Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
AtsukiYamaguchi1
PPTX, PDF
5,815 views
Transformerを雰囲気で理解する
BERTを理解するためのTransformer雰囲気紹介スライドです.
Technology
◦
Related topics:
Natural Language Processing
•
Read more
2
Save
Share
Embed
Embed presentation
Download
Downloaded 43 times
1
/ 37
2
/ 37
3
/ 37
4
/ 37
5
/ 37
6
/ 37
7
/ 37
8
/ 37
9
/ 37
10
/ 37
11
/ 37
12
/ 37
13
/ 37
Most read
14
/ 37
Most read
15
/ 37
16
/ 37
Most read
17
/ 37
18
/ 37
19
/ 37
20
/ 37
21
/ 37
22
/ 37
23
/ 37
24
/ 37
25
/ 37
26
/ 37
27
/ 37
28
/ 37
29
/ 37
30
/ 37
31
/ 37
32
/ 37
33
/ 37
34
/ 37
35
/ 37
36
/ 37
37
/ 37
More Related Content
PDF
全力解説!Transformer
by
Arithmer Inc.
PDF
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
PPTX
NLPにおけるAttention~Seq2Seq から BERTまで~
by
Takuya Ono
PPTX
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
PDF
Attentionの基礎からTransformerの入門まで
by
AGIRobots
PPTX
マルチモーダル深層学習の研究動向
by
Koichiro Mori
PDF
東京大学2021年度深層学習(Deep learning基礎講座2021) 第8回「深層学習と自然言語処理」
by
Hitomi Yanaka
全力解説!Transformer
by
Arithmer Inc.
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
NLPにおけるAttention~Seq2Seq から BERTまで~
by
Takuya Ono
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
Attentionの基礎からTransformerの入門まで
by
AGIRobots
マルチモーダル深層学習の研究動向
by
Koichiro Mori
東京大学2021年度深層学習(Deep learning基礎講座2021) 第8回「深層学習と自然言語処理」
by
Hitomi Yanaka
What's hot
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PPTX
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
by
Deep Learning JP
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PPTX
近年のHierarchical Vision Transformer
by
Yusuke Uchida
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
PPTX
ResNetの仕組み
by
Kota Nagasato
PPTX
backbone としての timm 入門
by
Takuji Tahara
PPTX
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
PDF
PRML学習者から入る深層生成モデル入門
by
tmtm otm
PDF
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
by
Deep Learning JP
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
近年のHierarchical Vision Transformer
by
Yusuke Uchida
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
ResNetの仕組み
by
Kota Nagasato
backbone としての timm 入門
by
Takuji Tahara
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
PRML学習者から入る深層生成モデル入門
by
tmtm otm
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
Similar to Transformerを雰囲気で理解する
PDF
Transformer メタサーベイ
by
cvpaper. challenge
PDF
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
PPTX
深層学習を用いた文生成モデルの歴史と研究動向
by
Shunta Ito
PPTX
[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...
by
Deep Learning JP
PDF
第六回全日本コンピュータビジョン勉強会資料 UniT (旧題: Transformer is all you need)
by
Yasunori Ozaki
PDF
BERTに関して
by
Saitama Uni
PDF
ニューラルネットワークを用いた自然言語処理
by
Sho Takase
PPTX
NLP2017 NMT Tutorial
by
Toshiaki Nakazawa
PDF
【論文紹介】Seq2Seq (NIPS 2014)
by
Tomoyuki Hioki
PDF
transformer解説~Chat-GPTの源流~
by
MasayoshiTsutsui
PPTX
Bert(transformer,attention)
by
norimatsu5
PDF
[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」
by
Yuki Arase
PDF
【DeepLearning研修】Transfomerの基礎と応用 --第4回 マルチモーダルへの展開
by
Sony - Neural Network Libraries
PDF
文献紹介:Big Bird: Transformers for Longer Sequences
by
Toru Tamaki
PDF
[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」
by
Yuki Arase
PDF
attention_is_all_you_need_nips17_論文紹介
by
Masayoshi Kondo
PPT
[FUNAI輪講] BERT
by
Takanori Ebihara
PDF
What is transformer ?
by
Riku Kawamura
PDF
第 11 回 最先端 NLP 勉強会
by
Yuko Fujiyama
PPTX
200122 bert slideshare
by
SohOhara
Transformer メタサーベイ
by
cvpaper. challenge
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
深層学習を用いた文生成モデルの歴史と研究動向
by
Shunta Ito
[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...
by
Deep Learning JP
第六回全日本コンピュータビジョン勉強会資料 UniT (旧題: Transformer is all you need)
by
Yasunori Ozaki
BERTに関して
by
Saitama Uni
ニューラルネットワークを用いた自然言語処理
by
Sho Takase
NLP2017 NMT Tutorial
by
Toshiaki Nakazawa
【論文紹介】Seq2Seq (NIPS 2014)
by
Tomoyuki Hioki
transformer解説~Chat-GPTの源流~
by
MasayoshiTsutsui
Bert(transformer,attention)
by
norimatsu5
[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」
by
Yuki Arase
【DeepLearning研修】Transfomerの基礎と応用 --第4回 マルチモーダルへの展開
by
Sony - Neural Network Libraries
文献紹介:Big Bird: Transformers for Longer Sequences
by
Toru Tamaki
[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」
by
Yuki Arase
attention_is_all_you_need_nips17_論文紹介
by
Masayoshi Kondo
[FUNAI輪講] BERT
by
Takanori Ebihara
What is transformer ?
by
Riku Kawamura
第 11 回 最先端 NLP 勉強会
by
Yuko Fujiyama
200122 bert slideshare
by
SohOhara
Recently uploaded
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):コアマイクロシステムズ株式会社 テーマ 「AI HPC時代のトータルソリューションプロバイダ」
by
PC Cluster Consortium
PDF
論文紹介:DiffusionRet: Generative Text-Video Retrieval with Diffusion Model
by
Toru Tamaki
PDF
論文紹介:HiLoRA: Adaptive Hierarchical LoRA Routing for Training-Free Domain Gene...
by
Toru Tamaki
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ2「『Slinky』 SlurmとクラウドのKuber...
by
PC Cluster Consortium
PDF
論文紹介:MotionMatcher: Cinematic Motion Customizationof Text-to-Video Diffusion ...
by
Toru Tamaki
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ3「『TrinityX』 AI時代のクラスターマネジメ...
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):エヌビディア合同会社 テーマ1「NVIDIA 最新発表製品等のご案内」
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ1「大規模AIの能力を最大限に活用するHPE Comp...
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):富士通株式会社 テーマ1「HPC&AI: Accelerating material develo...
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ3「IT運用とデータサイエンティストを強力に支援するH...
by
PC Cluster Consortium
PDF
AI開発の最前線を変えるニューラルネットワークプロセッサと、未来社会における応用可能性
by
Data Source
PPTX
ChatGPTのコネクタ開発から学ぶ、外部サービスをつなぐMCPサーバーの仕組み
by
Ryuji Egashira
PDF
ニューラルプロセッサによるAI処理の高速化と、未知の可能性を切り拓く未来の人工知能
by
Data Source
PPTX
2025年11月24日情報ネットワーク法学会大井哲也発表「API利用のシステム情報」
by
Tetsuya Oi
PDF
膨大なデータ時代を制する鍵、セグメンテーションAIが切り拓く解析精度と効率の革新
by
Data Source
PCCC25(設立25年記念PCクラスタシンポジウム):コアマイクロシステムズ株式会社 テーマ 「AI HPC時代のトータルソリューションプロバイダ」
by
PC Cluster Consortium
論文紹介:DiffusionRet: Generative Text-Video Retrieval with Diffusion Model
by
Toru Tamaki
論文紹介:HiLoRA: Adaptive Hierarchical LoRA Routing for Training-Free Domain Gene...
by
Toru Tamaki
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ2「『Slinky』 SlurmとクラウドのKuber...
by
PC Cluster Consortium
論文紹介:MotionMatcher: Cinematic Motion Customizationof Text-to-Video Diffusion ...
by
Toru Tamaki
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ3「『TrinityX』 AI時代のクラスターマネジメ...
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):エヌビディア合同会社 テーマ1「NVIDIA 最新発表製品等のご案内」
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ1「大規模AIの能力を最大限に活用するHPE Comp...
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):富士通株式会社 テーマ1「HPC&AI: Accelerating material develo...
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ3「IT運用とデータサイエンティストを強力に支援するH...
by
PC Cluster Consortium
AI開発の最前線を変えるニューラルネットワークプロセッサと、未来社会における応用可能性
by
Data Source
ChatGPTのコネクタ開発から学ぶ、外部サービスをつなぐMCPサーバーの仕組み
by
Ryuji Egashira
ニューラルプロセッサによるAI処理の高速化と、未知の可能性を切り拓く未来の人工知能
by
Data Source
2025年11月24日情報ネットワーク法学会大井哲也発表「API利用のシステム情報」
by
Tetsuya Oi
膨大なデータ時代を制する鍵、セグメンテーションAIが切り拓く解析精度と効率の革新
by
Data Source
Transformerを雰囲気で理解する
1.
BERTを理解するための TRANSFORMER 雰囲気理解 ◎_gucciiiii 2019/05/23
2.
Transformerとは? • 系列変換モデルの一種 入力も出力も時系列データとなるモデル エンコーダ
+ デコーダの構造 Seq2Seqとかがその例 • 再帰や畳み込みを一切使わないモデル 並列処理ができ,学習の高速化を実現 • 話題のBERTで活用されているモデル 2
3.
論文情報 • 論文名: Attention
Is All You Need 要するに「必要なのはAttentionだけ」 • 著者: A. Vaswani et al. (Google Brain) • 出典: NIPS 2017 3
4.
