Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Yoshinari Fujinuma
PDF, PPTX
8,417 views
言語モデル入門 (第二版)
Introduction to language models in Japanese
Technology
◦
Read more
7
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 33
2
/ 33
3
/ 33
4
/ 33
5
/ 33
6
/ 33
7
/ 33
8
/ 33
9
/ 33
10
/ 33
11
/ 33
12
/ 33
13
/ 33
14
/ 33
15
/ 33
16
/ 33
17
/ 33
18
/ 33
19
/ 33
20
/ 33
21
/ 33
22
/ 33
23
/ 33
24
/ 33
25
/ 33
26
/ 33
27
/ 33
28
/ 33
29
/ 33
30
/ 33
31
/ 33
32
/ 33
33
/ 33
More Related Content
PDF
組合せ最適化入門:線形計画から整数計画まで
by
Shunji Umetani
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
PDF
最適化超入門
by
Takami Sato
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
PPTX
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PDF
1 6.変数選択とAIC
by
logics-of-blue
PPTX
[DL輪読会]Neural Ordinary Differential Equations
by
Deep Learning JP
組合せ最適化入門:線形計画から整数計画まで
by
Shunji Umetani
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
最適化超入門
by
Takami Sato
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
1 6.変数選択とAIC
by
logics-of-blue
[DL輪読会]Neural Ordinary Differential Equations
by
Deep Learning JP
What's hot
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PDF
[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions
by
Deep Learning JP
KEY
アンサンブル学習
by
Hidekazu Tanaka
PDF
深層生成モデルと世界モデル
by
Masahiro Suzuki
PDF
[DL輪読会]ICLR2020の分布外検知速報
by
Deep Learning JP
PDF
SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜
by
SSII
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PDF
Attentionの基礎からTransformerの入門まで
by
AGIRobots
PDF
正準相関分析
by
Akisato Kimura
PDF
最適輸送入門
by
joisino
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PPTX
[研究室論文紹介用スライド] Adversarial Contrastive Estimation
by
Makoto Takenaka
PDF
計算論的学習理論入門 -PAC学習とかVC次元とか-
by
sleepy_yoshi
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PPTX
モデル高速化百選
by
Yusuke Uchida
PPTX
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
PPTX
【DL輪読会】An Image is Worth One Word: Personalizing Text-to-Image Generation usi...
by
Deep Learning JP
PDF
3DFeat-Net
by
Takuya Minagawa
PDF
【メタサーベイ】Transformerから基盤モデルまでの流れ / From Transformer to Foundation Models
by
cvpaper. challenge
PDF
Optimizer入門&最新動向
by
Motokawa Tetsuya
機械学習モデルの判断根拠の説明
by
Satoshi Hara
[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions
by
Deep Learning JP
アンサンブル学習
by
Hidekazu Tanaka
深層生成モデルと世界モデル
by
Masahiro Suzuki
[DL輪読会]ICLR2020の分布外検知速報
by
Deep Learning JP
SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜
by
SSII
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
Attentionの基礎からTransformerの入門まで
by
AGIRobots
正準相関分析
by
Akisato Kimura
最適輸送入門
by
joisino
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
[研究室論文紹介用スライド] Adversarial Contrastive Estimation
by
Makoto Takenaka
計算論的学習理論入門 -PAC学習とかVC次元とか-
by
sleepy_yoshi
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
モデル高速化百選
by
Yusuke Uchida
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
【DL輪読会】An Image is Worth One Word: Personalizing Text-to-Image Generation usi...
by
Deep Learning JP
3DFeat-Net
by
Takuya Minagawa
【メタサーベイ】Transformerから基盤モデルまでの流れ / From Transformer to Foundation Models
by
cvpaper. challenge
Optimizer入門&最新動向
by
Motokawa Tetsuya
Similar to 言語モデル入門 (第二版)
PDF
言語モデル入門
by
Yoshinari Fujinuma
PDF
100816 nlpml sec2
by
shirakia
PDF
TensorFlow math ja 05 word2vec
by
Shin Asakawa
PDF
大規模日本語ブログコーパスにおける言語モデルの構築と評価
by
Yahoo!デベロッパーネットワーク
PDF
Extract and edit
by
禎晃 山崎
PDF
I
by
SOINN Inc.
