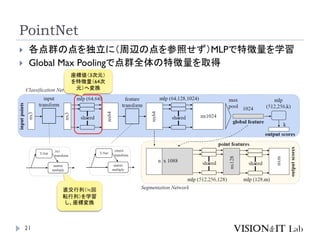
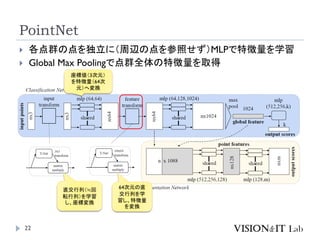
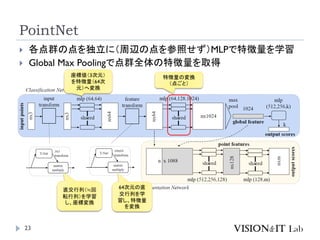
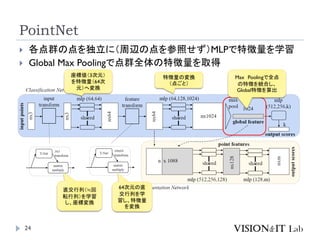
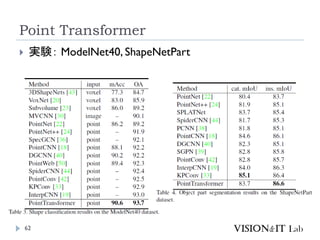
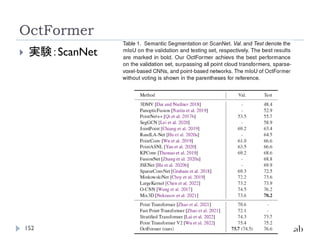
PointNetおさらい:出典
18
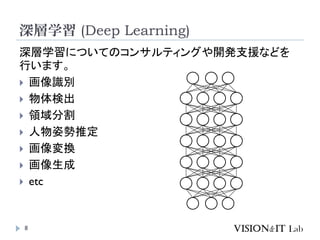
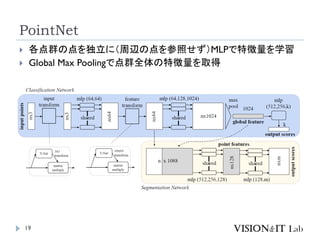
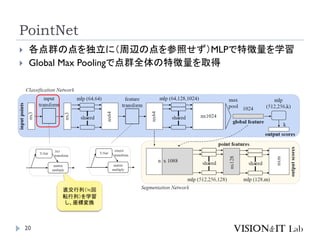
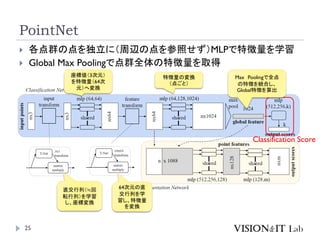
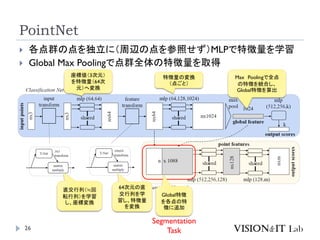
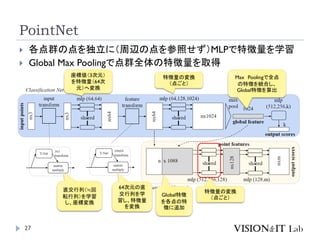
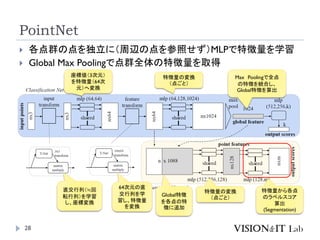
PointNet
Qi,C. R., Su, H., Mo, K., & Guibas, L. J. (2017). PointNet : Deep
Learning on Point Sets for 3D Classification and Segmentation Big
Data + Deep Representation Learning. IEEE Conference on Computer
Vision and Pattern Recognition (CVPR).
