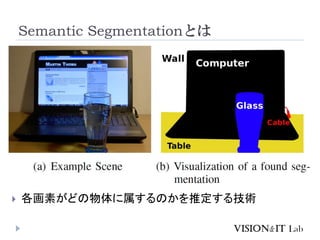
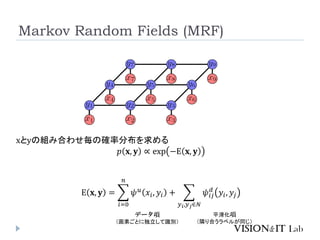
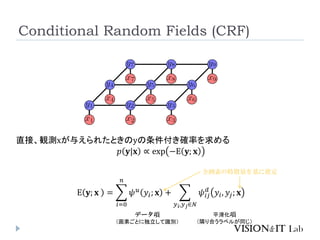
CRFを用いた例
CRFは認識対象クラスに関する知識をモデルの中に入れ込むこ
とが可能なため、 Semantic SegmentationではCRFを用いた手法
が性能的に良い。一方、SemanticでないSegmentationではMRF
が用いられることが多い。
X.He, R. S. Zemel, M. A. Carreira-Perpinan, “Multiscale
Conditional Random Fields for Image Labeling”, CVPR2004
J. Shotton, J. Winn, C. Rother, A. Criminisi, “TextonBoost for
Image Understanding: Multi-Class Object Recognition and
Segmentation by Jointly Modeling Texture, Layout, and
Context”, IJCV2009
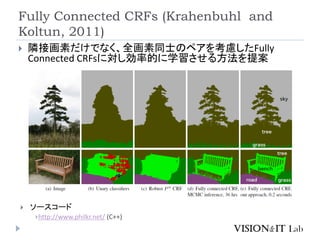
P. Krahenbuhl, V. Koltun, “Efficient Inference in Fully Connected
CRFs with Gaussian Edge Potentials”, NIPS2011
P. Arbelaez, B. Hariharan, C. Gu, S. Gupta, L. D. Bourdev, J. Malik,
“Semantic Segmentation using Regions and Parts”, CVPR2012
(非CRF)
25.
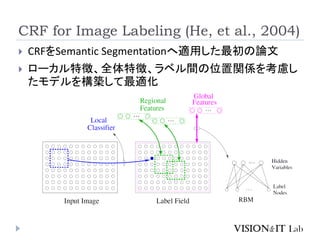
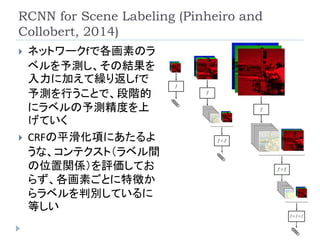
CRF for ImageLabeling (He, et al., 2004)
CRFをSemantic Segmentationへ適用した最初の論文
ローカル特徴、全体特徴、ラベル間の位置関係を考慮し
たモデルを構築して最適化
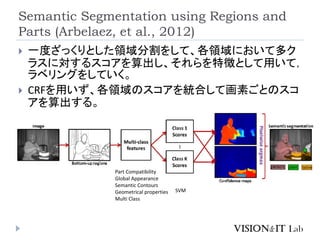
Semantic Segmentation usingRegions and
Parts (Arbelaez, et al., 2012)
一度ざっくりとした領域分割をして、各領域において多ク
ラスに対するスコアを算出し、それらを特徴として用いて,
ラベリングをしていく。
CRFを用いず、各領域のスコアを統合して画素ごとのスコ
アを算出する。
SVM
Part Compatibility
Global Appearance
Semantic Contours
Geometrical properties
Multi Class
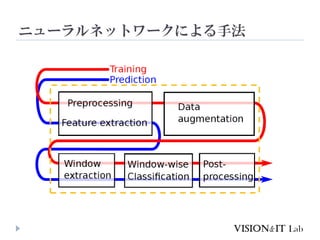
ニューラルネットワークによる手法の例
P. H.Pinheiro, R. Collobert, “Recurrent Convolutional Neural
Networks for Scene Labeling”, ICML2014
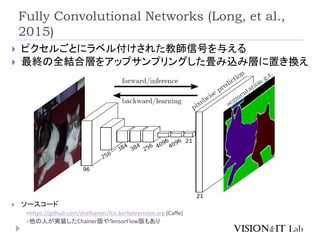
J. Long, E. Shelhamer, T. Darrel, “Fully Convolutional Networks
for Semantic Segmentation”, CVPR2015
S. Zheng, S. Jayasumana, B. Romera-Paredes, V. Vineet, Z. Su, D.
Du, C. Huang, P. H. S. Torr, “Conditional Random Fields as
Recurrent Neural Networks”, ICCV2015
H. Noh, S. Hong, B. Han, “Learning Deconvolution Network for
Semantic Segmentation”, ICCV2015
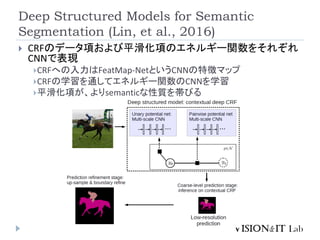
G. Lin, C. Shen, A. Hengel, I. Reid, “Efficient Piecewise Training
of Deep Structured Models for Semantic Segmentation”,
CVPR2016
P. Isola, J. Y. Zhu, T. Zhou, A. A. Efros, “Image to Image
Translation with Conditional Adversarial Networks”,
arXiv:1611.67004v1, 2016























![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)



























































