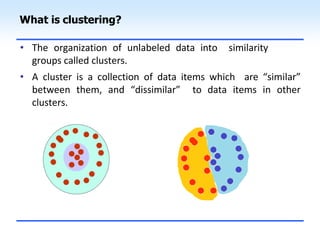
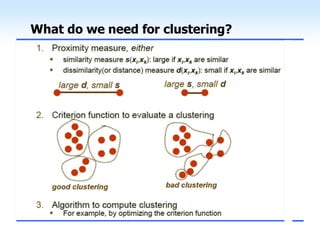
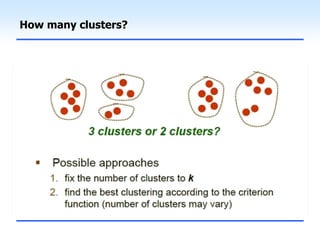
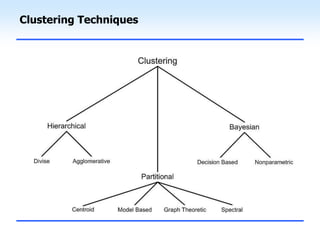
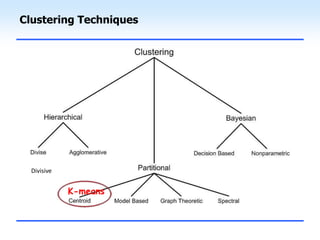
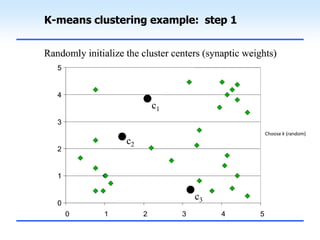
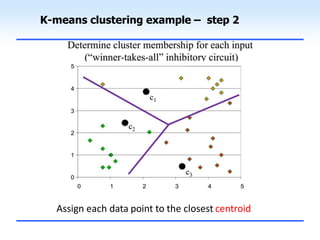
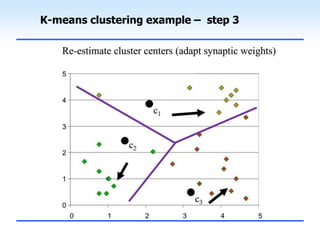
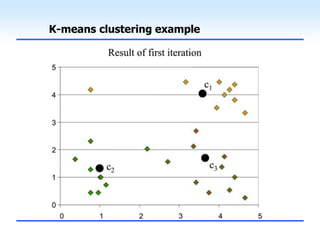
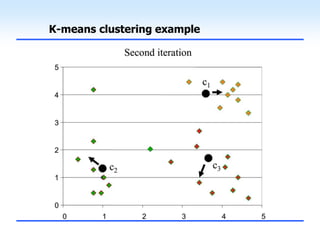
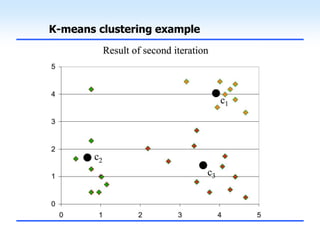
This document discusses unsupervised learning and clustering. It defines unsupervised learning as modeling the underlying structure or distribution of input data without corresponding output variables. Clustering is described as organizing unlabeled data into groups of similar items called clusters. The document focuses on k-means clustering, describing it as a method that partitions data into k clusters by minimizing distances between points and cluster centers. It provides details on the k-means algorithm and gives examples of its steps. Strengths and weaknesses of k-means clustering are also summarized.


















































![[ML]-Unsupervised-learning_Unit2.ppt.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ml-unsupervised-learningunit2-230916145038-acbd0397-thumbnail.jpg?width=640&height=640&fit=bounds)





![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)











![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










