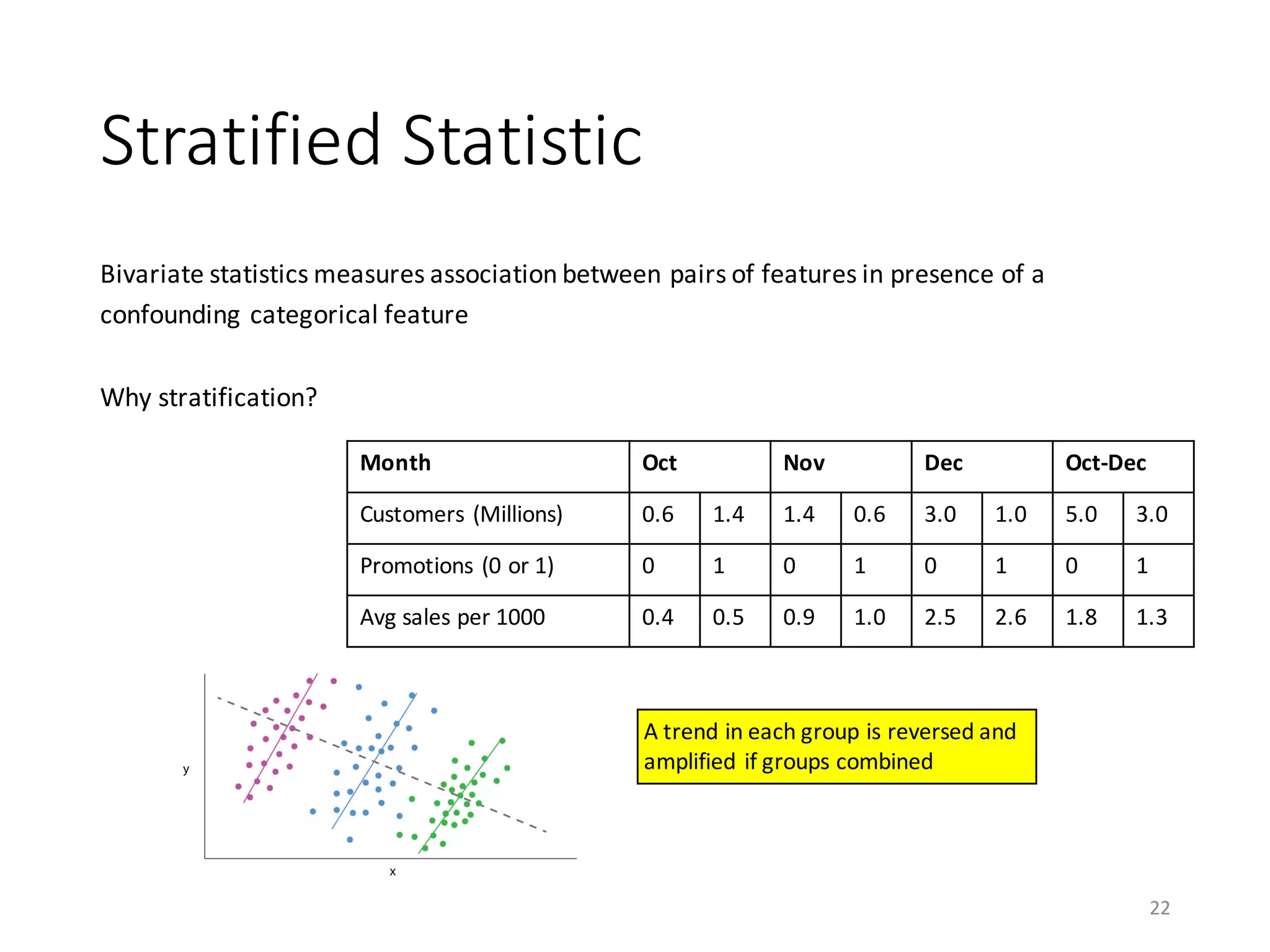
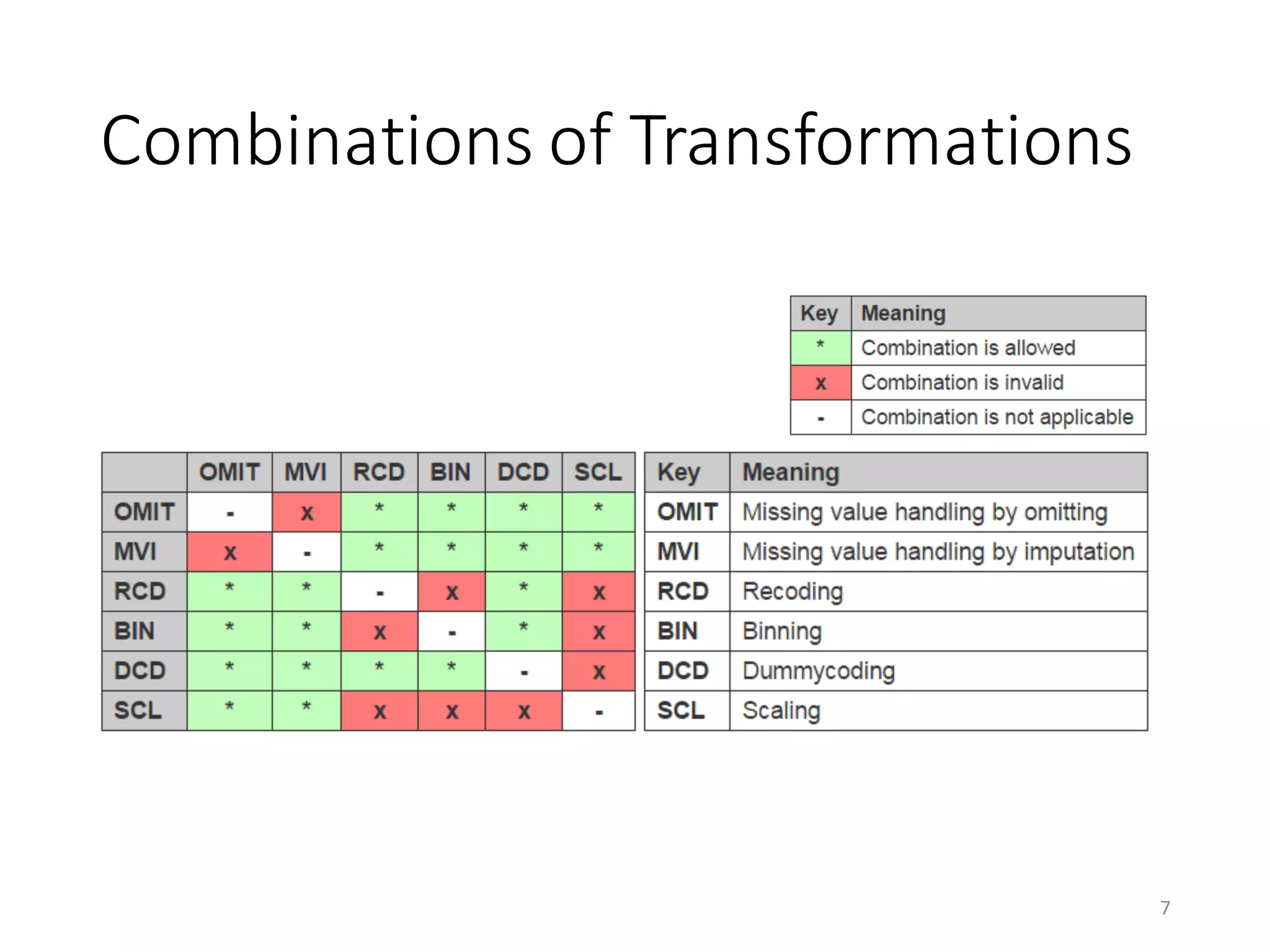
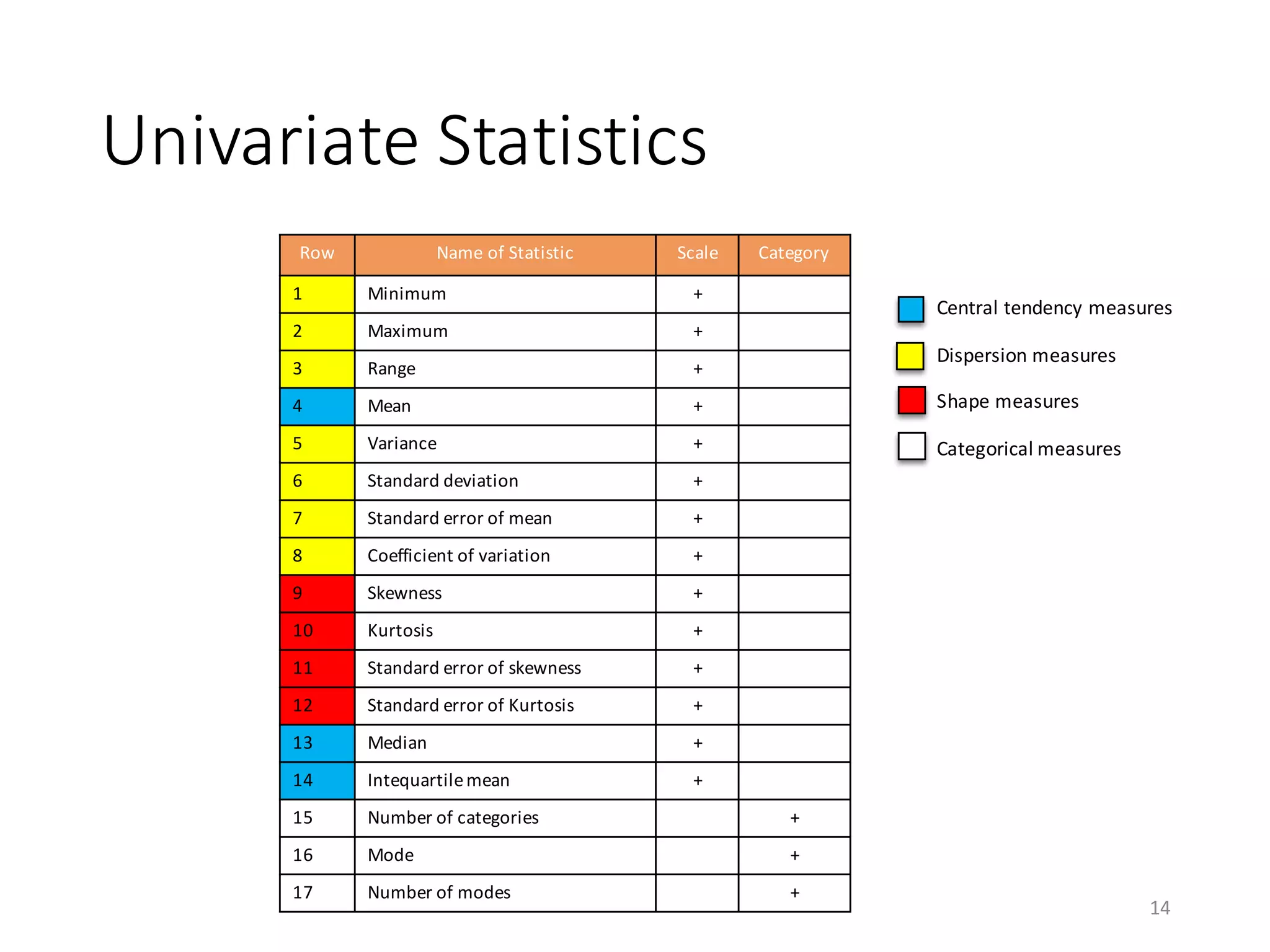
This document provides an overview of data preparation and descriptive statistics in SystemML. It discusses data formatting, pre-processing such as transforming categorical features and handling missing values, and descriptive statistics including univariate, bivariate, and stratified statistics. Univariate statistics describe the distribution of individual variables, bivariate statistics measure associations between pairs of variables, and stratified statistics measure associations between variables within subgroups defined by a categorical variable to control for confounding.





