Download to read offline





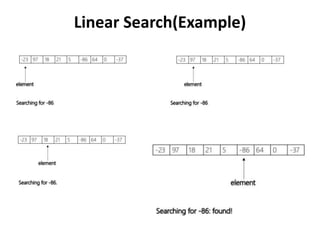

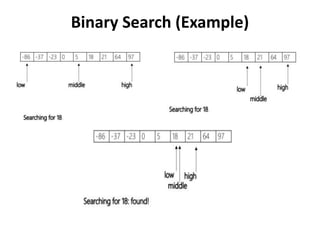
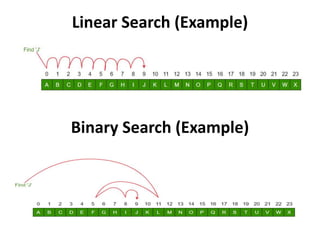

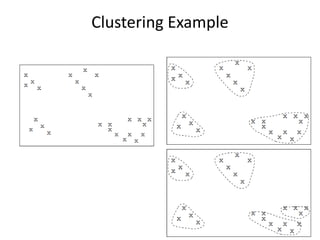


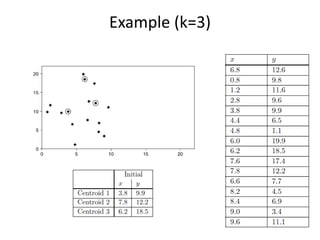
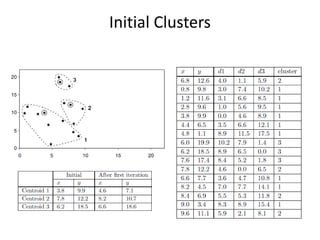
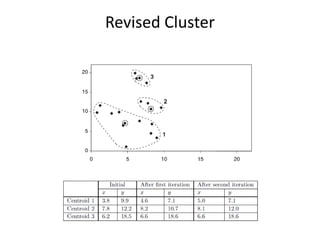





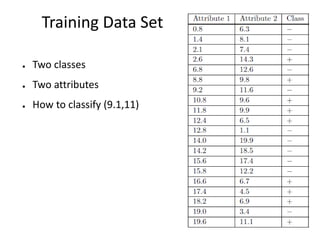
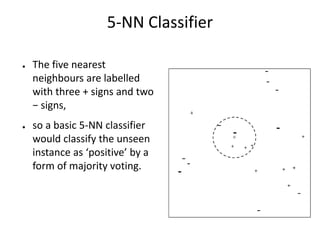
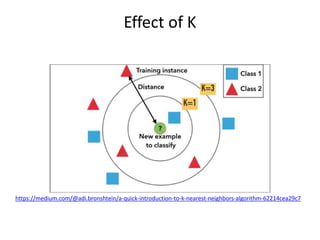

CSCI101 covers algorithms for searching, clustering, and classification. It discusses linear search, binary search, k-means clustering which groups similar objects, and k-nearest neighbors classification which assigns categories to new objects based on similarity to training examples. Examples are provided to illustrate key steps for each algorithm.



































