本スライドの構成 雰囲気中速(爆速🙅♂️)理解を図るために, 1. NLPにおけるNNの歴史的経緯を知る 2. Attentionについて知る 3.
Transformerのモデル概要を知る 4. Transformerのキモを知る 5. 実験結果を見てみる という流れで見ていきます. 4
5.
本スライドの構成 1. NLPにおけるNNの歴史的経緯を知る 2. Attentionについて知る 3.
Transformerのモデル概要を知る 4. Transformerのキモを知る 5. 実験結果を見てみる 5
6.
1. NLPにおけるNNの 歴史的経緯 6
7.
1. NLPにおけるNNの歴史的経緯① • 系列変換モデルは再帰ニューラルネットに 依存してきた
再帰は並列計算を妨げる 対症療法の考案: Factorization Trick [1]やConditional Computation [2] 直接解決しているわけではない! 7 1. https://arxiv.org/abs/1703.10722 2. https://arxiv.org/abs/1511.06297 3. (image) https://jeddy92.github.io/JEddy92.github.io/ts_seq2seq_intro/
8.
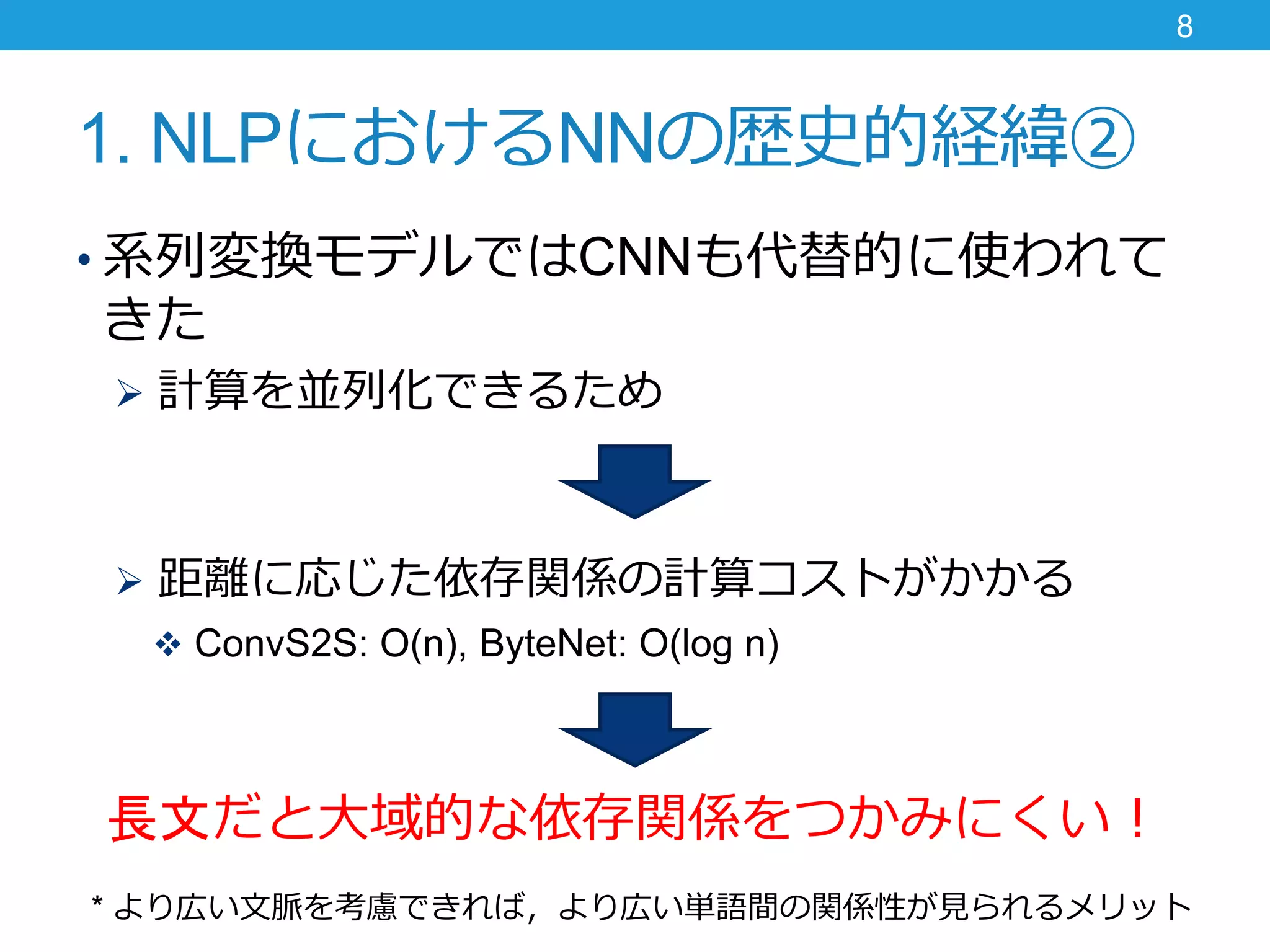
1. NLPにおけるNNの歴史的経緯② • 系列変換モデルではCNNも代替的に使われて きた
計算を並列化できるため 距離に応じた依存関係の計算コストがかかる ConvS2S: O(n), ByteNet: O(log n) 長文だと大域的な依存関係をつかみにくい! 8 * より広い文脈を考慮できれば,より広い単語間の関係性が見られるメリット
9.
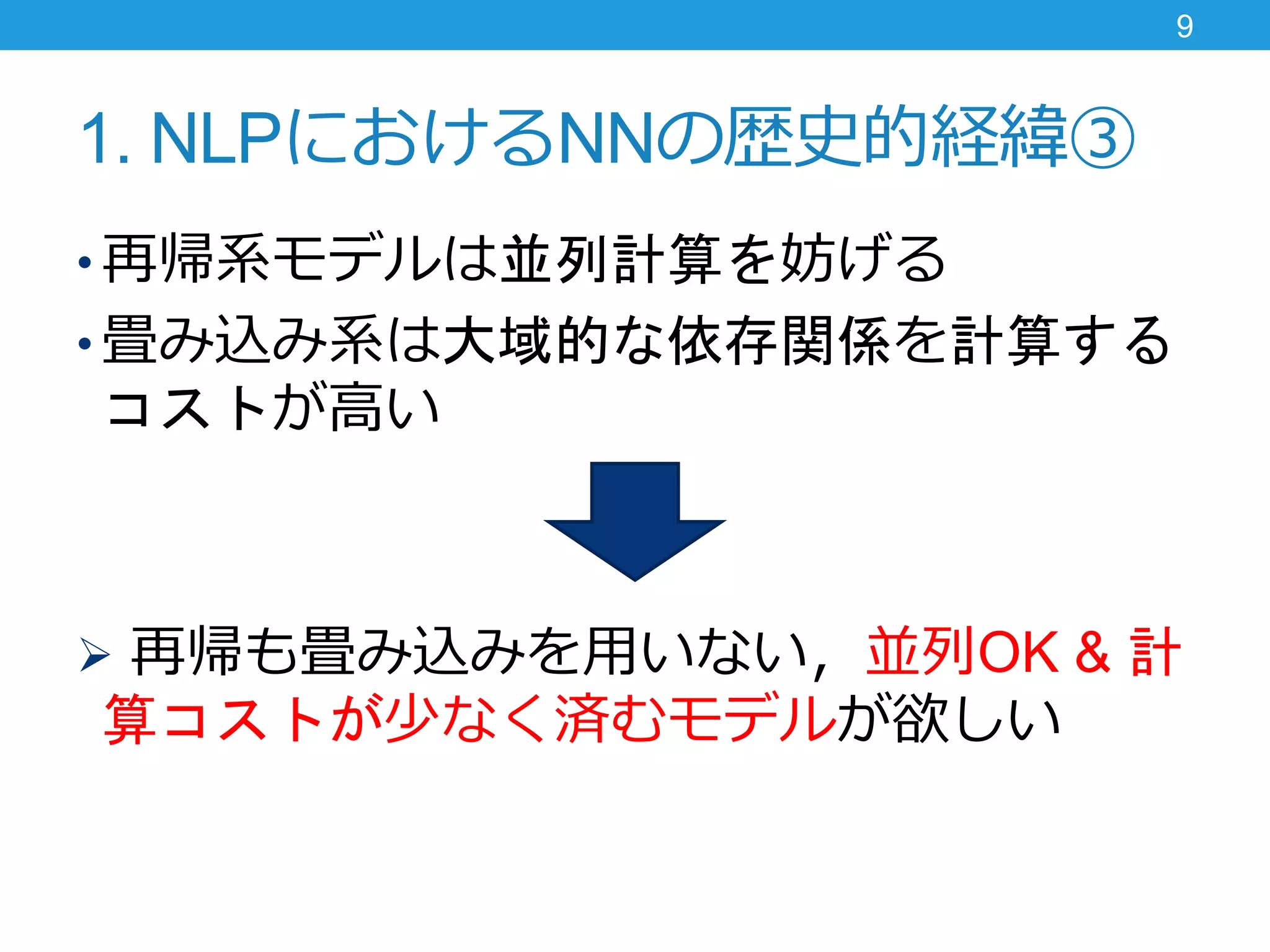
1. NLPにおけるNNの歴史的経緯③ • 再帰系モデルは並列計算を妨げる •
畳み込み系は大域的な依存関係を計算する コストが高い 再帰も畳み込みを用いない,並列OK & 計 算コストが少なく済むモデルが欲しい 9
10.
本スライドの構成 1. NLPにおけるNNの歴史的経緯を知る 2. Attentionについて知る 3.
Transformerのモデル概要を知る 4. Transformerのキモを知る 5. 実験結果を見てみる 10
11.
