自然言語処理をもっと学びたい人に:参考資料
Stanford大学の講義資料
Natural Language Processingwith Deep Learning
動画・演習のソースコードも充実
http://web.stanford.edu/class/cs224n/
Speech and Language Processing
Dan Jurafsky and James H. Martin
https://web.stanford.edu/~jurafsky/slp3/
東工大岡崎先生の講義資料
https://chokkan.github.io/deeplearning/
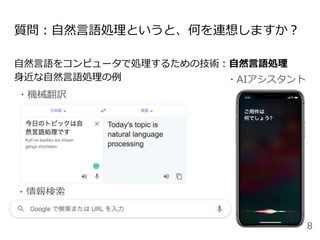
最新の研究は、Twitterも情報源
(NLPerの多くはTwitterにいる:ハッシュタグは#NLProc)
4
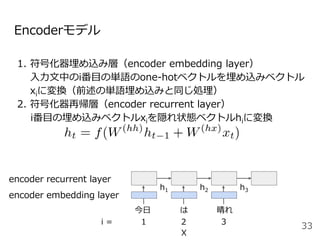
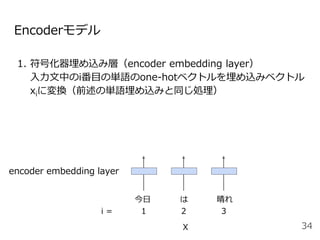
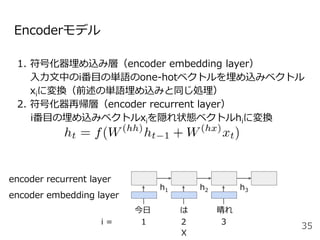
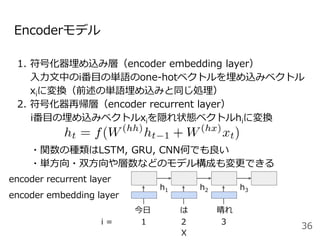
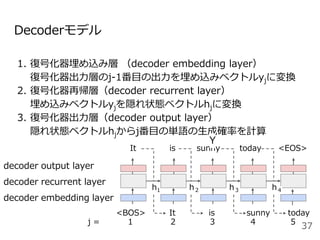
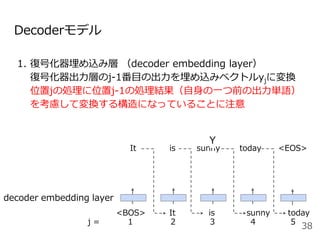
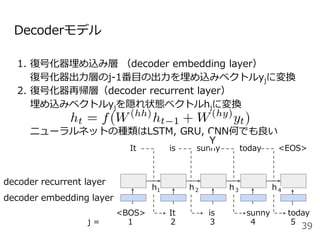
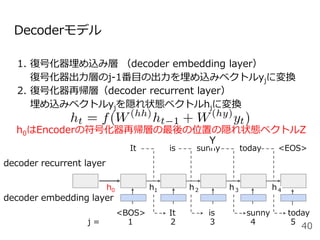
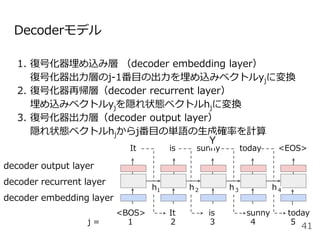
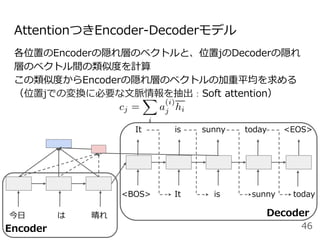
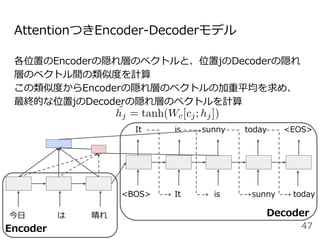
#33 系列から別の系列に変換する確率をモデル化したものがEncoder-decoderモデルです。
今日は晴れという単語列Xを固定長のベクトルZに変換するEncoderモデルと固定長のベクトルZからIt is sunny todayという系列Yを出力するDecoderモデルから構成されます。
ここで<BOS>はbeginning of sentenceの略で文頭, <EOS>はending of sentenceと文末を表す記号で、よく実装で使う記号なので覚えておいてください。
ここでのポイントはEncoderの最後の位置の隠れ状態ベクトルをDecoderの初期状態の隠れ状態ベクトルhとして利用するところです。
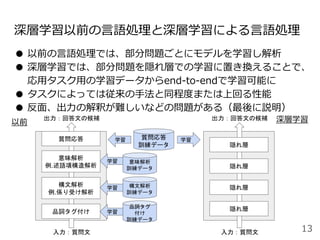
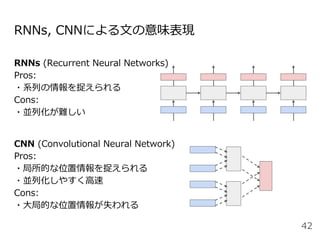
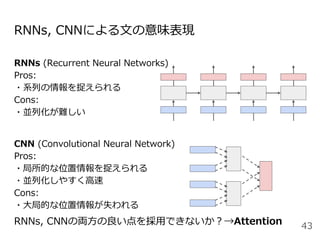
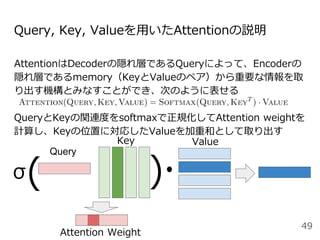
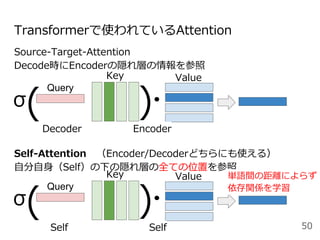
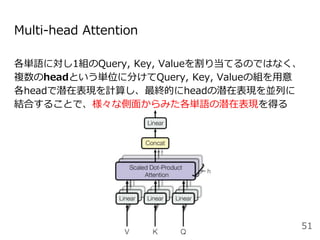
#49 Attentionを用いた代表的なモデルとしては、現在活発に研究されているTransformerというモデルがあります。これはAttention is all you needという論文のタイトルの通り、RNNやCNNを用いずAttentionのみを用いたEncoder-decoderモデルになっています。
Encoder, Decoderはそれぞれ6層あり、〜という3種類のAttentionを使用しています。順に説明します。
positional encoding: 一番最初にこのモデルに単語の分散表現を入力するときに単語位置に一意の値を各分散表現に加算する
masked decoder: 予測すべきターゲット単語の情報が予測前のデコーダにリークしないように自己注意にマスクをかけている














