Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
JubatusOfficial
6,880 views
Jubatusの特徴変換と線形分類器の仕組み
Read more
26
Save
Share
Embed
Embed presentation
Download
Downloaded 168 times
1
/ 41
2
/ 41
3
/ 41
4
/ 41
5
/ 41
6
/ 41
7
/ 41
8
/ 41
9
/ 41
10
/ 41
11
/ 41
12
/ 41
13
/ 41
14
/ 41
15
/ 41
16
/ 41
17
/ 41
18
/ 41
19
/ 41
20
/ 41
21
/ 41
22
/ 41
23
/ 41
24
/ 41
25
/ 41
26
/ 41
27
/ 41
28
/ 41
29
/ 41
30
/ 41
31
/ 41
32
/ 41
33
/ 41
34
/ 41
35
/ 41
36
/ 41
37
/ 41
38
/ 41
39
/ 41
40
/ 41
41
/ 41
More Related Content
PDF
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
PDF
機械学習の理論と実践
by
Preferred Networks
PDF
Pythonによる機械学習入門 ~Deep Learningに挑戦~
by
Yasutomo Kawanishi
PDF
Pythonによる機械学習
by
Kimikazu Kato
PDF
分類問題 - 機械学習ライブラリ scikit-learn の活用
by
y-uti
PDF
第1回 Jubatusハンズオン
by
Yuya Unno
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17
by
Yuya Unno
PDF
LCCC2010:Learning on Cores, Clusters and Cloudsの解説
by
Preferred Networks
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
機械学習の理論と実践
by
Preferred Networks
Pythonによる機械学習入門 ~Deep Learningに挑戦~
by
Yasutomo Kawanishi
Pythonによる機械学習
by
Kimikazu Kato
分類問題 - 機械学習ライブラリ scikit-learn の活用
by
y-uti
第1回 Jubatusハンズオン
by
Yuya Unno
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17
by
Yuya Unno
LCCC2010:Learning on Cores, Clusters and Cloudsの解説
by
Preferred Networks
What's hot
PDF
Jubatus: 分散協調をキーとした大規模リアルタイム機械学習プラットフォーム
by
Preferred Networks
PPTX
Dimensionality reduction with t-SNE(Rtsne) and UMAP(uwot) using R packages.
by
Satoshi Kato
PDF
機械学習チュートリアル@Jubatus Casual Talks
by
Yuya Unno
PDF
Pythonによる機械学習入門〜基礎からDeep Learningまで〜
by
Yasutomo Kawanishi
PDF
画像認識で物を見分ける
by
Kazuaki Tanida
PPTX
Pythonとdeep learningで手書き文字認識
by
Ken Morishita
PDF
TensorFlowによるニューラルネットワーク入門
by
Etsuji Nakai
PDF
機械学習 入門
by
Hayato Maki
PDF
Python 機械学習プログラミング データ分析演習編
by
Etsuji Nakai
PDF
ルールベースから機械学習への道 公開用
by
nishio
PPTX
ディープラーニングで株価予測をやってみた
by
卓也 安東
PDF
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
by
Tatsuya Tojima
PDF
Jubatusにおける機械学習のテスト@MLCT
by
Yuya Unno
PDF
論文紹介 Identifying Implementation Bugs in Machine Learning based Image Classifi...
by
y-uti
PPTX
Jubatus使ってみた 作ってみたJubatus
by
JubatusOfficial
PDF
はてなインターン「機械学習」
by
Hatena::Engineering
PDF
協調フィルタリング with Mahout
by
Katsuhiro Takata
PDF
機械学習
by
Hikaru Takemura
PDF
「深層学習」勉強会LT資料 "Chainer使ってみた"
by
Ken'ichi Matsui
PDF
ディープニューラルネット入門
by
TanUkkii
Jubatus: 分散協調をキーとした大規模リアルタイム機械学習プラットフォーム
by
Preferred Networks
Dimensionality reduction with t-SNE(Rtsne) and UMAP(uwot) using R packages.
by
Satoshi Kato
機械学習チュートリアル@Jubatus Casual Talks
by
Yuya Unno
Pythonによる機械学習入門〜基礎からDeep Learningまで〜
by
Yasutomo Kawanishi
画像認識で物を見分ける
by
Kazuaki Tanida
Pythonとdeep learningで手書き文字認識
by
Ken Morishita
TensorFlowによるニューラルネットワーク入門
by
Etsuji Nakai
機械学習 入門
by
Hayato Maki
Python 機械学習プログラミング データ分析演習編
by
Etsuji Nakai
ルールベースから機械学習への道 公開用
by
nishio
ディープラーニングで株価予測をやってみた
by
卓也 安東
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
by
Tatsuya Tojima
Jubatusにおける機械学習のテスト@MLCT
by
Yuya Unno
論文紹介 Identifying Implementation Bugs in Machine Learning based Image Classifi...
