Download as PDF, PPTX
![1
K-Means
Class Algorithmic Methods of Data Mining
Program M. Sc. Data Science
University Sapienza University of Rome
Semester Fall 2015
Lecturer Carlos Castillo http://chato.cl/
Sources:
● Mohammed J. Zaki, Wagner Meira, Jr., Data Mining and Analysis:
Fundamental Concepts and Algorithms, Cambridge University
Press, May 2014. Example 13.1. [download]
● Evimaria Terzi: Data Mining course at Boston University
http://www.cs.bu.edu/~evimaria/cs565-13.html](https://image.slidesharecdn.com/s3o456brqtm41i9vhb1q-signature-d503319da1301971aeeaa1b7e38d890bf394f7e6fb2415f661de7d4d58f0c518-poli-151222093950/85/K-Means-Algorithm-1-320.jpg)
![1
K-Means
Class Algorithmic Methods of Data Mining
Program M. Sc. Data Science
University Sapienza University of Rome
Semester Fall 2015
Lecturer Carlos Castillo http://chato.cl/
Sources:
● Mohammed J. Zaki, Wagner Meira, Jr., Data Mining and Analysis:
Fundamental Concepts and Algorithms, Cambridge University
Press, May 2014. Example 13.1. [download]
● Evimaria Terzi: Data Mining course at Boston University
http://www.cs.bu.edu/~evimaria/cs565-13.html](https://image.slidesharecdn.com/s3o456brqtm41i9vhb1q-signature-d503319da1301971aeeaa1b7e38d890bf394f7e6fb2415f661de7d4d58f0c518-poli-151222093950/75/K-Means-Algorithm-1-2048.jpg)





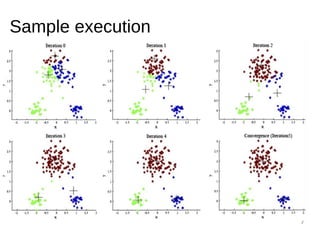


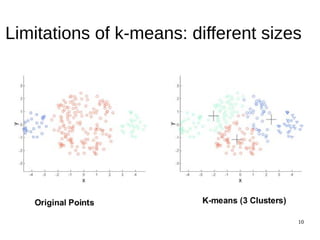
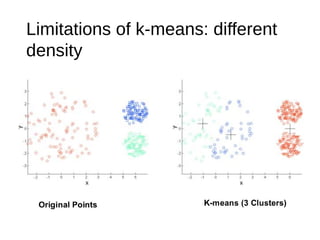
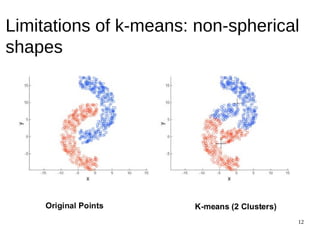










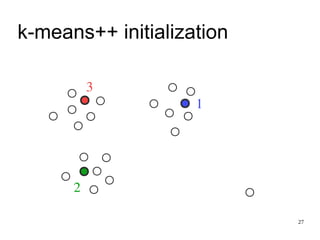



![31
k-means--
● Algorithm 4.1 in [Chawla & Gionis SDM 2013]](https://image.slidesharecdn.com/s3o456brqtm41i9vhb1q-signature-d503319da1301971aeeaa1b7e38d890bf394f7e6fb2415f661de7d4d58f0c518-poli-151222093950/85/K-Means-Algorithm-31-320.jpg)

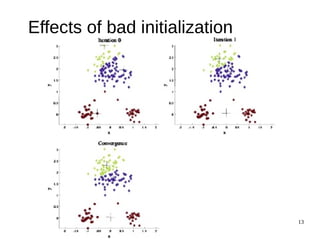
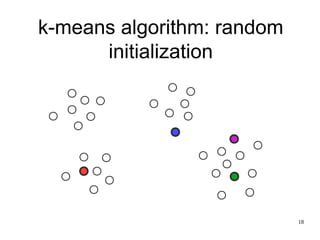
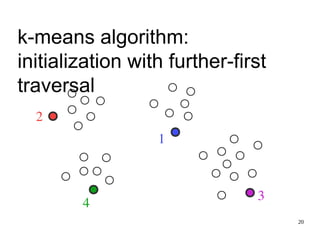
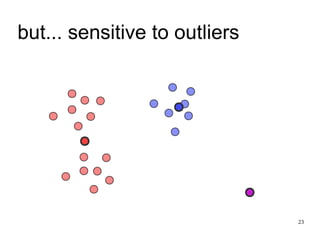
The document discusses the k-means clustering algorithm, highlighting its purpose of minimizing cost by finding cluster centers for a given set of points. It explains the limitations of k-means, such as sensitivity to initialization and inability to handle clusters of varying densities and shapes. Additionally, it introduces k-means++, an improved version with better initialization that enhances performance and guarantees improved results.











































































































