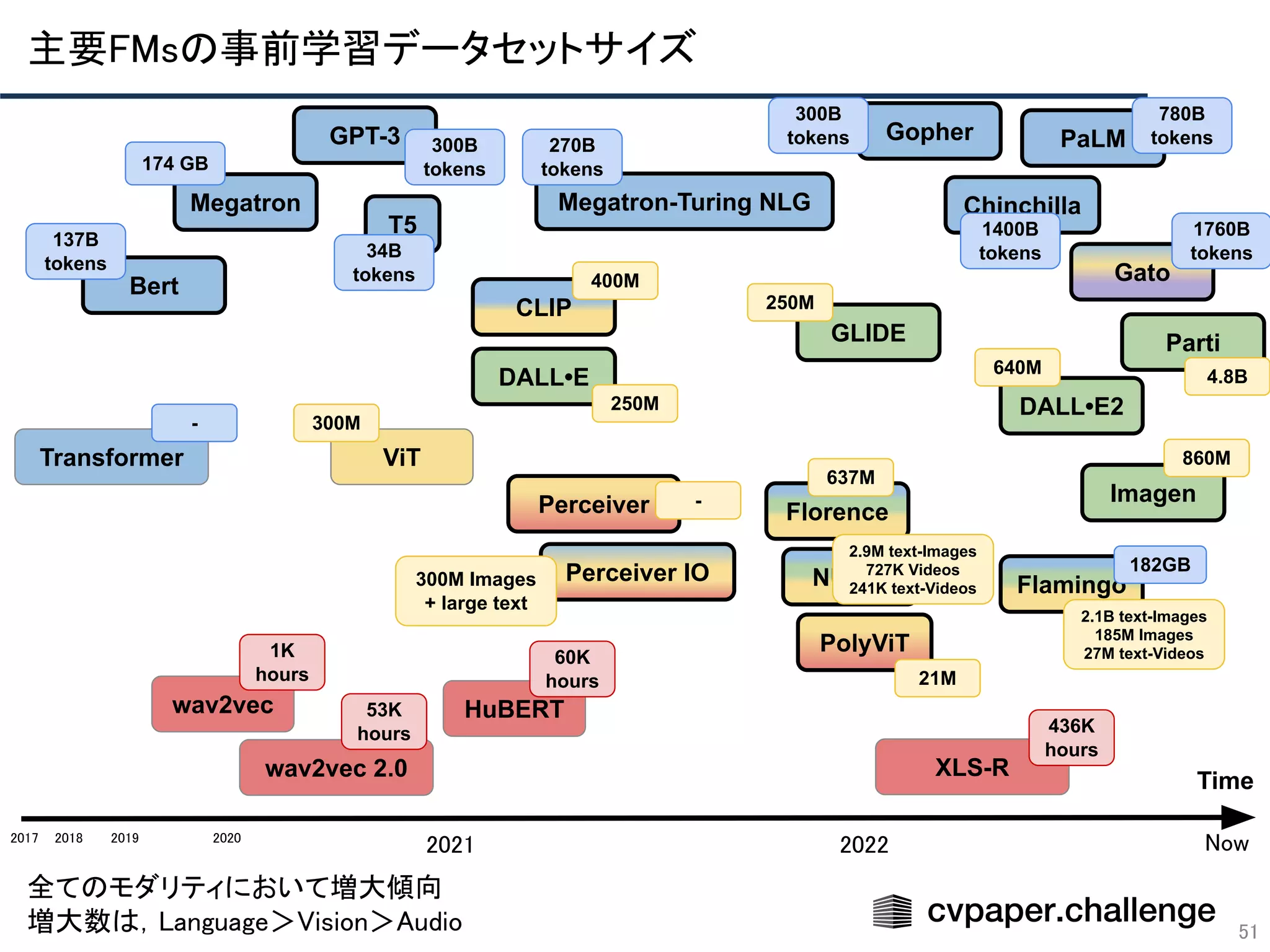
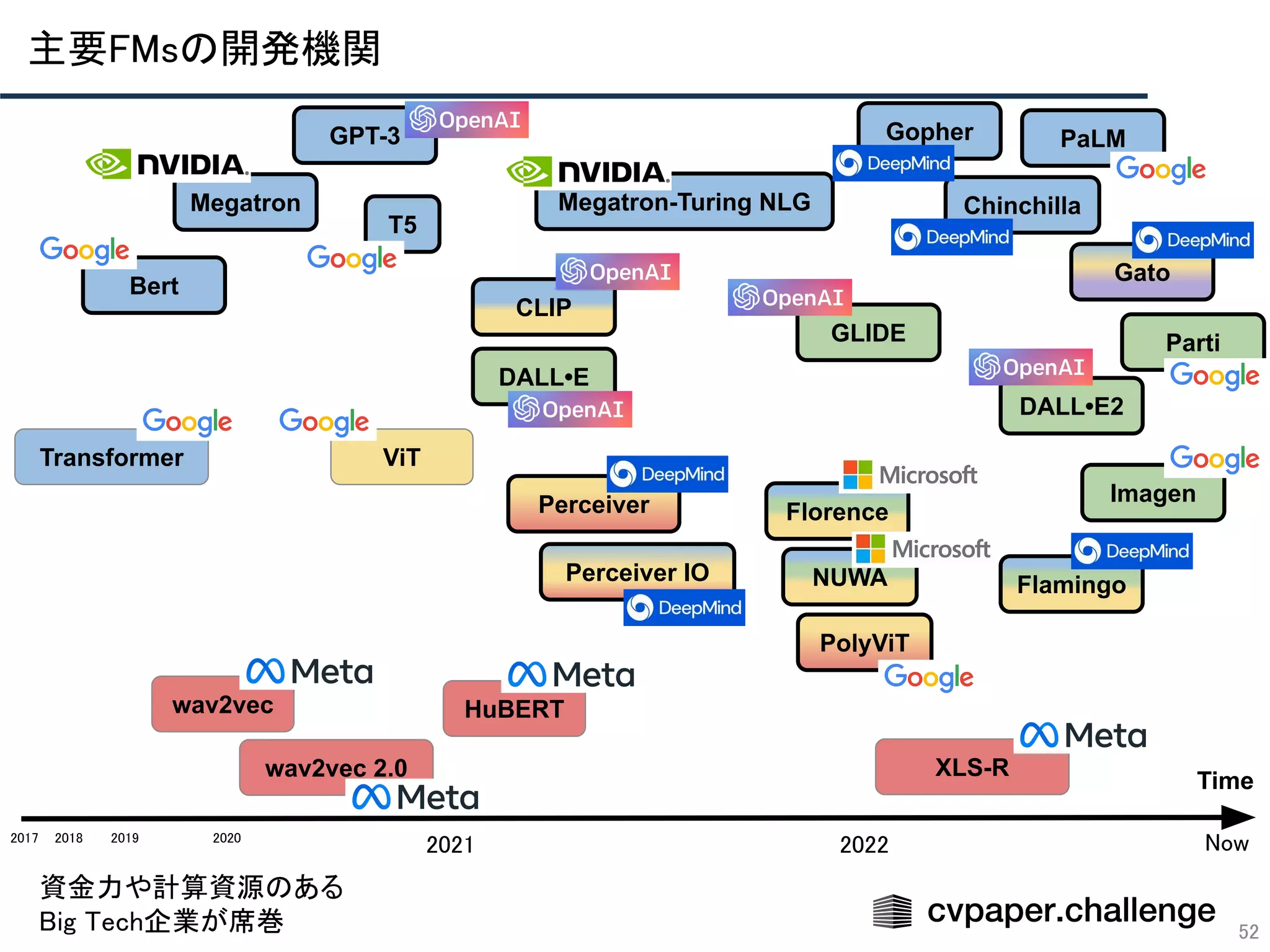
スケーリング則が基盤モデル研究に与えるリスク
近年の基盤モデルでは,
出力されるバイアスも評価観点として重視傾向
Center for Researchon Foundation Models (CRFM)
58
Percy Liang率いるStanford
● HAIから分岐してStanford大学内に2021年に発足
● Foundation Model開発に特化した研究機関
● CSだけでなく10種以上の専門領域から研究者が集結
● 不用意な大規模化でなく、効率性・堅牢性・
解釈可能性・倫理的健全性の実現を目指す理論研究
https://crfm.stanford.edu/





![2022年現在,CVに波及する基盤モデルの衝撃
8
DALL•E2やFlamingoなど言語と視覚を繋ぐモデルが台頭
画像・動画・言語の複数モダリティを同時に処理
● 画像/動画と言語を別々に学習して統合
● 70Bパラメータの事前学習済みテキストエンコーダーと
CLIP方式で事前学習済み画像エンコーダーがベース
● ベースラインのわずか 1/1000程度のみのサンプル提示で
VQAなどの6/16のマルチモーダルタスクで SoTA達成.