by
y-uti
Jubatus使ってみた 作ってみたJubatus
by
JubatusOfficial
はてなインターン「機械学習」
by
Hatena::Engineering
協調フィルタリング with Mahout
by
Katsuhiro Takata
機械学習
by
Hikaru Takemura
「深層学習」勉強会LT資料 "Chainer使ってみた"
by
Ken'ichi Matsui
ディープニューラルネット入門
by
TanUkkii
Viewers also liked
PDF
Random Forestsとその応用
by
MPRG_Chubu_University
PDF
画像認識の初歩、SIFT,SURF特徴量
by
takaya imai
PDF
「はじめてでもわかる RandomForest 入門-集団学習による分類・予測 -」 -第7回データマイニング+WEB勉強会@東京
by
Koichi Hamada
PDF
マルウェア分類に用いられる特徴量 Kaggle - Malware Classification Challenge勉強会
by
Takeshi Ishita
PDF
機械学習によるデータ分析まわりのお話
by
Ryota Kamoshida
PDF
Microsoft Malware Classification Challenge 上位手法の紹介 (in Kaggle Study Meetup)
by
Shotaro Sano
PDF
実践多クラス分類 Kaggle Ottoから学んだこと
by
nishio
PDF
サポートベクトルデータ記述法による異常検知 in 機械学習プロフェッショナルシリーズ輪読会
by
Shotaro Sano
PDF
パーソナライズニュースを支えるML業務のまわしかた@Yahoo! JAPAN
by
Yahoo!デベロッパーネットワーク
PDF
機械学習概論 講義テキスト
by
Etsuji Nakai
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PDF
機会学習ハッカソン:ランダムフォレスト
by
Teppei Baba
PDF
いまさら聞けない機械学習の評価指標
by
圭輔 大曽根
PPTX
みんな大好き機械学習
by
sady_nitro
PDF
Pythonによる機械学習の最前線
by
Kimikazu Kato
PDF
クラシックな機械学習の入門 11.評価方法
by
Hiroshi Nakagawa
PDF
Pythonによる機械学習入門 ~SVMからDeep Learningまで~
by
Yasutomo Kawanishi
PPTX
NW_#secccamp
by
Ryo Furuoto
PPTX
Ddos
by
Ryo Furuoto
Random Forestsとその応用
by
MPRG_Chubu_University
画像認識の初歩、SIFT,SURF特徴量
by
takaya imai
「はじめてでもわかる RandomForest 入門-集団学習による分類・予測 -」 -第7回データマイニング+WEB勉強会@東京
by
Koichi Hamada
マルウェア分類に用いられる特徴量 Kaggle - Malware Classification Challenge勉強会
by
Takeshi Ishita
機械学習によるデータ分析まわりのお話
by
Ryota Kamoshida
Microsoft Malware Classification Challenge 上位手法の紹介 (in Kaggle Study Meetup)
by
Shotaro Sano
実践多クラス分類 Kaggle Ottoから学んだこと
by
nishio
サポートベクトルデータ記述法による異常検知 in 機械学習プロフェッショナルシリーズ輪読会
by
Shotaro Sano
パーソナライズニュースを支えるML業務のまわしかた@Yahoo! JAPAN
by
Yahoo!デベロッパーネットワーク
機械学習概論 講義テキスト
by
Etsuji Nakai
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
機会学習ハッカソン:ランダムフォレスト
by
Teppei Baba
いまさら聞けない機械学習の評価指標
by
圭輔 大曽根
みんな大好き機械学習
by
sady_nitro
Pythonによる機械学習の最前線
by
Kimikazu Kato
クラシックな機械学習の入門 11.評価方法
by
Hiroshi Nakagawa
Pythonによる機械学習入門 ~SVMからDeep Learningまで~
by
Yasutomo Kawanishi
NW_#secccamp
by
Ryo Furuoto
Ddos
by
Ryo Furuoto
Similar to Jubatusの特徴変換と線形分類器の仕組み
PDF
MapReduceによる大規模データを利用した機械学習
by
Preferred Networks
PDF
tut_pfi_2012
by
Preferred Networks
PDF
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平
by
Preferred Networks
PDF
Deep learning勉強会20121214ochi
by
Ohsawa Goodfellow
PDF
予測型戦略を知るための機械学習チュートリアル
by
Yuya Unno
PDF
bigdata2012ml okanohara
by
Preferred Networks
PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
PDF
Oracle Cloud Developers Meetup@東京
by
tuchimur
PDF
レコメンドアルゴリズムの基本と周辺知識と実装方法
by
Takeshi Mikami
PPTX
機械学習の基礎
by
Ken Kumagai
PDF
Overview and Roadmap
by
JubatusOfficial
PDF
第1回 Jubatusハンズオン
by
JubatusOfficial
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9
by