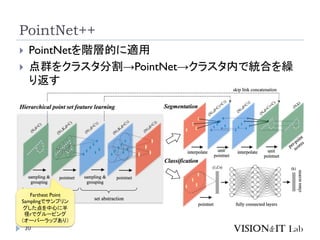
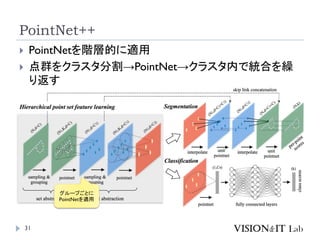
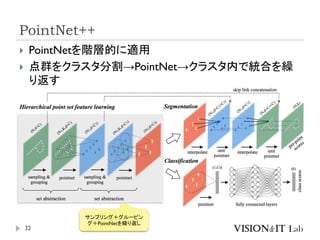
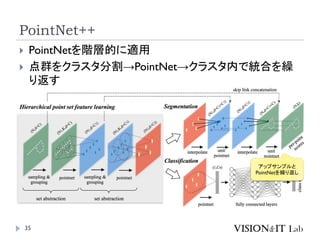
PointNet++
Qi, C. R.,Yi, L., Su, H., & Guibas, L. J. (2017). PointNet++: Deep
Hierarchical Feature Learning on Point Sets in a Metric Space.
Conference on Neural Information Processing Systems (NeurIPS)
PointNeXt
Qian, G., Li,Y., Peng, H., Mai, J., Hammoud, H.A.A. K., Elhoseiny, M., &
Ghanem, B. (2022). PointNeXt: Revisiting PointNet++ with Improved
Training and Scaling Strategies. Conference on Neural Information
Processing Systems (NeurIPS).
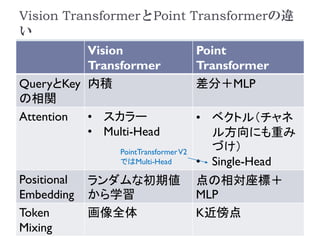
Transformerおさらい: 出典
38
Transformer
Vaswani,A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L.,
Gomez,A. N., Kaiser, L., & Polosukhin, I. (2017).Attention Is All
You Need. Advances in Neural Information Processing Systems
(NeurIPS).
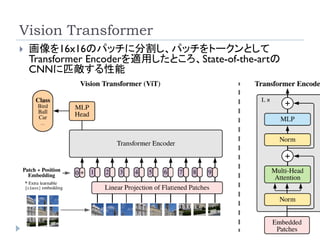
Vision Transformer
Dosovitskiy,A., Beyer, L., Kolesnikov,A.,Weissenborn, D., Zhai,
X., Unterthiner,T., Dehghani, M., Minderer, M., Heigold, G., Gelly,
S., Uszkoreit, J., & Houlsby, N. (2021).An Image Is Worth 16x16
Words:Transformers For Image Recognition At Scale.
International Conference on Learning Representations (ICLR).
39.
Transformerおさらい: 出典
39
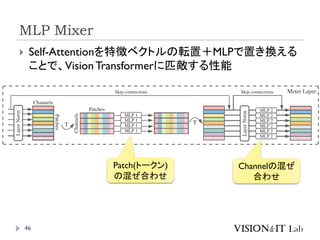
MLPMixer
Tolstikhin, I., Houlsby, N., Kolesnikov,A., Beyer, L., Zhai, X.,
Unterthiner,T.,Yung, J., Steiner,A., Keysers, D., Uszkoreit, J., Lucic,
M., & Dosovitskiy,A. (2021). MLP-Mixer:An all-MLP
Architecture forVision. Advances in Neural Information Processing
Systems
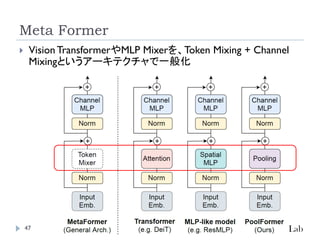
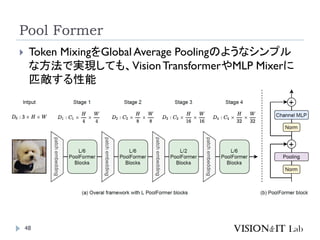
Meta Former (Pool Former)
Yu,W., Luo, M., Zhou, P., Si, C., Zhou,Y.,Wang, X., Feng, J., &Yan, S.