追加学習を行うと更に 5つのベンチマークで SoTA達成.
自然言語から高精細な画像を生成
● CLIP : 画像・言語空間の対応関係を高度に学習
○ WEB上から収集した約4億組の画像・言語ペアにより学習
● DDPM : ノイズ付与/復元により高解像画像描画するモデル
● CLIPの画像埋め込み特徴を生成するように DDPM
を学習させ,多様性に富んだ Text-to-Imageのモデルを構築
● この結果,AIは創造性を持ったと総評されるに至る
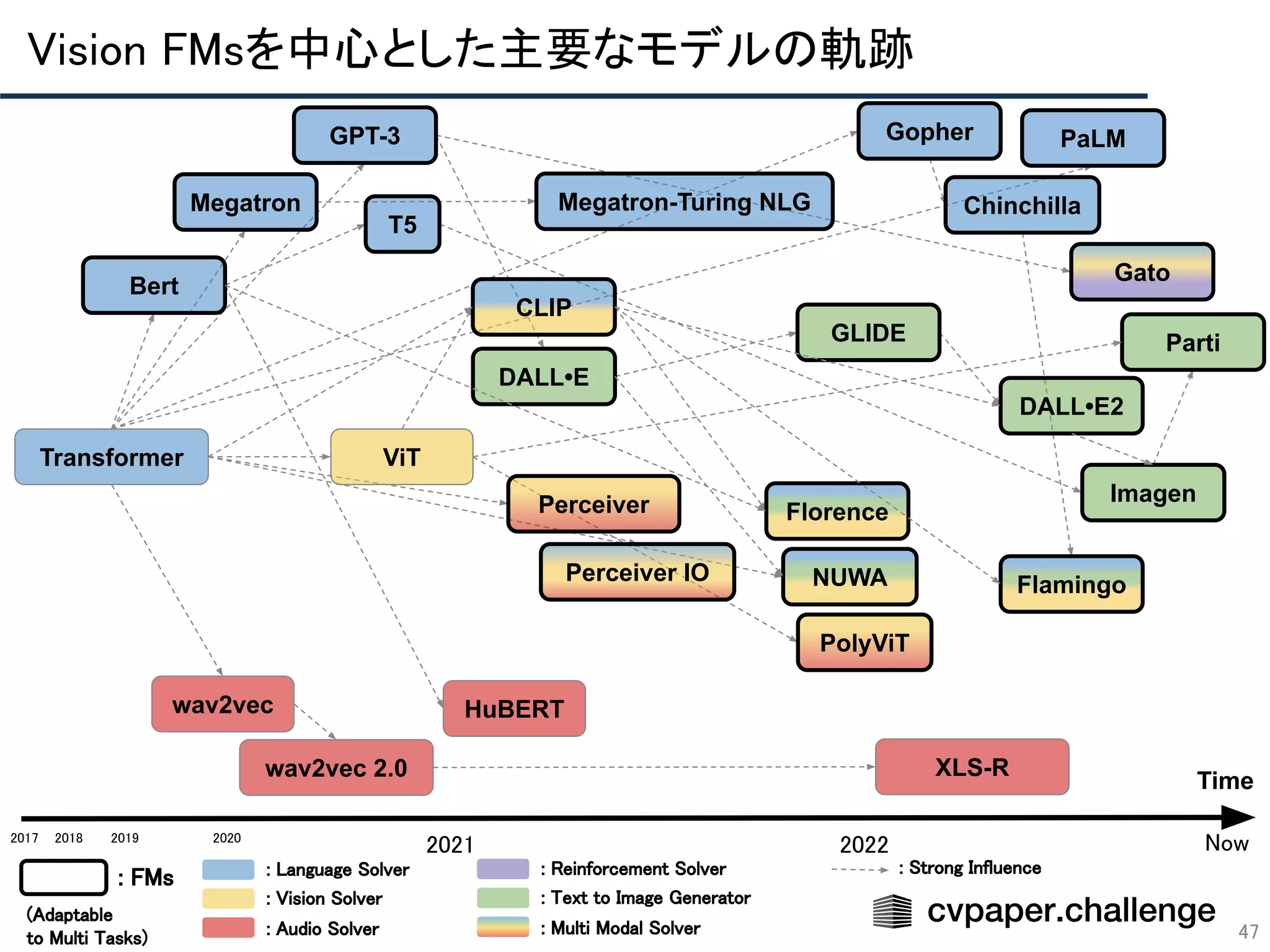
次ページよりTransformer〜Foudation Models(FMs)に至るまでを解説↓
Flamingo [Alayac(DeepMind)+, arXiv22]
DALL•E 2 [Ramesh(OpenAI)+, arXiv22]
ロボットのような半顔を持つ
サルバドール・ダリの鮮やかな肖像画
ベレー帽と黒のタートルネック
を身に付けた柴犬
葉を茂らせた手掌のクローズアップ](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-8-2048.jpg)

![12
自然言語処理(NLP)分野でTransformerが誕生
● Transformer
● Self-Attention(自己注意)機構により
系列データを一括同時処理可能に
(従来のRNNでは逐次的に処理
→並列計算できず 処理に時間がかかる ,
離れた単語関係が見えず 長文理解は困難 )
○ GPUフレンドリーで
容易に並列計算による学習高速化可能
○ 入力シーケンス全体を考慮可能
● 劇的な学習時間短縮・性能向上を同時に実
現し,ブレイクスルーを引き起こした
(当時の翻訳タスクでSoTAを達成)
Transformerについてはこちらも参照
https://www.slideshare.net/cvpaperchallenge/transformer-247407256
[Vaswani(Google)+, NeurIPS17]
基盤モデルの出発点
自然言語理解を目指したTransformerの発展
急発達するHPCによるGPU/TPU並列計算技術と相性抜群.
近代のほぼ全ての大規模基盤モデルは,Transformerがベースに](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-12-2048.jpg)
![13
NLP分野にてTransformerが拡がる
● BERT(Bi-directional Encoder Representations from Transformers)
● 大量の汎用テキストデータで事前学習→タスクに合わせて追加学習
● 翻訳・予測などNLPのタスクを幅広く解くことができるモデル
● 文章の「意味を理解」することができるようになったと話題
● なぜBERTは躍進した?
