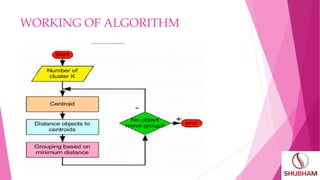
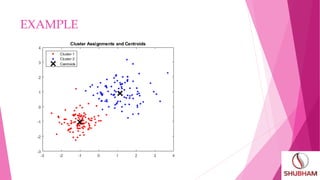
This document outlines topics to be covered in a presentation on K-means clustering. It will discuss the introduction of K-means clustering, how the algorithm works, provide an example, and applications. The key aspects are that K-means clustering partitions data into K clusters based on similarity, assigns data points to the closest centroid, and recalculates centroids until clusters are stable. It is commonly used for market segmentation, computer vision, astronomy, and agriculture.