2. ATTENTION 1. Attentionとは? 2.
Attentionのバリエーション 3. Self Attentionとは? 4. Attentionの利点・欠点 11
12.
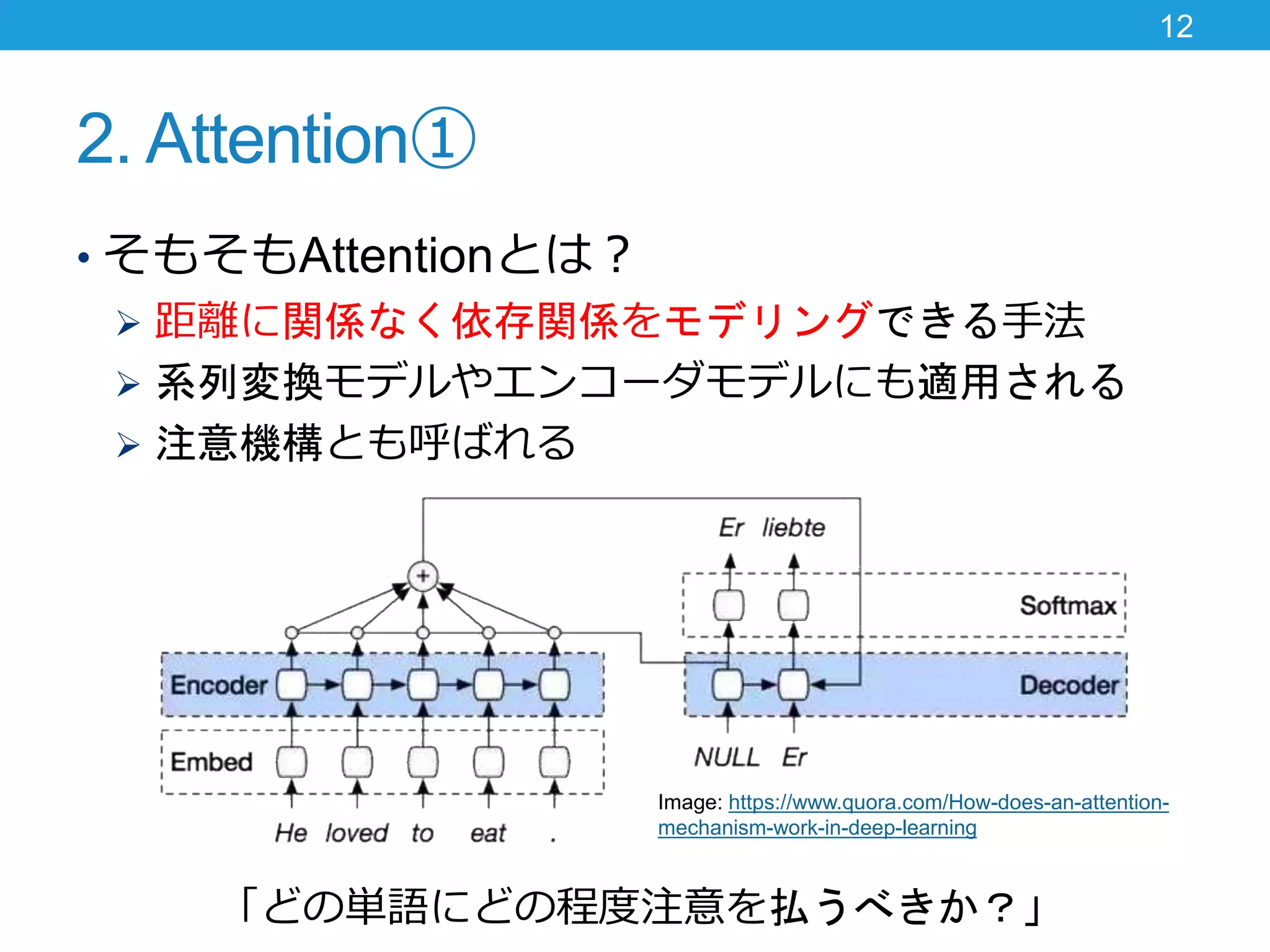
2. Attention① • そもそもAttentionとは?
距離に関係なく依存関係をモデリングできる手法 系列変換モデルやエンコーダモデルにも適用される 注意機構とも呼ばれる 12 「どの単語にどの程度注意を払うべきか?」 Image: https://www.quora.com/How-does-an-attention- mechanism-work-in-deep-learning
13.
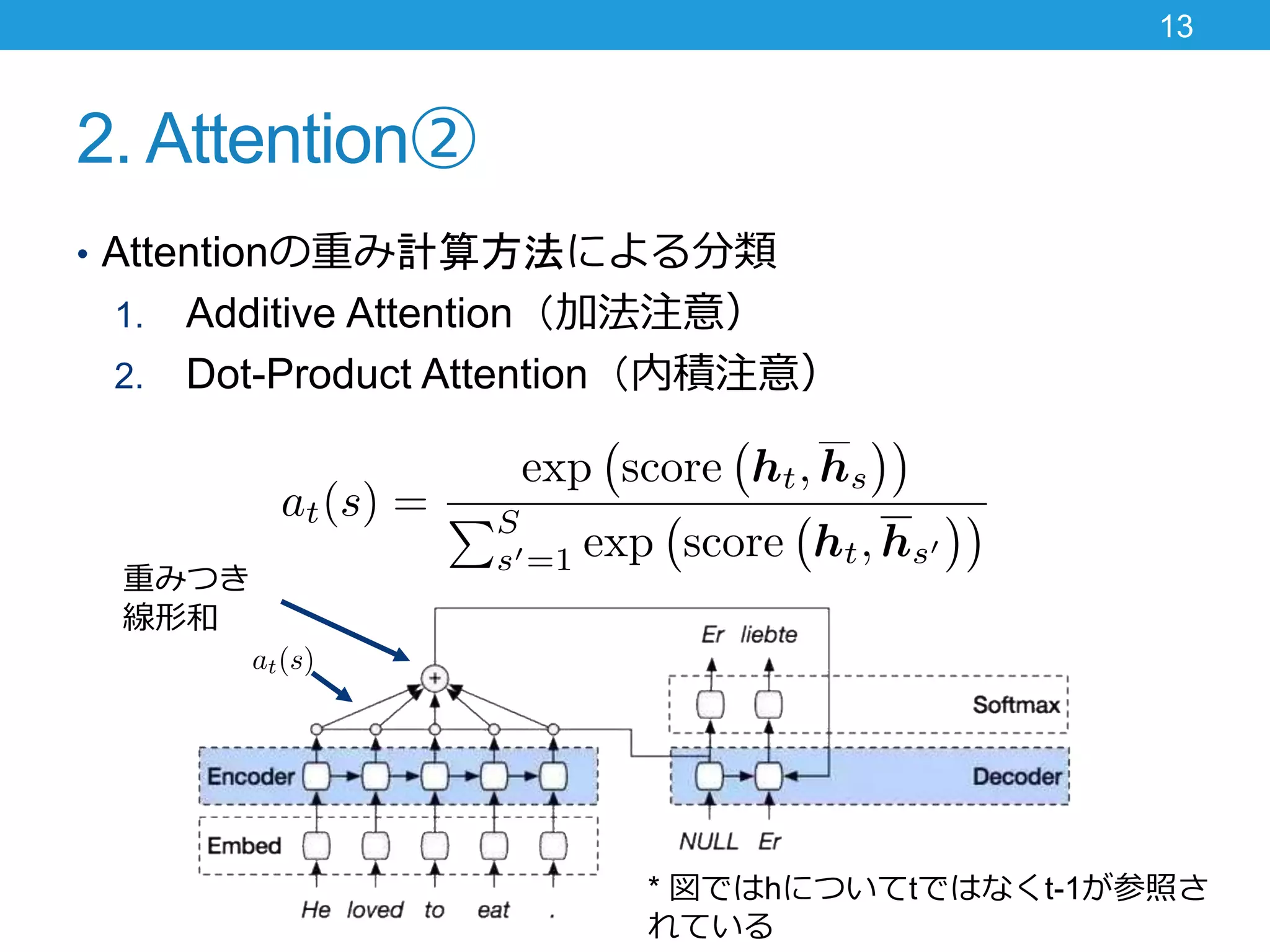
2. Attention② • Attentionの重み計算方法による分類 1.
Additive Attention(加法注意) 2. Dot-Product Attention(内積注意) 13 重みつき 線形和 * 図ではhについてtではなくt-1が参照さ れている
14.
2. Attention③ • Attentionの重み計算方法による分類 14 ここの求め方! •
内積注意 「時刻tのデコーダの隠れ 層の状態と,位置sでのエ ンコーダの隠れ層の状態」 との内積 • 加法注意 隠れ層を1層設けて計算 が となるパ ターンが2つくらいある *Attentionの重み計算手法は色々とありすぎるので,深く考える必要なし?
15.
