Downloaded 20 times
![Interpretabilitat
Interpretability / Explainable AI (XAI)
Xavier Giro-i-Nieto
@DocXavi
xavier.giro@upc.edu
Associate Professor
Universitat Politècnica de Catalunya
[GCED] [Lectures repo]](https://image.slidesharecdn.com/11interpretabilityaa22020-210203141957/85/Intepretability-Explainable-AI-for-Deep-Neural-Networks-1-320.jpg)
![Interpretabilitat
Interpretability / Explainable AI (XAI)
Xavier Giro-i-Nieto
@DocXavi
xavier.giro@upc.edu
Associate Professor
Universitat Politècnica de Catalunya
[GCED] [Lectures repo]](https://image.slidesharecdn.com/11interpretabilityaa22020-210203141957/75/Intepretability-Explainable-AI-for-Deep-Neural-Networks-1-2048.jpg)

![3
Videolectures
Amaia Salvador
[UPC DLCV 2016]
Eva Mohedano
[UPC DLCV 2018]
Laura Leal-Taixé
[UPC DLCV 2019]](https://image.slidesharecdn.com/11interpretabilityaa22020-210203141957/85/Intepretability-Explainable-AI-for-Deep-Neural-Networks-3-320.jpg)


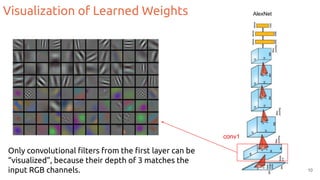




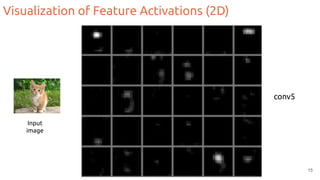

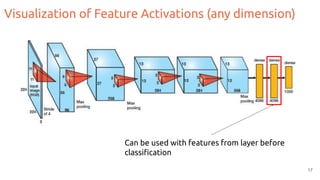
![Visualization of Feature Activations (any dimension)
18
#t-sne Maaten, Laurens van der, and Geoffrey Hinton. "Visualizing data using t-SNE." Journal of machine learning research
9, no. Nov (2008): 2579-2605. [Python scikit-learn]
t-SNE:
Embeds high dimensional data
points (i.e. feature maps) so
that pairwise distances are
preserved in a local 2D
neighborhoods.
Example: 10 classes from MNIST dataset](https://image.slidesharecdn.com/11interpretabilityaa22020-210203141957/85/Intepretability-Explainable-AI-for-Deep-Neural-Networks-18-320.jpg)
![19
CNN codes:
t-SNE on fc7 features from
AlexNet.
Source: Andrey Karpath (Stanford University)
Visualization of Feature Activations (any dimension)
#t-sne Maaten, Laurens van der, and Geoffrey Hinton. "Visualizing data using t-SNE." Journal of machine learning research
9, no. Nov (2008): 2579-2605. [Python scikit-learn]](https://image.slidesharecdn.com/11interpretabilityaa22020-210203141957/85/Intepretability-Explainable-AI-for-Deep-Neural-Networks-19-320.jpg)









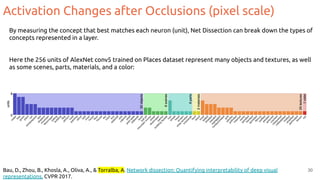











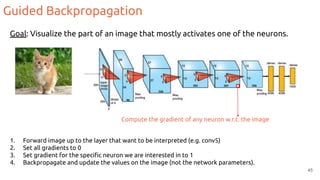
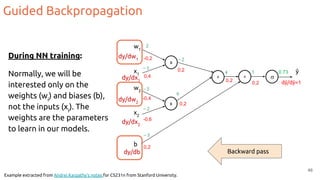
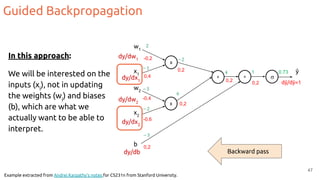


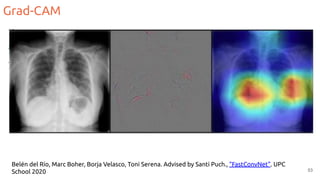
![Grad-CAM
50
#Grad-CAM Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra.
Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization. ICCV 2017 [video]
Same idea as Class Activation Maps (CAMs), but:
● No modifications required to the network
● Weight feature map by the gradient of the class wrt each channel](https://image.slidesharecdn.com/11interpretabilityaa22020-210203141957/85/Intepretability-Explainable-AI-for-Deep-Neural-Networks-50-320.jpg)
![Grad-CAM
51
#Grad-CAM Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra.
Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization. ICCV 2017 [video]](https://image.slidesharecdn.com/11interpretabilityaa22020-210203141957/85/Intepretability-Explainable-AI-for-Deep-Neural-Networks-51-320.jpg)
![52
#Grad-CAM Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra.
Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization. ICCV 2017 [video]](https://image.slidesharecdn.com/11interpretabilityaa22020-210203141957/85/Intepretability-Explainable-AI-for-Deep-Neural-Networks-52-320.jpg)