(2022). MetaFormer is ActuallyWhatYou Need forVision.
Proceedings of the IEEE Computer Society Conference on Computer
Vision and Pattern Recognition
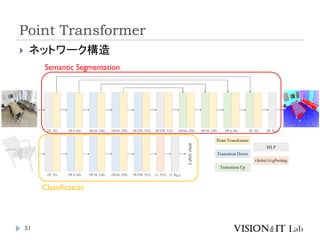
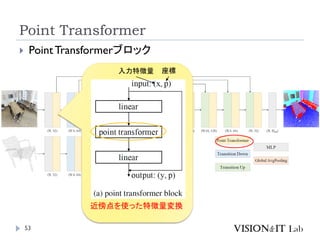
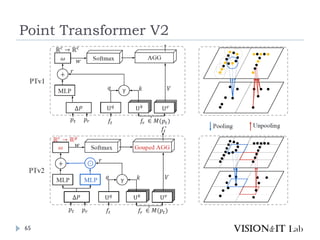
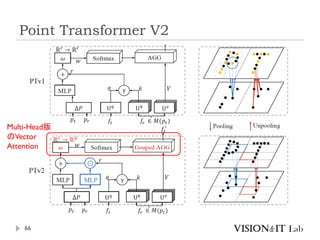
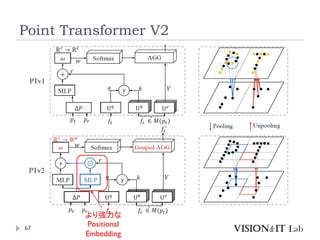
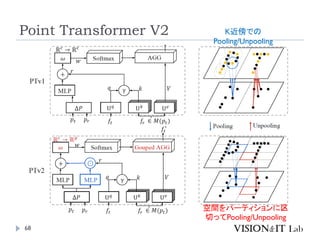
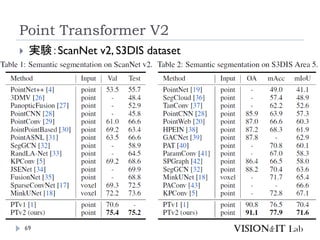
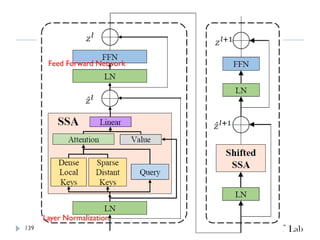
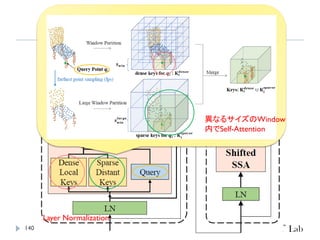
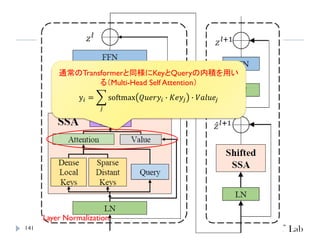
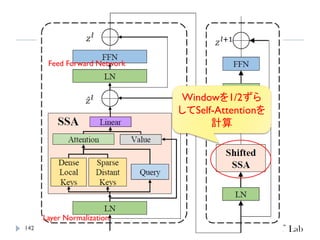
Point Transformer V2
64
Wu, X., Lao,Y., Jiang, L., Liu, X., & Zhao, H. (2022). Point
TransformerV2: GroupedVector Attention and Partition-
based Pooling. Advances in Neural Information Processing
Systems (NeurIPS), NeurIPS
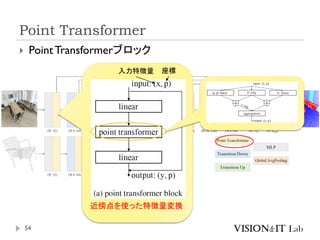
