Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Takuya Minagawa
PDF, PPTX
5,789 views
Cvpr2017事前読み会
2017/07/08にAbejaで開催したCVPR2017事前読み会資料
Technology
◦
Related topics:
Computer Vision Insights
•
Read more
2
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 24
2
/ 24
3
/ 24
4
/ 24
5
/ 24
6
/ 24
7
/ 24
8
/ 24
9
/ 24
10
/ 24
11
/ 24
12
/ 24
13
/ 24
14
/ 24
15
/ 24
16
/ 24
17
/ 24
18
/ 24
19
/ 24
20
/ 24
21
/ 24
22
/ 24
23
/ 24
24
/ 24
More Related Content
PDF
LiDAR点群とSfM点群との位置合わせ
by
Takuya Minagawa
PDF
ORB-SLAMを動かしてみた
by
Takuya Minagawa
PDF
Pn learning takmin
by
Takuya Minagawa
PDF
cvsaisentan5 Multi View Stereo 3.3
by
Takuya Minagawa
PDF
20140131 R-CNN
by
Takuya Minagawa
PDF
20180424 orb slam
by
Takuya Minagawa
PDF
20170211クレジットカード認識
by
Takuya Minagawa
PDF
第34回CV勉強会「コンピュテーショナルフォトグラフィ」発表資料
by
Takuya Minagawa
LiDAR点群とSfM点群との位置合わせ
by
Takuya Minagawa
ORB-SLAMを動かしてみた
by
Takuya Minagawa
Pn learning takmin
by
Takuya Minagawa
cvsaisentan5 Multi View Stereo 3.3
by
Takuya Minagawa
20140131 R-CNN
by
Takuya Minagawa
20180424 orb slam
by
Takuya Minagawa
20170211クレジットカード認識
by
Takuya Minagawa
第34回CV勉強会「コンピュテーショナルフォトグラフィ」発表資料
by
Takuya Minagawa
What's hot
PDF
How to feed myself with computer vision
by
Takuya Minagawa
PDF
LiDAR点群と画像とのマッピング
by
Takuya Minagawa
PDF
20160417dlibによる顔器官検出
by
Takuya Minagawa
PDF
Curiosity driven exploration
by
Takuya Minagawa
PDF
run Keras model on opencv
by
Takuya Minagawa
PDF
20170806 Discriminative Optimization
by
Takuya Minagawa
PDF
Show and tell takmin
by
Takuya Minagawa
PDF
[CV勉強会]Active Object Localization with Deep Reinfocement Learning
by
Takuya Minagawa
PDF
20200910コンピュータビジョン今昔物語(JPTA講演資料)
by
Takuya Minagawa
PDF
BERT の解剖学: interpret-text による自然言語処理 (NLP) モデル解釈
by
順也 山口
PDF
2021 10-07 kdd2021読み会 uc phrase
by
Tatsuya Shirakawa
PDF
NeurIPS2021読み会 Fairness in Ranking under Uncertainty
by
Tatsuya Shirakawa
PDF
日本ソフトウェア科学会第36回大会発表資料「帰納的プログラミングの初等教育の試み」西澤勇輝
by
Preferred Networks
PDF
ICCV2019 report
by
Tatsuya Shirakawa
PDF
DeepLearningフレームワークChainerの学習済みモデルをスマートフォンにDeployする
by
tomohiro kato
PPTX
DeNAにおける先端AI技術活用のチャレンジ
by
Yusuke Uchida
PDF
東北大学 先端技術の基礎と実践_深層学習による画像認識とデータの話_菊池悠太
by
Preferred Networks
PPTX
視覚と対話の融合研究
by
Yoshitaka Ushiku
PPTX
ロボットアームをPythonで動かす
by
Core Concept Technologies
PPTX
ドライブレコーダ映像からの3次元空間認識 [MOBILITY:dev]
by
DeNA
How to feed myself with computer vision
by
Takuya Minagawa
LiDAR点群と画像とのマッピング
by
Takuya Minagawa
20160417dlibによる顔器官検出
by
Takuya Minagawa
Curiosity driven exploration
by
Takuya Minagawa
run Keras model on opencv
by
Takuya Minagawa
20170806 Discriminative Optimization
by
Takuya Minagawa
Show and tell takmin
by
Takuya Minagawa
[CV勉強会]Active Object Localization with Deep Reinfocement Learning
by
Takuya Minagawa
20200910コンピュータビジョン今昔物語(JPTA講演資料)
by
Takuya Minagawa
BERT の解剖学: interpret-text による自然言語処理 (NLP) モデル解釈
by
順也 山口
2021 10-07 kdd2021読み会 uc phrase
by
Tatsuya Shirakawa
NeurIPS2021読み会 Fairness in Ranking under Uncertainty
by
Tatsuya Shirakawa
日本ソフトウェア科学会第36回大会発表資料「帰納的プログラミングの初等教育の試み」西澤勇輝
by
Preferred Networks
ICCV2019 report
by
Tatsuya Shirakawa
DeepLearningフレームワークChainerの学習済みモデルをスマートフォンにDeployする
by
tomohiro kato
DeNAにおける先端AI技術活用のチャレンジ
by
Yusuke Uchida
東北大学 先端技術の基礎と実践_深層学習による画像認識とデータの話_菊池悠太
by
Preferred Networks
視覚と対話の融合研究
by
Yoshitaka Ushiku
ロボットアームをPythonで動かす
by
Core Concept Technologies
ドライブレコーダ映像からの3次元空間認識 [MOBILITY:dev]
by
DeNA
Viewers also liked
PPTX
CVPR2017 参加報告 速報版 本会議 1日目
by
Atsushi Hashimoto
PDF
ICCV2017一人読み会
by
Fujimoto Keisuke
PPTX
CVPR2017 参加報告 速報版 本会議3日目
by
Atsushi Hashimoto
PPTX
こまった時のOpenJump(デジタイジング編)
by
IWASAKI NOBUSUKE
DOCX
FOSS4Gで地理院タイルを使ってみよう!