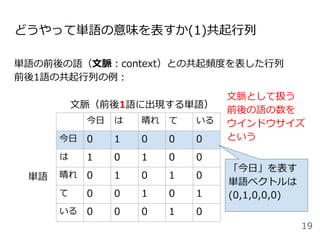
![分布仮説(distributional hypothesis)[Harris+, 1954]
単語の意味はその周囲の単語から形成されるという仮説
天気という単語は今日という単語と同時に出現しやすい(共起)
→単語の意味を周囲の単語との共起頻度で表現できそう
18
今日の天気は晴れである。
今日の1時間ごとの天気、気温、降水量を掲載します。
あなたが知りたい天気予報をお伝えします。
今日は天気が良いので布団を干した。](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-18-320.jpg)
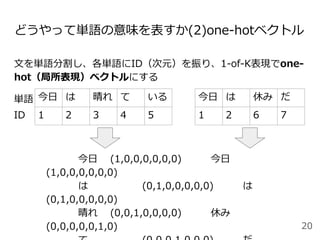



![● 分布仮説に基づき、埋め込み行列 を学習する言語モデル
● 周辺の単語から中心の単語を予測する
CBOW (Continuous Bag of Words)モデル(左)と、
ある単語が与えられた時にその周辺の単語を予測する
Skip-Gramモデル(右)から構成される
Word2Vec [Micolov+,2013]
入力
V次元
隠れ層
N次元
出力
V次元
入力
V次元
隠れ層
N次元
出力
V次元
V×N
次元
N×V
次元
N×V
次元
V×N
次元
24](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-24-320.jpg)



![文脈を考慮した単語ベクトル:ELMo [Peters+2018]
大規模コーパス1B Word Benchmarkを用い、
文字レベルの双方向(left-to-right, right-to-left)2層LSTMで
前後の文脈を考慮した単語ベクトルの学習を実現
28
図は[Devlin+2019]から引用](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-28-320.jpg)