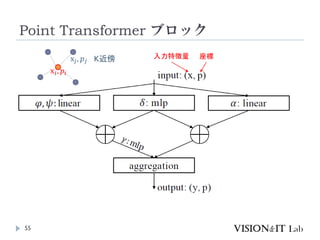
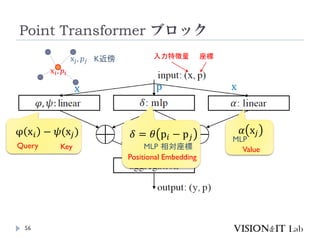
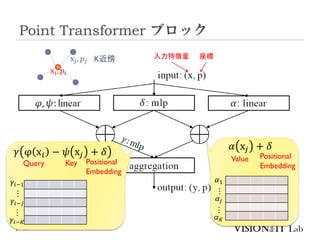
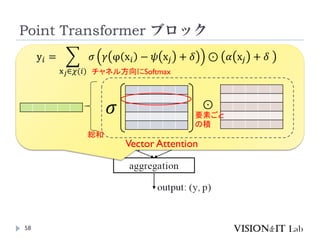
PointTransformerに対して、以下を導入することで性能改善
GroupedVector Attention
より強力なPositional Embedding
Partition Based Pooling
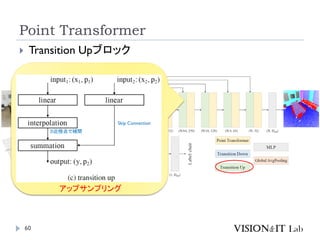
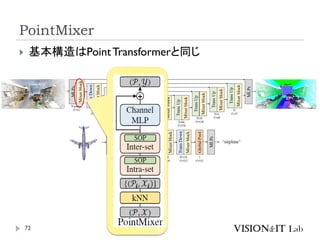
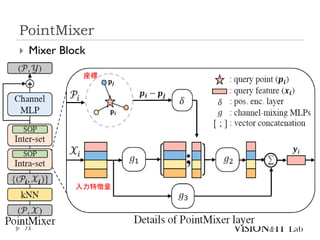
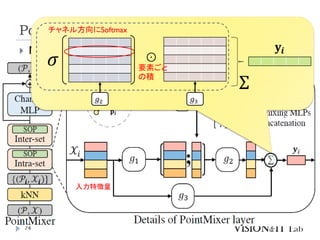
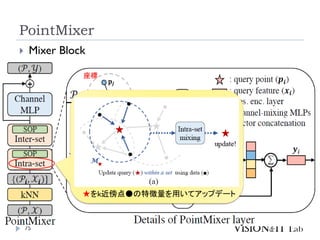
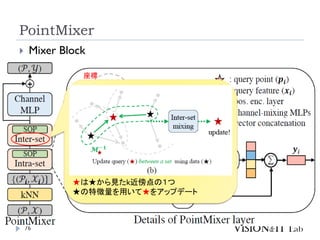
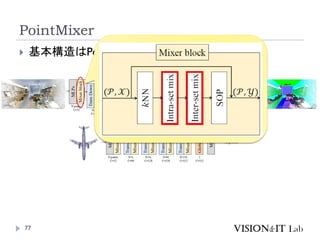
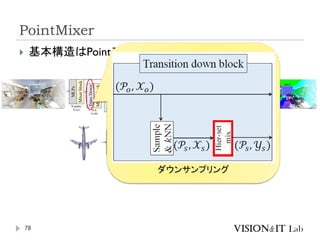
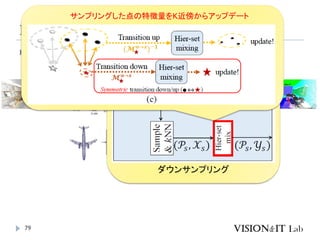
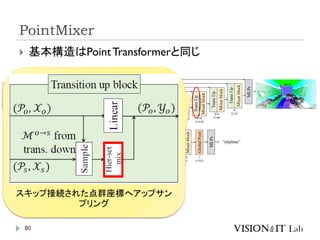
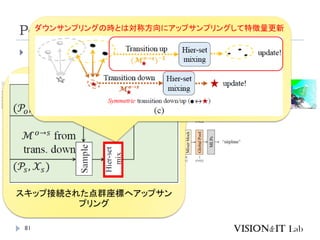
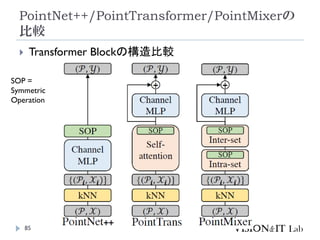
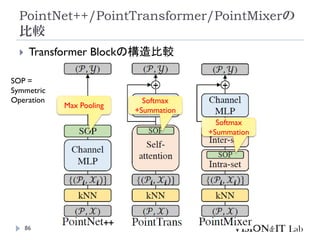
PointMixer
70
Choe, J.,Park, C., Rameau, F., Park, J., & Kweon, I. S. (2022).
