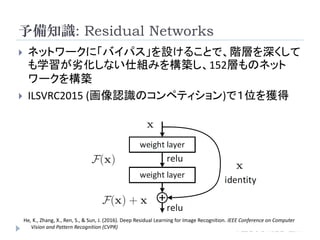
予備知識:Faster R-CNN
9
R-CNNおよびFastR-CNNではSelective Searchを用いて物体候
補領域を事前に求めておく必要。
Fast R-CNNのSelective Search部分をfeature map上で行うこと
で、余計な処理を省き、高精度化/高速化(1枚当たり約
200msec)。
→ Region Proposal Network (RPN)
この上(特徴マップ)で物体候補領域検出を行う
Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal
Networks. Advances in Neural Information Processing Systems (NIPS).
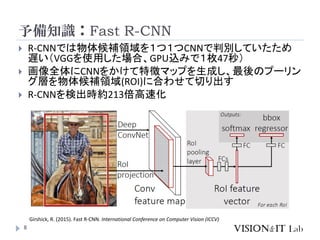
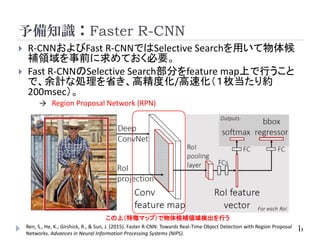
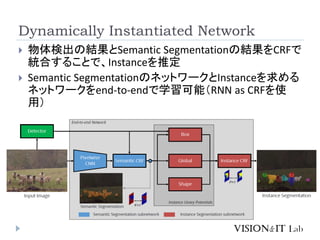
Instance Level上位の手法 (2017/03/11現在)
1.A. Arnab, & P. Torr, “Pixelwise Instance Segmentation
with a Dynamically Instantiated Network”, IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), 2017.
Method AP AP 50% AP 100m AP 50m
Pixelwise Instance
Segmentation with a
Dynamically
Instantiated Network
*1
20.0 (1st) 38.8 (1st) 32.6 (1st) 37.6 (1st)
紹介する論文
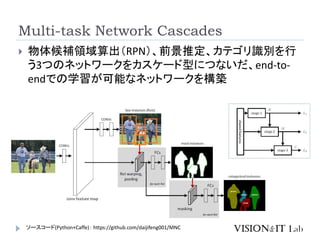
Object Detectionを物体候補領域推定(RegionProposal)
を用いて行い、その領域情報を利用
Hariharan, B., Arbeláez, P., Girshick, R., & Malik, J. (2014).
Simultaneous Detection and Segmentation. European
Conference on Computer Vision (ECCV)
紹介する論文
Object Detectionを用いてBoundingBoxを算出し、その中および周辺
画素の前景/背景を算出
Yang, Y., Hallman, S., Ramanan, D., & Fowlkes, C. C. (2012). Layered Object
Models for Image Segmentation. IEEE Transaction on Pattern Analysis and
Machine Intelligence (PAMI)
Dai, J., He, K., & Sun, J. (2016). Instance-aware Semantic Segmentation via
Multi-task Network Cascades. IEEE Conference on Computer Vision and
Pattern Recognition (CVPR)
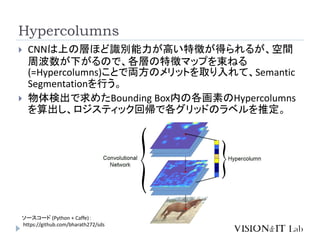
Hariharan, B., Arbel, P., & Girshick, R. (2015). Hypercolumns for Object
Segmentation and Fine-grained Localization. IEEE Conference on Computer
Vision and Pattern Recognition (CVPR)
Li, K., Hariharan, B., Malik, J., Berkeley, U. C., & Berkeley, U. C. (2016).
Iterative Instance Segmentation. IEEE Conference on Computer Vision and
Pattern Recognition (CVPR)
Li, K., & Malik, J. (2016). Amodal Instance Segmentation. IEEE Europian
Conference on Computer Vision (ECCV)
He, K., Gkioxari, G., Dollar, P., & Girshick, R. (2017). Mask R-CNN.
arXiv:1703.06870
31.
Layered object models
物体検出(Deformable Part Model)の結果を基に、生成
確率モデルを用いて、各Super Pixelの前後関係(層構造)
を推定
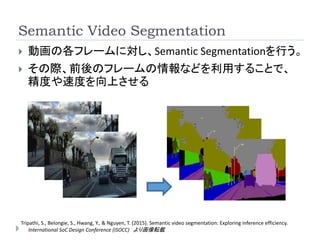
Semantic Video Segmentation
動画の各フレームに対し、Semantic Segmentationを行う。
その際、前後のフレームの情報などを利用することで、
精度や速度を向上させる
Tripathi, S., Belongie, S., Hwang, Y., & Nguyen, T. (2015). Semantic video segmentation: Exploring inference efficiency.
International SoC Design Conference (ISOCC) より画像転載
39.
動画用データセット
The Cambridge-drivingLabeled Video Database(CamVid)
Dataset
概要
32クラスにラベル付けされた車載カメラからの動画データセット。
動画は30Hz、ラベルは1Hz
URL
http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/
ライセンス
特に記述無
例
40.
Playing for Data
Richer, S. R., Vineet, V., Roth, S., & Koltun, V. (2016). Playing for Data: Ground Truth
from Computer Games. European Conference on Computer Vision (ECCV)
市販のゲームに対し、グラフィックハードウェアにアクセスすることで、高速にセマ
ンティックラベルを取得
CamVidの1/3のデータ+ゲームから取得したデータを使用して学習させることで、
CamVid全てのデータを使って学習した場合よりも大幅に性能向上
URL (コードあり)
https://download.visinf.tu-darmstadt.de/data/from_games/
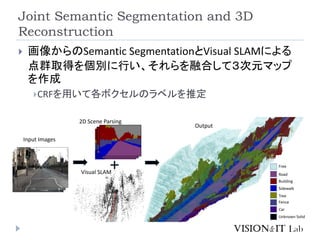
紹介する論文
動画から推定した対象の三次元構造に基づいてラベル
付け
G. J.Brostow, J. Shotton, J. Fauqueur, and R. Cipolla.
Segmentation and recognition using structure from motion
point clouds. In ECCV, 2008
43.
Segmentation using SfM
Structure from Motionにより動画から三次元点群を計算
各点の高さ、カメラの軌跡との最短距離、法線ベクトル、
再投影誤差等を特徴量として、Randomized Forestにより
ラベリング
44.
紹介する論文
フレームごとのラベル付け結果と三次元推定結果を融合
Kundu, A.,Li, Y., Daellert, F., Li, F., & Rehg, J. M. (2014). Joint
Semantic Segmentation and 3D Reconstruction from Monocular
Video. European Conference on Computer Vision (ECCV)
紹介する論文
フレームごとのラベル付け結果を統合
Scharwaechter, T.,Enzweiler, M., Franke, U., & Roth, S. (2014).
Stixmantics: A Medium-Level Model for Real-Time Semantic
Scene Understanding. European Conference on Computer Vision
(ECCV)
Sevilla-Lara, L., Sun, D., Jampani, V., & Black, M. J. (2016).
Optical Flow with Semantic Segmentation and Localized Layers.
CVPR
紹介する論文
複数フレーム全体を同時にラベル付け
Liu, B.,& He, X. (2015). Multiclass semantic video segmentation
with object-level active inference. IEEE Conference on Computer
Vision and Pattern Recognition (CVPR)
Kundu, A., Tech, G., Vineet, V., Labs, I., Koltun, V., & Labs, I.
(2016). Feature Space Optimization for Semantic Video
Segmentation. 2016 IEEE Conference on Computer Vision and
Pattern Recognition (CVPR)
50.
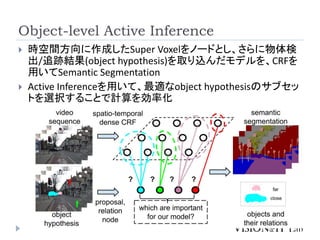
Object-level Active Inference
時空間方向に作成したSuper Voxelをノードとし、さらに物体検
出/追跡結果(object hypothesis)を取り込んだモデルを、CRFを
用いてSemantic Segmentation
Active Inferenceを用いて、最適なobject hypothesisのサブセッ
トを選択することで計算を効率化