by
IWASAKI NOBUSUKE
PDF
Building GUI App with Electron and Lisp
by
fukamachi
PDF
Semantic segmentation2
by
Takuya Minagawa
PDF
Semantic segmentation
by
Takuya Minagawa
PDF
ドライバハッキング。UMPC、Windowsタブレット にLinux、*BSDを入れて遊ぼう 2017年度京都版 #osckyoto
by
Netwalker lab kapper
PDF
Hacking with x86 Windows Tablet and mobile devices on openSUSE #opensuseasia17
by
Netwalker lab kapper
PDF
ECCV 2016 速報
by
Hirokatsu Kataoka
PDF
ICCV 2017 速報
by
cvpaper. challenge
CVPR2017 参加報告 速報版 本会議 1日目
by
Atsushi Hashimoto
ICCV2017一人読み会
by
Fujimoto Keisuke
CVPR2017 参加報告 速報版 本会議3日目
by
Atsushi Hashimoto
こまった時のOpenJump(デジタイジング編)
by
IWASAKI NOBUSUKE
FOSS4Gで地理院タイルを使ってみよう!
by
IWASAKI NOBUSUKE
Building GUI App with Electron and Lisp
by
fukamachi
Semantic segmentation2
by
Takuya Minagawa
Semantic segmentation
by
Takuya Minagawa
ドライバハッキング。UMPC、Windowsタブレット にLinux、*BSDを入れて遊ぼう 2017年度京都版 #osckyoto
by
Netwalker lab kapper
Hacking with x86 Windows Tablet and mobile devices on openSUSE #opensuseasia17
by
Netwalker lab kapper
ECCV 2016 速報
by
Hirokatsu Kataoka
ICCV 2017 速報
by
cvpaper. challenge
Similar to Cvpr2017事前読み会
PDF
CVPR 2018 速報
by
cvpaper. challenge
PDF
コンピュータビジョンの今を映す-CVPR 2017 速報より- (夏のトップカンファレンス論文読み会)
by
cvpaper. challenge
PPTX
CVPR 2017 報告
by
Yu Nishimura
PDF
cvpaper.challenge -CVの動向とこれからの問題を作るために- (東京大学講演)
by
cvpaper. challenge
PDF
CVPR 2017 速報
by
cvpaper. challenge
PDF
【2016.09】cvpaper.challenge2016
by
cvpaper. challenge
PDF
cvpaper.challenge in CVPR2015 (PRMU2015年12月)
by
cvpaper. challenge
PDF
CVPR 2018 速報とその後 (CVPR 2018 完全読破チャレンジ報告会)
by
cvpaper. challenge
PDF
CVPR 2016 速報
by
Hirokatsu Kataoka
PDF
CVPR 2019 速報
by
cvpaper. challenge
PDF
優れた問いを見つける(中京大学講演)
by
cvpaper. challenge
PDF
CVPR 2020報告
by
日本ディープラーニング協会(JDLA)
PDF
CVPR2017/ICCV2017から見た研究動向(名古屋CV・PRML勉強会)
by
cvpaper. challenge
PDF
CVPR2019読み会@関東CV
by
Takanori Ogata
PPTX
Eccv2018 report day3
by
Atsushi Hashimoto
PDF
cvpaper.challenge チームラボ講演
by
cvpaper. challenge
PDF
cvpaper.challenge -サーベイの共有と可能性について- (画像応用技術専門委員会研究会 2016年7月)
by
cvpaper. challenge
PDF
【2016.01】(2/3)cvpaper.challenge2016
by
cvpaper. challenge
PDF
【2015.05】cvpaper.challenge@CVPR2015
by
cvpaper. challenge
PDF
CVPR 2016 まとめ v1
by
cvpaper. challenge
CVPR 2018 速報
by
cvpaper. challenge
コンピュータビジョンの今を映す-CVPR 2017 速報より- (夏のトップカンファレンス論文読み会)
by
cvpaper. challenge
CVPR 2017 報告
by
Yu Nishimura
cvpaper.challenge -CVの動向とこれからの問題を作るために- (東京大学講演)
by
cvpaper. challenge
CVPR 2017 速報
by
cvpaper. challenge
【2016.09】cvpaper.challenge2016
by
cvpaper. challenge
cvpaper.challenge in CVPR2015 (PRMU2015年12月)
by
cvpaper. challenge
CVPR 2018 速報とその後 (CVPR 2018 完全読破チャレンジ報告会)
by
cvpaper. challenge
CVPR 2016 速報
by
Hirokatsu Kataoka
CVPR 2019 速報
by
cvpaper. challenge
優れた問いを見つける(中京大学講演)
by
cvpaper. challenge
CVPR 2020報告
by
日本ディープラーニング協会(JDLA)
CVPR2017/ICCV2017から見た研究動向(名古屋CV・PRML勉強会)
by
cvpaper. challenge
CVPR2019読み会@関東CV
by
Takanori Ogata
Eccv2018 report day3
by
Atsushi Hashimoto
cvpaper.challenge チームラボ講演
by
cvpaper. challenge
cvpaper.challenge -サーベイの共有と可能性について- (画像応用技術専門委員会研究会 2016年7月)
by
cvpaper. challenge
【2016.01】(2/3)cvpaper.challenge2016
by
cvpaper. challenge
【2015.05】cvpaper.challenge@CVPR2015
by
cvpaper. challenge
CVPR 2016 まとめ v1
by
cvpaper. challenge
More from Takuya Minagawa
PDF
R-SCoRe: Revisiting Scene Coordinate Regression for Robust Large-Scale Visual...
