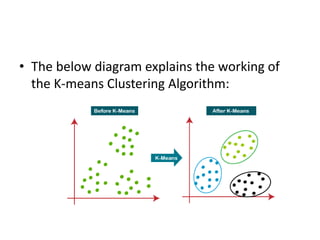
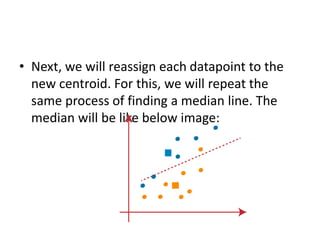
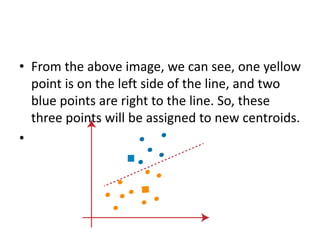
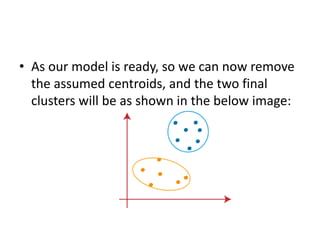
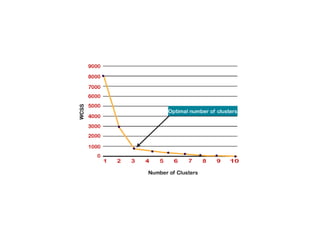
The k-means clustering algorithm is an unsupervised machine learning algorithm that groups unlabeled data points into k number of clusters. It works by first selecting k random cluster centroids and then assigns each data point to its nearest centroid, forming k clusters. It then recalculates the positions of the centroids and reassigns data points in an iterative process until centroids stabilize. The optimal number of clusters k can be determined using the elbow method by plotting the within-cluster sum of squares against k and selecting the k value at the point of inflection of the curve, resembling an elbow.