PointMixer: MLP-Mixer for Point Cloud Understanding.
European Conference on ComputerVision (ECCV)
MLP Mixerを、点群のような疎で乱雑なデータに対して適用す
るために、Token-Mixing部分をChannel-MixingとSoftmaxの組
み合わせで置き換え
Inter-Set、Intra-Set、Hierarchical-Setの3パターンでmixing
高効率
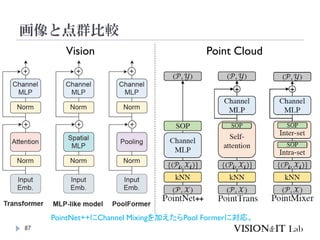
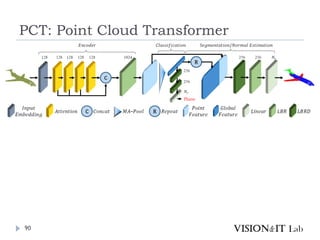
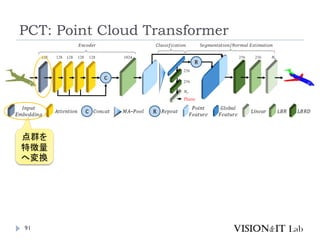
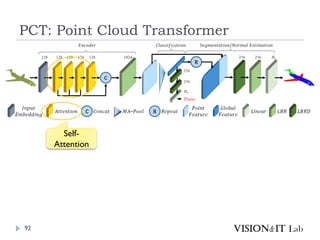
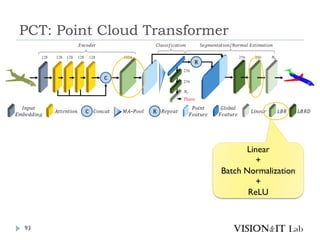
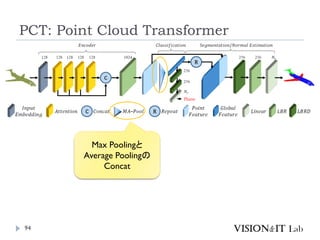
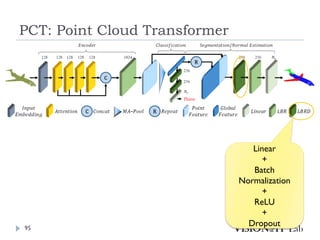
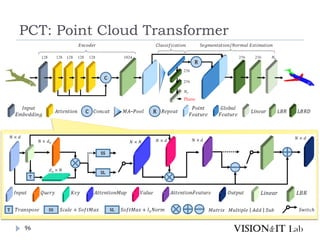
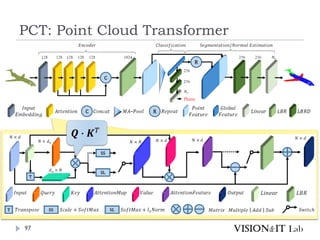
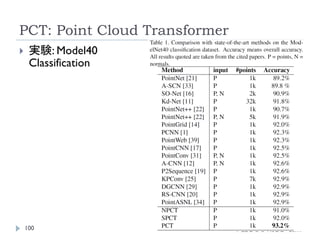
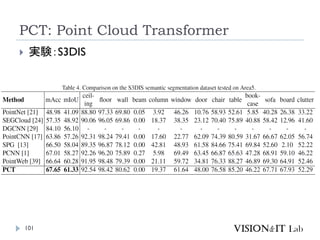
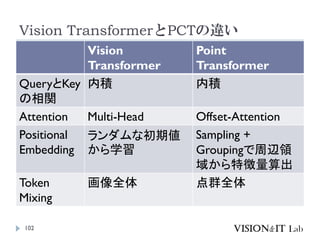
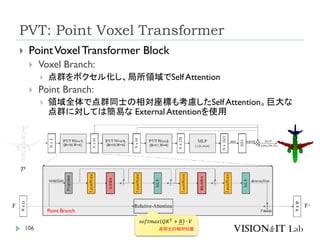
PCT: Point CloudTransformer
89
Guo, M. H., Cai, J. X., Liu, Z. N., Mu,T. J., Martin, R. R., & Hu,
S. M. (2021). PCT: Point cloud transformer. Computational
Visual Media, 7(2), 187–199.