Yuya Unno
PDF
Jubatusの紹介@第6回さくさくテキストマイニング
by
Yuya Unno
PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで
by
Shunsuke Nakamura
PDF
EMNLP 2011 reading
by
正志 坪坂
PDF
Sakusaku svm
by
antibayesian 俺がS式だ
PDF
Hands on-ml section1-1st-half-20210317
by
Nagi Kataoka
PDF
機械学習とJubatus
by
Junya Yamaguchi
PPTX
0610 TECH & BRIDGE MEETING
by
健司 亀本
MapReduceによる大規模データを利用した機械学習
by
Preferred Networks
tut_pfi_2012
by
Preferred Networks
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平
by
Preferred Networks
Deep learning勉強会20121214ochi
by
Ohsawa Goodfellow
予測型戦略を知るための機械学習チュートリアル
by
Yuya Unno
bigdata2012ml okanohara
by
Preferred Networks
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
Oracle Cloud Developers Meetup@東京
by
tuchimur
レコメンドアルゴリズムの基本と周辺知識と実装方法
by
Takeshi Mikami
機械学習の基礎
by
Ken Kumagai
Overview and Roadmap
by
JubatusOfficial
第1回 Jubatusハンズオン
by
JubatusOfficial
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9
by
Yuya Unno
Jubatusの紹介@第6回さくさくテキストマイニング
by
Yuya Unno
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで
by
Shunsuke Nakamura
EMNLP 2011 reading
by
正志 坪坂
Sakusaku svm
by
antibayesian 俺がS式だ
Hands on-ml section1-1st-half-20210317
by
Nagi Kataoka
機械学習とJubatus
by
Junya Yamaguchi
0610 TECH & BRIDGE MEETING
by
健司 亀本
More from JubatusOfficial
PDF
jubabanditの紹介
by
JubatusOfficial
PPTX
Jubatus 1.0 の紹介
by
JubatusOfficial
PDF
JubaQLご紹介
by
JubatusOfficial
PDF
まだCPUで消耗してるの?Jubatusによる近傍探索のGPUを利用した高速化
by
JubatusOfficial
PDF
地域の魅力を伝えるツアーガイドAI
by
JubatusOfficial
PDF
Jubaanomalyについて
by
JubatusOfficial
ODP
小町のレス数が予測できるか試してみた
by
JubatusOfficial
PDF
Jubatus解説本の紹介
by
JubatusOfficial
PDF
Python 特徴抽出プラグイン
by
JubatusOfficial
PDF
jubarecommenderの紹介
by
JubatusOfficial
PDF
Jubakitの解説
by
JubatusOfficial
PPTX
発言小町からのプロファイリング
by
JubatusOfficial
PDF
単語コレクター(文章自動校正器)
by
JubatusOfficial
PPTX
銀座のママ
by
JubatusOfficial
PPTX
新機能紹介 1.0.6
by
JubatusOfficial
PPTX
小町の溜息
by
JubatusOfficial
PPTX
JUBARHYME
by
JubatusOfficial
PPTX
かまってちゃん小町
by
JubatusOfficial
PPTX
新聞から今年の漢字を予測する
by
JubatusOfficial
PDF
コンテンツマーケティングでレコメンドエンジンが必要になる背景とその活用
by
JubatusOfficial
jubabanditの紹介
by
JubatusOfficial
Jubatus 1.0 の紹介
by
JubatusOfficial
JubaQLご紹介
by
JubatusOfficial
まだCPUで消耗してるの?Jubatusによる近傍探索のGPUを利用した高速化
by
JubatusOfficial
地域の魅力を伝えるツアーガイドAI
by
JubatusOfficial
Jubaanomalyについて
by
JubatusOfficial
小町のレス数が予測できるか試してみた
by
JubatusOfficial
Jubatus解説本の紹介
by
JubatusOfficial
Python 特徴抽出プラグイン
by
JubatusOfficial
jubarecommenderの紹介
by
JubatusOfficial
Jubakitの解説
by
JubatusOfficial
発言小町からのプロファイリング
by
JubatusOfficial
単語コレクター(文章自動校正器)
by
JubatusOfficial
銀座のママ
by
JubatusOfficial
新機能紹介 1.0.6
by
JubatusOfficial
小町の溜息
by
JubatusOfficial
JUBARHYME
by
JubatusOfficial
かまってちゃん小町
by
JubatusOfficial
新聞から今年の漢字を予測する
by
JubatusOfficial
コンテンツマーケティングでレコメンドエンジンが必要になる背景とその活用
by
JubatusOfficial
Jubatusの特徴変換と線形分類器の仕組み
1.
