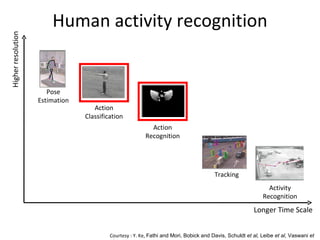
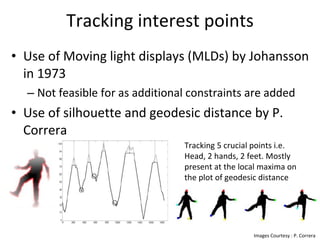
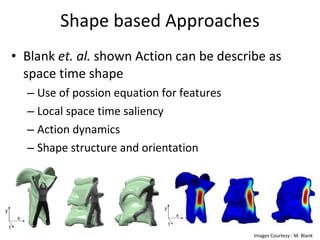
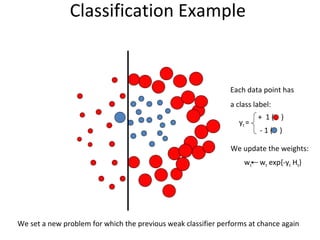
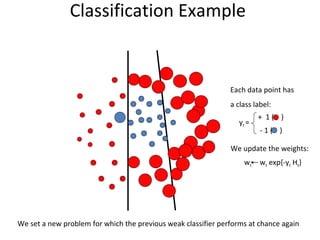
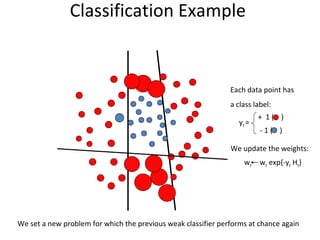
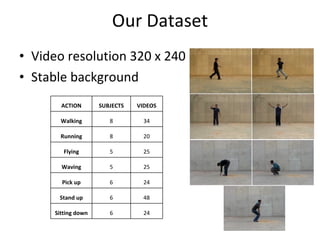
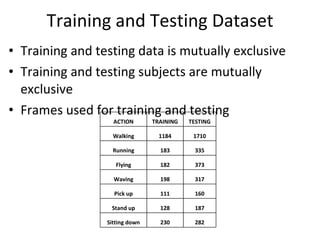
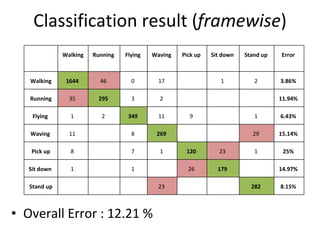
The document discusses human action recognition using spatio-temporal features. It proposes using optical flow and shape-based features to form motion descriptors, which are then classified using Adaboost. Targets are localized using background subtraction. Optical flows within localized regions are organized into a histogram to describe motion. Differential shape information is also captured. The descriptors are used to train a strong classifier with Adaboost that can recognize actions in testing videos.












![Noise removal Presence of noisy optical flows Noise removal by averaging Optical flows with magnitude > C * O mean are ignored, where C – constant [1.5 - 2], O mean - mean of optical flow within ROI Noisy Optical flows After noise removal](https://image.slidesharecdn.com/actionrecognition-12661691655651-phpapp01/85/Action-Recognition-Thesis-presentation-15-320.jpg)

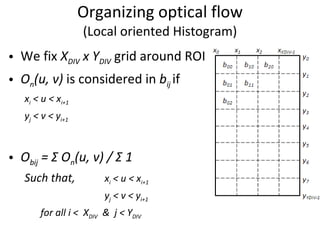
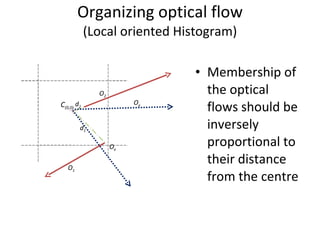
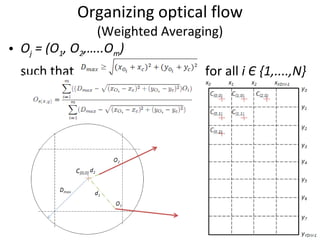

![Formation of motion descriptor Optical flow is represented in xy component form Effective optical flow from each box is written in a single row as [O ex00 , O ey00 , O ex10 , O ey10 ,….. ] vector Vectors for each action are stored for every training subject Adaboost is used to learn the patterns](https://image.slidesharecdn.com/actionrecognition-12661691655651-phpapp01/85/Action-Recognition-Thesis-presentation-21-320.jpg)

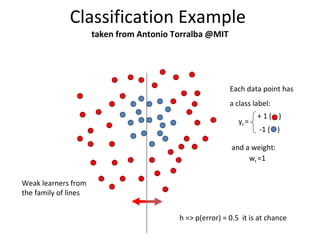
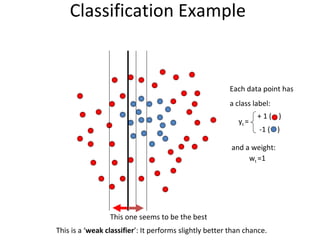

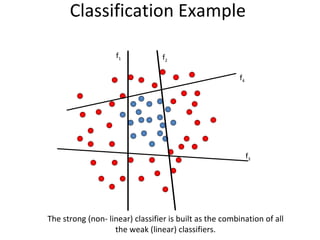

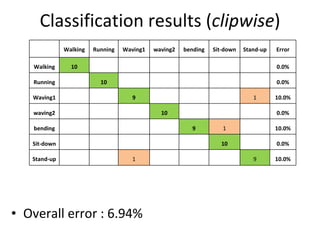

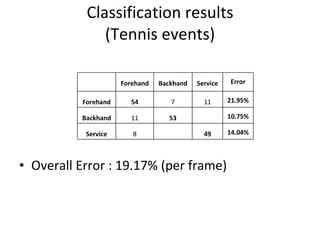
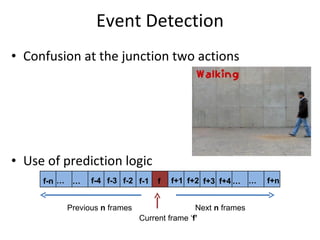


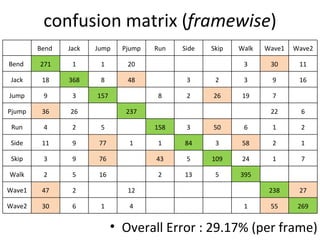



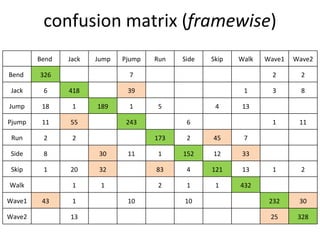
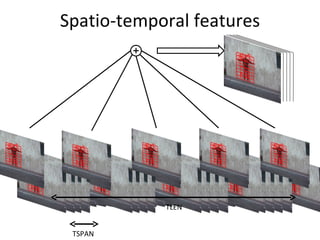
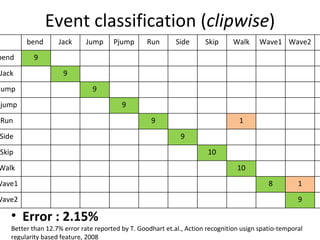
![Spatio-temporal descriptor Volume Descriptor in row form [Frame1 | Frame2 | Frame3 | Frame4 | Frame5 | ……] Motion and Differential shape information for the volume Error : 8.472% (per frame)](https://image.slidesharecdn.com/actionrecognition-12661691655651-phpapp01/85/Action-Recognition-Thesis-presentation-47-320.jpg)









































![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)




















