Downloaded 2,612 times













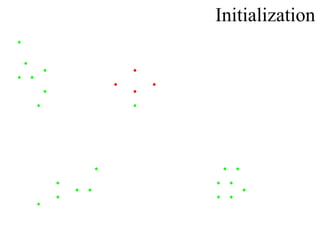
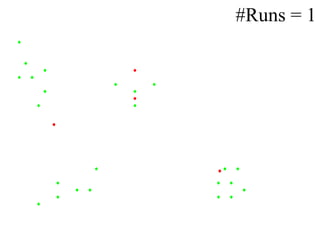








K-means clustering is an algorithm that groups data points into k number of clusters based on their similarity. It works by randomly selecting k data points as initial cluster centroids and then assigning each remaining point to the closest centroid. It then recalculates the centroids and reassigns points in an iterative process until centroids stabilize. While efficient, k-means clustering has weaknesses in that it requires specifying k, can get stuck in local optima, and is not suitable for non-convex shaped clusters or noisy data.





















































































![Assignment for Factory Method Design Pattern in C# [ANSWERS]](https://cdn.slidesharecdn.com/ss_thumbnails/assingment1answers-200420114633-thumbnail.jpg?width=640&height=640&fit=bounds)



















![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