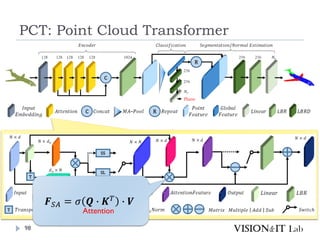
点群の座標を特徴量へ変換し、通常のTransformerと同様、
Key、Queryの内積を用いてAttentionを生成し、Valueに重み
づけ
全ての点同士でSelf-Attentionを計算
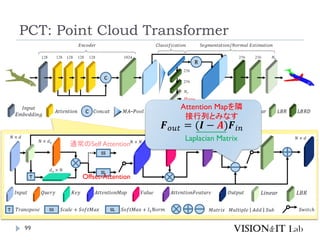
グラフ理論で用いられるラプラシアン行列を用いたOffset
Attentionを導入することで、順序不変なAttentionを実装
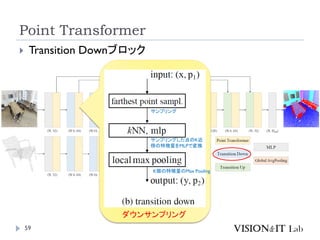
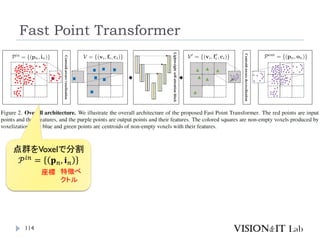
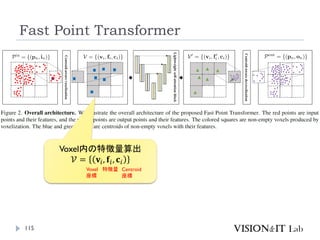
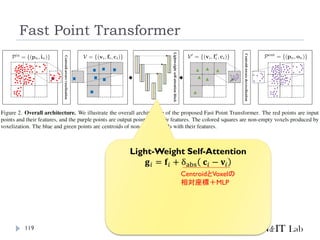
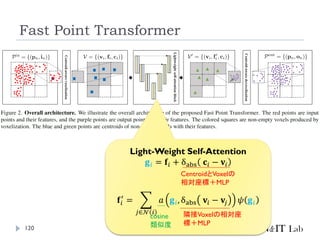
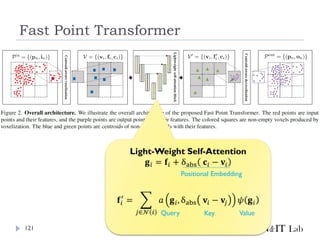
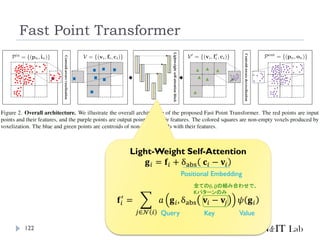
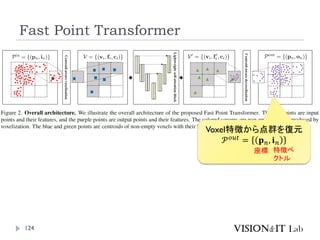
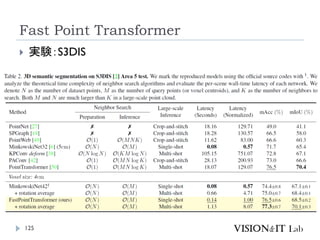
Fast Point Transformer
