Downloaded 67 times



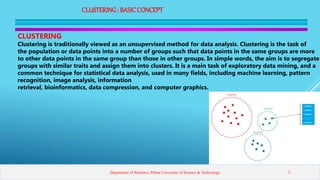


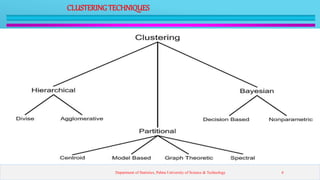




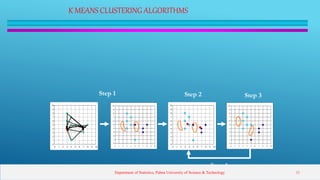












This presentation introduces clustering analysis and the k-means clustering technique. It defines clustering as an unsupervised method to segment data into groups with similar traits. The presentation outlines different clustering types (hard vs soft), techniques (partitioning, hierarchical, etc.), and describes the k-means algorithm in detail through multiple steps. It discusses requirements for clustering, provides examples of applications, and reviews advantages and disadvantages of k-means clustering.



































![Clustering[306] [Read-Only].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/clustering306read-only-230112103535-3fb144db-thumbnail.jpg?width=640&height=640&fit=bounds)







![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)

















![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)