Jubatusの特徴変換と 線形分類器の仕組み
2011/11/07 株式会社Preferred Infrastructure 海野 裕也 (@unnonouno)
2.
本発表のねらい l
現状のJubatusで何が出来るのかを機能の⾯面から解説 l 線形分類器の仕組みと使い⽅方 l 特徴抽出器の仕組みと使い⽅方 2
3.
機械学習とは? l
データから有⽤用な規則、ルール、知識識表現、判断基準な どを抽出 l データがあるところ、どこでも使える l 様々な分野の問題に利利⽤用可能 適用分野 レコメンデー ションクラス 分類、識識別 市場予測 評判分析 タリング 情報抽出 ⽂文字認識識 ロボット 画像解析 検索索ランキン 遺伝⼦子分析 ⾦金金融 医療療診断 グ 3
4.
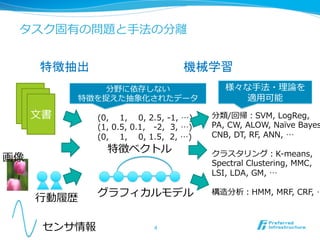
タスク固有の問題と⼿手法の分離離
特徴抽出 機械学習 分野に依存しない 様々な⼿手法・理理論論を 特徴を捉えた抽象化されたデータ 適⽤用可能 ⽂文書 (0, 1, 0, 2.5, -‐‑‒1, …) 分類/回帰:SVM, LogReg, (1, 0.5, 0.1, -‐‑‒2, 3, …) PA, CW, ALOW, Naïve Bayes (0, 1, 0, 1.5, 2, …) CNB, DT, RF, ANN, … 特徴ベクトル クラスタリング:K-‐‑‒means, 画像 Spectral Clustering, MMC, LSI, LDA, GM, … ⾏行行動履履歴 グラフィカルモデル 構造分析:HMM, MRF, CRF, … センサ情報 4
5.
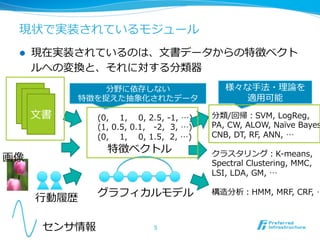
現状で実装されているモジュール l
現在実装されているのは、⽂文書データからの特徴ベクト ルへの変換と、それに対する分類器 分野に依存しない 様々な⼿手法・理理論論を 特徴を捉えた抽象化されたデータ 適⽤用可能 ⽂文書 (0, 1, 0, 2.5, -‐‑‒1, …) 分類/回帰:SVM, LogReg, (1, 0.5, 0.1, -‐‑‒2, 3, …) PA, CW, ALOW, Naïve Bayes (0, 1, 0, 1.5, 2, …) CNB, DT, RF, ANN, … 特徴ベクトル クラスタリング:K-‐‑‒means, 画像 Spectral Clustering, MMC, LSI, LDA, GM, … ⾏行行動履履歴 グラフィカルモデル 構造分析:HMM, MRF, CRF, … センサ情報 5
6.
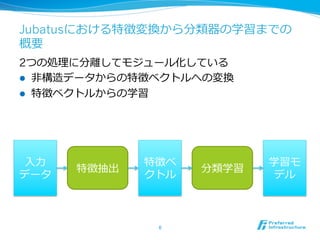
Jubatusにおける特徴変換から分類器の学習までの 概要 2つの処理理に分離離してモジュール化している l ⾮非構造データからの特徴ベクトルへの変換 l 特徴ベクトルからの学習 ⼊入⼒力力
特徴ベ 学習モ 特徴抽出 分類学習 データ クトル デル 6
7.
Jubatusの線形分類器 7
8.
現在Jubatusで実装されているのは多クラス分類 l
⼊入⼒力力xに対し、出⼒力力yを予測する タスク ⼊入⼒力力x 出⼒力力y メール分類 メール スパム or 普通 or 重要等 Twitterのユーザー分析 Tweet ユーザーの性別、職業、年年齢など 電気使⽤用料料需要の予測 パケット 各サーバーの予測使⽤用量量(連続値) 広告のコンバージョン予測 アクセス履履 クリック、コンバージョンするか 歴、広告 監視カメラ解析 監視カメラ 部屋の状態(明かりがついている? 画像 ⼈人がいるか?など) 8
9.
