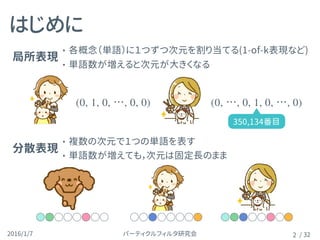
パーティクルフィルタ研究会2016/1/7 / 32
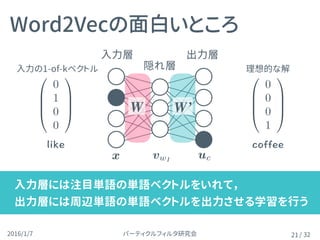
入力層のベクトルはV次元
ある要素だけ1、それ以外は0の 1-of-k ベクトル
例: V= { } =
入力層( )
15
x =
0
B
B
B
B
B
B
@
x1
x2
x3
x4
x5
x6
1
C
C
C
C
C
C
A
=
0
B
B
B
B
B
B
@
0 · · · I
1 · · · like
0 · · · black
0 · · · coffee
0 · · · am
0 · · · cat
1
C
C
C
C
C
C
A
x
x
wI
16.
パーティクルフィルタ研究会2016/1/7 / 32
Wはボキャブラリの全単語の単語ベクトルを横に並べた行列
隠れ層への重み( )
16
隠
れ
層
の
次
元
W
=
0
B
B
B
@
v11 v21 v31 v41 v51 v61
v12 v22 v32 v42 v52 v62
...
...
...
...
...
...
v1N v2N v3N v4N v5N v6N
1
C
C
C
A
W = v1 v2 v3 v4 v5 v6
, の場合,W は 200 x 106
の大きさh 2 R200
x 2 R106
17.
パーティクルフィルタ研究会2016/1/7 / 32
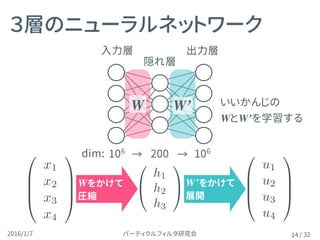
隠れ層の計算h = Wx
(活性化関数なし)
隠れ層( )
17
隠れ層の出力は、複雑な計算をせずに になる
ここで 1-of-k が生きてくる
( :N次元ベクトル)
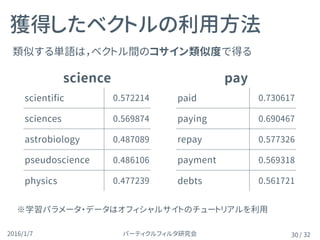
各 v が単語の「意味」を表す
W x = v1 v2 v3 v4 v5 v6
0
B
B
B
B
B
B
@
0
1
0
0
0
0
1
C
C
C
C
C
C
A
= v2W x = v1 v2 v3 v4
h
h = W xwI
= vwI
vwI v
18.
パーティクルフィルタ研究会2016/1/7 / 32
隠れ層から出力層への重みW′も同様に単語ベクトルv′ を並べた
出力層への重み( )
18
W'
W 0
=
0
B
B
B
B
B
B
B
@
v0T
1
v0T
2
v0T
3
v0T
4
v0T
5
v0T
6
1
C
C
C
C
C
C
C
A
=
0
B
B
B
B
B
B
@
v0
11 v0
12 · · · v0
1N
v0
21 v0
22 · · · v0
2N
v0
31 v0
32 · · · v0
3N
v0
41 v0
42 · · · v0
4N
v0
51 v0
52 · · · v0
5N
v0
61 v0
62 · · · v0
6N
1
C
C
C
C
C
C
A
, の場合,W' は 106
x 200 の大きさh 2 R200
x 2 R106
19.
