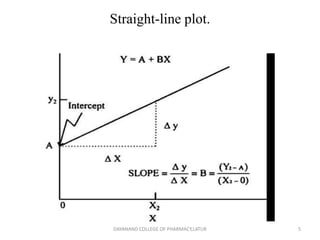
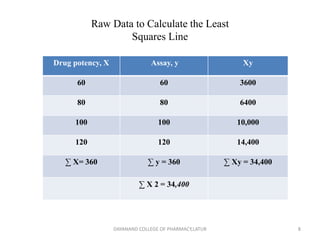
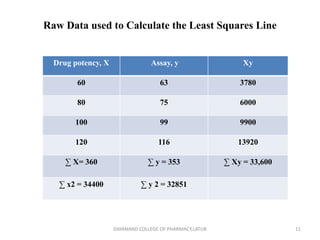
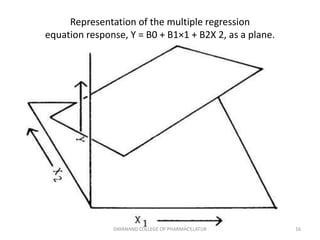
Regression analysis is a statistical technique for investigating relationships between variables. Simple linear regression defines a relationship between two variables (X and Y) using a best-fit straight line. Multiple regression extends this to model relationships between a dependent variable Y and multiple independent variables (X1, X2, etc.). Regression coefficients are estimated to define the regression equation, and R-squared and the standard error can be used to assess the goodness of fit of the regression model to the data. Regression analysis has applications in pharmaceutical experimentation such as analyzing standard curves for drug analysis.












































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










