This document presents a method for 3D representation of noisy point clouds using Growing Self-Organizing Maps (GSOM) accelerated on GPUs. It addresses challenges such as feature extraction, keypoint detection, and noise management in 3D data processing, particularly from low-cost 3D sensors like the Kinect. The proposed approach demonstrates significant improvements in real-time processing capabilities, adaptability to noisy environments, and integration within complex computer vision systems.





![Introduction
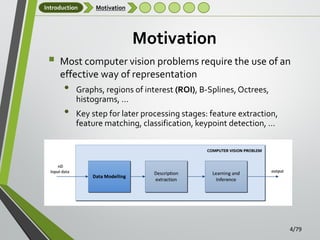
Motivation
Motivation (III)
3D models of objects and scenes have been extensively used in
computer graphics
•
•
•
Suitable structure for rendering and display
Common graphics representations include quadric surfaces [Gotardo et
al., 2004], B-spline surfaces [Gregorski et al., 2000], and subdivision
surfaces
Not general enough to handle such a variety of features: flexibility,
adaption, noise-aware, … that are present in computer vision problems
(Left) Point cloud captured from a manufactured object (builder helmet).
(Right) 3D mesh generated from the captured point cloud (post-processed)
6/79](https://image.slidesharecdn.com/thesispresentationsergioorts-escolanoprint-140123123433-phpapp02/85/A-Three-Dimensional-Representation-method-for-Noisy-Point-Clouds-based-on-Growing-Self-Organizing-Maps-accelerated-on-GPUs-6-320.jpg)




![3D Representation GSOM
Review
Review
SOMs were originally proposed for data clustering and pattern
recognition purposes [Kohonen, 1982, Vesanto and Alhoniemi, 2000,
Dittenbach et al., 2001]
As the original model had some drawbacks due to the preestablished topology of the network, growing approaches were
proposed in order to deal with this problem
Growing Neural Gas network has been successfully applied to the
representation of 2D shapes in many computer vision problems
[Stergiopoulou and Papamarkos, 2006, García-Rodríguez et al., 2010,
Baena et al., 2013]
Already exist approaches that use traditional SOMs for 3D data
representation: [Yu, 1999, Junior et al., 2004]
•
•
•
Difficulties to correctly approximate concave structures
High computational cost
Synthetic data
12/79](https://image.slidesharecdn.com/thesispresentationsergioorts-escolanoprint-140123123433-phpapp02/85/A-Three-Dimensional-Representation-method-for-Noisy-Point-Clouds-based-on-Growing-Self-Organizing-Maps-accelerated-on-GPUs-12-320.jpg)

![3D Representation GSOM
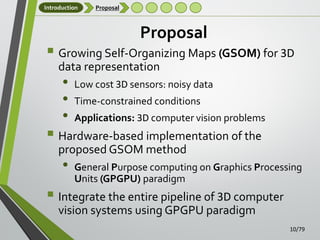
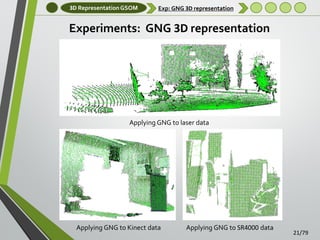
GNG network
3D Growing Neural Gas Network
Obtaining a reduced and compact representation of 3D data
•
Self Organizing Maps – Growing Neural Gas
Growing Neural Gas Algorithm (GNG) [Fritzke, 1995]
•
•
•
•
Incremental training algorithm
Links between the units in the network are established through Competitive
Hebbian Learning (CHL)
Topology Preserving Graph
Flexibility, growth, rapid adaption and good quality of representation.
GNG representation is comprised of nodes (neurons) and connections
(edges)
•
Wire-frame model
Initial, intermediate and final states of the GNG learning algorithm
14/79](https://image.slidesharecdn.com/thesispresentationsergioorts-escolanoprint-140123123433-phpapp02/85/A-Three-Dimensional-Representation-method-for-Noisy-Point-Clouds-based-on-Growing-Self-Organizing-Maps-accelerated-on-GPUs-14-320.jpg)