![Transform Specification
§ Transformations operate on individual columns
§ All required transformations specified in a JSON file
§ Property na.strings in the mtd file specifies missing values
Example:
data.spec.json data.csv.mtd
6
{
"data_type": "frame",
"format": "csv",
"sep": ",",
"header": true,
"na.strings": [ "NA", "" ]
}
{
“ids": true
, "omit": [ 1, 4, 5, 6, 7, 8, 9 ]
, "impute":
[ { “id": 2, "method": "constant",
"value": "south" }
,{ “id": 3, "method":
"global_mean" }
]
,"recode": [ 1, 2, 4, 5, 6, 7 ]
,"bin":
[ { “id": 8, "method": "equi-
width", "numbins": 3 } ]
,"dummycode": [ 2, 5, 6, 7, 8, 3 ]
}](https://image.slidesharecdn.com/s2datapreparationanddescriptivestatisticsinsystemml-160913180332/75/Data-preparation-training-and-validation-using-SystemML-by-Faraz-Makari-Manshadi-6-2048.jpg)







![Scale-vs-Scale Statistics
Pearson’s correlation coefficient
§ A measure of linear dependence between scale features
§ 𝜌)
measures accuracy of 𝑥) ~ 𝑥0
16
𝜌 =
123(56,57)
9:69:7
, 𝜌 ∈ [−1,+1]
1 − 𝜌)
=
∑ 𝑥A,) − 𝑥BA,)
)C
AD0
∑ 𝑥A,) − 𝑥̅A,)
)C
AD0
Residual Sum of Squares (RSS)
Total Sum of Squares (TSS)](https://image.slidesharecdn.com/s2datapreparationanddescriptivestatisticsinsystemml-160913180332/75/Data-preparation-training-and-validation-using-SystemML-by-Faraz-Makari-Manshadi-16-2048.jpg)


![Nominal-vs-Scale Statistics
Eta statistic
§ A measure for the strength of association between a categorical feature and a scale
feature
§ 𝜂)
measures accuracy of 𝑦 ~ 𝑥 similar to 𝑅)
statistic of linear regression
19
𝜂)
= 1 −
∑ 𝑦A − 𝑦B[𝑥A] )C
AD0
∑ 𝑦A − 𝑦k )C
AD0
RSS
TSS
𝑥 categorical
𝑦 scale
𝑦B[𝑥A]: average of 𝑦A among all records with
𝑥A = 𝑥](https://image.slidesharecdn.com/s2datapreparationanddescriptivestatisticsinsystemml-160913180332/75/Data-preparation-training-and-validation-using-SystemML-by-Faraz-Makari-Manshadi-19-2048.jpg)

![Ordinal-vs-Ordinal Statistics
Spearman’s rank correlation coefficient
§ A measure for the strength of association between two ordinal features
§ Pearson’s correlation efficient applied to feature with values replaced by their ranks
Example:
21
8x
3)
11z
8{
5|
20
𝑥′
8
3
11
8
5
2
𝑥
4.5
2
6
4.5
3
1
𝑟
𝜌 =
123 (•6,•7)
9‚69‚7
𝜌 ∈ [−1, +1]](https://image.slidesharecdn.com/s2datapreparationanddescriptivestatisticsinsystemml-160913180332/75/Data-preparation-training-and-validation-using-SystemML-by-Faraz-Makari-Manshadi-21-2048.jpg)