PPTX
未出現事象の出現確率
by
Hiroshi Nakagawa
PDF
言語資源と付き合う
by
Yuya Unno
PPTX
Machine Learning Seminar (5)
by
Tomoya Nakayama
PPT
ACLreading2014@Ace12358
by
Ace12358
PDF
STAIR Lab Seminar 202105
by
Sho Takase
PDF
Ism npblm-20120315
by
隆浩 安
PDF
論文紹介 A Bayesian framework for word segmentation: Exploring the effects of con...
by
Akira Taniguchi
PDF
2016word embbed
by
Shin Asakawa
PPTX
PFI seminar 2010/05/27 統計的機械翻訳
by
Preferred Networks
PDF
CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multipl...
by
禎晃 山崎
PDF
大規模言語モデルとChatGPT
by
nlab_utokyo
PDF
IBMModel2
by
Hidekazu Oiwa
PDF
nl190segment
by
Hiroshi Ono
PDF
ICLR2017読み会 Data Noising as Smoothing in Neural Network Language Models @Dena
by
Takanori Nakai
言語モデル入門
by
Yoshinari Fujinuma
100816 nlpml sec2
by
shirakia
TensorFlow math ja 05 word2vec
by
Shin Asakawa
大規模日本語ブログコーパスにおける言語モデルの構築と評価
by
Yahoo!デベロッパーネットワーク
Extract and edit
by
禎晃 山崎
I
by
SOINN Inc.
未出現事象の出現確率
by
Hiroshi Nakagawa
言語資源と付き合う
by
Yuya Unno
Machine Learning Seminar (5)
by
Tomoya Nakayama
ACLreading2014@Ace12358
by
Ace12358
STAIR Lab Seminar 202105
by
Sho Takase
Ism npblm-20120315
by
隆浩 安
論文紹介 A Bayesian framework for word segmentation: Exploring the effects of con...
by
Akira Taniguchi
2016word embbed
by
Shin Asakawa
PFI seminar 2010/05/27 統計的機械翻訳
by
Preferred Networks
CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multipl...
by
禎晃 山崎
大規模言語モデルとChatGPT
by
nlab_utokyo
IBMModel2
by
Hidekazu Oiwa
nl190segment
by
Hiroshi Ono
ICLR2017読み会 Data Noising as Smoothing in Neural Network Language Models @Dena
by
Takanori Nakai
More from Yoshinari Fujinuma
PPTX
Probabilistic Graphical Models 輪読会 Chapter 4.1 - 4.4
by
Yoshinari Fujinuma
PPTX
IT業界における英語とプログラミングの関係性
by
Yoshinari Fujinuma
PDF
Kuromoji FST
by
Yoshinari Fujinuma
PPTX
Liさん
by
Yoshinari Fujinuma
PPTX
冨田さん
by
Yoshinari Fujinuma
PPTX
藤沼さん
by
Yoshinari Fujinuma
PPTX
Yokoさん
by
Yoshinari Fujinuma
PPTX
Panotさん
by
Yoshinari Fujinuma
PPTX
大橋さん
by
Yoshinari Fujinuma
PDF
研究室紹介用ポスター
by
Yoshinari Fujinuma
PDF
Minhさん
by
Yoshinari Fujinuma
PDF
Pascualさん
by
Yoshinari Fujinuma
PDF
Pontusさん
by
Yoshinari Fujinuma
PPTX
hara-san's research
by
Yoshinari Fujinuma
PDF
Tweet Recommendation with Graph Co-Ranking
by
Yoshinari Fujinuma
Probabilistic Graphical Models 輪読会 Chapter 4.1 - 4.4
by
Yoshinari Fujinuma
IT業界における英語とプログラミングの関係性
by
Yoshinari Fujinuma
Kuromoji FST
by
Yoshinari Fujinuma
Liさん
by
Yoshinari Fujinuma
冨田さん
by
Yoshinari Fujinuma
藤沼さん
by
Yoshinari Fujinuma
Yokoさん
by
Yoshinari Fujinuma
Panotさん
by
Yoshinari Fujinuma
大橋さん
by
Yoshinari Fujinuma
研究室紹介用ポスター
by
Yoshinari Fujinuma
Minhさん
by
Yoshinari Fujinuma
Pascualさん
by
Yoshinari Fujinuma
Pontusさん
by
Yoshinari Fujinuma
hara-san's research
by
Yoshinari Fujinuma
Tweet Recommendation with Graph Co-Ranking
by
Yoshinari Fujinuma
Recently uploaded
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PDF
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
言語モデル入門 (第二版)
1.
言語モデル入門 (第二版) 2014年10月19日
@akkikiki
2.