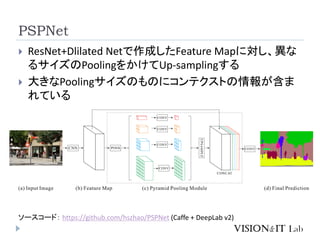
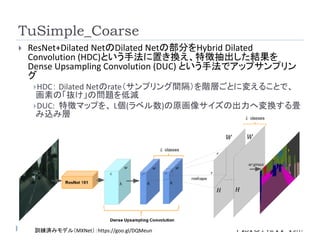
![予備知識: Dilated Network
CNNではPooling層において、出力のサイズが入力サイ
ズよりも小さくなってしまい、予測の解像度が低下する
Pooling層の代わりに、マルチスケールの「Dilated
Convolution」を使用することで、解像度を保ったままコン
テクストの情報を学習する。
Yu, F., & Koltun, V. (2016). Multi-Scale Context Aggregation by Dilated Convolutions. International Conference on Machine
Learning (ICML)
画像は[http://sergeiturukin.com/2017/03/02/wavenet.html]より転載](https://image.slidesharecdn.com/semanticsegmentation2-170418022111/85/Semantic-segmentation2-6-320.jpg)





















































![[CV勉強会]Active Object Localization with Deep Reinfocement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20160204objectdetectionrl-160206032348-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Dl輪読会]dl hacks輪読](https://cdn.slidesharecdn.com/ss_thumbnails/dldlhacks-161125051944-thumbnail.jpg?width=640&height=640&fit=bounds)




![[unofficial] Pyramid Scene Parsing Network (CVPR 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/pyramidsceneparsingnetwork-170815035025-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DLHacks 実装]Network Dissection: Quantifying Interpretability of Deep Visual R...](https://cdn.slidesharecdn.com/ss_thumbnails/171030netdissectimple1-171030120240-thumbnail.jpg?width=640&height=640&fit=bounds)








