● 自己教師学習によりラベルなし文章を学習に適用可能
● 双方向モデルにつき,単語の前後から文脈を把握
BERTでは多くのタスクを単一モデルで解くことができ
るが,その学習は「文章のマスクと復元」の自己教師
あり学習により実施される
Attention is All You Need.(元データ)
↓ 意図的に欠損作成
Attention is All ___ Need.(復元前)
↓ BERTにより推定
Attention is All You Need.(復元後)
[Devlin(Google)+, NAACL19]
基盤モデルの出発点
自然言語理解を目指したTransformerの発展](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-13-2048.jpg)
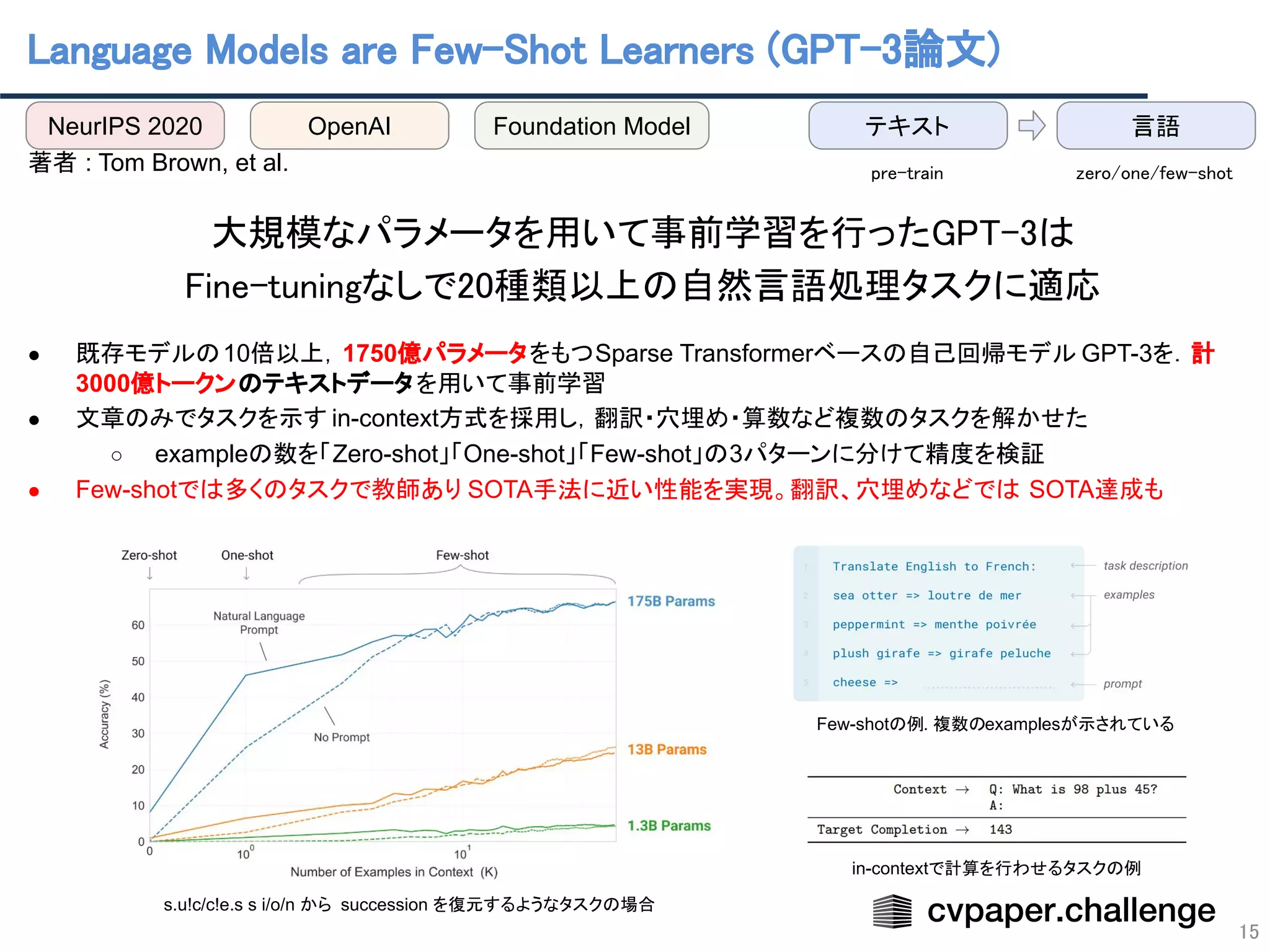
![GPT-3論文はNeurIPS 2020にて
Best Paper Awardを獲得
14
人間レベルの文章生成を可能に
● GPT(Generative Pre-trained Transformer)
● 与えられた文章の先を予測して文章生成
● 拡張される度にパラメータ数 / 学習テキストサイズが一気に増加
○ GPT : 1.2億パラメータ
○ GPT-2 : 15億パラメータ, 40GBテキスト
○ GPT-3 : 1750億パラメータ, 570GBテキスト(3000億トークン)
○ 爆発的なパラメータ数の増加により大幅な性能改善が見られた
● 「シンギュラリティが来た」と言われるほどに文章生成能力を獲得
https://neuripsconf.medium.com/announcing-the-neurips-2020-award-recipients-73e4d3101537
[Brown(OpenAI)+, NeurIPS20]
基盤モデルの出発点
自然言語理解を目指したTransformerの発展](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-14-2048.jpg)


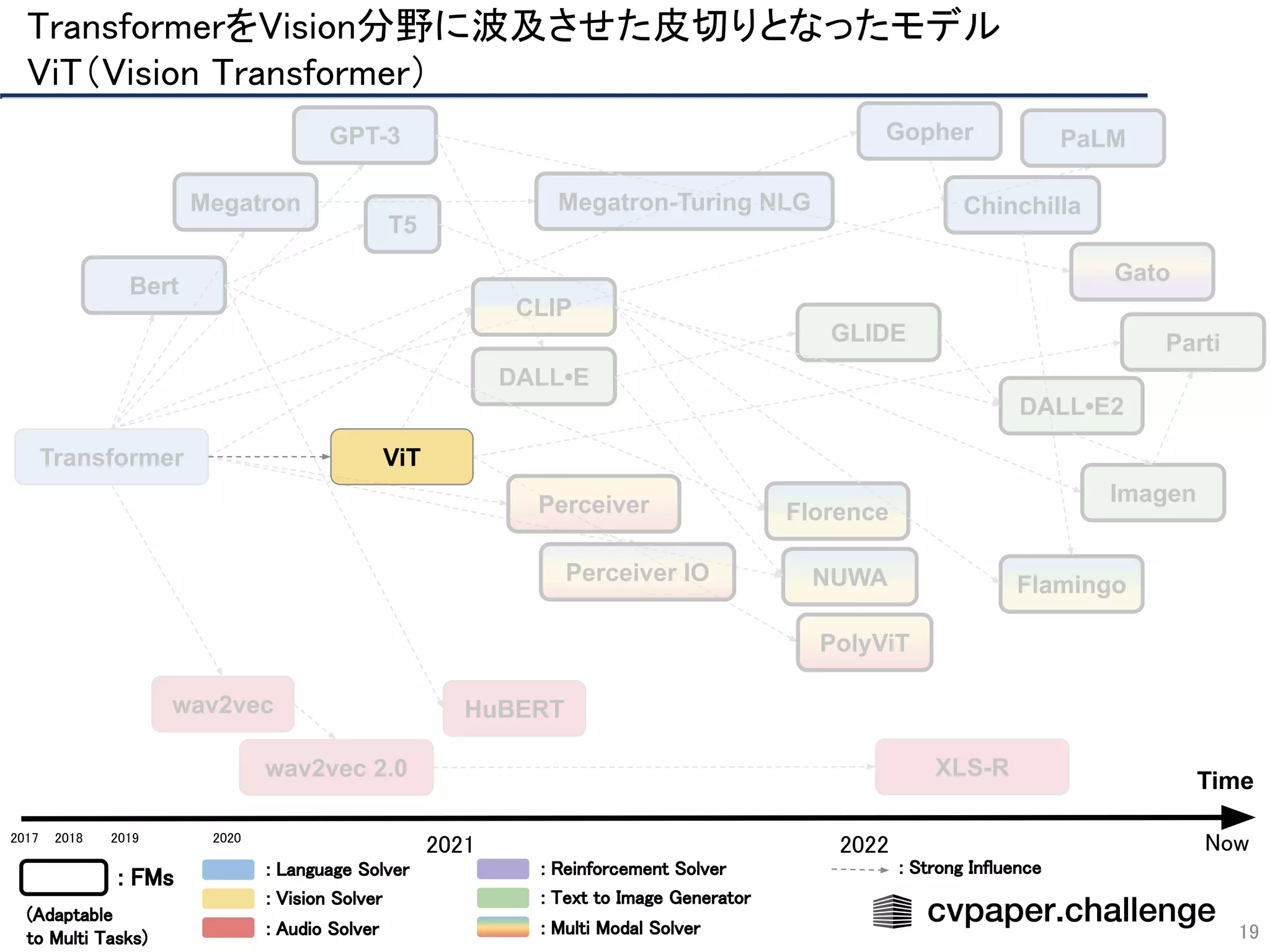
![20
Vision Transformer(ViT)
● 純Transformer構造により画像認識
● 画像パッチを単語と見なして処理
● Encoderのみ使用 / MLPを通して出力
● 3億枚のラベル付き画像で事前学習
→CNNを超えたか?と話題に
● ViTの後にも亜種が登場
● CNN + Transformer: CvT, ConViT(擬似畳込み),
CMT, CoAtNet
● MLP: MLP-Mixer, gMLP(Attentionそのものではなく構造が重要?)