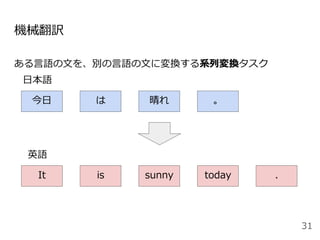
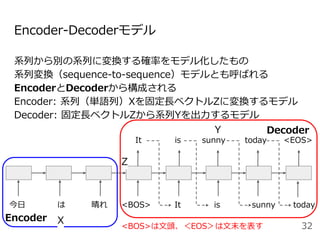

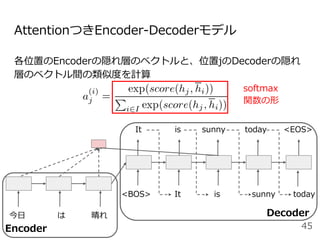
![Attentionを用いた代表的なモデル:Transformer
[Vaswani+ 2017]
48
Encoder
● RNNやCNNを用いず、
Attentionのみを使用したEncoder-
Decoderモデル
● N=6層のEncoderとDecoder
● Attentionは3箇所
○ Encoder-Decoder Attention
○ Encoder Self-Attention
○ Decoder Masked Self-Attention
Decoder](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-48-320.jpg)

![GPT (Generative Pre-trained Transformer)
[Radford+2018]
元祖・Transformerによる事前学習に基づく汎用言語モデル
12層片方向(left-to-right)Transformerの自己回帰言語モデル
:逆方向の情報を利用できていないのが難点
53図は[Devlin+2019]から引用](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-53-320.jpg)
![BERT (Bidirectional Encoder Representations
from Transformers)[Devlin+ 2019]
24層の双方向Transformerをベースとした、
1. 大規模コーパスによる事前学習
2. タスクに応じたファインチューニング
によって様々なタスク・言語に応用できる汎用言語モデル
54](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-54-320.jpg)
![[CLS] 今日 の [MASK] は 雨 だ [SEP] 傘 を 持っ て [SEP]
BERTの事前学習
2つの事前学習タスクによって双方向Transformerの学習を実現
1. Masked Language Model
入力データの一部を[MASK]でマスキングし、前後の単語ではなく
マスキングされた単語を予測するタスクで双方向の情報を考慮
2. Next Sentence Prediction
文のペア(A, B)が入力として与えられた時、文Bが文Aの次に続く
か否かを予測する
55
…
文B文A
is_next 天気](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-55-320.jpg)
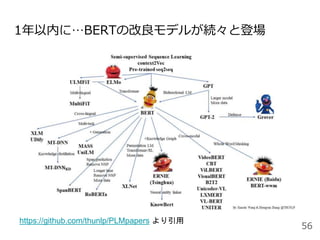
![1年以内に…BERTの改良モデルが続々と登場
● XLNet[Zhilin+2019]
マスキングに用いられる特殊記号[MASK]はfine-tuning時には
出現しないためバイアスとなる問題に対して、
単語の並び替え(Permutation Language Model)を採用
● RoBERTa[Yinhan+2019]
マスキングの位置を動的に変えることで効率的な学習を実現
● ALBERT[Lan+2019]
BERTで使われているパラメータ数を減らし軽量化
● T5[Raffel+2019]
Text-to-Text Transfer Transformerの略。
分類・翻訳・質問応答などの全タスクで入力と出力をテキスト
フォーマットに統一し転移学習することで、高精度を実現
57](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-57-320.jpg)
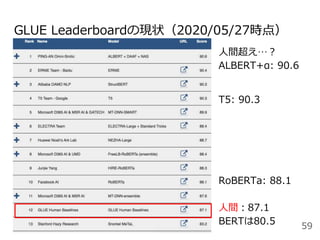
![汎用言語モデルの評価ベンチマーク
General Language Understanding Evaluation Benchmark
(GLUE)[Wang+2019] https://gluebenchmark.com/
・文単位の理解(文法性評価、感情分析)
・文間の理解(質問応答、類似度、言い換え、推論、照応)
を問う9種類のデータセットを組み合わせている
SuperGLUE[Wang+2020] https://super.gluebenchmark.com/
・GLUEの後続。共参照などGLUEよりもハードなタスクを追加
58](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-58-320.jpg)
![汎用言語モデルの実装:transformersの利用
huggingfaceが提供するpytorchフレームワークtransformers
https://github.com/huggingface/transformers
で、簡単にBERTなどの汎用言語モデルを動かせる
例えば、BERTを用いた日本語単語分割も、数行で書けてしまう!
60
from transformers import BertJapaneseTokenizer
tokenizer = BertJapaneseTokenizer.from_pretrained('bert-
base-japanese-whole-word-masking')
tokenizer.tokenize('今日は晴れている')
#['今日', 'は', '晴れ', 'て', 'いる']](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-60-320.jpg)
![汎用言語モデルの課題:
言語の意味を真に理解しているか?
自然言語推論 (Natural Language Inference) a.k.a.
含意関係認識(Recognizing Textual Entailment)[Dagan,2013]