by
Takuya Minagawa
PDF
「第63回コンピュータビジョン勉強会@関東」発表資料 CVの社会実装について考えていたらゲームを作っていた話
by
Takuya Minagawa
PDF
第61回CV勉強会「CVPR2024読み会」(前編)発表資料:State Space Models for Event Cameras
by
Takuya Minagawa
PDF
ろくに電子工作もしたことない人間がIoT用ミドルウェアを作った話(IoTLT vol112 発表資料)
by
Takuya Minagawa
PDF
Machine Learning Operations (MLOps): Overview, Definition, and Architecture
by
Takuya Minagawa
PDF
MobileNeRF
by
Takuya Minagawa
PDF
点群SegmentationのためのTransformerサーベイ
by
Takuya Minagawa
PDF
Learning to Solve Hard Minimal Problems
by
Takuya Minagawa
PDF
ConditionalPointDiffusion.pdf
by
Takuya Minagawa
PDF
楽しいコンピュータビジョンの受託仕事
by
Takuya Minagawa
PDF
20210711 deepI2P
by
Takuya Minagawa
PDF
20201010 personreid
by
Takuya Minagawa
PDF
2020/07/04 BSP-Net (CVPR2020)
by
Takuya Minagawa
PDF
20200704 bsp net
by
Takuya Minagawa
PDF
20190825 vins mono
by
Takuya Minagawa
PDF
20190706cvpr2019_3d_shape_representation
by
Takuya Minagawa
PDF
20190307 visualslam summary
by
Takuya Minagawa
PDF
Visual slam
by
Takuya Minagawa
PDF
20190131 lidar-camera fusion semantic segmentation survey
by
Takuya Minagawa
PDF
2018/12/28 LiDARで取得した道路上点群に対するsemantic segmentation
by
Takuya Minagawa
R-SCoRe: Revisiting Scene Coordinate Regression for Robust Large-Scale Visual...
by
Takuya Minagawa
「第63回コンピュータビジョン勉強会@関東」発表資料 CVの社会実装について考えていたらゲームを作っていた話
by
Takuya Minagawa
第61回CV勉強会「CVPR2024読み会」(前編)発表資料:State Space Models for Event Cameras
by
Takuya Minagawa
ろくに電子工作もしたことない人間がIoT用ミドルウェアを作った話(IoTLT vol112 発表資料)
by
Takuya Minagawa
Machine Learning Operations (MLOps): Overview, Definition, and Architecture
by
Takuya Minagawa
MobileNeRF
by
Takuya Minagawa
点群SegmentationのためのTransformerサーベイ
by
Takuya Minagawa
Learning to Solve Hard Minimal Problems
by
Takuya Minagawa
ConditionalPointDiffusion.pdf
by
Takuya Minagawa
楽しいコンピュータビジョンの受託仕事
by
Takuya Minagawa
20210711 deepI2P
by
Takuya Minagawa
20201010 personreid
by
Takuya Minagawa
2020/07/04 BSP-Net (CVPR2020)
by
Takuya Minagawa
20200704 bsp net
by
Takuya Minagawa
20190825 vins mono
by
Takuya Minagawa
20190706cvpr2019_3d_shape_representation
by
Takuya Minagawa
20190307 visualslam summary
by
Takuya Minagawa
Visual slam
by
Takuya Minagawa
20190131 lidar-camera fusion semantic segmentation survey
by
Takuya Minagawa
2018/12/28 LiDARで取得した道路上点群に対するsemantic segmentation
by
Takuya Minagawa
Recently uploaded
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
Cvpr2017事前読み会
1.
CVPR2017事前読み会 2017/07/08 皆川卓也(@takmin)
2.
本資料について CVPR2017 paper
on the web上のタイトルを眺めて、面白 そうなやつを適当にピックアップ http://www.cvpapers.com/cvpr2017.html 選んだ論文に共有のテーマとか一貫性とかは特にない。 今回は1本を深く読むよりも、広く浅く と思ったら広くない。 最初は10本くらいやるつもりが、結局5本。。。 単純に読んだ順番で並べただけ
3.
自己紹介 3 テクニカル・ソリューション・アーキテクト 皆川 卓也(みながわ たくや) フリーエンジニア(ビジョン&ITラボ) 「コンピュータビジョン勉強会@関東」主催 博士(工学) 略歴: 1999-2003年 日本HP(後にアジレント・テクノロジーへ分社)にて、ITエンジニアとしてシステム構築、プリ セールス、プロジェクトマネジメント、サポート等の業務に従事 2004-2009年 コンピュータビジョンを用いたシステム/アプリ/サービス開発等に従事 2007-2010年 慶應義塾大学大学院
後期博士課程にて、コンピュータビジョンを専攻 単位取得退学後、博士号取得(2014年) 2009年-現在 フリーランスとして、コンピュータビジョンのコンサル/研究/開発等に従事 http://visitlab.jp
4.
Network Dissection Network Dissection:
Quantifying Interpretability of DeepVisual Representations David Bau, Bolei Zhou,Aditya Khosla,Aude Oliva, and AntonioTorralba 概要 画像解析を行うCNNの隠れ層がどのような 「意味」と関連付けられているかを解析するた めのフレームワークを提案
5.
Network Dissection 手法
Broden (Broadly and Densely Labbeled Dataset)という様々なコンセ プトをラベル付けしたデータセットと学習済みCNNモデルの各隠れ 層ユニットの反応との関係を見ることで、ユニットが持つ「意味」を解 析
6.