● ViT: DeiT, Swin Transformer
ViT [Dosovitskiy(Google)+, ICLR21]
【Swin Transformer V1/V2】
Swin Transformer V1 [Liu(Microsoft)+, ICCV21]
Swin Transformer V2 [Liu(Microsoft)+, CVPR22]
TransformerをVision分野に波及させた皮切りとなったモデル
ViT(Vision Transformer)](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-20-2048.jpg)
![21
ViTでも自己教師あり学習できることを実証
● ViTでは教師あり学習 @ ImageNet-1k/22k, JFT-300M(Googleが誇る3億のラベル付き画像データ)
● 初期よりContrastive Learning (対照学習)が提案・使用
● SimCLR / MoCo / DINOいずれもViTを学習可能
SimCLR [Chen+, ICML20] DINO [Caron+, ICCV21]
自己教師あり学習では Contrastive Learningが主流の1つ
Transformerへ適用する研究も多数
MoCo [He+, CVPR20]
TransformerをVision分野に波及させた皮切りとなったモデル
ViT(Vision Transformer)](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-21-2048.jpg)
![22
ViTにおける自己教師あり学習の真打ち!?
● “ViTでBERTする” Masked AutoEncoder (MAE)
● 画像・言語・音声の自己教師あり学習 Data2vec
MAE [He+, CVPR22]
Data2vec [Baevski+, arXiv22]
どちらも「マスクして復元」という方法論
● MAEは画像における自己教師あり学習
● Data2vecは3つのモダリティ(但しFTは個別)
● 今後,基盤モデルのための自己教師あり学習が
登場する可能性は大いにある
TransformerをVision分野に波及させた皮切りとなったモデル
ViT(Vision Transformer)](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-22-2048.jpg)

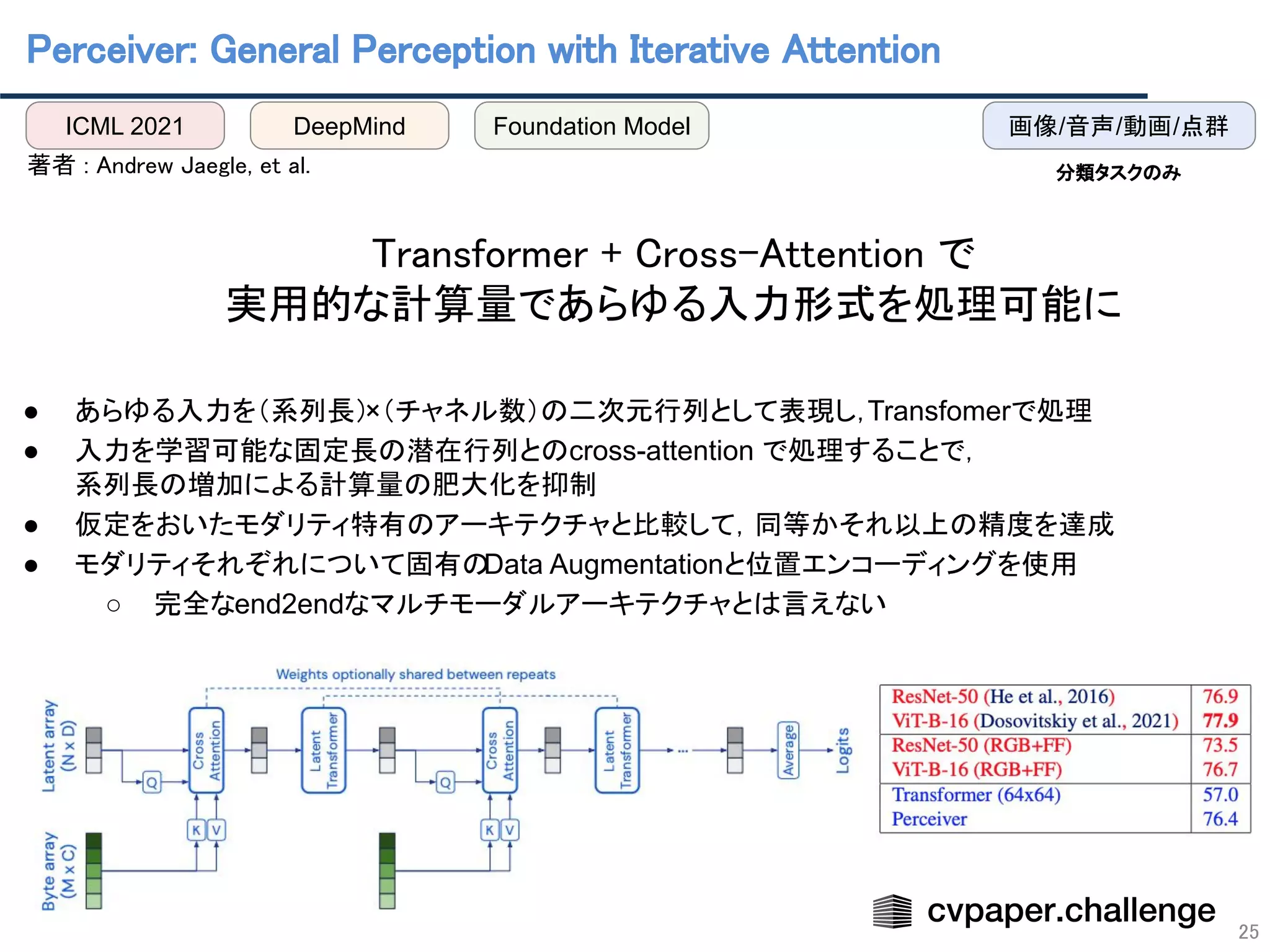
![Perceiver IO: A General Architecture for Structured
Inputs & Outputs
26
著者 : Andrew Jaegle, et al.