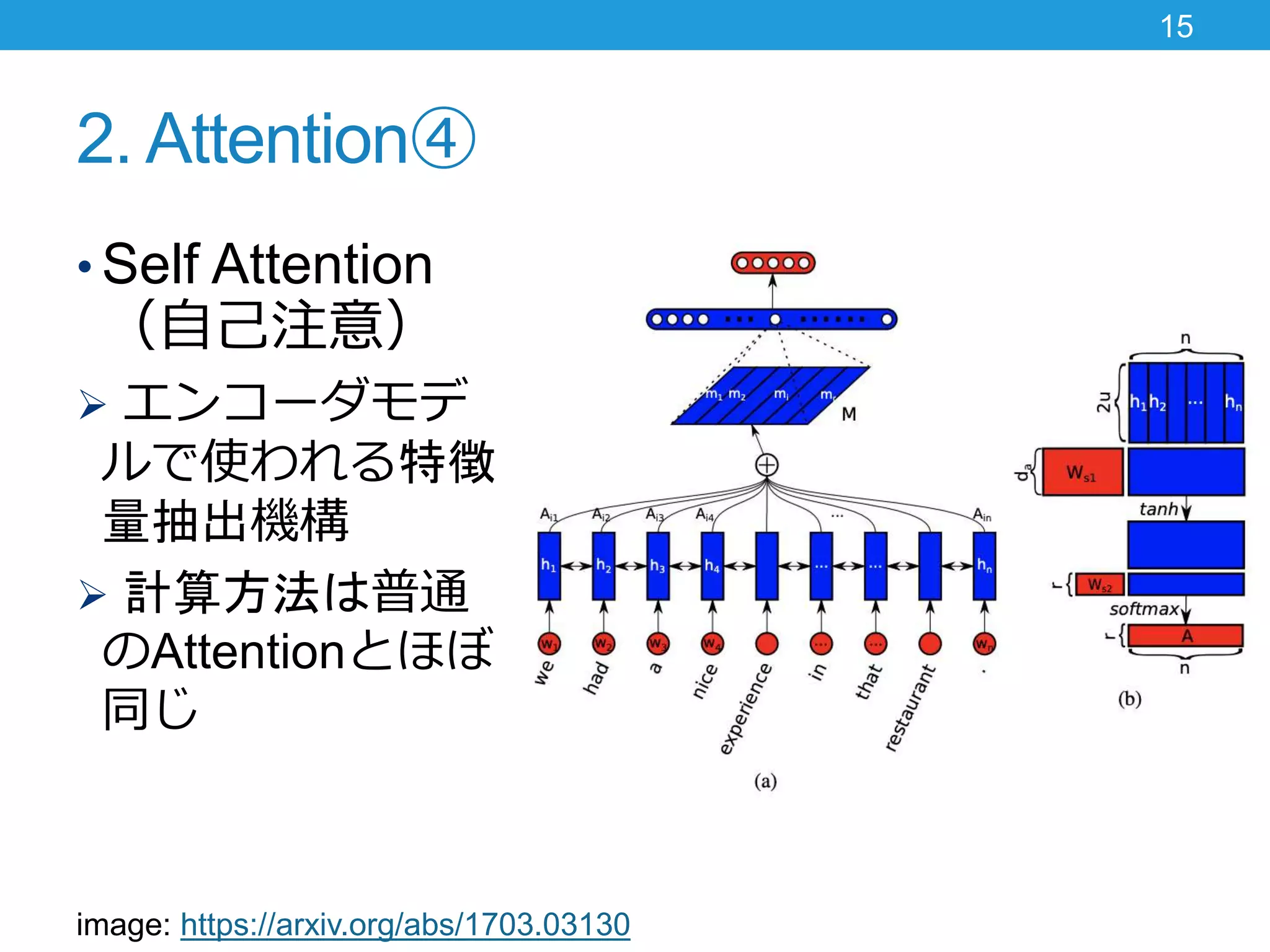
2. Attention④ • Self
Attention (自己注意) エンコーダモデ ルで使われる特徴 量抽出機構 計算方法は普通 のAttentionとほぼ 同じ 15 image: https://arxiv.org/abs/1703.03130
16.
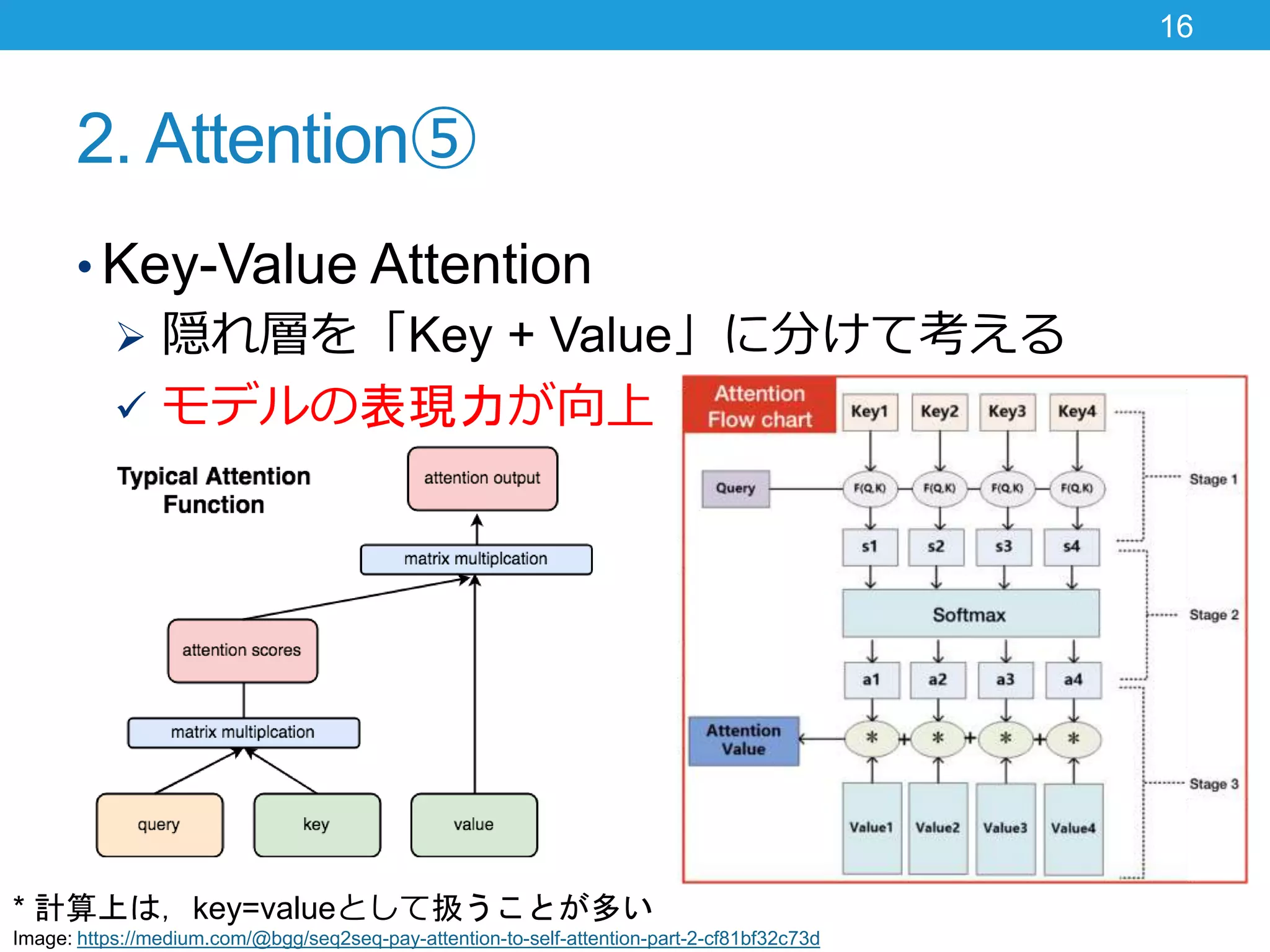
2. Attention⑤ • Key-Value
Attention 隠れ層を「Key + Value」に分けて考える モデルの表現力が向上 16 * 計算上は,key=valueとして扱うことが多い Image: https://medium.com/@bgg/seq2seq-pay-attention-to-self-attention-part-2-cf81bf32c73d
17.
2. Attention⑥ • Attentionの利点
位置に関わらず依存関係をO(1)で捉えられる LSTMやGRU等は長期記憶に弱い • Attentionの欠点 スコアの重み計算コストが通常O(n^2)以上になる Attentionはあくまでもモデルの補助的な役割 CNNベースのモデルも計算量の問題あり Attentionだけでモデルを作れば良いのでは? 17
18.
本スライドの構成 1. NLPにおけるNNの歴史的経緯を知る 2. Attentionについて知る 3.
Transformerのモデル概要を知る 4. Transformerのキモを知る 5. 実験結果を見てみる 18
19.
3. TRANSFORMERの概要 モデルの概要と BERTでの使われ方について 19
20.