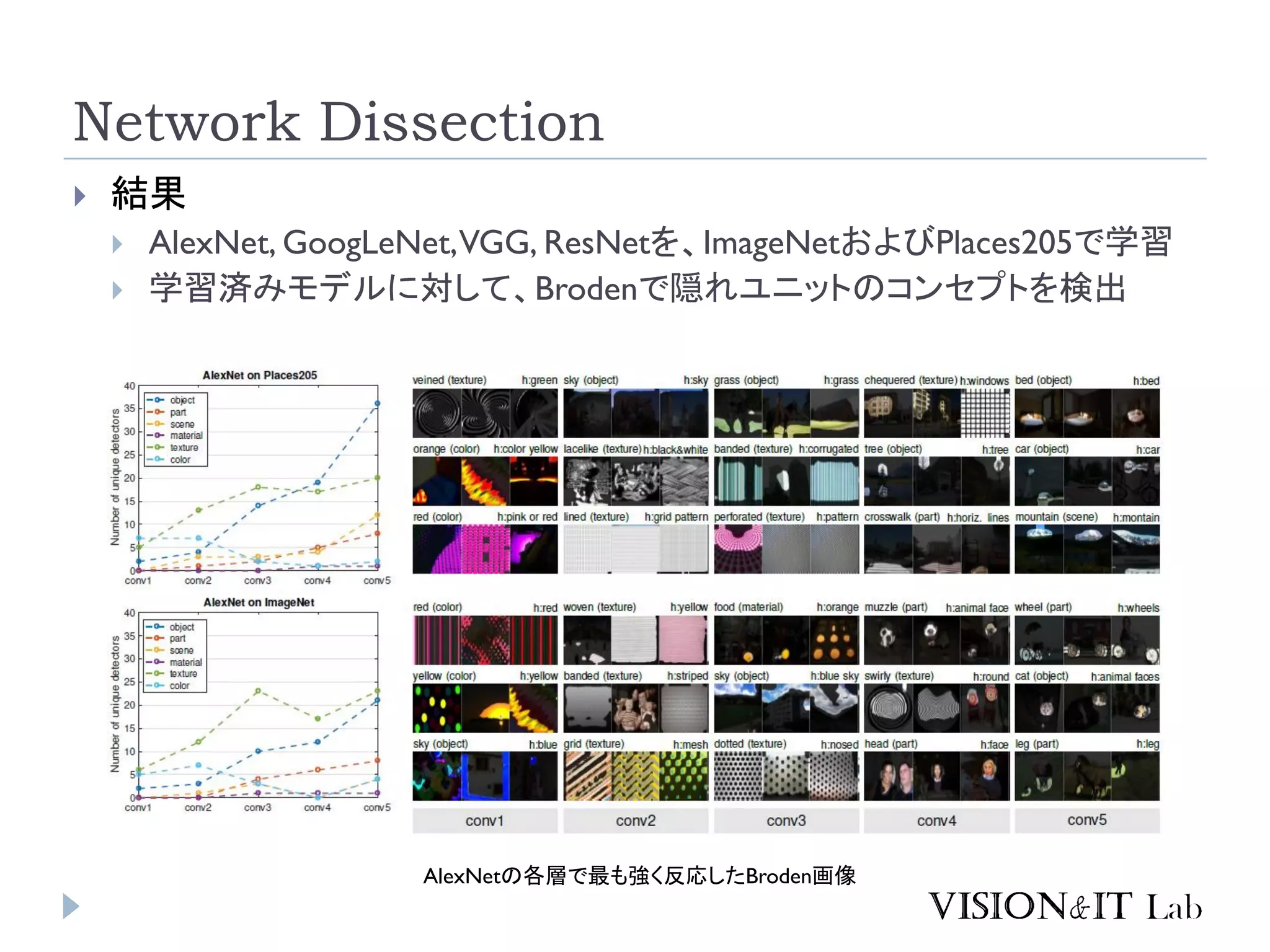
Network Dissection 結果
AlexNet, GoogLeNet,VGG, ResNetを、ImageNetおよびPlaces205で学習 学習済みモデルに対して、Brodenで隠れユニットのコンセプトを検出 AlexNetの各層で最も強く反応したBroden画像
7.
Network Dissection 結果
AlexNet, GoogLeNet,VGG, ResNetを、ImageNetおよびPlaces205で学習 学習済みモデルに対して、Brodenで隠れユニットのコンセプトを検出 Places205を学習させたVGG, GoogLeNet, ResNetの各ネットワークで、あるコンセプトに最も強く反応した2つのユニット における検出結果例
8.
Semantic Scene Completion Semantic
Scene Completion from a Single Depth Image Shuran Song, FisherYu,Andy Zeng,Angel X. Chang, Manolis Savva,Thomas Funkhouser 概要 1枚の深度画像から、ボクセ ル空間を生成するScene Completionと、各ボクセル にラベル付けを行う Semantic Segmentationを「同 時に」行うSemantic Scene Completion Network (SSCNet)を提案
9.