免責事項 •この発表は個人のものであり、会社とは 関係ありません
3.
目次 •はじめに –言語モデルとは?何に使うの?
•基礎編 –スムージング –言語モデルの評価 •応用編:言語モデルの最近の研究 •ツールキットのお話
4.
今回メインで使用した資料 •Coursera •IME本
5.
言語モデルって何? •人間が用いるであろう言葉らしさ、を確率とし てモデル化する
•例:P(<BOS>我輩は猫である<EOS>) > P(<BOS>は猫である<EOS>) IME本210ページより
6.
モデル化するデータは? •コーパスが整備されている。 •Brownコーパス
•新聞コーパス(読売、毎日、日経等々) •Google 日本語 n-gramコーパス •日本語書き言葉均衡コーパス(BCCWJ) •…
7.
言語モデルは何に使うの? •例:基本タスク –機械翻訳
•翻訳した日本語は日本語らしいか。 –かな漢字変換 •変換候補はよく使われる漢字(+送り仮名等)か。 •例:変化球系タスク –翻字(マイケル=Michael)検出(Li+ ACL 2004) –Twitter上のTopic tracking(Lin+ KDD 2011) –ユーザのオンラインコミュニティの退会予測 (Danescu-Niculescu-Mizil+ WWW 2013)
8.
•基礎編: 言語モデルとスムージング
9.
シャノンゲーム •次の単語はなにがくる? •I
want to go to ______ •P(w | I want to go to)でモデル化しよう!
10.
n-gram言語モデル •n-1語を文脈として次の単語を予測する –文字n-gram、単語n-gram、品詞n-gram
–1-gram = unigram, 2-gram = bigram •例:bigram言語モデル –P(w_i | w_i-1) = c(w_i, w_i-1) / c(w_i-1) •P(<BOS>/我輩 / は / 猫 / で / ある/<EOS>) –=P(我輩| <BOS>) * P(は|我輩) * P(猫|は) * P(で|猫) * P(ある|で) * P(<EOS> | ある)
11.
スムージング •コーパスに登場する単語は有限である。 •例:<BOS>/俺/は/猫/で/あ/る/<EOS>
•P(俺 | <BOS>) = 0 •コーパスに登場していない単語にどう対応す るか?(=ゼロ頻度問題) •⇒解決策:スムージング
12.
スムージングの種類 •加算スムージング ⇒
不十分 •n-1, n-2, …と低次のn-gramを用いよう! •バックオフ型 –高次のngramが存在しない場合、低次を考慮 –Good Turingによる推定値で低次をDiscount •補完(interpolated)型 –常に低次を考慮 –Interpolated Kneser-neyスムージング
13.
加算スムージング •一番単純:定数を頻度に加算する •n(w):コーパス中の単語の出現回数
•C:コーパス中の全単語の出現回数 •k:加算する定数 •P(w) = (n(w) + k) / (C + kV)
14.
Good Turing 推定:バックオフ型
•頻度の頻度を用いた、頻度の補正 •N_c: 頻度の頻度 •コーパス例: –マグロ:2,鮭:3,こはだ:1, 玉子:1, いか:1 –合計8単語 •N_1 = 3, N_2 = 1, N_3 = 1 •1回しか観測されていない単語を「未知の単 語が観測される確率」と扱う
15.
Good Turing 推定:例
•P_gt(ゼロ頻度) = N_1 / N •ゼロ頻度: –P_gt(ゼロ頻度) = 3/8 •一回だけ観測された単語: –c*(こはだ) =2 * N_2 / N_1 = 2/3 –P_gt(一回だけの単語) = 2/3 / 8 = 1/12
16.
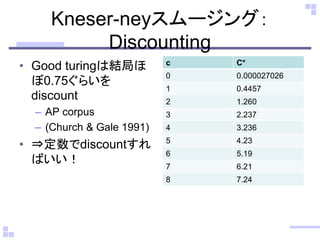
Kneser-neyスムージング: Discounting •Good
turingは結局ほ ぼ0.75ぐらいを discount –AP corpus –(Church & Gale 1991) •⇒定数でdiscountすれ ばいい! c C* 0 0.000027026 1 0.4457 2 1.260 3 2.237 4 3.236 5 4.23 6 5.19 7 6.21 8 7.24
17.
Kneser-neyスムージング: overview •実験的に一番良いスムージング
•いくつかバリエーションがある –Interpolated Kneser-ney (Kneser & Ney 1995) •今回はこっちを説明 –Modified Kneser-ney(Chen & Goodman 1999) •アイディアは: –直前の単語の種類数を重視
18.
