Download as PDF, PPTX



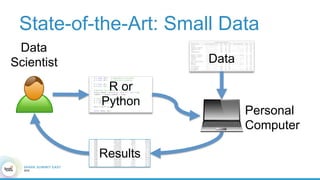
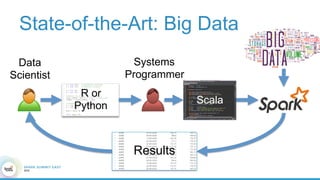

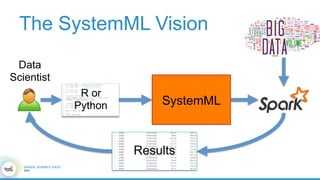
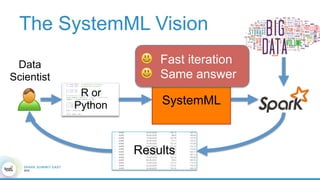
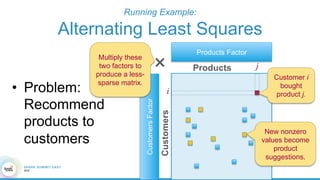










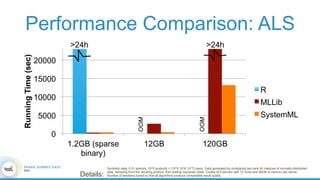

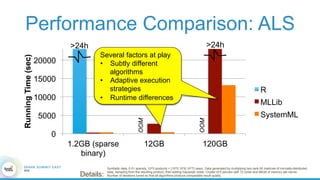

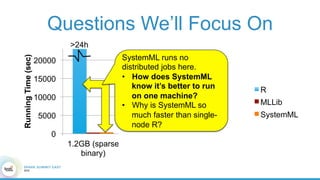
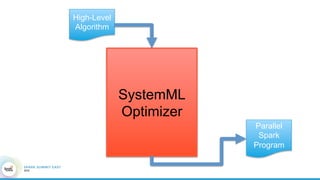
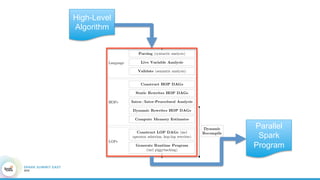
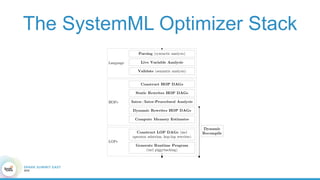



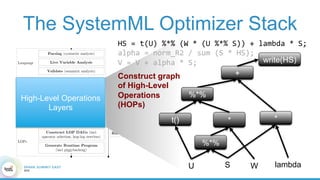
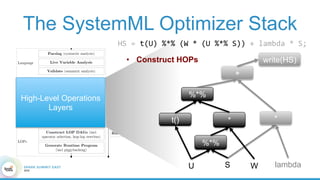
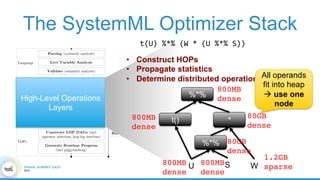

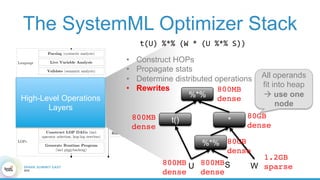
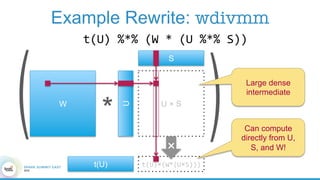
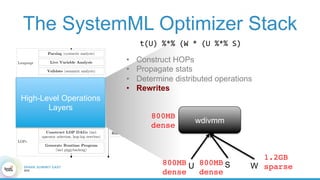

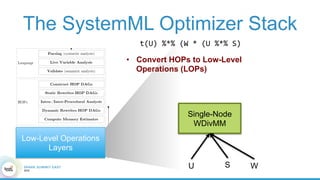
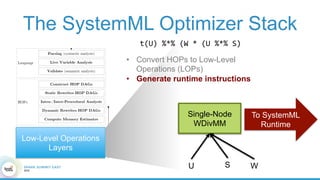



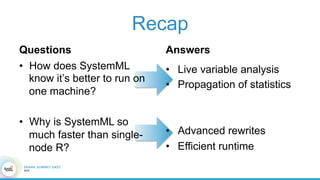




1. The document describes the origins and goals of the SystemML project for scalable machine learning. 2. SystemML was created to allow data scientists to write machine learning algorithms in R and automatically compile and optimize them to run efficiently on large datasets in parallel. 3. An example alternating least squares algorithm is shown written concisely in R, while traditional approaches required translating algorithms to other languages like Scala which was error-prone and slowed iteration. SystemML aims to allow the same algorithm to run fast at large scale with the same answer.































































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)


![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)