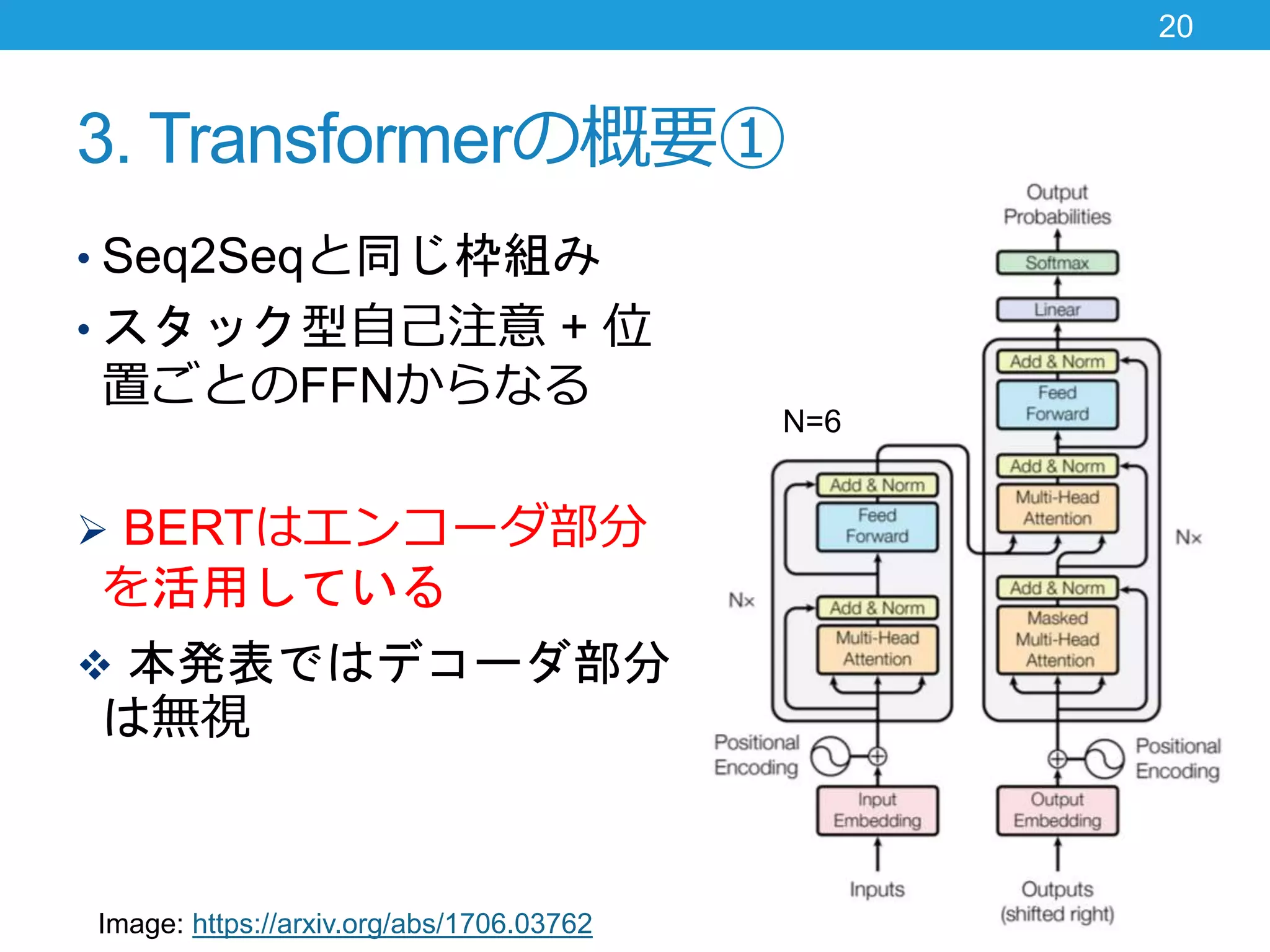
3. Transformerの概要① • Seq2Seqと同じ枠組み •
スタック型自己注意 + 位 置ごとのFFNからなる BERTはエンコーダ部分 を活用している 本発表ではデコーダ部分 は無視 20 Image: https://arxiv.org/abs/1706.03762 N=6
21.
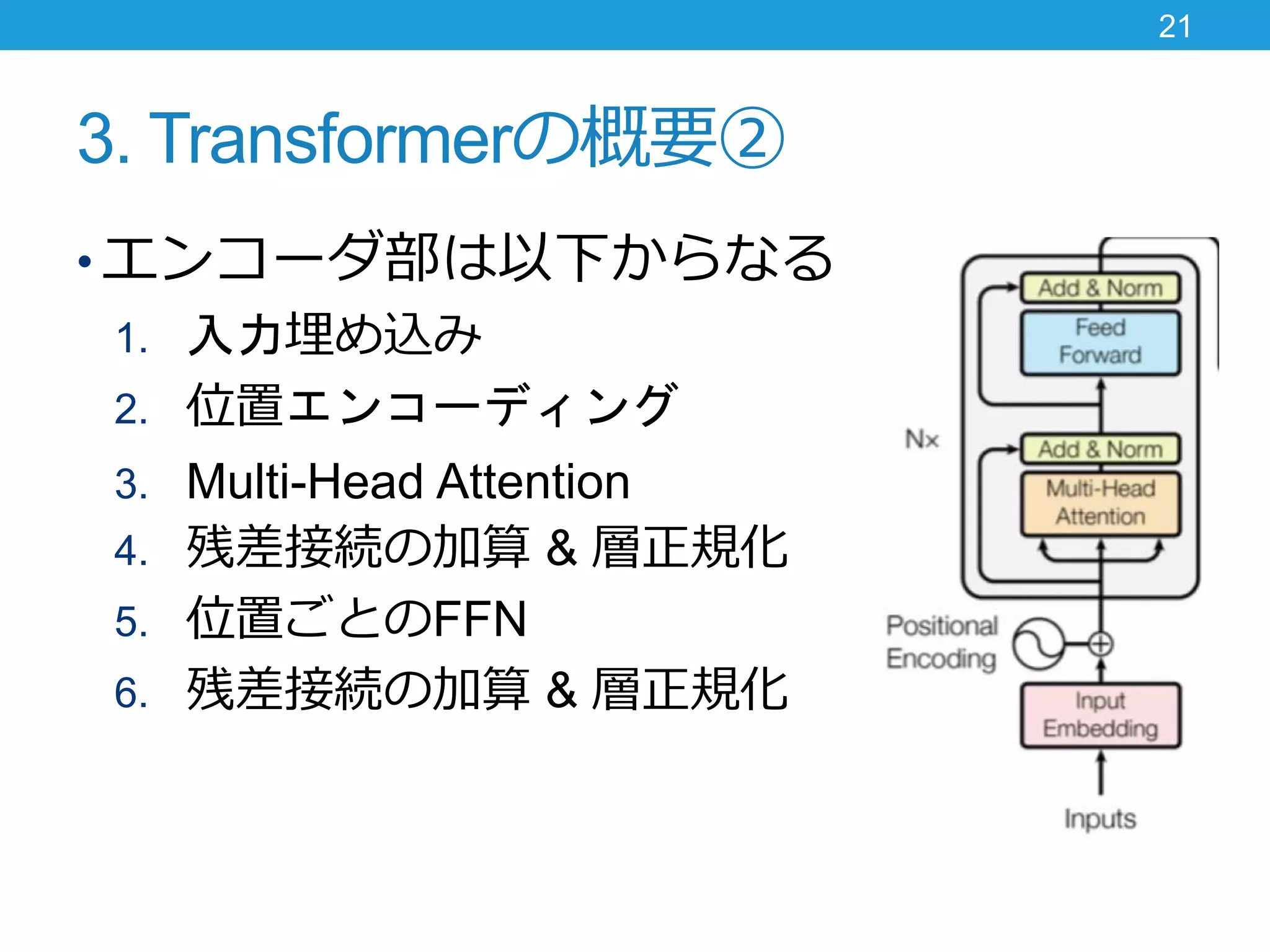
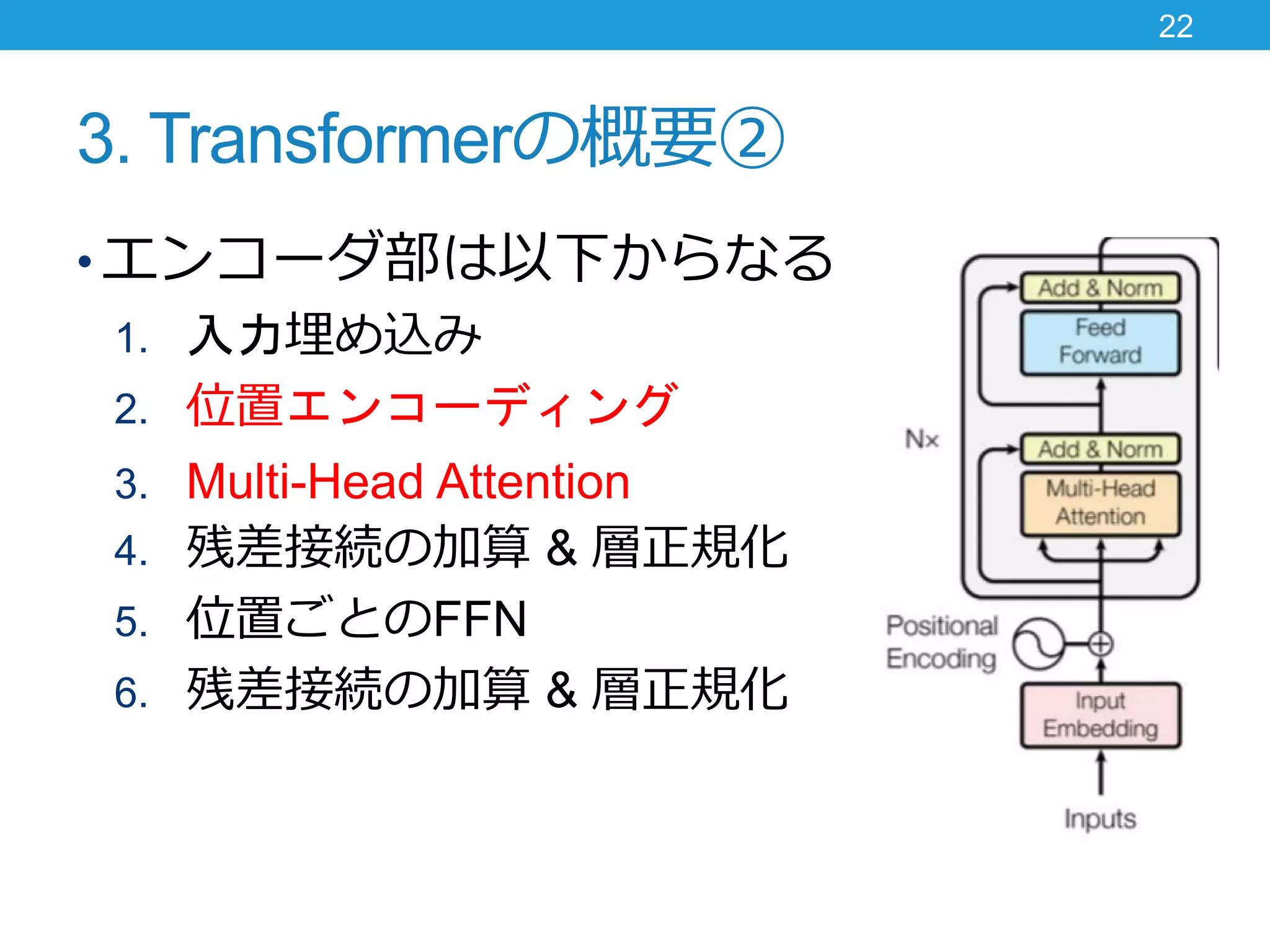
3. Transformerの概要② • エンコーダ部は以下からなる 1.
入力埋め込み 2. 位置エンコーディング 3. Multi-Head Attention 4. 残差接続の加算 & 層正規化 5. 位置ごとのFFN 6. 残差接続の加算 & 層正規化 21
22.
