様々な組み込み機器
4
By
Alexander
Glinz
-‐ photo
by
Alexander
Glinz
/
uploaded
by
Joadl,
CC
BY-‐SA
3.0at,https://commons.wikimedia.org/w/index.php?curid=29727889
GFDL,
https://ja.wikipedia.org/w/index.php?curid=248165
5.
組み込みにおけるNNの搭載
5
By
Alexander
Glinz
-‐ photo
by
Alexander
Glinz
/
uploaded
by
Joadl,
CC
BY-‐SA
3.0at,https://commons.wikimedia.org/w/index.php?curid=29727889
衝突回避システム
オンボード上でシステムを完結させたい
⾃自⽴立立制御ドローン
衛星リモート
センシング
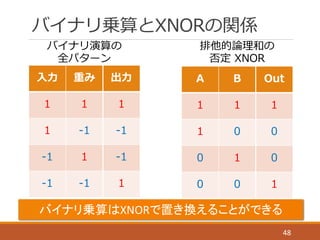
BinaryConnect
M.Courbariaux, Y.Bengio, & David, J. P. (2015).
“Binaryconnect: Training deep neural networks with binary
weights during propagations”. In Advances in Neural
Information Processing Systems (pp. 3123-‐‑‒3131).
26
Binarized
Neural Network
M. Courbariauxet al. “Binarized Neural Networks:
Training Deep Neural Networks with Weights and
Activations Constrained to +1 or -‐‑‒1”. (2016): 12
June 2017.
38
XNOR-‐‑‒Net
M. Rastegari, V. Ordonez, J. Redmon, & A. Farhadi. (2016,
October). “Xnor-‐‑‒net: Imagenet classification using binary
convolutional neural networks”. In European Conference on
Computer Vision (pp. 525-‐‑‒542).
55
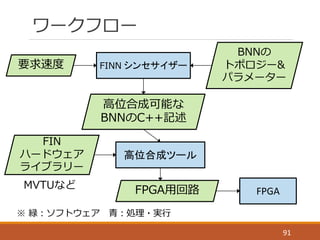
FINN
Y. Umuroglu, N. J. Fraser, G. Gambardella, M. Blott, P. Leong, M. Jahre, & K.
Vissers, (2017, February). “Finn: A framework for fast, scalable binarized
neural network inference”. In Proceedings of the 2017 ACM/SIGDA
International Symposium on Field-‐‑‒Programmable Gate Arrays (pp. 65-‐‑‒74).
ACM.
83
乗算と加算の回路路⾯面積
107
Horowitz,
“Computing’s
Energy
Problem
(and
what
we
can
do
about
it)”,
ISSCC
2014
3495
137
0
500
1000
1500
2000
2500
3000
3500
32bit
乗算 32bit
加算
乗算と加算の回路路⾯面積[μm2]
同じ面積で24個
多く実装できる※
※回路路によって多少異異なる








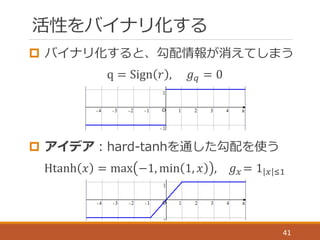
![バイナリ化の威⼒力力
9
[M.
Rastegari,
2016]
M.
Rastegari,
et
al.
“XNOR-‐Net:
ImageNet
Classification
Using
Binary
Convolutional
Neural
Networks”,
arxiv:1603.05279,
2016.
475
7.4
0
100
200
300
400
500
バイナリ化前 バイナリー化後
AlexNetの重みのデータ量量[MB]
32倍省省メモリ
58倍⾼高速化
[M. Rastegari, 2016]](https://image.slidesharecdn.com/nn-170621094551/85/slide-9-320.jpg)






![NNの軽量量化
p 組み込み⽤用途を想定したNNが抱える問題
Ø ⼤大量量のビットを使って情報を保持
Ø ⼤大量量の浮動⼩小数点同⼠士の積和演算の発⽣生
p モデルの軽量量化⼿手法
Ø 蒸留留 :⼩小さいモデルで再学習[Hinton, 2015]
Ø 冗⻑⾧長性の排除:構造化された⾏行行列列[Sindhwani, 2015]
Ø 適度度な量量⼦子化:重みのクラスタリング[Han, 2015]
Ø バイナリ化 :実数値→2値[Courbariaux, 2015]
16](https://image.slidesharecdn.com/nn-170621094551/85/slide-16-320.jpg)