● 複数モダリティのデータを取り扱える
Perceiverは分類タスクのみに特化していた
● 複数モダリティの入力に対し,複数の出力(タスク)に対応可能な
Perceiver IOを提案
● 扱ったタスク
○ セグメンテーション ,言語の多様なタスク,動画予測,(
StarCractⅡ)
● 手法
○ 入力配列を潜在空間の配列に対応付けるアテンションモジュールを適用して符号化
○ 複数のアテンションモジュールを適用して潜在空間のパラメータを計算
○ 潜在空間の配列と出力配列を対応付けるアテンションモジュールを適用して復号
● 事前学習では,テキストは自己教師あり学習,画像は教師あり学習
○ 後にDeepMindは,画像などにもMAEを用いて自己教師ありで事前学習させる
Hierarchical
Perceiver[Carreira+, 2022]を発表
ICLR 2022 DeepMind Foundation Model 言語/画像/動画/音声
テキスト/画像
fine-tune
pre-train](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-26-2048.jpg)

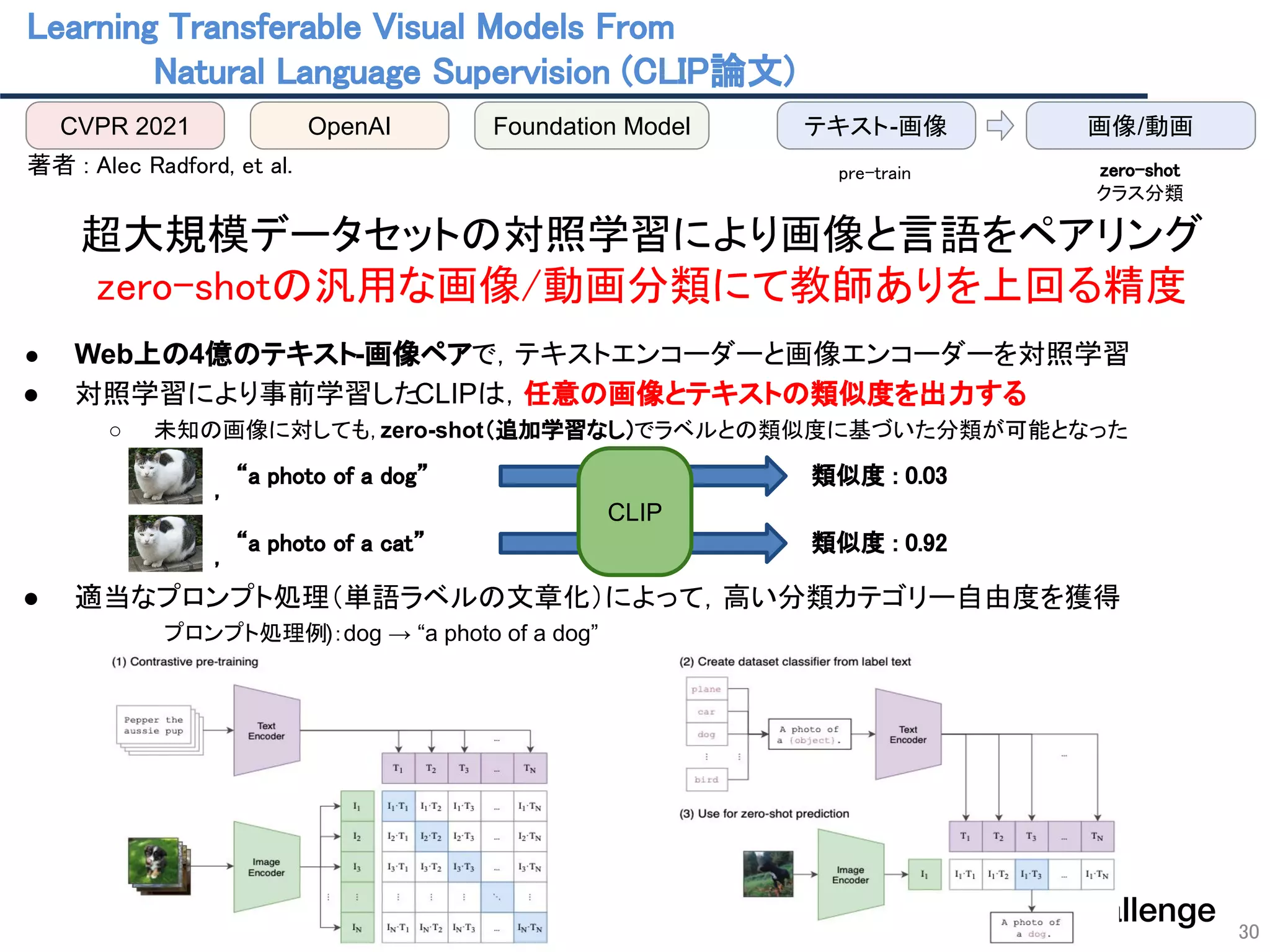
![31
言語を媒介として視覚的情報の本質理解を目指す
“Vision and Language”の基盤モデル
CLIPは言語を介して画像の意味を捉えるレンズ
● 従来の画像エンコーダーのように
「そのものに意味がない記号(ラベル)」によって画像を捉えるのではなく,
「そのものに意味がある言語表現」によって画像を捉える
ため,より解像度の高い自然な画像理解を達成し得る
従来の
画像分類で
事前学習
CLIPで
事前学習
“白と黒のぶち猫が
座ってこちらを見ている ”
Class: 3
CLIP [Radford(OpenAI)+, CVPR21]
画像分類
テキストからの
画像生成
画像自動
キャプショニング
物体検出
VQA
視覚言語
ナビゲーション
画像キャプション
妥当性評価
NeRFによる
シーン生成
他モダリティ
拡張
多種多様な画像認識タスク,
Vision and Languageタスク
への応用が可能](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-31-2048.jpg)
![33
言語を媒介として視覚的情報の本質理解を目指す
“Vision and Language”の基盤モデル
次々に更新される文章から画像生成する基盤モデル
● DALL•E [Ramesh(OpenAI)+, ICML21]