前提文が仮説文の意味を含むか否かを自動判定するタスク
61
前提文: 今年はある日本人がノーベル文学賞を受賞した
仮説文: 今年はある日本人がノーベル賞を受賞した 含意
前提文: 今年はある日本人がノーベル文学賞を受賞した
仮説文: 日本人は誰もノーベル賞を受賞しなかった 矛盾
前提文: 今年はある日本人がノーベル文学賞を受賞した
仮説文: 去年はある日本人がノーベル文学賞を受賞した 非含意 (中立)](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-61-320.jpg)
![汎用言語モデルの課題:
言語の意味を真に理解しているか?
62
大規模データMultiNLI[Williams+2018]でfinetuningしたBERTの正答率
・MultiNLIテストデータ
・様々な推論現象に特化したテストデータ
- MED[Yanaka+2019]
- Logic Fragments[Richardson+2020]
特定の推論は全く解けていない
MEDに含まれる、BERTが解けない推論の例(downward monotone)
前提文: 今年は日本人は誰もノーベル賞を受賞しなかった
仮説文: 今年は日本人は誰もノーベル文学賞を受賞しなかった 含意](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-62-320.jpg)
![汎用言語モデルの課題:
言語の意味を真に理解しているか?
63
大規模データMultiNLI[Williams+2018]でfinetuningしたBERTの正答率
・MultiNLIテストデータ
・様々な推論現象に特化したテストデータ
- MED[Yanaka+2019]
- Logic Fragments[Richardson+2020]
特定の推論は全く解けていない
大規模データセットの問題:
・簡単な問題が多い
・クラウドワーカーの作業バイアス
ニューラル言語モデルの問題:
・否定・数量などの離散的な意味を埋め込むことが難しい
・入力から出力までの過程がブラックボックス化されており、
なぜ解ける/解けないのかがわからない](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-63-320.jpg)
![汎用言語モデルの分析:プロービング(probing)
汎用言語モデルが言語を真に理解しているかを分析するための
様々なデータセットや手法が研究されている
subject-verb agreement[Linzen+2016][Gulordava+2018]
主語と動詞の数の一致を正しく予測できるかで言語モデルが文法
性を獲得しているか評価
● The keys are/*is ...
● The keys to the cabinet are/*is ...
64
文法構造を捉えていないと、
直前のcabinetに対応する動詞
を予測してしまう](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-64-320.jpg)
![判断の根拠を生成可能なDNNに向けて(1)データ
● e-SNLI[Camburu+,2018]
自然言語推論の判断根拠をアノテーションしたデータセット
● e-SNLI-VE[Xie+2019][Do+2020]
e-SNLIのマルチモーダル版。画像ーテキスト間の含意関係と
判断根拠がアノテーションされている
65](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-65-320.jpg)
![判断の根拠を生成可能なDNNに向けて(2)モデル
WT5[Narang+,2020]
Text-to-Textの汎用言語モデルT5を応用したモデル
タスクの種類と問題のテキストを入力として、
問題の答えと根拠を予測
66](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-66-320.jpg)
![記号推論が可能なDNNに向けて(1)データ
DROP[Dua+,2019]:数値演算・ソート・比較などの記号推論を
問う文書読解データセット
67](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-67-320.jpg)
![記号推論が可能なDNNに向けて(2)モデル
Neural Symbolic Reader[Chen+,2020]
Neural Module Networks[Gupta+,2020][Andreas+,2016]
質問文から回答を算出するためのプログラムに変換することで、
数値演算を実現
68](https://image.slidesharecdn.com/20200625-200703074223/85/2020-Deep-learning-9-68-320.jpg)




















![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)



![[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180606065226-thumbnail.jpg?width=640&height=640&fit=bounds)
![[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180607030706-thumbnail.jpg?width=640&height=640&fit=bounds)











![[ML論文読み会資料] Teaching Machines to Read and Comprehend](https://cdn.slidesharecdn.com/ss_thumbnails/ml2-171222014201-thumbnail.jpg?width=640&height=640&fit=bounds)