![BinaryConnectの学習
32
③更更新
実数重みをバイナリ勾配で更更新
𝑾(_) = clip(𝑾 _ − 𝜂
𝜕𝑬
𝜕𝑾a
_
)
𝒃(_) = 𝒃(_) − 𝜂
𝜕𝑬
𝜕𝒃 _
クリッピング ([-‐‑1,
1]に収める)
に
よって、実数重みの発散を防ぐ
→学習⾃自体は結局実数で⾏行行う
𝑾(_)
𝑾a
(_)
𝒃(_)
𝜕𝑬
𝜕𝑾a
_
𝜕𝑬
𝜕𝒃 _
順伝播
逆伝播](https://image.slidesharecdn.com/nn-170621094551/85/slide-32-320.jpg)
![バイナリ化の正則化効果
33
p 正則化:重み⾏行行列列の表現⼒力力を落落とし、過学習を
防ぐこと
Ø 例例:DropConnect [Wan+, 2013]
Ø 重み⾏行行列列の各要素の⼤大きさの情報を捨てるバイナリ
化は、正則化の⼀一種と考えることができる
p 実際、今回の実験では正則化なしの場合よ
りかえって良良い正解率率率を得た](https://image.slidesharecdn.com/nn-170621094551/85/slide-33-320.jpg)










![学習の流流れ
3. パラメータの更更新
45
BNのパラメタを更更新
重みを更更新して[-‐‑‒1,1]に
クリップする
(BinaryConnectと同様)](https://image.slidesharecdn.com/nn-170621094551/85/slide-45-320.jpg)





![実験
p データセット
Ø MNIST, CIFAR-‐‑‒10, SVHN
p ネットワークの構成
Ø MNIST:4096ユニット隠れ層3段の全結合-‐‑‒SVM
Ø CIFAR-‐‑‒10:畳み込み3層-‐‑‒全結合層-‐‑‒SVM
Ø SVHN:上と同様(ただしユニット数が半分)
p ⽐比較対象
Ø Maxout Networks [GoodFellow+ 2013]
(通常のNN)
52](https://image.slidesharecdn.com/nn-170621094551/85/slide-52-320.jpg)










































![実験結果:誤答率率率
96
MNIST SVHN CIFAR-‐‑‒10
提案⼿手法 1.60%
[SFCmax]
5.10%
[CNVmax]
19.90%
[CNVmax]
BNN 0.96% 2.8% 11.40%
BinaryConnect 1.29 ± 0.08% 2.30% 9.90%
正規化の近似のためか、誤答率率率の上昇がみられる](https://image.slidesharecdn.com/nn-170621094551/85/slide-96-320.jpg)
![実験結果:消費電⼒力力
97
組み込み機器において現実的な消費電⼒力力でNNを使⽤用可能
7.3 8.8
3.6
0.4 0.8 2.3
21.2
22.6
11.7
8.1 7.9 10
0
10
20
30
SFC-‐max LFC-‐max CNV-‐max SFC-‐fix LFC-‐fix CNV-‐fix
P(chip) P(Wall)[W]
Pchip:Chipの消費電⼒力力[W]
Pwall:ボード全体の消費電⼒力力[W]
ボードのアイドル状態での消費電⼒力力は約7 W](https://image.slidesharecdn.com/nn-170621094551/85/slide-97-320.jpg)
![実験結果:速度度
98
速度度 :⼀一秒当たりの処理理枚数(FPS)を計測
要求速度度(max):可能な限り⾼高速に
要求速度度(fix) :9000 (9k) FPS
maxのシナリオにおいて1000万FPSを実現
12361
1561
21.9 12.2 12.2 11.6
0
5000
10000
15000
SFC-‐max LFC-‐max CNV-‐max SFC-‐fix LFC-‐fix CNV-‐fix
[k
FPS]](https://image.slidesharecdn.com/nn-170621094551/85/slide-98-320.jpg)
![実験結果:リソース
99
リソース :FPGAの回路路構成要素LUTの数
要求速度度(max):可能な限り⾼高速に
要求速度度(fix) :9000 (9k) FPS
以上⼆二つのシナリオに問題なく対応できた
91131 82988
46253
5155 5636
26274
0
50000
100000
SFC-‐max LFC-‐max CNV-‐max SFC-‐fix LFC-‐fix CNV-‐fix
[個]](https://image.slidesharecdn.com/nn-170621094551/85/slide-99-320.jpg)






![乗算と加算の回路路⾯面積
106
Horowitz,
“Computing’s
Energy
Problem
(and
what
we
can
do
about
it)”,
ISSCC
2014
3495
137
0
500
1000
1500
2000
2500
3000
3500
32bit
乗算 32bit
加算
加算と乗算の回路路⾯面積[μm2]
乗算の約1/25](https://image.slidesharecdn.com/nn-170621094551/85/slide-106-320.jpg)
![乗算と加算の回路路⾯面積
107
Horowitz,
“Computing’s
Energy
Problem
(and
what
we
can
do
about
it)”,
ISSCC
2014
3495
137
0
500
1000
1500
2000
2500
3000
3500
32bit
乗算 32bit
加算
乗算と加算の回路路⾯面積[μm2]
同じ面積で24個
多く実装できる※
※回路路によって多少異異なる](https://image.slidesharecdn.com/nn-170621094551/85/slide-107-320.jpg)
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)