⾮非定形データからの特徴ベクトルへの変換 l
Jubatusは⽂文書や画像などの⾮非定形データの解析も想定 し、標準でこうした特徴抽出機構を備える l 変換後はベクトルとなる l キーと値のペアになっていると思えばOK ⽇日本電信電話株式会社(東京都千代⽥田区、代表取締役社⻑⾧長:三浦 惺、以下「NTT」) と株式会社プリファードインフラストラクチャー(東京都⽂文京区、代表取締役社⻑⾧長:⻄西川 徹、以下「PFI社」)は、ビッグデータ*1と呼ばれる⼤大規模データをリアルタイムに⾼高速分 析処理理する基盤技術「Jubatus*2」(第1版)を開発しました。 例例:⼊入⼒力力が⾔言語データの場合 単語/キーワード N-‐‑‒gram ⽇日本電信電話株式会社 : 1 Ju: 1 東京都 : 2 ub: 2 詳細は後述 千代⽥田区 : 1 ba:1 、代表取締役社⻑⾧長 : 2 、at:1 NTT : 1 tu:1 プリファードインフラストラクチャー : 1 9 us:1
10.
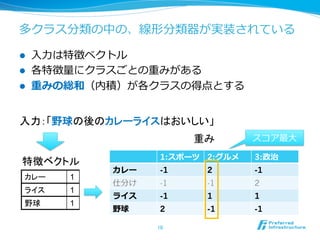
多クラス分類の中の、線形分類器が実装されている l
⼊入⼒力力は特徴ベクトル l 各特徴量量にクラスごとの重みがある l 重みの総和(内積)が各クラスの得点とする 入力:「野球の後のカレーライスはおいしい」 重み スコア最⼤大 1:スポーツ 2:グルメ 3:政治 特徴ベクトル カレー -1 2 -1 カレー 1 仕分け -1 -1 2 ライス 1 ライス -1 1 1 野球 1 野球 2 -1 -1 10
11.
線形分類器の機械学習 l
機械学習で重みを⾃自動調整する l 調整の基準や、計算⽅方法で様々な種類が存在する l 単純ベイズ l パーセプトロン l 最⼤大エントロピー法 l サポートベクトルマシン l Jubatusではオンライン学習アルゴリズムが実装されて いる 11
12.
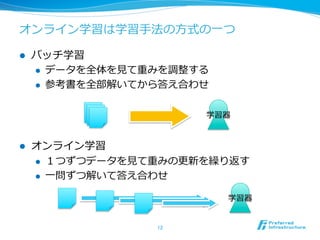
オンライン学習は学習⼿手法の⽅方式の⼀一つ l
バッチ学習 l データを全体を⾒見見て重みを調整する l 参考書を全部解いてから答え合わせ 学習器 l オンライン学習 l 1つずつデータを⾒見見て重みの更更新を繰り返す l ⼀一問ずつ解いて答え合わせ 学習器 12
13.
オンライン学習の重み更更新のイメージ l
分類に間違えたら正しく分類できるように微調整 l 微調整の⽅方法の違いで学習⼿手法の良良し悪しが決まる 特徴ベクトル 重み 正しいクラス 間違えたクラス 正しいクラス 間違えたクラス 正解クラスの重みが小さい 13 正しく分類できるように調整
14.
オンライン学習の特徴 l
オンライン学習は更更新が早い l 同じ学習時間に対して、経験的に精度度も⾼高い l Jubatusでは最新の⼿手法を含む、様々な⼿手法が実装され ている l Perceptron (1958) l Passive Aggressive (PA) (2003) l Confidence Weighted Learning (CW) (2008) l AROW (2009) l Normal HERD (NHERD) (2010) 14
15.
Jubatusの分散学習:緩いモデル共有 l たまに全学習器の重みを混ぜ合わせる
l 全サーバーで重みの平均をとる (Iterative Parameter Mixture) l 重み情報だけを交換するので軽い l ⾮非同期・オンラインでMapReduceしているイメージに 近い 15
16.
Jubatusにおける分散機械学習のイメージ
学習器 l みんな個別に⾃自学⾃自習 l たまに勉強会で情報交換 l ⼀一⼈人で勉強するより効率率率がいいはず! 16
17.
線形分類器以外の分類⼿手法はないのか? l
⾮非線形の分類器はたくさんあります l 決定⽊木 l カーネル法 l ニューラルネットワーク l 分類速度度、シンプルさ、学習速度度などの点で線形分類器 は⾮非常に優れる 17
18.
今後のJubatusの機械学習 l
「緩いモデル共有」モデルが他の学習問題でも有効に働 くことを検証 l そのための⼿手法の研究開発&実証実験 l 「勉強会モデル」のアナロジーで⾔言えばうまく⾏行行 く? l 今後、順次実装して公開していきます 18
19.
Jubatusの特徴抽出処理理 19
20.