3. Transformerの概要② • エンコーダ部は以下からなる 1.
入力埋め込み 2. 位置エンコーディング 3. Multi-Head Attention 4. 残差接続の加算 & 層正規化 5. 位置ごとのFFN 6. 残差接続の加算 & 層正規化 22
23.
本スライドの構成 1. NLPにおけるNNの歴史的経緯を知る 2. Attentionについて知る 3.
Transformerのモデル概要を知る 4. Transformerのキモを知る 5. 実験結果を見てみる 23
24.
4. TRANSFORMERのキモ 1. スケール化内積注意 2.
Multi-Head Attention 3. 位置エンコーディング 24
25.
4. Transformerのキモ① • スケール化内積注意
隠れ層の次元が大きくなると,内積が大きく なる 勾配が小さくなり,学習が進まない スコアを で除算してあげることで解決 25
26.
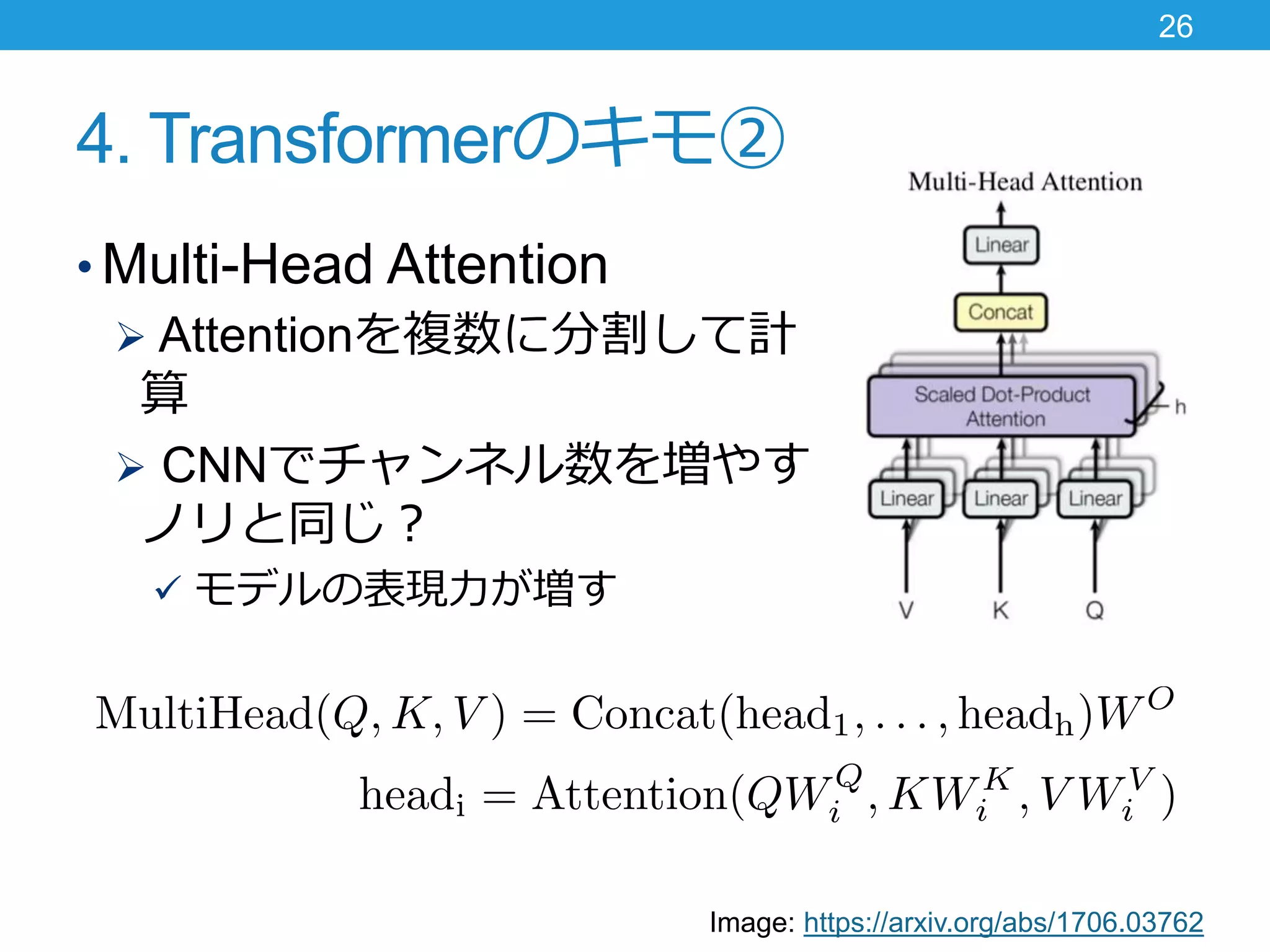
4. Transformerのキモ② • Multi-Head
Attention Attentionを複数に分割して計 算 CNNでチャンネル数を増やす ノリと同じ? モデルの表現力が増す 26 Image: https://arxiv.org/abs/1706.03762
27.
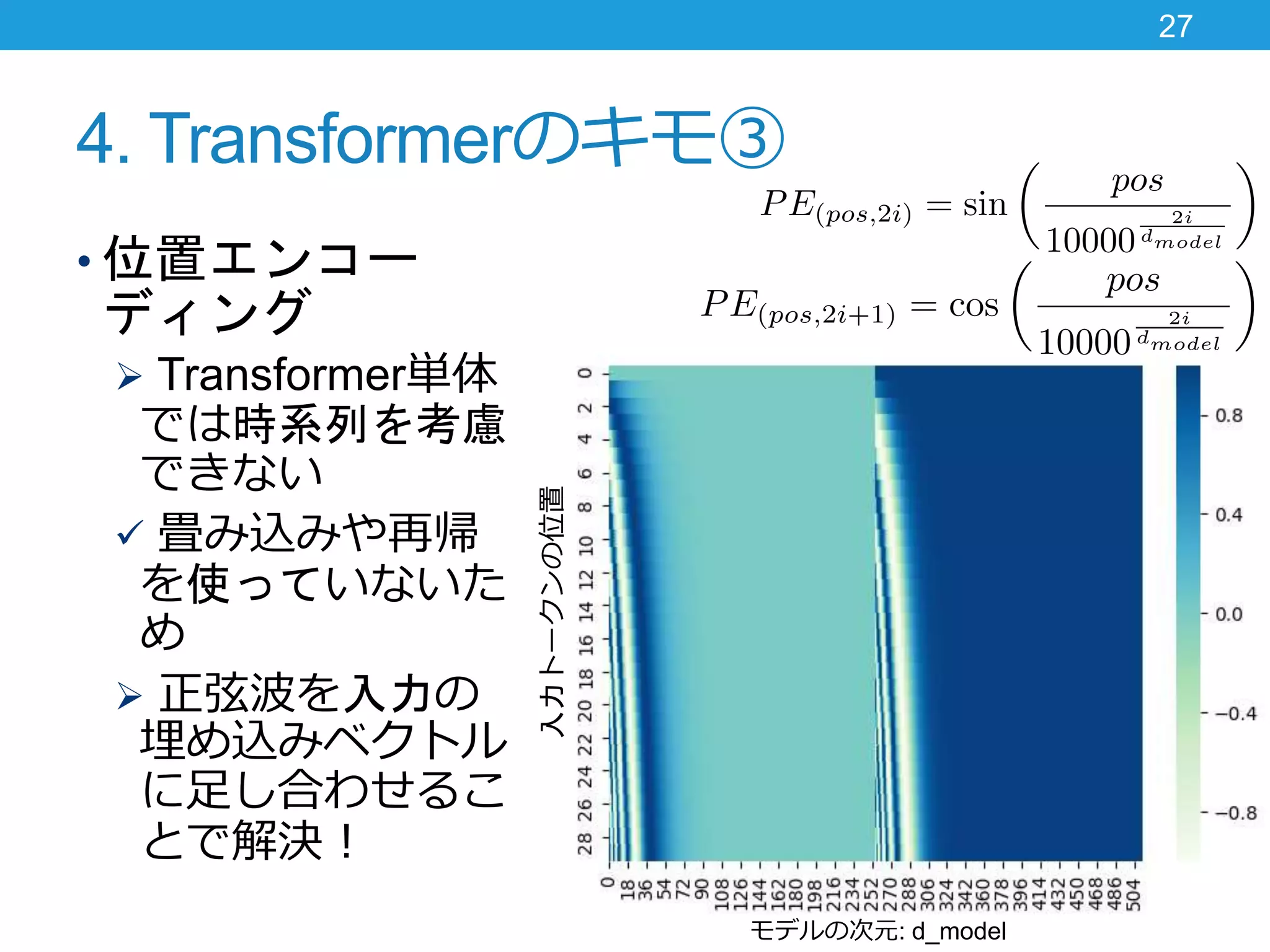
4. Transformerのキモ③ • 位置エンコー ディング
Transformer単体 では時系列を考慮 できない 畳み込みや再帰 を使っていないた め 正弦波を入力の 埋め込みベクトル に足し合わせるこ とで解決! 27 モデルの次元: d_model 入力トークンの位置
28.