![3D Representation GSOM
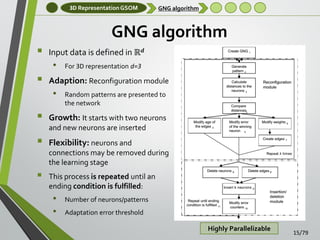
Experiments: Data
Experiments: Data Sets
Some public data sets have been used to validate
the proposed method:
•
•
•
Well known Stanford 3D scanning repository. It
contains complete models that have been previously
processed (noise free)
Dataset captured using the Kinect sensor. Released by
the Computer Vision Laboratory of the University of
Bologna [Tombari et al., 2010a]
Own dataset obtained using three previously
mentioned 3D sensors
18/79](https://image.slidesharecdn.com/thesispresentationsergioorts-escolanoprint-140123123433-phpapp02/85/A-Three-Dimensional-Representation-method-for-Noisy-Point-Clouds-based-on-Growing-Self-Organizing-Maps-accelerated-on-GPUs-18-320.jpg)








![3D Representation GSOM
Extension: 3D Reconstruction
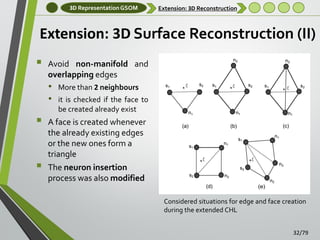
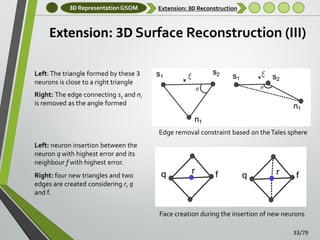
Extension: 3D Surface Reconstruction
Three-dimensional surface reconstruction is not
considered in the original GNG algorithm as it only
generates wire-frame models
[Holdstein and Fischer, 2008, Do Rego et al., 2010,
Barhak, 2002] have already considered the creation of 3D
triangular faces modifying the original GNG algorithm
•
Post-processing steps are required for avoid gaps and holes in
the final mesh
We extended the CHL developing a method able to
produce full 3D meshes during the learning stage
•
•
No post-processing steps are required
A new learning scheme was developed
31/79](https://image.slidesharecdn.com/thesispresentationsergioorts-escolanoprint-140123123433-phpapp02/85/A-Three-Dimensional-Representation-method-for-Noisy-Point-Clouds-based-on-Growing-Self-Organizing-Maps-accelerated-on-GPUs-31-320.jpg)
![3D Representation GSOM
Extension: 3D Reconstruction
Extension: 3D Surface Reconstruction (IV)
Different views of reconstructed models using an existing GNGbased method [Do Rego et al., 2010] for surface reconstruction
Post-processing steps were avoided causing gaps and holes in
the final 3D reconstructed models
34/79](https://image.slidesharecdn.com/thesispresentationsergioorts-escolanoprint-140123123433-phpapp02/85/A-Three-Dimensional-Representation-method-for-Noisy-Point-Clouds-based-on-Growing-Self-Organizing-Maps-accelerated-on-GPUs-34-320.jpg)