● CLIDE [Nichol(OpenAI)+, ACL22]
● VQGAN-CLIP [Crowson(EleutherAI)+, arXiv22]
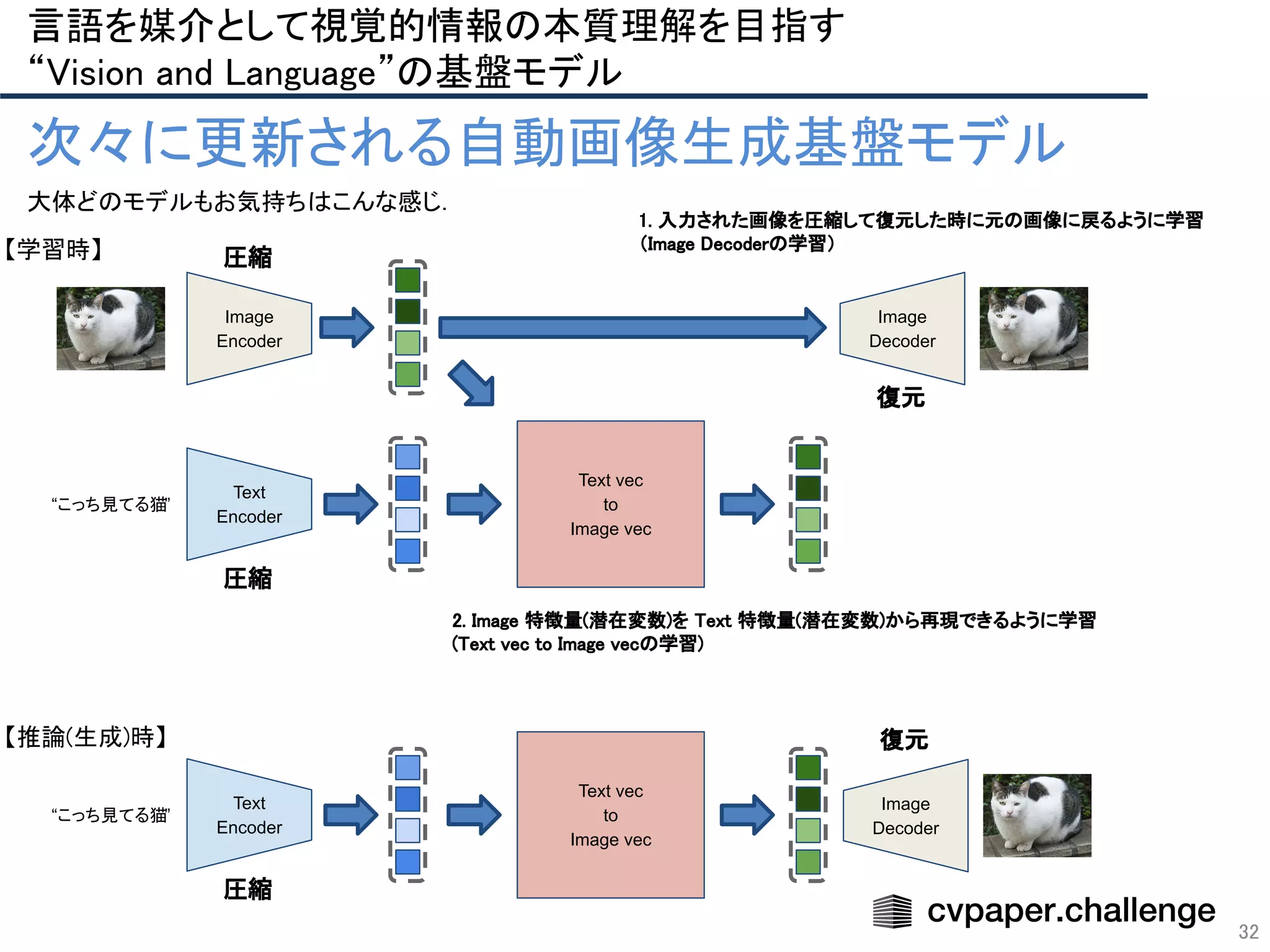
大体どのモデルも生成時のお気持ちはこんな感じ.
“こっち見てる白黒ぶち猫
”
Text
Encoder
復元
圧縮
テキストから潜在表現を獲得するブロック
(Text Encoder)
テキストの潜在表現から画像を生成するブロック
(Image Generator)
基盤モデル間で異なる主な要素は,
● Text Encoder に何を使うか
● Image Generator に何を使うか
● DALL•E 2 [Ramesh(OpenAI)+, arXiv22]
● Imagen [Saharia(Google)+, arXiv22]
● Parti [Yu(Google)+, arXiv22]
etc…](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-33-2048.jpg)
![34
言語を媒介として視覚的情報の本質理解を目指す
“Vision and Language”の基盤モデル
Text Encoder
Image Generator
DALL•E
GLIDE
VQGAN-CLIP
DALL•E 2
Imagen
Parti
BPE
VQ-VAE
+
Transformer(GPT-3 like)
VQGAN
+
CLIP
CLIP
DDPM
+
Classsifier-free Guidance
Transformer
DDPM
+
Classsifier-free Guidance
+
CLIP
T5-XXL
DDPM
+
Classsifier-free Guidance
ViT-VQGAN
+
Classsifier-free Guidance
+
Transformer
SentencePiece
model
CLIP
VQ-VAE(Vector Quantised-Variational AutoEncoder):
潜在変数を離散的なベクトルとして持たせて学習させ、複合して
画像を生成するモデル,オートエンコーダー
VQGAN:
VQ-VAEの進化系で,以下の点で異なる.
- PixelCNNの代わりにTransformerを導入し広い視野獲得
- GANの併用により,精度保ったまま
Patchの解像度を圧縮可能に
DDPM(拡散確率モデル) :
ソース画像に複数回ノイズを加え
(forward process),