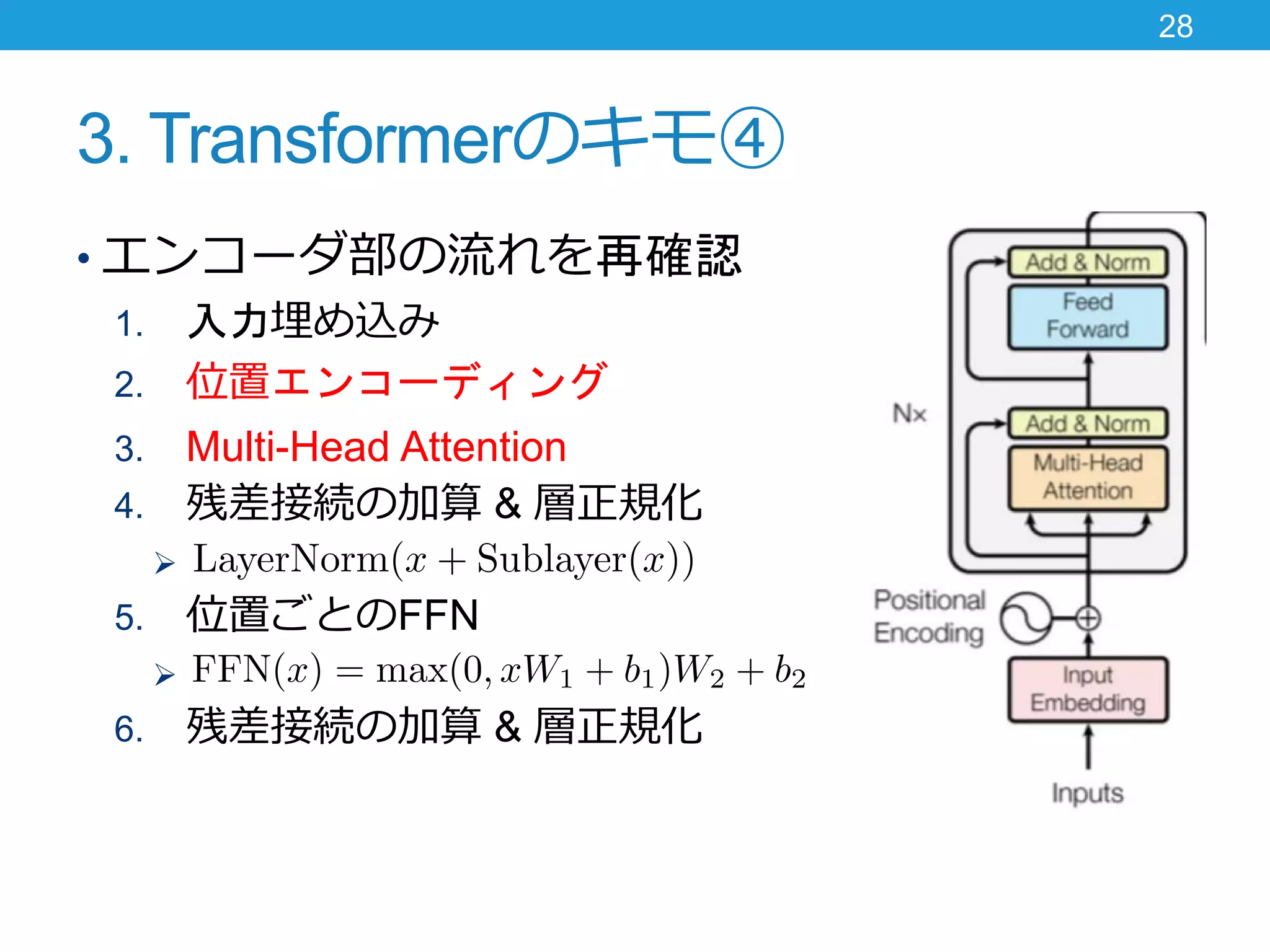
3. Transformerのキモ④ • エンコーダ部の流れを再確認 1.
入力埋め込み 2. 位置エンコーディング 3. Multi-Head Attention 4. 残差接続の加算 & 層正規化 5. 位置ごとのFFN 6. 残差接続の加算 & 層正規化 28
29.
本スライドの構成 1. NLPにおけるNNの歴史的経緯を知る 2. Attentionについて知る 3.
Transformerのモデル概要を知る 4. Transformerのキモを知る 5. 実験結果を見てみる 29
30.
5. 実験結果 1. 計算コスト比較 2.
翻訳性能比較 30
31.
5. 実験結果① 計算コスト比較 •
Self Attentionが優れている: n < dのとき 31 層あたり計算量 逐次処理を最小限にする 並列可能な計算量 依存関係の最大経路長計算コスト RecurrentとConvの算出方法がいまいちわからん?(誰か教えて)
32.
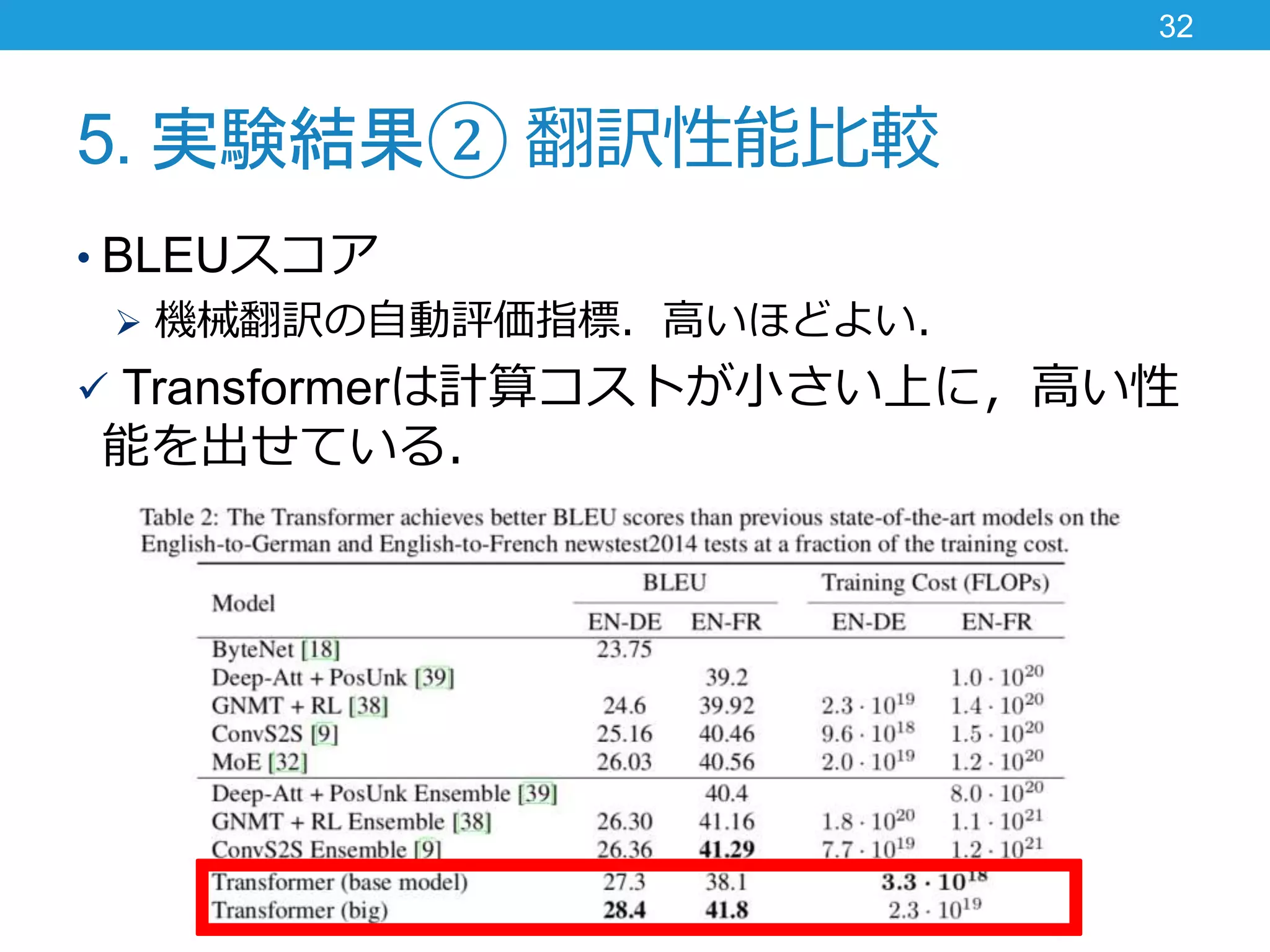
5. 実験結果② 翻訳性能比較 •
BLEUスコア 機械翻訳の自動評価指標.高いほどよい. Transformerは計算コストが小さい上に,高い性 能を出せている. 32
33.
まとめ 33
34.
まとめ • TransformerはAttention +
もろもろで作ら れた系列変換モデル Positional Encoding 位置ごとのフィードフォワード • 計算量が少ない・高性能なモデル • BERTはエンコーダ部分を活用している 34
35.