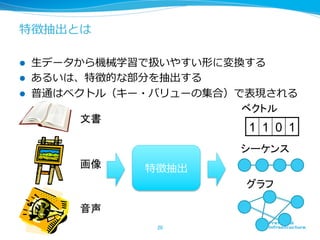
特徴抽出とは l
⽣生データから機械学習で扱いやすい形に変換する l あるいは、特徴的な部分を抽出する l 普通はベクトル(キー・バリューの集合)で表現される ベクトル 文書 1 1 0 1 シーケンス 画像 特徴抽出 グラフ 音声 20
21.
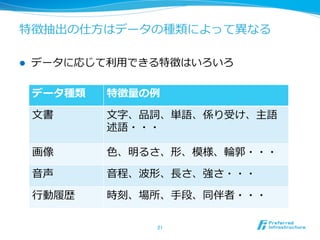
特徴抽出の仕⽅方はデータの種類によって異異なる l
データに応じて利利⽤用できる特徴はいろいろ データ種類 特徴量量の例例 ⽂文書 ⽂文字、品詞、単語、係り受け、主語 述語・・・ 画像 ⾊色、明るさ、形、模様、輪輪郭・・・ ⾳音声 ⾳音程、波形、⻑⾧長さ、強さ・・・ ⾏行行動履履歴 時刻、場所、⼿手段、同伴者・・・ 21
22.
分析⽬目的によっても最適な特徴量量は異異なる l
適切切な特徴が抽出できないと良良い結果は得られない Jubatusは⼤大規模な Jubatus / データ / 分 名詞 散 / 機械学習 / ライブラ データに対して、分 散機械学習するため リ / インストール / 分類 のライブラリだ。イ 性能 / レイテンシー ンストールは難し テーマがなんとなくわかる・・・ かったが、とても⾼高 い分類性能と、低い レイテンシーで満⾜足 ⼤大規模だ / 難しい / ⾼高 した。 形容詞・動詞 い / 低い / 満⾜足する 評価がなんとなくわかる・・・ 22
23.
Jubatusにおける特徴抽出のコンセプト
全ての⼈人に機械学習を! l ちょっと設定を書けば、あとはよろしくやってくれる l しかし、現実は難しいのでチューニングがなるべく簡単 にできるように・・・ 23
24.
現在の特徴抽出の流流れ
文字列情報の変換 ⽂文字列列フィ ⽂文字列列特 ルター 徴抽出 特徴ベク データ トル 数値フィル 数値特徴 ター 抽出 数値情報の変換 24
25.
⼊入⼒力力データの与え⽅方 ( [ ("user/id",
"ippy"), ("user/name", "Loren Ipsum"), ("message", "<H>Hello World</H>") ], [ ("user/age", 29) , ("user/income", 100000) ] ) l 与えられるデータはシンプルなキー・バリュー l バリューは⽂文字列列と数値のみ l 画像や⾳音声などの扱いは今後検討・・・ l 各プログラミング⾔言語ごとに与え⽅方は微妙に異異なる 25
26.
⼊入⼒力力データの与え⽅方 ⽂文字列列情報
⽂文字列列のキー ⽂文字列列の値 ( [ ("user/id", "ippy"), ("user/name", "Loren Ipsum"), ("message", "<H>Hello World</H>") ], [ ("user/age", 29) , ("user/income", 100000) ] ) l タプルの1番⽬目の要素は⽂文字列列のデータ l 効率率率の都合でタプルの配列列 26
27.
⼊入⼒力力データの与え⽅方 数値情報 ( [ ("user/id",
"ippy"), ("user/name", "Loren Ipsum"), ("message", "<H>Hello World</H>") ], [ ("user/age", 29) , ("user/income", 100000) ] ) ⽂文字列列のキー 数値型の値 l タプルの2番⽬目の要素は数値型のデータ l これもタプルの配列列 27
28.
特徴抽出に基本的な考え⽅方 ( [ ("user/id",
"ippy"), タグの除去 ("user/name", "Loren Ipsum"), ("message", "<H>Hello World</H>") ], [ ("user/age", 29) , ("user/income", 100000) ] ) 単語の抽出 l ⽣生のデータはこのままでは扱えない l ⽣生データから必要な情報を取り出してベクトルに変換す る 28
29.
変換規則の書き⽅方の例例 {
"string_filter_types": {}, ⽂文字列列フィルター "string_filter_rules": [], "num_filter_types": {}, "num_filter_rules": [], 数値フィルター "string_types": {}, "string_rules": [ { "key": "*", "type": "space", "sample_weight": "bin”, "global_weight": "bin" } ⽂文字列列特徴 ], "num_types": {}, "num_rules": [ 数値特徴 { "key": "*", "type": "num" } ] } もう少し簡単に書けるようにしたい… 29
30.