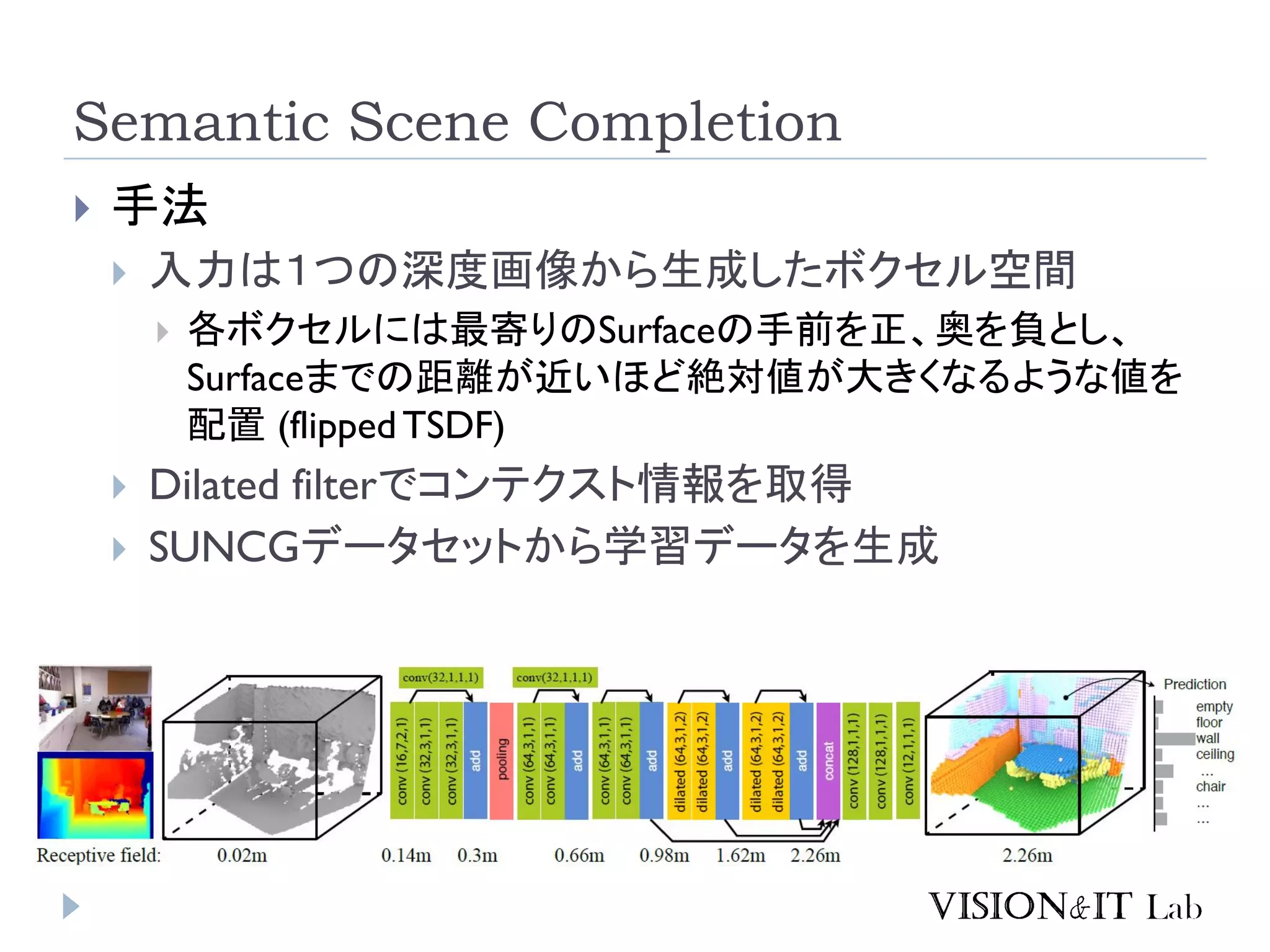
Semantic Scene Completion
手法 入力は1つの深度画像から生成したボクセル空間 各ボクセルには最寄りのSurfaceの手前を正、奥を負とし、 Surfaceまでの距離が近いほど絶対値が大きくなるような値を 配置 (flippedTSDF) Dilated filterでコンテクスト情報を取得 SUNCGデータセットから学習データを生成
10.
Semantic Scene Completion
実験 Scene CompletionとSemantic Segmentationを同時に行う方が 個別に行うよりうまくいく
11.
Context-Aware Correlation Filter
Tracking Context-Aware Correlation Filter Tracking Matthias Mueller, Neil Smith, Bernard Ghanem 概要 追跡対象の周辺の情報をNegative Sampleとして加えることで、 Contextも考慮したCorrelation Filterを作成するフレームワー クを提案 従来のCorrelation Filterに関する関連研究は、より強力な特 徴量を使用するものがほとんど
12.
Context-Aware Correlation Filter
Tracking 従来手法 Correlation Filter 目的関数 目的関数の解は周波数ドメインで以下のように求まる 目的画像𝒂0を 巡回させた行列 求める フィルタ 物体の 場所 正則化項 入力画像𝒂0の複 素共役𝒂0 ∗ を離散 フーリエ変換 要素ごとの積
13.
Context-Aware Correlation Filter
Tracking 手法 Context-Aware Correlation Filter 目的関数 目的関数の解は周波数ドメインで以下のように求まる 背景パッチ 画像の巡回 行列 論文ではこの手法をカーネルを使用した場合や、Multi Channel (HOG等の特徴を使用する場合など)に拡張して いるが、ここでは割愛。
14.
Context-Aware Correlation Filter
Tracking 結果 4つの従来法にContext-Awareを追加してOTB-100データセットで比 較
15.
Context-Aware Correlation Filter
Tracking 結果動画 https://www.youtube.com/watch?v=-mEkFAAag2Q (1:24くらいから)
16.
Feature Pyramid Networks Feature
Pyramid Networks for Object Detection Tsung-Yi Lin, Piotr Dollar, Ross Girshick 概要 Deep CNNに対しわず かな追加コストでFeature Pyramidを生成する手法 を提案 Hand-crafted特徴の物体 検出では一般的 CNNによる物体検出で は、計算コストとメモリの 点からFeature Pyramid生 成は避けられてきた
17.