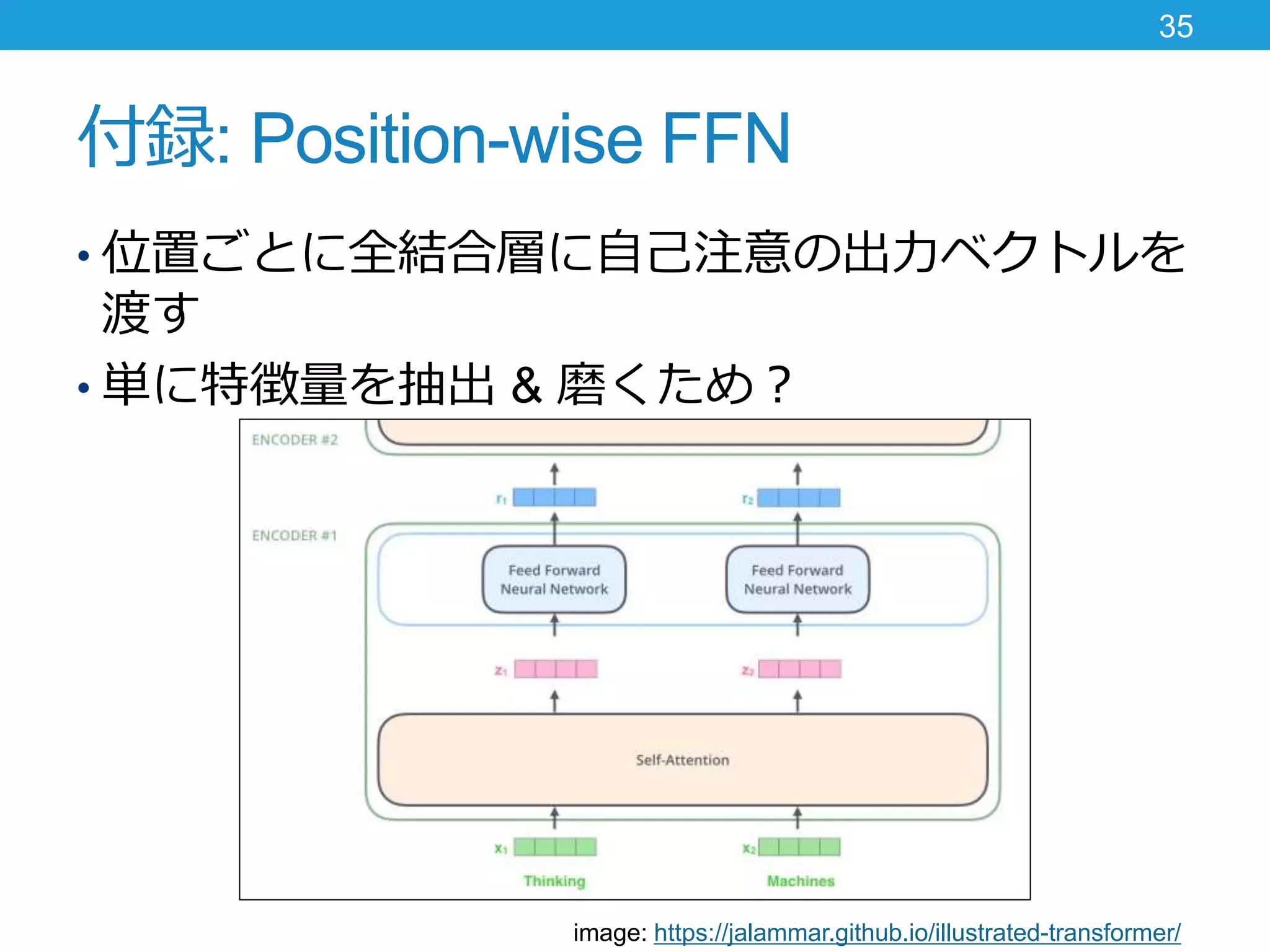
付録: Position-wise FFN •
位置ごとに全結合層に自己注意の出力ベクトルを 渡す • 単に特徴量を抽出 & 磨くため? 35 image: https://jalammar.github.io/illustrated-transformer/
36.
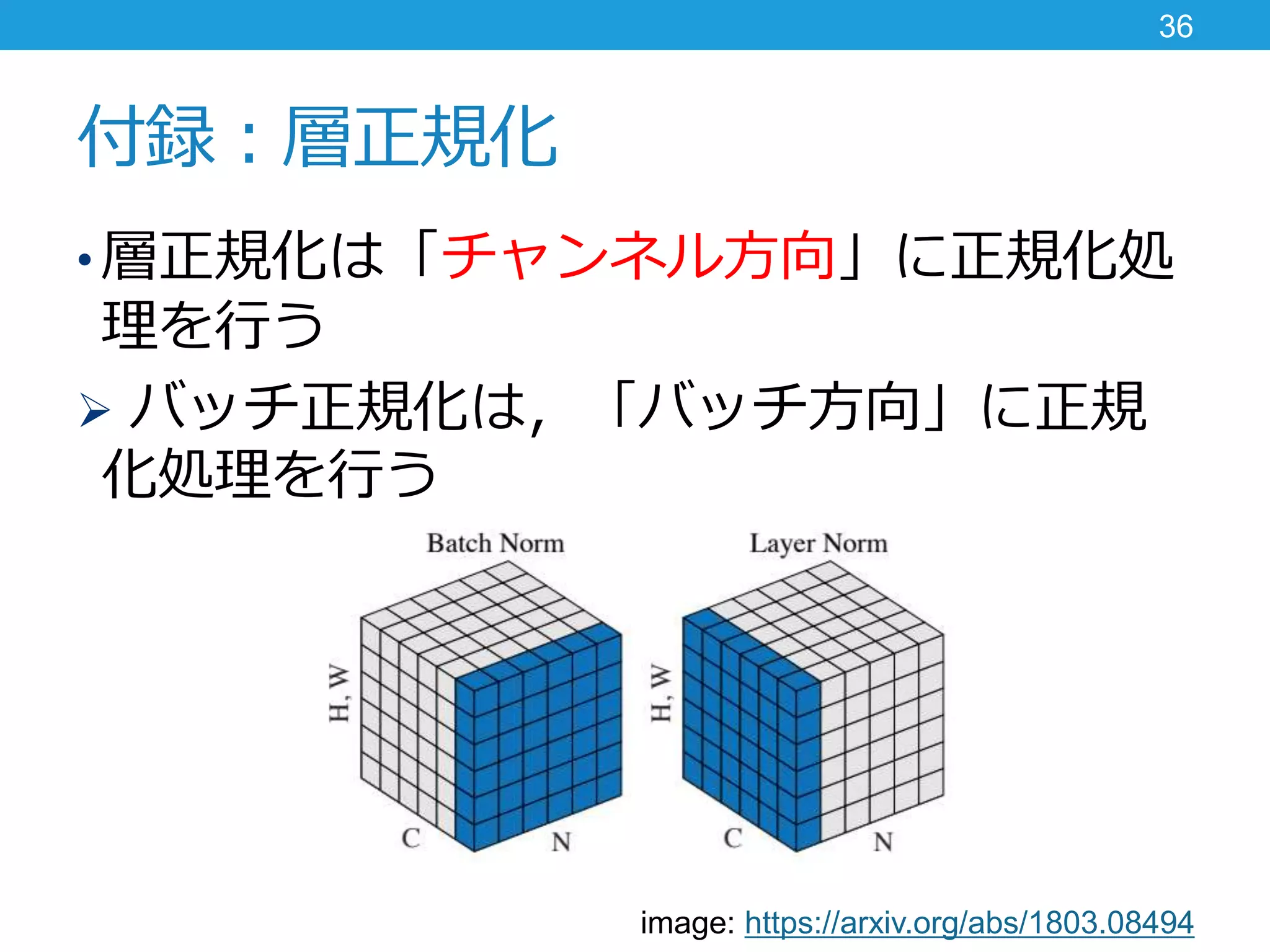
付録:層正規化 36 • 層正規化は「チャンネル方向」に正規化処 理を行う バッチ正規化は,「バッチ方向」に正規 化処理を行う image:
https://arxiv.org/abs/1803.08494
37.
付録: BLEUスコア • Bilingual
Evaluation Understudyの略 • スコアが高いほど自然な翻訳 37 • BP: brevity Penalty 翻訳文が短文のとき, その文についてペナル ティを課す • Nグラム精度 翻訳文とコーパスの参 照文がどれだけ一致し ているか
Editor's Notes
#9
距離でスケールしてしまう
#15
わかりやすいAttention written in PyTorch: https://github.com/spro/practical-pytorch/blob/master/seq2seq-translation/seq2seq-translation.ipynb 詳しくは勉強会で後々やると思います
Download






![1. NLPにおけるNNの歴史的経緯①
• 系列変換モデルは再帰ニューラルネットに
依存してきた
再帰は並列計算を妨げる
対症療法の考案:
Factorization Trick [1]やConditional Computation [2]
直接解決しているわけではない!
7
1. https://arxiv.org/abs/1703.10722
2. https://arxiv.org/abs/1511.06297
3. (image) https://jeddy92.github.io/JEddy92.github.io/ts_seq2seq_intro/](https://image.slidesharecdn.com/transformerslideshare-190523043252/75/Transformer-7-2048.jpg)


















![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)







![[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180607030706-thumbnail.jpg?width=640&height=640&fit=bounds)


![[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180606065226-thumbnail.jpg?width=640&height=640&fit=bounds)

![[FUNAI輪講] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/bert-190625044118-thumbnail.jpg?width=640&height=640&fit=bounds)

















