Downloaded 43 times

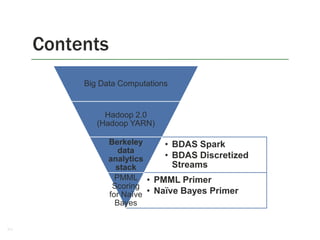
![Big Data Computations
Computations/Operations
Giant 1 (simple stats) is perfect
for Hadoop 1.0.
Giants 2 (linear algebra), 3 (Nbody), 4 (optimization) Spark
from UC Berkeley is efficient.
Interactive/On-the-fly data
processing – Storm.
Logistic regression, kernel SVMs,
conjugate gradient descent,
collaborative filtering, Gibbs
sampling, alternating least squares.
Example is social group-first
approach for consumer churn
analysis [2]
OLAP – data cube operations.
Dremel/Drill
Data sets – not embarrassingly
parallel?
Machine vision from Google [3]
Deep Learning
Artificial Neural Networks
Speech analysis from Microsoft
Giant 5 – Graph processing –
GraphLab, Pregel, Giraph
3
[1] National Research Council. Frontiers in Massive Data Analysis . Washington, DC: The National Academies Press, 2013.
[2] Richter, Yossi ; Yom-Tov, Elad ; Slonim, Noam: Predicting Customer Churn in Mobile Networks through Analysis of Social
Groups. In: Proceedings of SIAM International Conference on Data Mining, 2010, S. 732-741
[3] Jeffrey Dean, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Quoc V. Le, Mark Z. Mao, Marc'Aurelio
Ranzato, Andrew W. Senior, Paul A. Tucker, Ke Yang, Andrew Y. Ng: Large Scale Distributed Deep Networks. NIPS 2012:](https://image.slidesharecdn.com/yarnsparknextgenhadoop8jan2014-140108222152-phpapp02/85/Yarn-spark-next_gen_hadoop_8_jan_2014-3-320.jpg)

![Iterative ML Algorithms
What are iterative algorithms?
Those that need communication among the computing entities
Examples – neural networks, PageRank algorithms, network traffic analysis
Conjugate gradient descent
Commonly used to solve systems of linear equations
[CB09] tried implementing CG on dense matrices
DAXPY – Multiplies vector x by constant a and adds y.
DDOT – