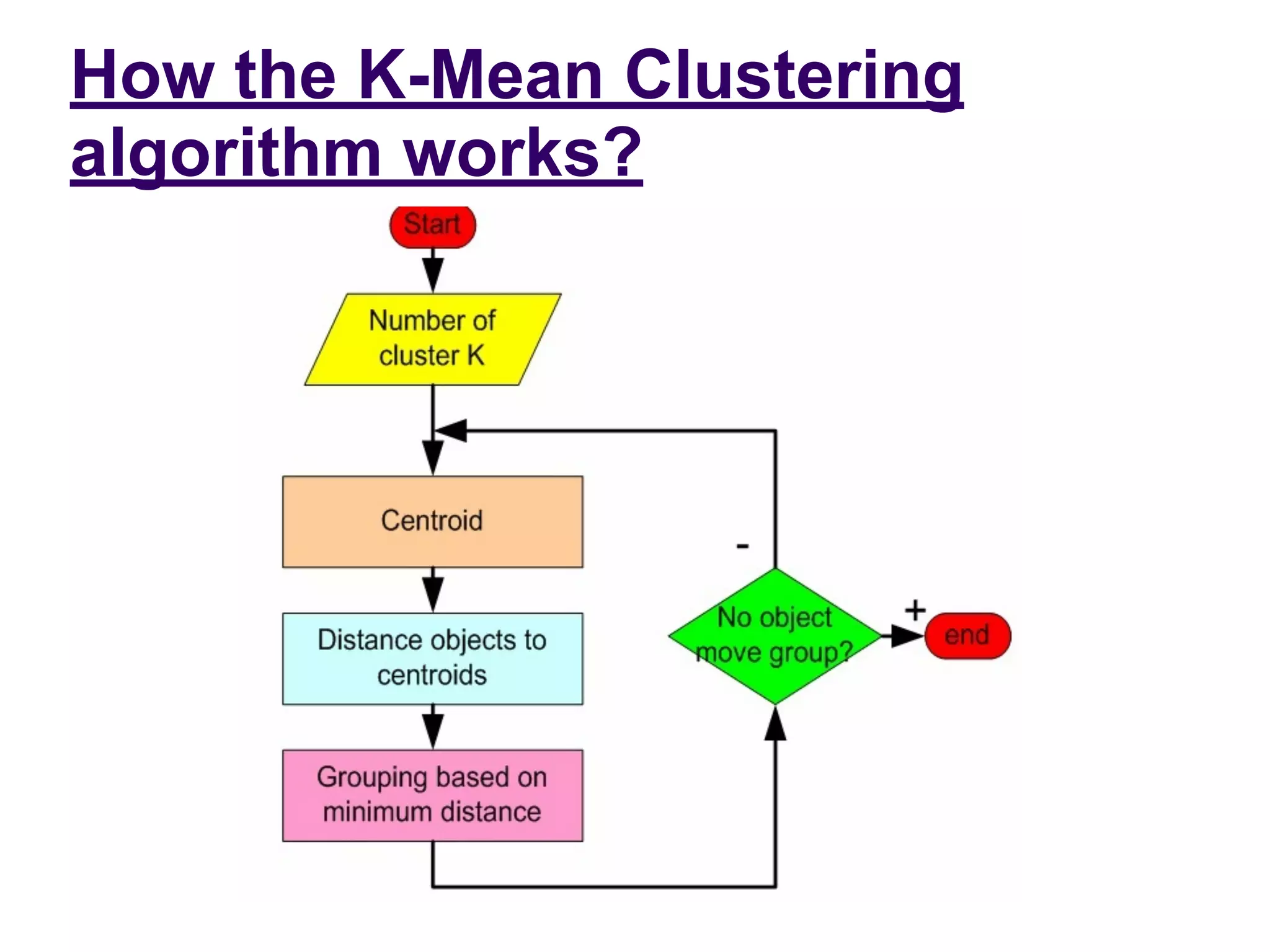
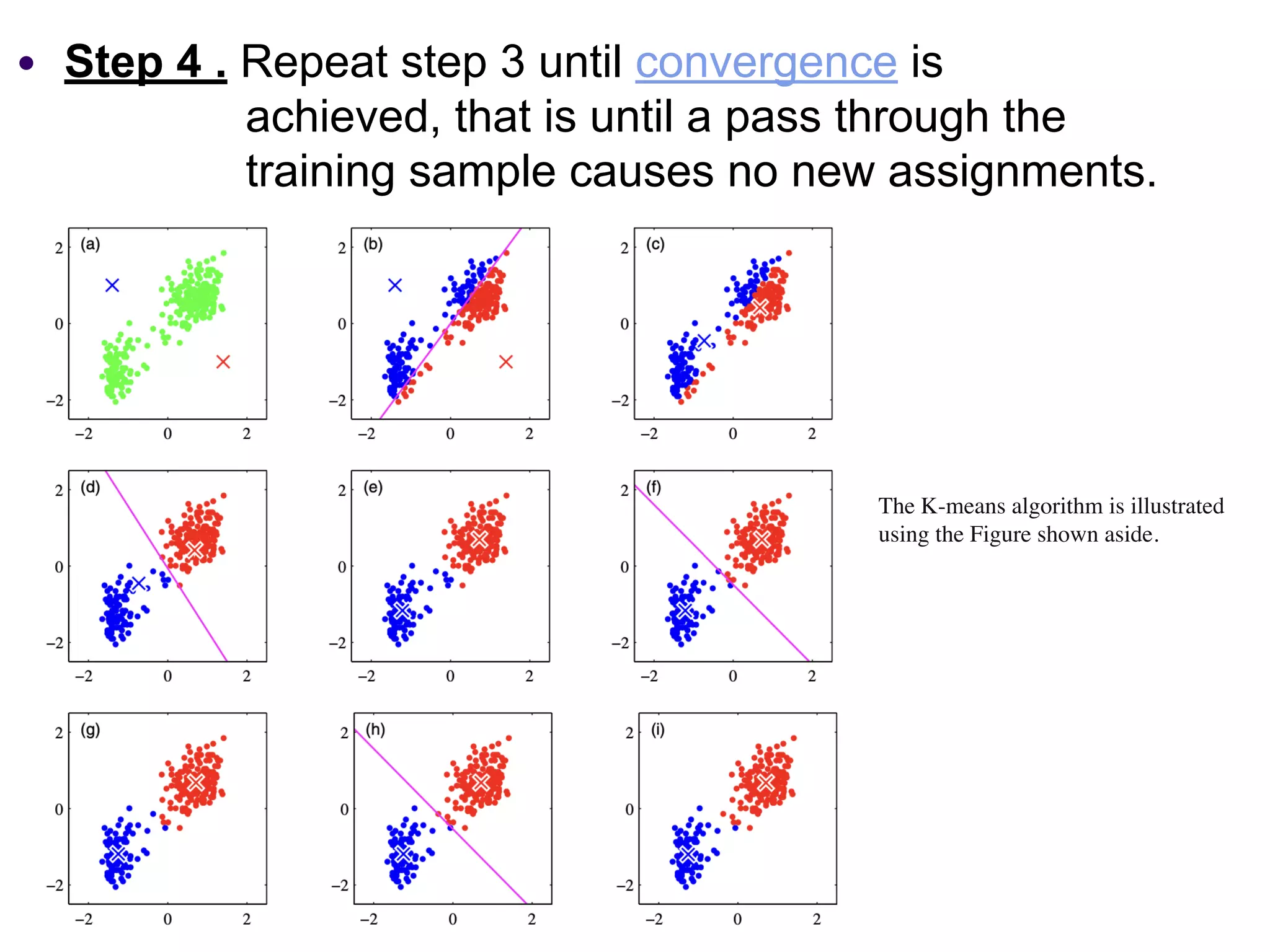
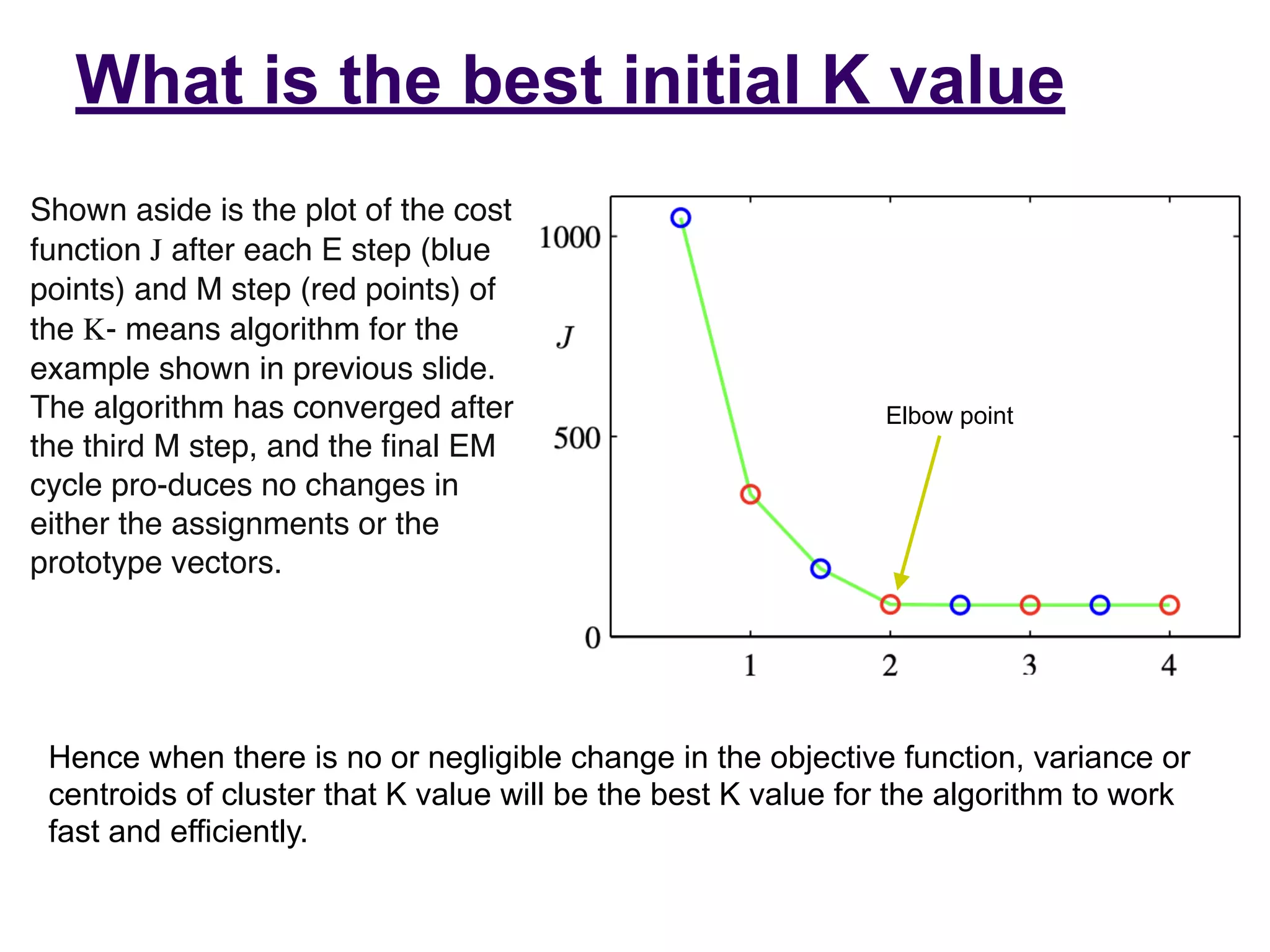
The document provides an overview of k-means clustering, a method for partitioning a data set into k distinct groups based on similarity measures, particularly the Euclidean distance. It outlines the algorithm's steps, its sensitivity to initial conditions, and its applications in areas such as machine learning and image segmentation. Additionally, it discusses the limitations of k-means clustering, including dependency on initial groupings and varying results with different data orders.







![Applications of K-Mean
Clustering
● It is relatively efficient and fast. It computes result at O(kn),
where n is number of objects or points and k is number of
clusters.
● k-means clustering can be applied to machine learning or
data mining
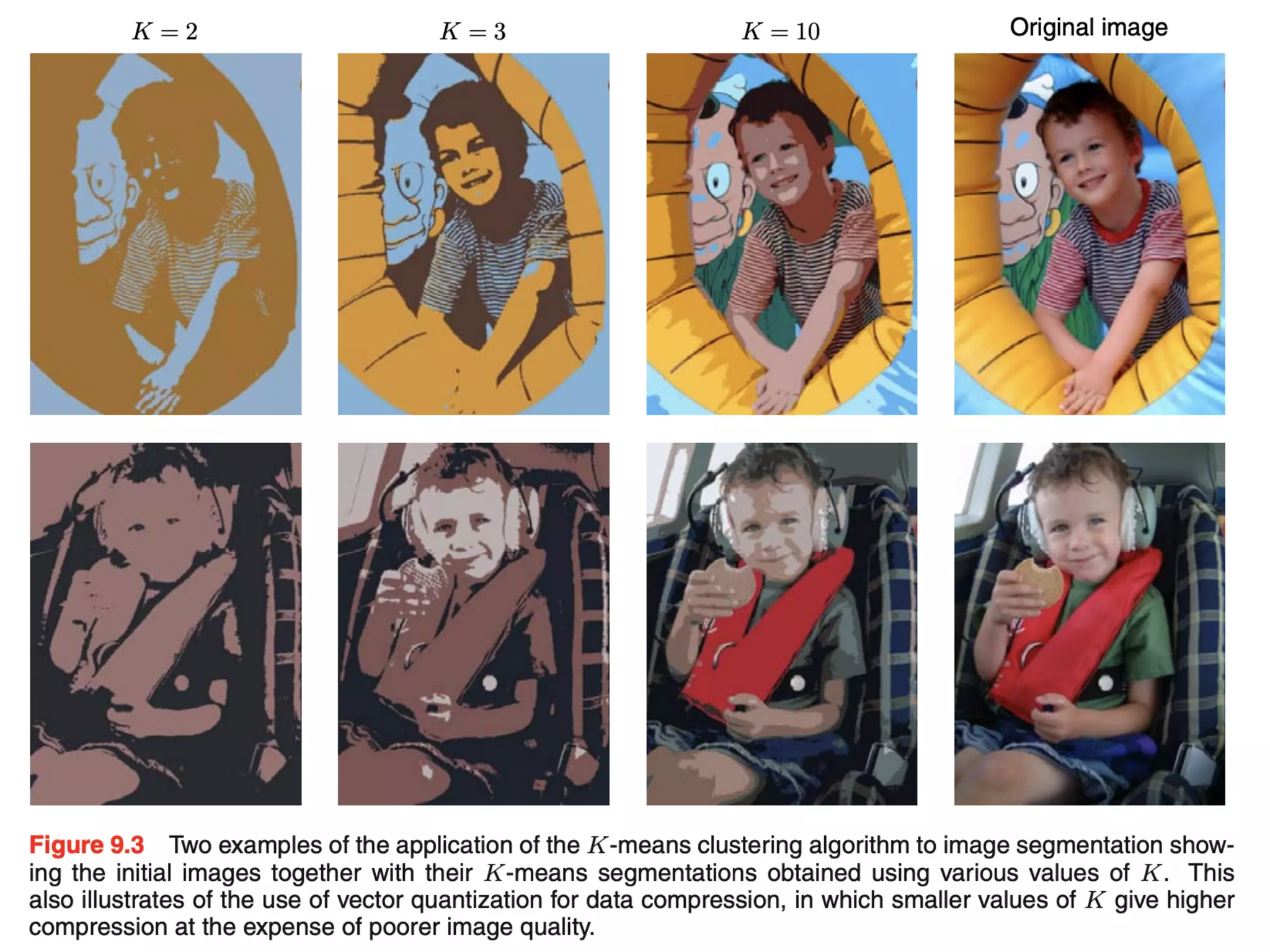
• It can be used in Image Segmentation.(example of image
segmentation is as follows)
• Each pixel in an image is a point in a 3-dimensional space
comprising the intensities of the red, blue, and green
channels, and our segmentation algorithm simply treats
each pixel in the image as a separate data point. Note that
strictly this space is not Euclidean because the channel
intensities are bounded by the interval [0, 1].
•](https://image.slidesharecdn.com/k-mean-clustering-230414062502-f9d7e521/75/k-mean-clustering-pdf-11-2048.jpg)