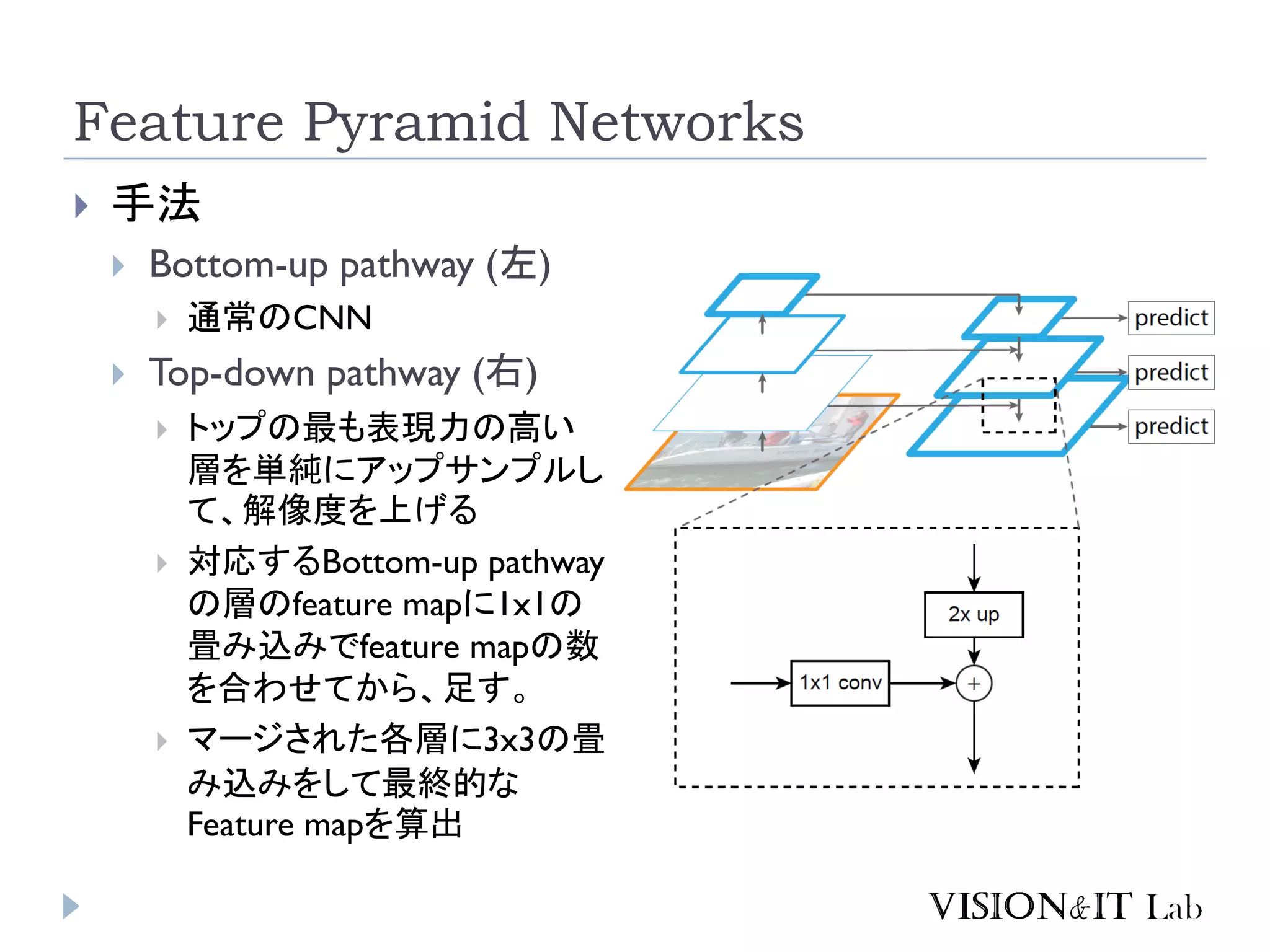
Feature Pyramid Networks
手法 Bottom-up pathway (左) 通常のCNN Top-down pathway (右) トップの最も表現力の高い 層を単純にアップサンプルし て、解像度を上げる 対応するBottom-up pathway の層のfeature mapに1x1の 畳み込みでfeature mapの数 を合わせてから、足す。 マージされた各層に3x3の畳 み込みをして最終的な Feature mapを算出
18.
Feature Pyramid Networks
実験 Bottom-upはResNets 各スケールのFeature Map上でFaster R-CNNで検出 COCO (single model)でstate-of-the-artを達成
19.
Real-time tracking from
depth-colour imagery Real-time tracking of single and multiple objects from depth- colour imagery using 3D signed distance functions C.Y. Ren,V.A.Prisacariu, O.Kahler, I.D.Reid, D.W.Murray 概要 RGB-Dカメラを用いて物体を3Dでリアルタイム追跡
20.
Real-time tracking from
depth-colour imagery 手法 ベイズモデルで物体の位置/姿勢をMAP推定 追跡対象周辺のボクセルを表面からの距離関数φでモデル化
21.