112
Park, C., Jeong,Y., Cho, M., & Park, J. (2022). Fast Point
Transformer. Conference on ComputerVision and Pattern
Recognition (CVPR)
LightWeightな局所領域でのSelf-Attention Blockを導入
Voxel-Hashingベースアーキテクチャによって、Point
Transformerと比較して129倍の推論の高速化
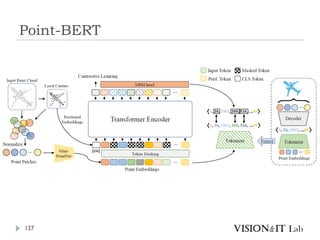
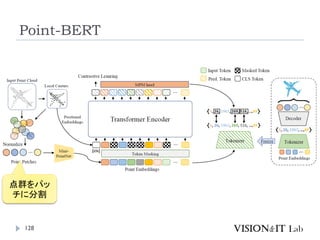
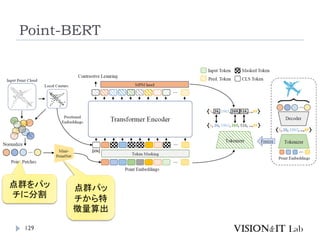
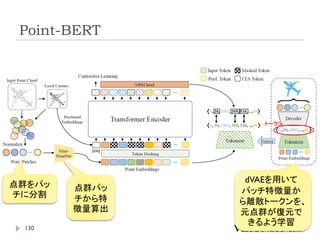
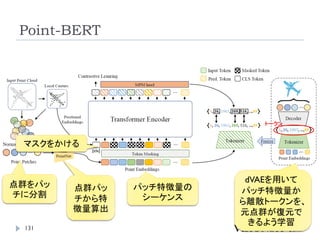
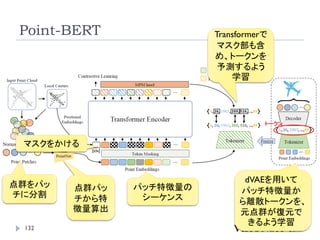
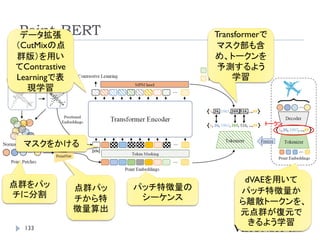
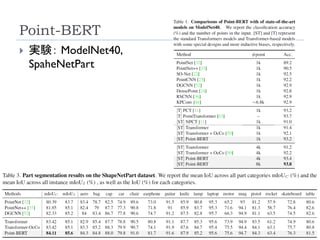
Point-BERT
126
Yu, X.,Tang,L., Rao,Y., Huang,T., Zhou, J., & Lu, J. (2022).
