Downloaded 12 times







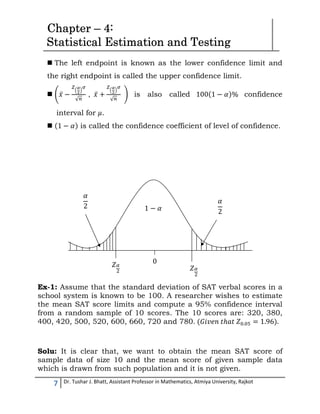




















This document is a comprehensive guide for B.Com/M.Com students on statistical estimation and testing, authored by Dr. Tushar J. Bhatt. It covers key concepts such as statistical inference, estimation types, confidence intervals, hypothesis testing, and various statistical tests including z-tests. The document includes practical examples and formulas to aid understanding and application of these statistical methods.























































