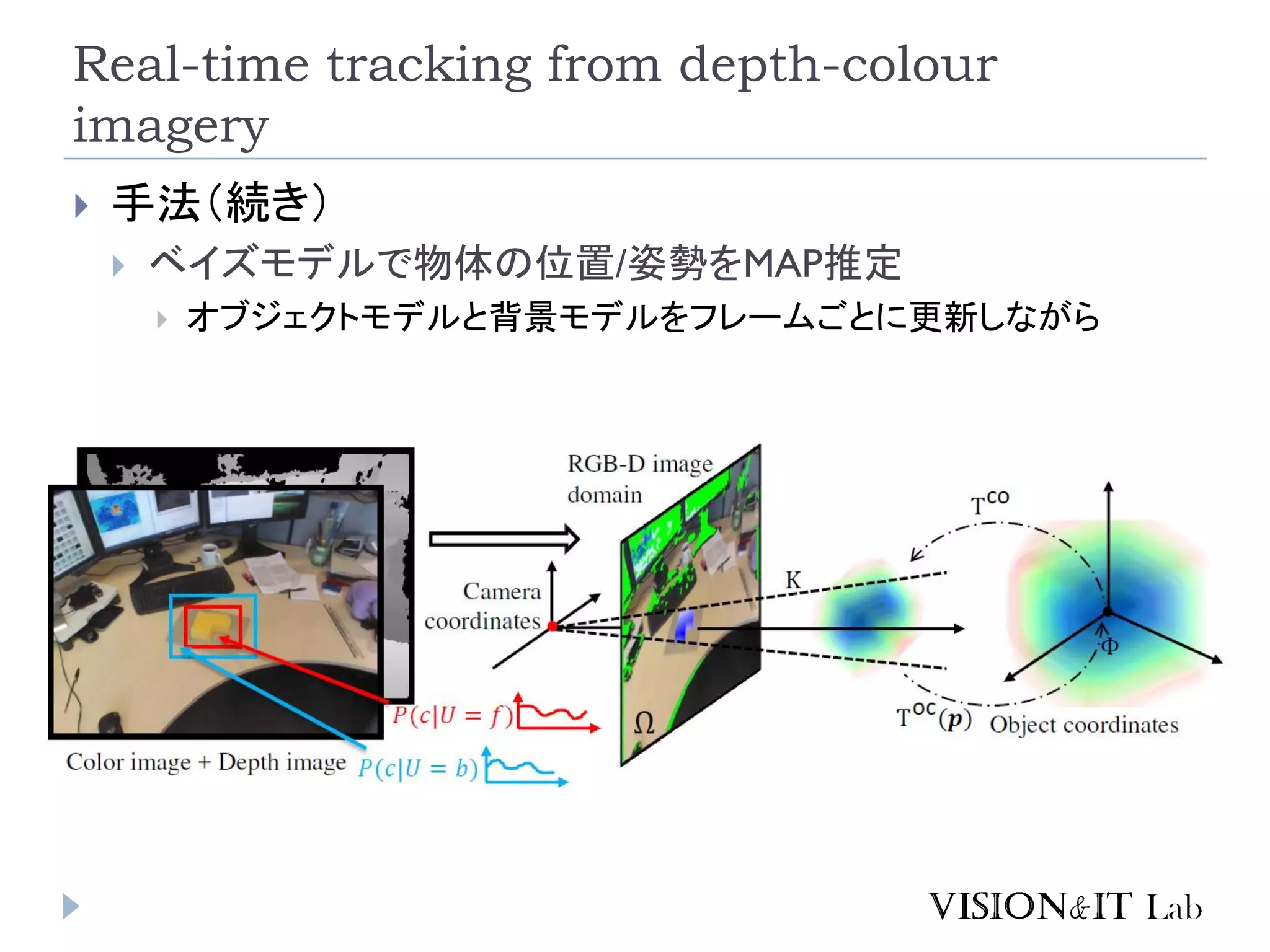
Real-time tracking from
depth-colour imagery 手法(続き) ベイズモデルで物体の位置/姿勢をMAP推定 オブジェクトモデルと背景モデルをフレームごとに更新しながら
22.
Real-time tracking from
depth-colour imagery 手法(続き) ベイズモデルで物体の位置/姿勢をMAP推定 Levenberg-Marquart法 前景モデル (色ヒストグラム) 背景モデル (色ヒストグラム) モデルΩ上の点を姿勢pに 基づいて投影した位置に 反応するデルタ関数 モデルΩ上の周辺の点を姿 勢pに基づいて投影した位 置に反応するデルタ関数
23.
Real-time tracking from
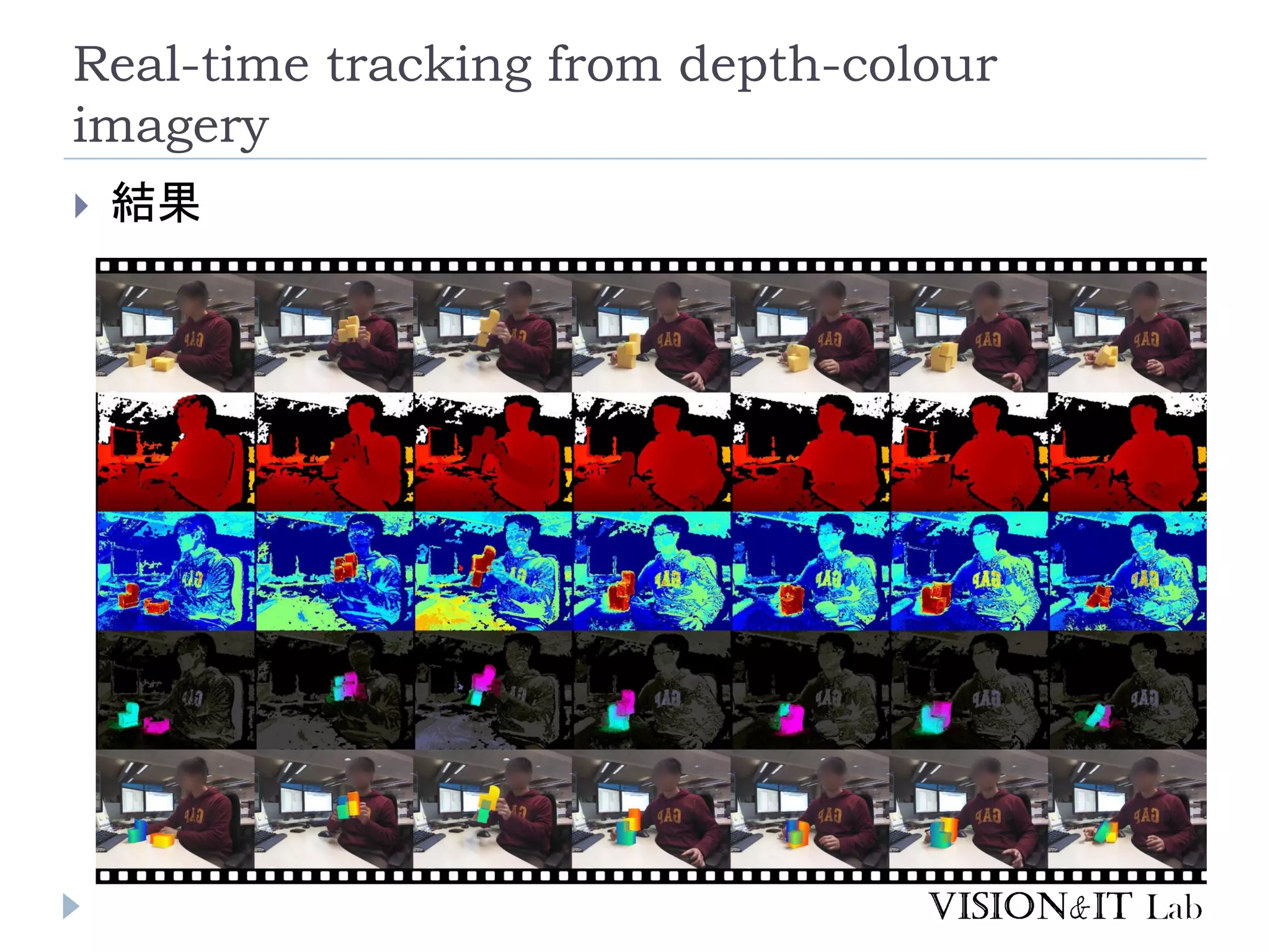
depth-colour imagery 結果
24.