パーティクルフィルタ研究会2016/1/7 / 32
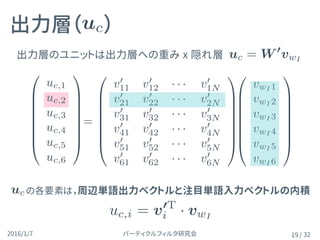
出力層( )
19
の各要素は,周辺単語出力ベクトルと注目単語入力ベクトルの内積
uc.i=
0
B
B
B
B
B
B
@
v0
11 v0
12 · · · v0
1N
v0
21 v0
22 · · · v0
2N
v0
31 v0
32 · · · v0
3N
v0
41 v0
42 · · · v0
4N
v0
51 v0
52 · · · v0
5N
v0
61 v0
62 · · · v0
6N
1
C
C
C
C
C
C
A
vwI
出力層のユニットは出力層への重み x 隠れ層
0
B
B
B
B
B
B
@
uc,1
uc,2
uc,3
uc,4
uc,5
uc,6
1
C
C
C
C
C
C
A
0
B
B
B
B
B
B
@
vwI 1
vwI 2
vwI 3
vwI 4
vwI 5
vwI 6
1
C
C
C
C
C
C
A
uc = W 0
vwI
uc,i = v0T
i · vwI
uc = W 0
vwI
uc = W 0
vwI
20.
パーティクルフィルタ研究会2016/1/7 / 32
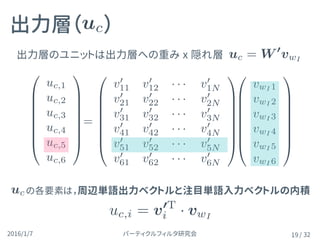
出力層( )
19
の各要素は,周辺単語出力ベクトルと注目単語入力ベクトルの内積
uc.i=
0
B
B
B
B
B
B
@
v0
11 v0
12 · · · v0
1N
v0
21 v0
22 · · · v0
2N
v0
31 v0
32 · · · v0
3N
v0
41 v0
42 · · · v0
4N
v0
51 v0
52 · · · v0
5N
v0
61 v0
62 · · · v0
6N
1
C
C
C
C
C
C
A
vwI
出力層のユニットは出力層への重み x 隠れ層
0
B
B
B
B
B
B
@
uc,1
uc,2
uc,3
uc,4
uc,5
uc,6
1
C
C
C
C
C
C
A
0
B
B
B
B
B
B
@
vwI 1
vwI 2
vwI 3
vwI 4
vwI 5
vwI 6
1
C
C
C
C
C
C
A
uc = W 0
vwI
uc,i = v0T
i · vwI
uc = W 0
vwI
uc = W 0
vwI
21.
パーティクルフィルタ研究会2016/1/7 / 32
出力層( )
19
の各要素は,周辺単語出力ベクトルと注目単語入力ベクトルの内積
uc.i=
0
B
B
B
B
B
B
@
v0
11 v0
12 · · · v0
1N
v0
21 v0
22 · · · v0
2N
v0
31 v0
32 · · · v0
3N
v0
41 v0
42 · · · v0
4N
v0
51 v0
52 · · · v0
5N
v0
61 v0
62 · · · v0
6N
1
C
C
C
C
C
C
A
vwI
出力層のユニットは出力層への重み x 隠れ層
0
B
B
B
B
B
B
@
uc,1
uc,2
uc,3
uc,4
uc,5
uc,6
1
C
C
C
C
C
C
A
0
B
B
B
B
B
B
@
vwI 1
vwI 2
vwI 3
vwI 4
vwI 5
vwI 6
1
C
C
C
C
C
C
A
uc = W 0
vwI
uc,i = v0T
i · vwI
uc = W 0
vwI
uc = W 0
vwI
パーティクルフィルタ研究会2016/1/7 / 32
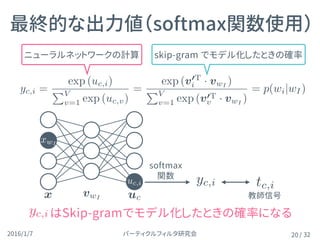
高速化したあとの目的関数
29
Wの更新式
W’の更新式
Eを W,W’ の各要素で偏微分する ti =
⇢
1 (i = wO)
0 (otherwise)
E = log (v0T
wO
· vwI
)
X
v2VNeg
( v0T
v · vwI
)
v0
ij := v0
ij ⌘( (v0T
i · v0
wI
) ti)vwI j
vij := vwI i ⌘
X
v2wO[VNeg
( (v0T
v · vwI
) tv)v0
vi





































![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)






