特徴抽出規則の書き⽅方
1. マッチ規則 “string_rules”: [ { "key": "*", 2. 特徴抽出の⼿手法 "type": "space", "sample_weight": "bin”, 3. 重み付け "global_weight": "bin" } ] l 上記の設定は、 1. すべてのキーに対して、 2. ”space”という特徴抽出を施して、 3. 重みを1に設定する l ということを書いている l num_rulesも基本的に同じ 30
31.
引数の必要な特徴抽出器の書き⽅方
変換の名前 "string_types": { "bigram": { 種類 "method": "ngram", "char_num": "2" } }, "string_rules”: [ 引数(method依存) { "key": "message", "type": "bigram", ruleに指定 "sample_weight": "tf", "global_weight": "bin" }, …] l XXX_typesで引数付きで抽出器を定義 l 定義の仕⽅方はマニュアル参照 l あとは、XXX_rulesで使えるようになる 31
32.
前処理理をしてから特徴抽出したい場合
タグ除去 (“message”, "<H>Hello World</H>”) RT除去 (“twit”, “Thanks RT: Here you are”) (“nationaliy”, “JAPAN”) ⼤大⽂文字・⼩小⽂文字 l タグなどのデータ固有のゴミ情報を取り除きたい l 前処理理をしたい場合はフィルターを使う 32
33.
フィルターを掛けてから処理理する⽅方法 “string_filter_types”:
{ 正規表現フィルター “detag”: { “method”: “regexp”, パターン “pattern”: “<[^>]*>”, “replace”: “” }, … }, … 置き換え⽂文字列列 “string_filter_rules”: [ { “key”: “message”, “type”: “detag”, 変換後の格納先 “suffix”: “-detagged”}, … ] l xxx_types で定義を書く l xxx_rules で適⽤用規則を書く 33
34.
プラグインの使い⽅方 “string_types”: {
“mecab”: { “method”: “dynamic”, “function”: “create”, “path”: “/usr/local/lib/libmecab_splitter.so” }, … } l 先と同様XXX_typesで定義できる l methodにdynamic、pathに.soヘのフルパス、function にプラグイン固有の関数名を指定する 34
35.
プラグインの作り⽅方 #include <jubatus/plugin.hpp> class my_splitter
: public jubatus::word_splitter { public: void split(const string& string, vector<pair<size_t, size_t> >& ret_boundaries) { // do somehting } }; extern "C" { my_splitter* create(const map<string, string>& params) { return new my_splitter(); } } 35
36.
プラグインの作り⽅方 #include <jubatus/plugin.hpp>
ひな形は全部この ヘッダ class my_splitter : public jubatus::word_splitter { public: void split(const string& string, vector<pair<size_t, size_t> >& ret_boundaries) { // do somehting } }; extern "C" { my_splitter* create(const map<string, string>& params) { return new my_splitter(); } } 36
37.
プラグインの作り⽅方 #include <jubatus/plugin.hpp> class my_splitter
: public jubatus::word_splitter { public: void split(const string& string, vector<pair<size_t, size_t> >& ret_boundaries) { // do somehting } ひな形クラスを継承して、 }; やりたい処理理を記述 extern "C" { my_splitter* create(const map<string, string>& params) { return new my_splitter(); } } 37
38.
プラグインの作り⽅方 #include <jubatus/plugin.hpp> class my_splitter
: public jubatus::word_splitter { public: void split(const string& string, vector<pair<size_t, size_t> >& ret_boundaries) { // do somehting } インスタンスを⽣生成 }; する関数を記述 extern "C" { my_splitter* create(const map<string, string>& params) { return new my_splitter(); } } 38
39.
特徴抽出の今後の予定 l
マルチメディアデータへの対応 l 画像 l ⾳音声 l 映像 l etc. l プラグインの管理理 l より複雑なフローの検討 39
40.
まとめ l
特徴抽出と機械学習の2つの部分に別れる l 機械学習 l 分類問題、特にオンライン線形分類器を実装 l さらに分散学習している l 特徴抽出 l 誰にでも簡単に機械学習を! l 現在はテキストデータと数値データのみに対応 l 皆さん使ってみてください! 40
41.
