Downloaded 87 times







![Understanding data - Vectors
X = 5 , Y = 3
(5, 3)
Y
X
• The vector denoted by point (5, 3) is simply
Array([5, 3]) or HashMap([0 => 5], [1 => 3])](https://image.slidesharecdn.com/05-k-meansclustering-141206232253-conversion-gate01/85/05-k-means-clustering-9-320.jpg)
![Representing Vectors – The basics
• Now think 3, 4, 5, ….. n-dimensional
• Think of a document as a bag of words.
“she sells sea shells on the sea shore”
• Now map them to integers
she => 0
sells => 1
sea => 2
and so on
• The resulting vector [1.0, 1.0, 2.0, … ]](https://image.slidesharecdn.com/05-k-meansclustering-141206232253-conversion-gate01/85/05-k-means-clustering-10-320.jpg)




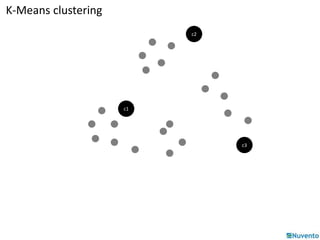
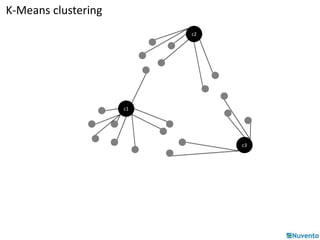
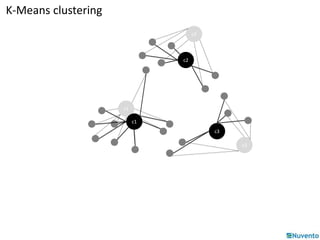
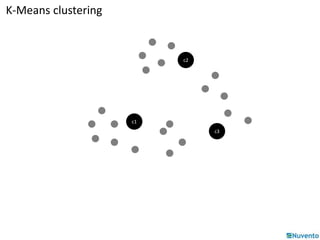















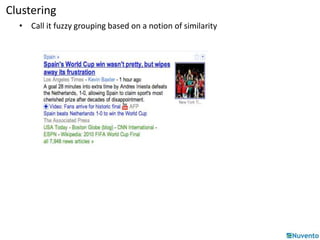
K-Means clustering is an algorithm that partitions data points into k clusters based on their distances from initial cluster center points. It is commonly used for classification applications on large datasets and can be parallelized by duplicating cluster centers and processing each data point independently. Mahout provides implementations of K-Means clustering and other algorithms that can operate on distributed datasets stored in Hadoop SequenceFiles.


















































![[ML]-Unsupervised-learning_Unit2.ppt.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ml-unsupervised-learningunit2-230916145038-acbd0397-thumbnail.jpg?width=640&height=640&fit=bounds)











