Kneser-neyスムージング:例 •Bigram言語モデルを想定 •I
want to go to Toyama Fransisco –Fransiscoは頻度が高いが、ほぼSanの後に続く •スムージング:unigramの頻度 –P(Toyama Fransisco) ≒ P(Fransisco) –P(Toyama Fransisco)が高くなってしまう! •Kneser-neyのアイディア: –P_continuation: 単語wは直前の単語の種類は 豊富か?
19.
Kneser-neyスムージングによるバ イグラム確率
20.
Kneser-neyスムージングによるバ イグラム確率 w_iの直前に現れる単語の
種類数
21.
Kneser-neyスムージングによるバ イグラム確率 w_iの直前に現れる単語の
種類数 全ての単語の直前に現れ る単語の種類数
22.
•言語モデルの評価
23.
パープレキシティ •情報理論的距離 •低いほど言語モデルに近く、高いほどモデル
から遠い •D: テスト文書 •N: 単語数 •長さNで正規化しているイメージ
24.
•応用編
25.
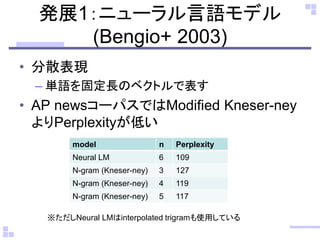
発展1:ニューラル言語モデル (Bengio+ 2003)
•分散表現 –単語を固定長のベクトルで表す •AP newsコーパスではModified Kneser-ney よりPerplexityが低い model n Perplexity Neural LM 6 109 N-gram (Kneser-ney) 3 127 N-gram (Kneser-ney) 4 119 N-gram (Kneser-ney) 5 117 ※ただしNeural LMはinterpolated trigramも使用している
26.
発展2:大規模データによる言語モ デル (Brants+
EMNLP 2007) •Stupid back off –文字通りstupidだが、意外とうまくいく –Discoutingなし •確率ではなくスコア –α = 0.4 •Unigramは
27.
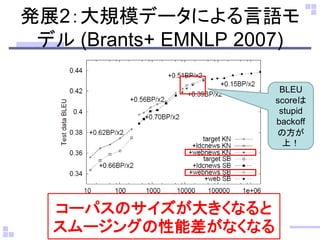
発展2:大規模データによる言語モ デル (Brants+
EMNLP 2007) BLEU scoreは stupid backoff の方が 上!
28.
発展2:大規模データによる言語モ デル (Brants+
EMNLP 2007) BLEU scoreは stupid backoff の方が 上! コーパスのサイズが大きくなると スムージングの性能差がなくなる
29.
•ツールキットのお話
30.
主な言語モデルツール •CMU-Cambridge language
model toolkit –Kneser-neyがないのであまりおすすめしない •SRI language model toolkit (SRILM) –Kneser-neyはある –Bengioらもこれを使った。多分これが一番使わ れている? –早い!
31.
まとめ •N-gram言語モデルが主に用いられる •Kneser-neyが経験的に良いスムージング
•スムージングの性能差はコーパスを大きくす ればなくなる •おすすめツールはSRILM
32.
参考文献 •日本語入力を支える技術 •StanfordのNLPの授業
–https://class.coursera.org/nlp/lecture –http://nlp.stanford.edu/~wcmac/papers/20050421-smoothing- tutorial.pdf •NYUの言語モデルの授業スライド –http://www.cs.nyu.edu/~petrov/lecture2.pdf •Univ. of Marylandの言語モデルの授業スライド –http://www.umiacs.umd.edu/~jimmylin/cloud-2010- Spring/session9-slides.pdf •Neural Language Modelの授業スライド –http://www.inf.ed.ac.uk/teaching/courses/asr/2013-14/asr09- nnlm.pdf
33.
付録:SRILMのコマンド •# build
a 5-gram model •ngram-count -order 5 -text hogehoge.txt - unk -lm hogehoge_lm •# calculate perplexity •ngram -order 5 -lm hogehoge_lm -ppl test.txt
Download
































![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180720-180723071258-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)





![[研究室論文紹介用スライド] Adversarial Contrastive Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/acepub-181119101425-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)



















