最終的にノイズのみになるガウス確率過程を考え,
その逆過程を学習して遡ることで
(reverse process),
完全なノイズから画像の生成を行う.
VQ-VAE [Oord(DeepMind)+, NeurIPS17]
VQGAN [Esser(HCIP)+, CVPR21]
Denoising Diffusion Probabilistic Model
[Ho(UC Berkeley)+, NeurIPS20]
基本的に下に行くほど
新しく性能の高い
アーキテクチャ
次々に更新される文章から画像生成する基盤モデル](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-34-2048.jpg)





![41
言語を媒介として視覚的情報の本質理解を目指す
“Vision and Language”の基盤モデル
多種多様なVisionタスクを
言語を介して解く基盤モデル
Flamingo [Alayac(DeepMind)+, arXiv22]
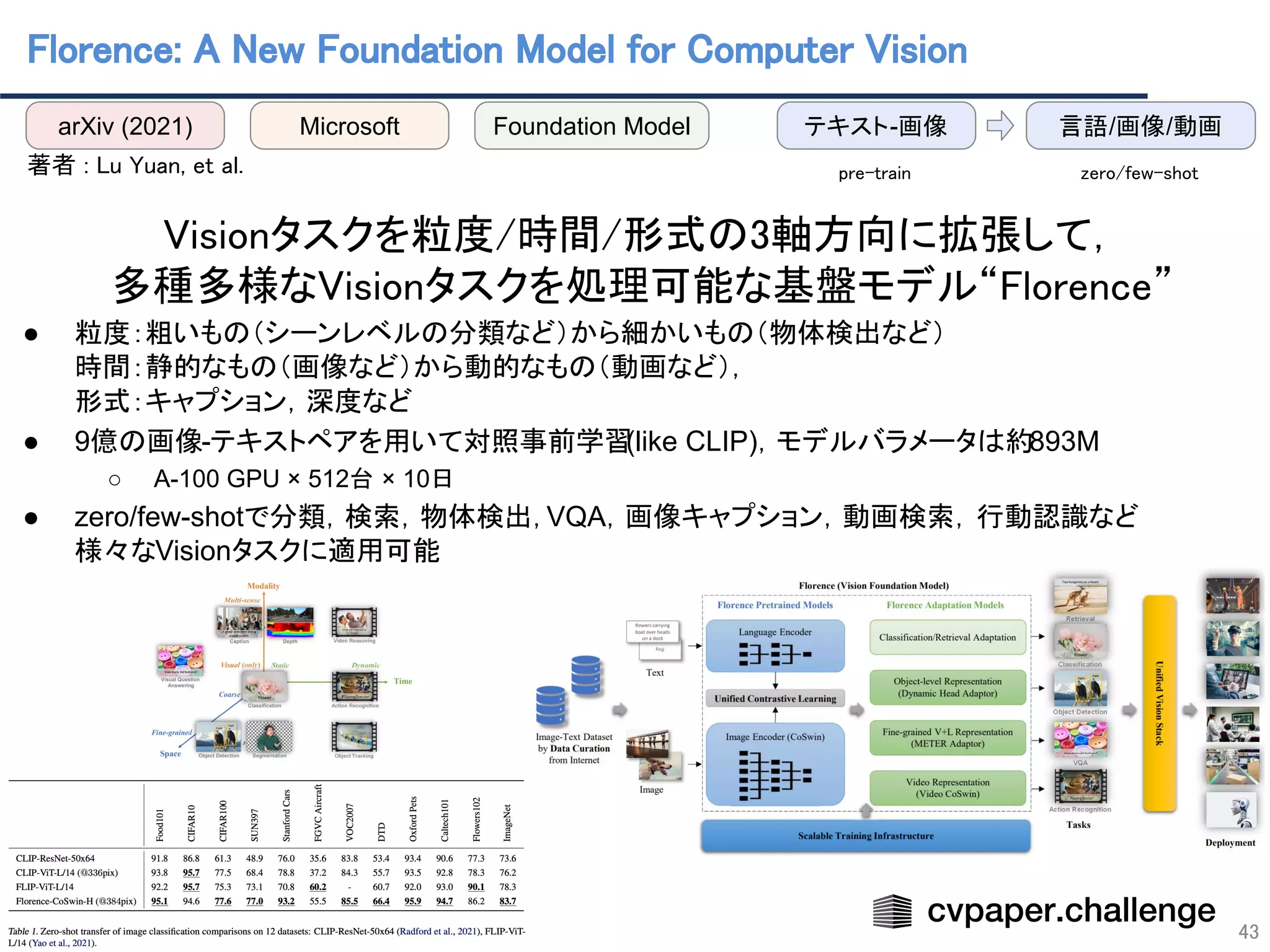
Florence [Lu Yuan(Microsoft)+, arXiv21]](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-41-2048.jpg)




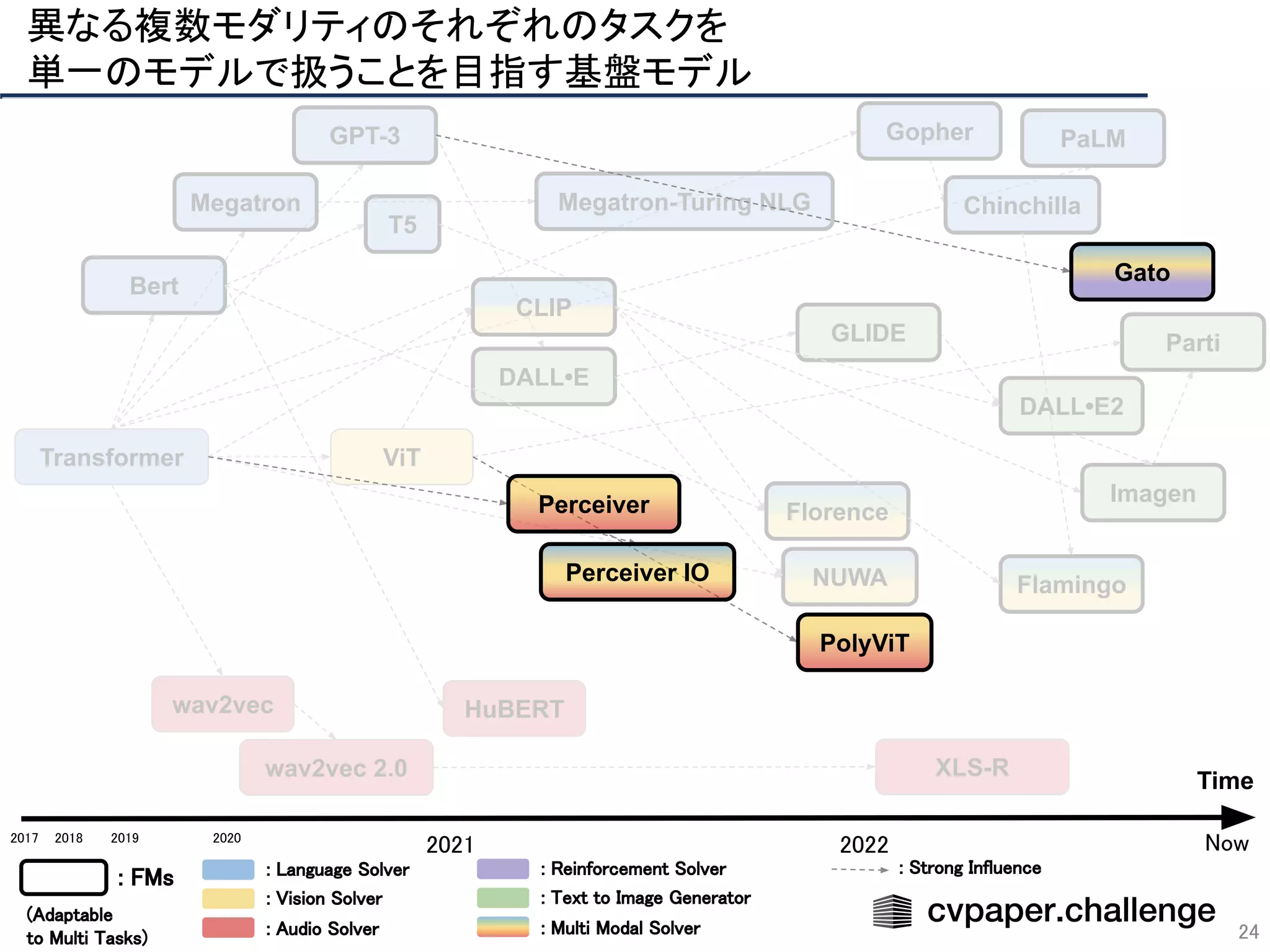
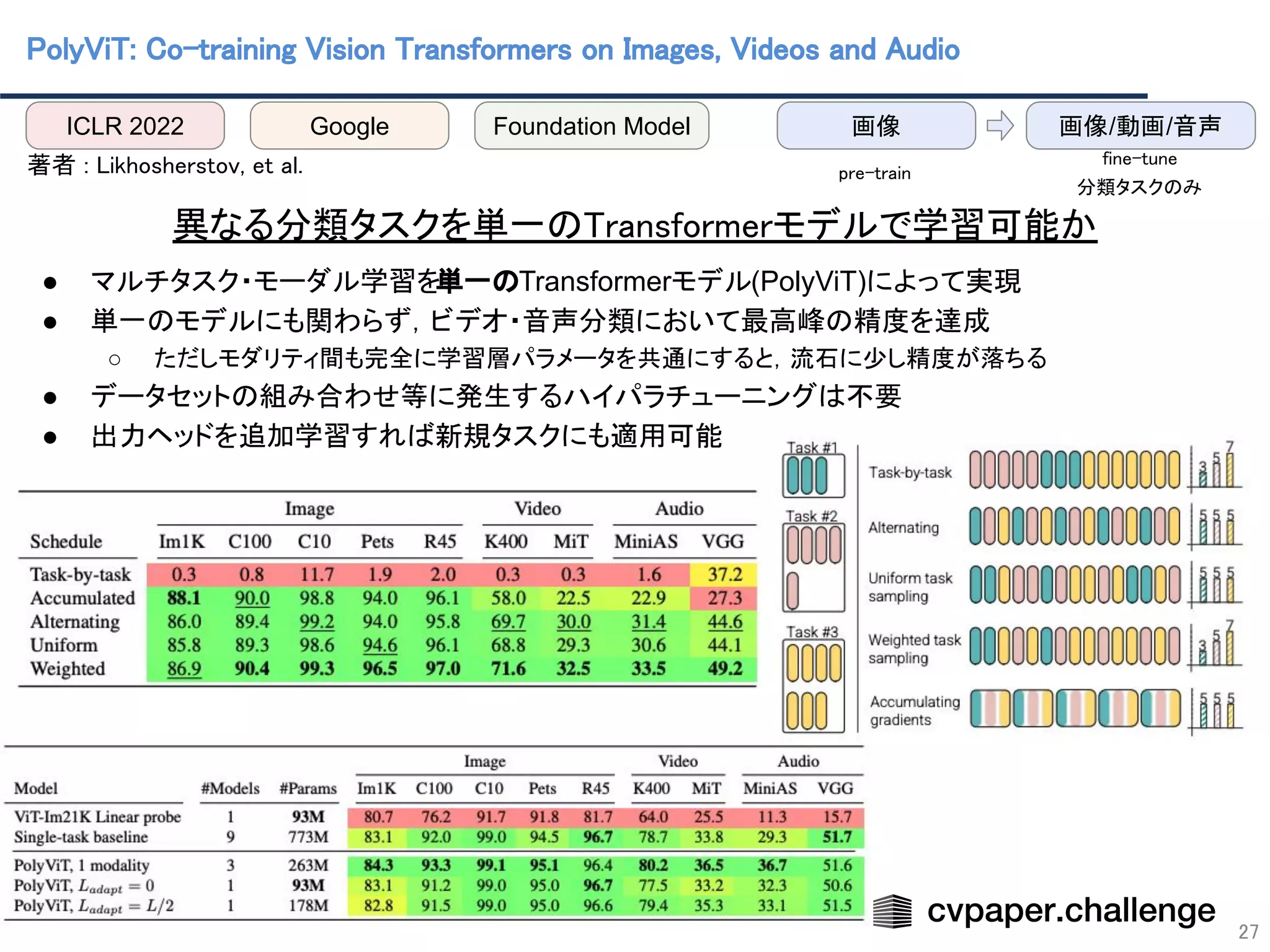
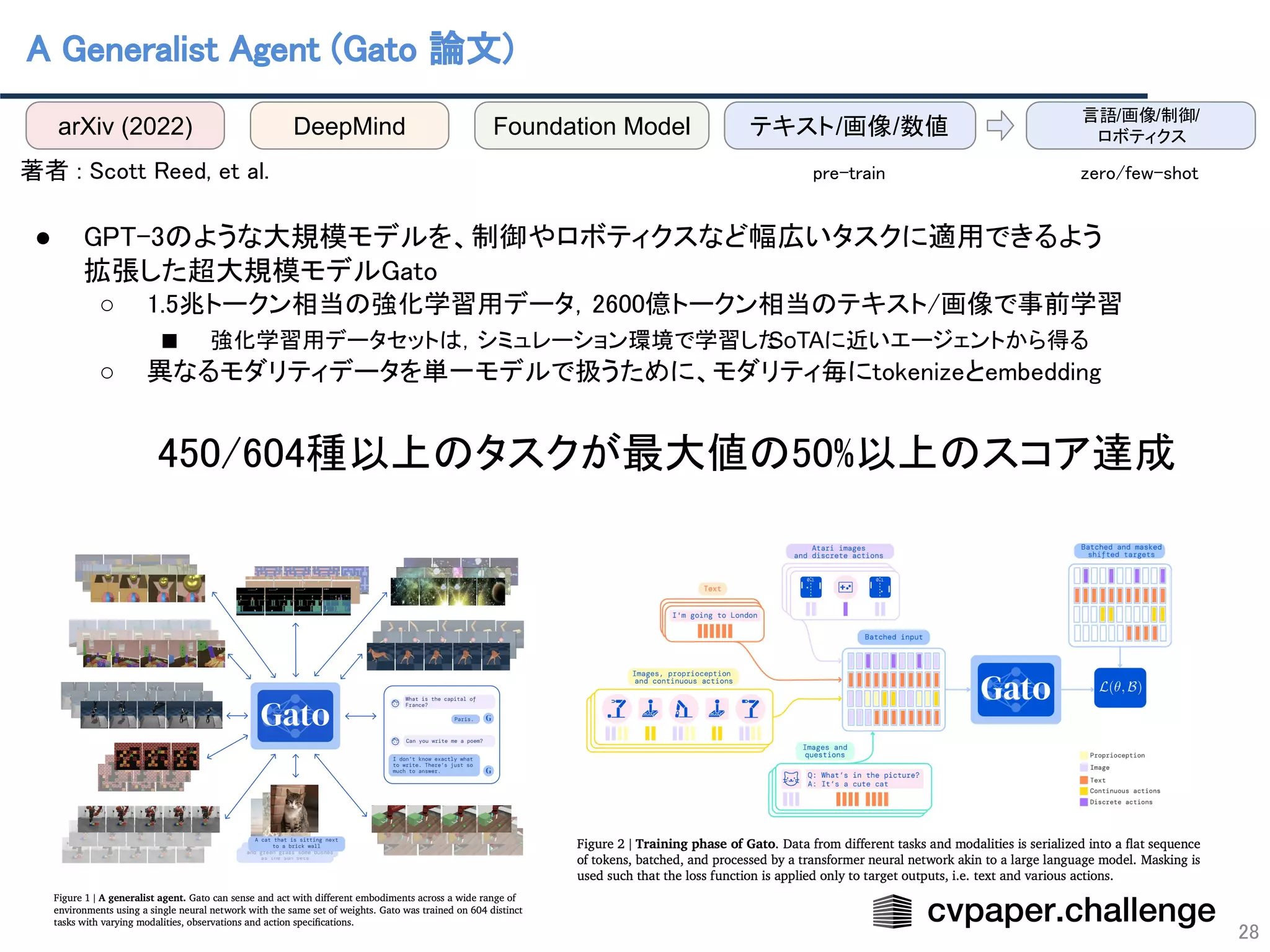
![マルチモダリティ/マルチタスク化の促進
48
複数モダリティでのデータ入力が可能
○ あらゆるデータをtokenizeしてTransformerで処理
→各分野のタスクを基盤モデルによる学習で統合
Visionに限らずあらゆるモダリティを基盤モデルによって
統一的に学習できるようになる(かも)
PolyViT [Likhosherstov(Google)+, ICLR22]
Gato [Reed(DeepMind)+, arXiv22]
入力形式:テキスト,画像,音声,動画,数値,…
分野:言語処理,画像認識,音声認識,行動認識,…](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-48-2048.jpg)
![Foundation Modelsのスケーリング則
49
スケーリング則(Scaling Law)
● モデルパラメータサイズ