ご清聴ありがとうございました 41
Download

















![⼊入⼒力力データの与え⽅方
( [ ("user/id", "ippy"),
("user/name", "Loren Ipsum"),
("message", "<H>Hello World</H>") ],
[ ("user/age", 29) ,
("user/income", 100000) ] )
l 与えられるデータはシンプルなキー・バリュー
l バリューは⽂文字列列と数値のみ
l 画像や⾳音声などの扱いは今後検討・・・
l 各プログラミング⾔言語ごとに与え⽅方は微妙に異異なる
25](https://image.slidesharecdn.com/20111107jubatusmachinelearning-111107235740-phpapp02/85/Jubatus-25-320.jpg)
![⼊入⼒力力データの与え⽅方 ⽂文字列列情報
⽂文字列列のキー ⽂文字列列の値
( [ ("user/id", "ippy"),
("user/name", "Loren Ipsum"),
("message", "<H>Hello World</H>") ],
[ ("user/age", 29) ,
("user/income", 100000) ] )
l タプルの1番⽬目の要素は⽂文字列列のデータ
l 効率率率の都合でタプルの配列列
26](https://image.slidesharecdn.com/20111107jubatusmachinelearning-111107235740-phpapp02/85/Jubatus-26-320.jpg)
![⼊入⼒力力データの与え⽅方 数値情報
( [ ("user/id", "ippy"),
("user/name", "Loren Ipsum"),
("message", "<H>Hello World</H>") ],
[ ("user/age", 29) ,
("user/income", 100000) ] )
⽂文字列列のキー 数値型の値
l タプルの2番⽬目の要素は数値型のデータ
l これもタプルの配列列
27](https://image.slidesharecdn.com/20111107jubatusmachinelearning-111107235740-phpapp02/85/Jubatus-27-320.jpg)
![特徴抽出に基本的な考え⽅方
( [ ("user/id", "ippy"), タグの除去
("user/name", "Loren Ipsum"),
("message", "<H>Hello World</H>") ],
[ ("user/age", 29) ,
("user/income", 100000) ] ) 単語の抽出
l ⽣生のデータはこのままでは扱えない
l ⽣生データから必要な情報を取り出してベクトルに変換す
る
28](https://image.slidesharecdn.com/20111107jubatusmachinelearning-111107235740-phpapp02/85/Jubatus-28-320.jpg)
![変換規則の書き⽅方の例例
{
"string_filter_types": {}, ⽂文字列列フィルター
"string_filter_rules": [],
"num_filter_types": {},
"num_filter_rules": [],
数値フィルター
"string_types": {},
"string_rules":
[ { "key": "*", "type": "space",
"sample_weight": "bin”,
"global_weight": "bin" } ⽂文字列列特徴
],
"num_types": {},
"num_rules": [ 数値特徴
{ "key": "*", "type": "num" }
]
} もう少し簡単に書けるようにしたい…
29](https://image.slidesharecdn.com/20111107jubatusmachinelearning-111107235740-phpapp02/85/Jubatus-29-320.jpg)
![特徴抽出規則の書き⽅方
1. マッチ規則
“string_rules”: [
{ "key": "*", 2. 特徴抽出の⼿手法
"type": "space",
"sample_weight": "bin”,
3. 重み付け
"global_weight": "bin" } ]
l 上記の設定は、
1. すべてのキーに対して、
2. ”space”という特徴抽出を施して、
3. 重みを1に設定する
l ということを書いている
l num_rulesも基本的に同じ
30](https://image.slidesharecdn.com/20111107jubatusmachinelearning-111107235740-phpapp02/85/Jubatus-30-320.jpg)
![引数の必要な特徴抽出器の書き⽅方
変換の名前
"string_types": {
"bigram": {
種類
"method": "ngram",
"char_num": "2" } },
"string_rules”: [ 引数(method依存)
{ "key": "message",
"type": "bigram", ruleに指定
"sample_weight": "tf",
"global_weight": "bin" }, …]
l XXX_typesで引数付きで抽出器を定義
l 定義の仕⽅方はマニュアル参照
l あとは、XXX_rulesで使えるようになる
31](https://image.slidesharecdn.com/20111107jubatusmachinelearning-111107235740-phpapp02/85/Jubatus-31-320.jpg)

![フィルターを掛けてから処理理する⽅方法
“string_filter_types”: { 正規表現フィルター
“detag”: {
“method”: “regexp”,
パターン
“pattern”: “<[^>]*>”,
“replace”: “” }, …
}, … 置き換え⽂文字列列
“string_filter_rules”: [
{ “key”: “message”,
“type”: “detag”, 変換後の格納先
“suffix”: “-detagged”}, … ]
l xxx_types で定義を書く
l xxx_rules で適⽤用規則を書く
33](https://image.slidesharecdn.com/20111107jubatusmachinelearning-111107235740-phpapp02/85/Jubatus-33-320.jpg)






























































