Point-BERT: Pre-training 3D Point CloudTransformers
with Masked Point Modeling. Conference on ComputerVision
and Pattern Recognition (CVPR)
点群解析のための事前学習モデルの作成
Classificationは2層のMLPを加えて識別。
Object Part Segmentationは、Transformerのいくつかの中間
層と最終層の特徴量を元に、各点のラベルを計算
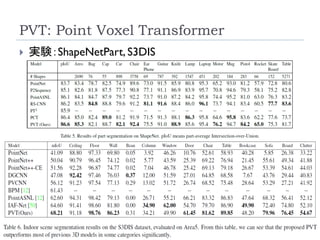
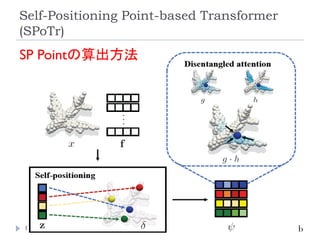
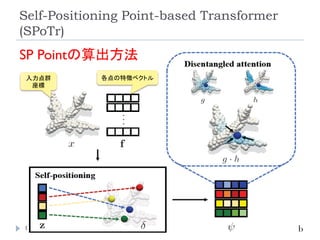
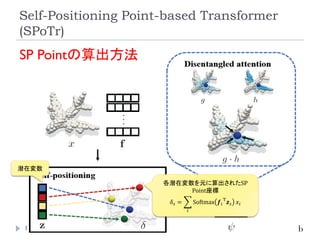
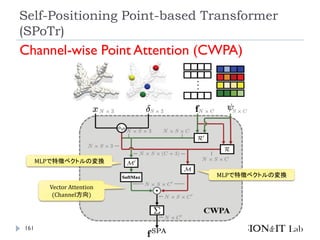
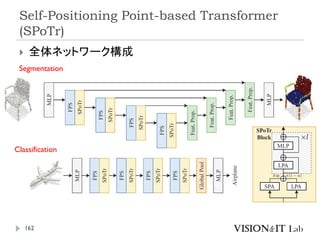
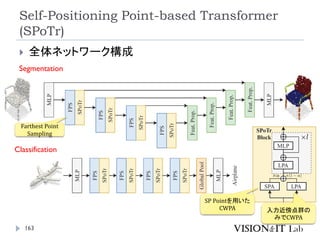
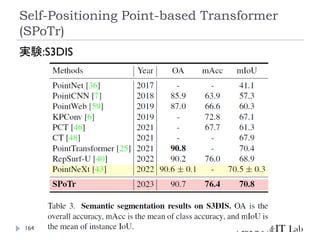
Self-Positioning Point-based Transformer
(SPoTr)
153
Park, J., Lee, S., Kim, S., Xiong,Y., & Kim, H. J. (2023).
Self-positioning Point-based Transformer for Point
Cloud Understanding. Conference on Computer
Vision and Pattern Recognition (CVPR).
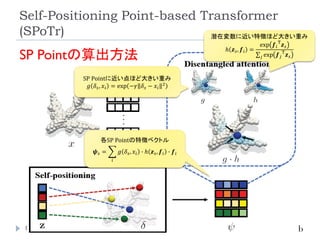
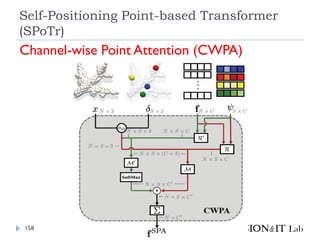
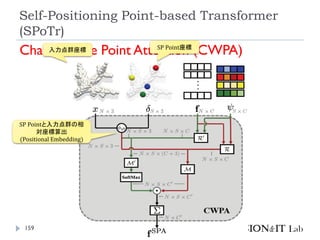
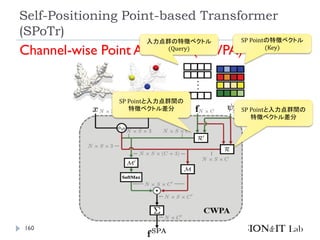
リソース削減のために、全ての点同士のSelf-
Attentionを取るのではなく、グローバルおよびロー
カルの特徴を捉えたself-positioning point (SP point)
を使用。
SP pointを用いてローカルおよびグローバルなCross-
Attentionを取ることで、3つのベンチマーク(SONN,
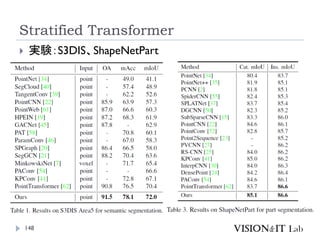
SN-Part, and S3DIS)でSOTA達成






















































![SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~](https://cdn.slidesharecdn.com/ss_thumbnails/ts1-01-210607042113-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]SlowFast Networks for Video Recognition](https://cdn.slidesharecdn.com/ss_thumbnails/20191206slowfastnetworkkuboshizuma-191206010601-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Reasoning-RCNN: Unifying Adaptive Global Reasoning into Large-scale Ob...](https://cdn.slidesharecdn.com/ss_thumbnails/20190726-190725235641-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=640&height=640&fit=bounds)



