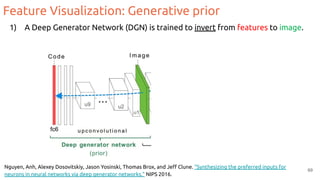
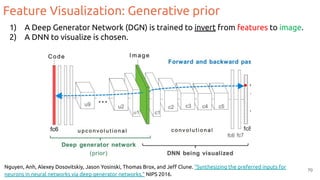
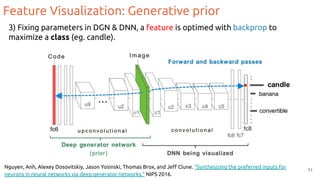
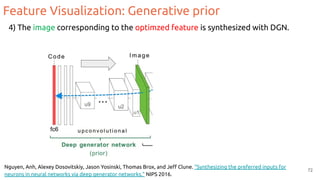
![Feature Visualization
Goal: Generate an image that maximizes the activation of a neuron.
1. Forward random image
2. Set the gradient of the neuron to be [0,0,0…,1,...,0,0]
3. Backprop to get gradient on the image
4. Update image (small step in the gradient direction)
5. Repeat
56
K. Simonyan, A. Vedaldi, A. Ziseramnn, Deep Inside Convolutional Networks: Visualising Image Classification Models and
Saliency Maps, ICLR 2014](https://image.slidesharecdn.com/11interpretabilityaa22020-210203141957/85/Intepretability-Explainable-AI-for-Deep-Neural-Networks-56-320.jpg)

![Feature Visualization
58
Chris Olah, Alexander Mordvintsev, Ludwig Schubert, “Feature Visualization”. Distill.pub (2017) [Google Colab]](https://image.slidesharecdn.com/11interpretabilityaa22020-210203141957/85/Intepretability-Explainable-AI-for-Deep-Neural-Networks-58-320.jpg)
![Feature Visualization
59
Chris Olah, Alexander Mordvintsev, Ludwig Schubert, “Feature Visualization”. Distill.pub (2017) [Google Colab]](https://image.slidesharecdn.com/11interpretabilityaa22020-210203141957/85/Intepretability-Explainable-AI-for-Deep-Neural-Networks-59-320.jpg)





![Bonus: Adversarial Attacks (eg. patch on sticker)
Brown, Tom B., Dandelion Mané, Aurko Roy, Martín Abadi, and Justin Gilmer. "Adversarial patch." arXiv preprint
arXiv:1712.09665 (2017). [Google Colab]
65
Goal: Generate a patch P that will make a Neural Network always predict class the
same class for any image containing the patch.](https://image.slidesharecdn.com/11interpretabilityaa22020-210203141957/85/Intepretability-Explainable-AI-for-Deep-Neural-Networks-65-320.jpg)




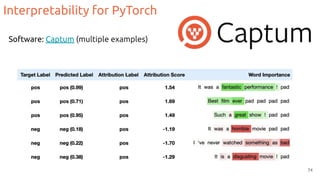
![Interpretability for PyTorch
75
Software: Lucent, based on Kornia [tweet]](https://image.slidesharecdn.com/11interpretabilityaa22020-210203141957/85/Intepretability-Explainable-AI-for-Deep-Neural-Networks-75-320.jpg)

![Additional material
77
Adebayo, Julius, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, and Been Kim. "Sanity checks for saliency maps."
NeurIPS 2018
#HINT Selvaraju, Ramprasaath R., Stefan Lee, Yilin Shen, Hongxia Jin, Shalini Ghosh, Larry Heck, Dhruv Batra, and Devi Parikh. "Taking
a hint: Leveraging explanations to make vision and language models more grounded." ICCV 2019. [blog].
#Ablation-CAM Ramaswamy, Harish Guruprasad. "Ablation-CAM: Visual Explanations for Deep Convolutional Network via
Gradient-free Localization." WACV 2020.
Chris Olah et al, “An Overview of Early Vision in InceptionV1”. Distill .pub, 2020.
Rebuffi, S. A., Fong, R., Ji, X., & Vedaldi, A. There and Back Again: Revisiting Backpropagation Saliency Methods. CVPR 2020. [tweet]
Bau, D., Zhu, J. Y., Strobelt, H., Lapedriza, A., Zhou, B., & Torralba, A. Understanding the role of individual units in a deep neural
network. PNAS 2020. [tweet]
Oana-Maria Camburu, “Explaining Deep Neural Networks”. Oxford VGG 2020.](https://image.slidesharecdn.com/11interpretabilityaa22020-210203141957/85/Intepretability-Explainable-AI-for-Deep-Neural-Networks-77-320.jpg)

This document discusses interpretability and explainable AI (XAI) in neural networks. It begins by providing motivation for why explanations of neural network predictions are often required. It then provides an overview of different interpretability techniques, including visualizing learned weights and feature maps, attribution methods like class activation maps and guided backpropagation, and feature visualization. Specific examples and applications of each technique are described. The document serves as a guide to interpretability and explainability in deep learning models.






















































