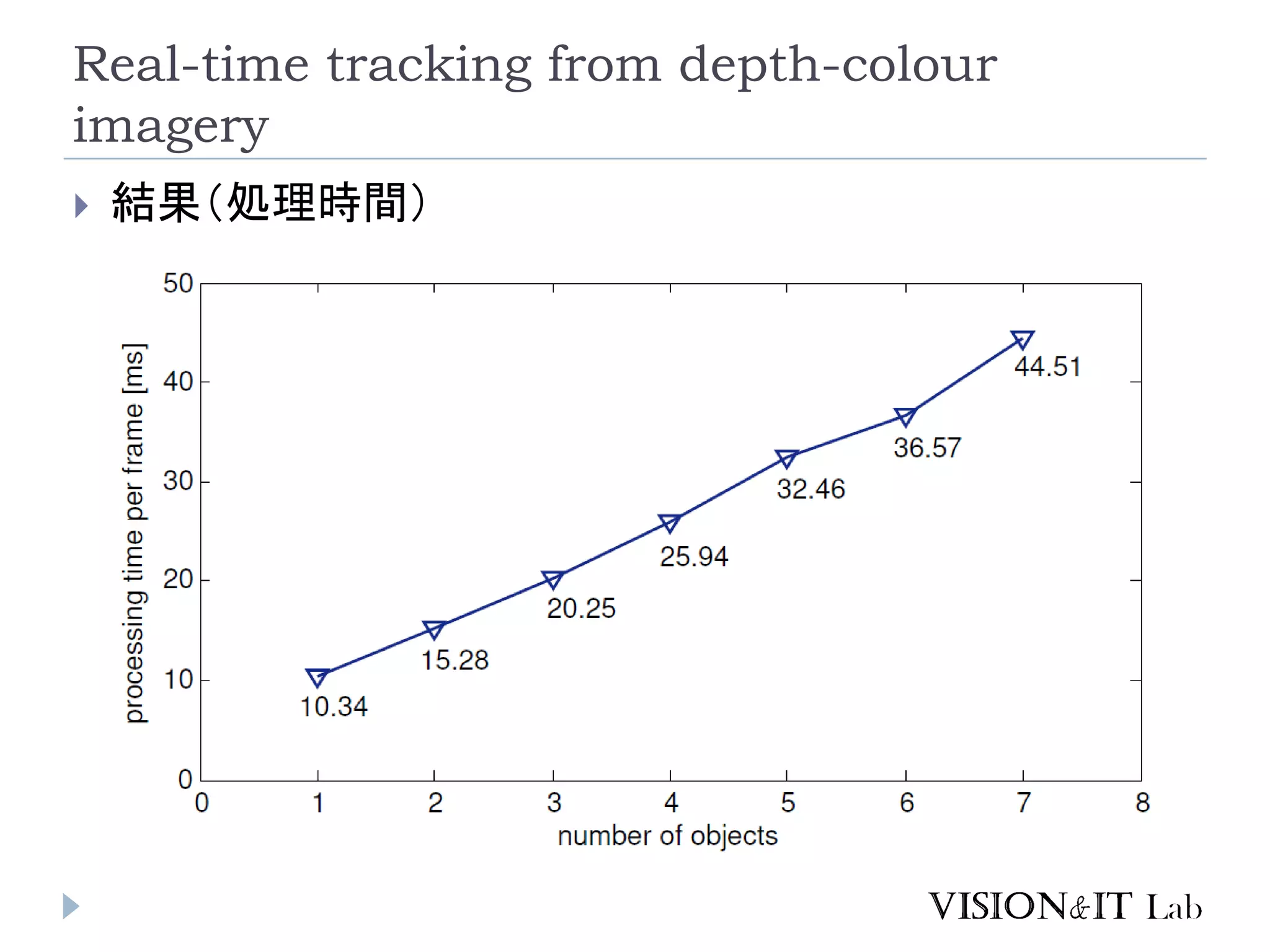
Real-time tracking from
depth-colour imagery 結果(処理時間)
Download


































![[CV勉強会]Active Object Localization with Deep Reinfocement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20160204objectdetectionrl-160206032348-thumbnail.jpg?width=640&height=640&fit=bounds)











![ドライブレコーダ映像からの3次元空間認識 [MOBILITY:dev]](https://cdn.slidesharecdn.com/ss_thumbnails/20191031mobilitydevmiyazawa-191031085336-thumbnail.jpg?width=640&height=640&fit=bounds)

























