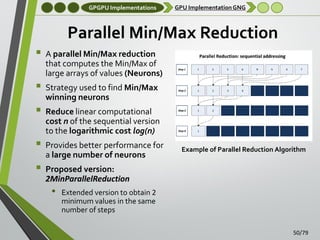
![GPGPU Implementations
Experimental Setup
Experimental setup
Main GNG Parameters:
•
•
~0-20,000 neurons and a maximum λ (entries per iteration) of
1,000-2,000
Others parameters have been fixed based on previous works
[García-Rodriguez et al., 2012]
o єw = 0.1 , єn = 0.001
o amax = 250, α = 0.5 , β = 0.0005
Hardware
• GPUs: CUDA capable devices used in experiments
•
CPU: single thread and multiple thread implementations were
tested
o
Intel Core i3 540 3.07Ghz
51/79](https://image.slidesharecdn.com/thesispresentationsergioorts-escolanoprint-140123123433-phpapp02/85/A-Three-Dimensional-Representation-method-for-Noisy-Point-Clouds-based-on-Growing-Self-Organizing-Maps-accelerated-on-GPUs-51-320.jpg)
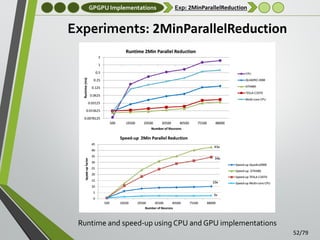
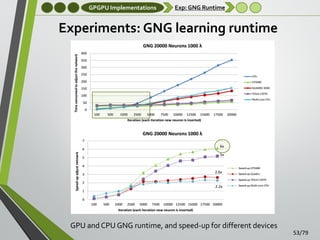
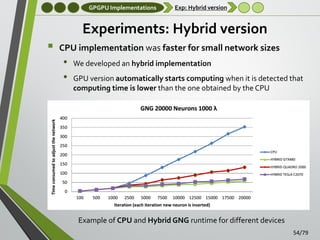
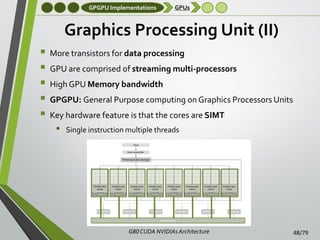
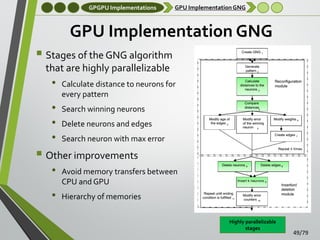
![GPGPU Implementations
GPU Feature extraction
GPU-based Tensor extraction algorithm
Time-constrained 3D feature extraction
• Most feature descriptors cannot be computed online due to their
high computational complexity
o 3D Tensor - [Mian et al., 2006b]
o Geometric Histogram - [Hetzel et al., 2001]
•
•
•
Highly parallelizable
Geometrical properties
Invariant to linear
transformations
o Spin Images - [Andrew Johnson, 1997]
An accelerated GPU-based implementation of an
existing 3D feature extraction algorithm is proposed
•
Accelerate entire pipeline of RGB-D based computer vision
systems
55/79](https://image.slidesharecdn.com/thesispresentationsergioorts-escolanoprint-140123123433-phpapp02/85/A-Three-Dimensional-Representation-method-for-Noisy-Point-Clouds-based-on-Growing-Self-Organizing-Maps-accelerated-on-GPUs-55-320.jpg)
![GPGPU Implementations
GPU Feature extraction
GPU-based Tensor extraction algorithm (II)
The surface area of the mesh intersecting each bin of the grid is the value
of the tensor element
As many threads as voxels are launched in parallel where each GPU
thread represent a voxel (bin) of the grid
Each thread computes the area of intersection between the mesh and its
corresponding voxel using Sutherland Hodgman’s polygon clipping
algorithm. [Foley et al., 1990]
56/79](https://image.slidesharecdn.com/thesispresentationsergioorts-escolanoprint-140123123433-phpapp02/85/A-Three-Dimensional-Representation-method-for-Noisy-Point-Clouds-based-on-Growing-Self-Organizing-Maps-accelerated-on-GPUs-56-320.jpg)
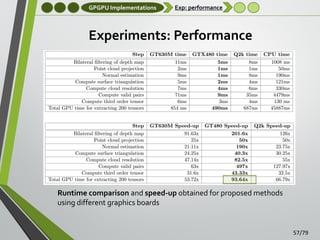


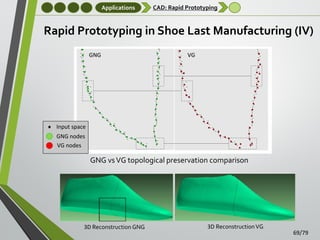
![Applications
Robotics
Robotics: 6DoF pose registration
The main goal of this application is to perform six degrees
of freedom (6DoF) pose registration in semi-structured
environments
•
We combined our accelerated GNG-based algorithm with
the method proposed in [Viejo and Cazorla, 2013]
•
Man-made indoor and outdoor environments
Planar patches extraction
It provides a good starting point for Simultaneous Location
and Mapping (SLAM)
GNG was applied directly to raw 3D data
60/79](https://image.slidesharecdn.com/thesispresentationsergioorts-escolanoprint-140123123433-phpapp02/85/A-Three-Dimensional-Representation-method-for-Noisy-Point-Clouds-based-on-Growing-Self-Organizing-Maps-accelerated-on-GPUs-60-320.jpg)








![Conclusions
Future work
Future work
Other improvements on the GPU implementation of the
GNG algorithm:
•
•
•
•
Using multi-GPU to manage several neural networks
simultaneously
Distributed computing
Testing new architectures: Intel Xeon Phi [Fang et al., 2013a]
Generating random patterns using GPU
More applications of the accelerated GNG algorithm will be
studied in the future
•
•
Clustering multi-dimensional data: Big Data
Medical Image Reconstruction
Extension of the real-time implementation of the 3D tensor
•
•
Visual features extracted from RGB information
Improve implicit keypoint detector used by the 3D tensor
73/79](https://image.slidesharecdn.com/thesispresentationsergioorts-escolanoprint-140123123433-phpapp02/85/A-Three-Dimensional-Representation-method-for-Noisy-Point-Clouds-based-on-Growing-Self-Organizing-Maps-accelerated-on-GPUs-73-320.jpg)




























































