● 事前学習データセットサイズ
● 計算予算
の3要素を同時にスケーリングすると性能が際限なく向上していく,
という仮説
Scaling Vision Transformers [Zhai+, CVPR22]
GPT-3 [Brown+, NeurIPS22]](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-49-2048.jpg)


![54
“思考停止”のスケーリングは資源の枯渇を招く
○ スケーリングを行う過程では
データ効率,パラメータ効率,計算効率
の追求が必須(ただ各要素をデカくするだけではダメ)
スケーリング則が基盤モデル研究に与えるリスク
An empirical analysis of compute-optimal large language model training
(chinchilla [Hoffmann(DeepMind)+, arXiv22]のプロジェクトページ )より
https://medium.com/@thepathtochange/maybe-microsoft-s-tay-ai-didn-t-have-a-meltdown-4291b910a37c
DeepMindがchinchillaの発表に伴い,
最近の言語基盤モデルが,モデルパラメータを大きくしすぎて
学習データ不足による精度劣化を引き起こしている ことを指摘](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-54-2048.jpg)

![56
JFT-300M/3B/4B (Google, 2017/2021/2022)
→約3億/30億/40億枚の画像データセット
IG-3.5B (Facebook, 2018)
→約35億枚の画像データセット
スケーリング則が基盤モデル研究に与えるリスク
巨大Tech企業による大規模データセット寡占化
○ 独自に保有するプラットフォームで
非公開な超大規模データを収集し利用
Parti [Yu(Google)+, arXiv22]
プライバシーの問題や誤用の懸念がある以上,
容易に公開はできず難しい問題](https://image.slidesharecdn.com/foundation-models-220818062424-82e259ce/75/Foundation-Models-56-2048.jpg)












![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)






















