Download as PDF, PPTX





![And many more..
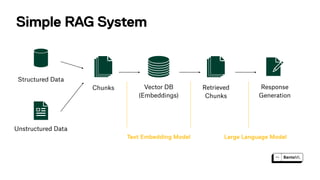
Context-Aware chunking
And global concept aware
chunking Metadata
{ datetime: ‘2024-04-11’,
product: “..”, user_id: “..”,
sentiment: “positive”,
summary: “..”,
topics: [..], }
Text Chunk
“I recently purchased the
product and I'm extremely
satis
fi
ed with it! …”
Metadata extraction for Improved retrieval accuracy
And additional context for response synthesis
Reranker Model
fi
ne-tuned
with your dataset generally
performs ~10-30% better](https://image.slidesharecdn.com/unstructureddatameetup-63chaoyuyangbentoml-240606180246-a166705f/85/Infrastructure-Challenges-in-Scaling-RAG-with-Custom-AI-models-8-320.jpg)



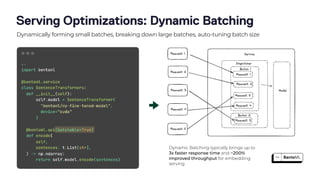


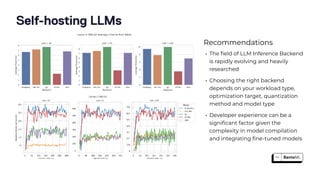



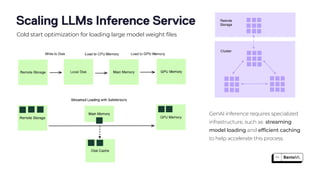
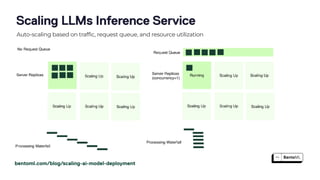

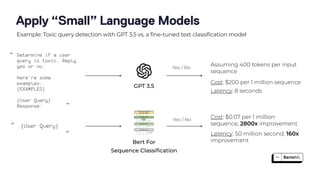

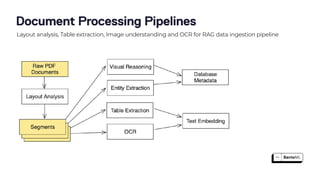
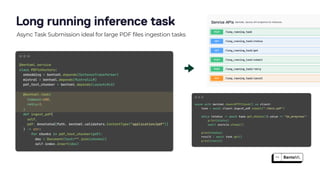
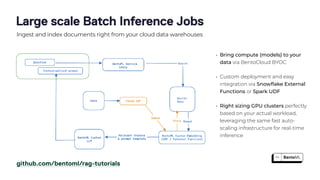

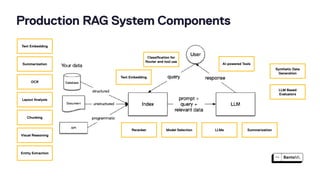


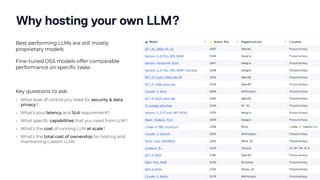
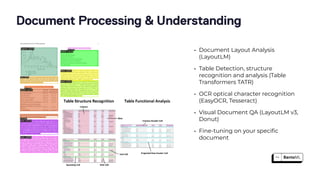
The document discusses the challenges and best practices in scaling retrieval-augmented generation (RAG) systems using custom AI models. It covers topics such as deploying inference APIs, optimizing model performance, and the complexities of managing structured and unstructured data. It emphasizes the importance of fine-tuning models for specific tasks and the need for specialized infrastructure to efficiently handle inference workloads.







![[DSC Europe 23] Spela Poklukar & Tea Brasanac - Retrieval Augmented Generation](https://cdn.slidesharecdn.com/ss_thumbnails/spelapoklukarteabrasanacprez-231129000106-d6582d1b-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DSC Europe 22] Overview of the Databricks Platform - Petar Zecevic](https://cdn.slidesharecdn.com/ss_thumbnails/petarzecevic-databricksoverview-221130080703-c60d93de-thumbnail.jpg?width=640&height=640&fit=bounds)
























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










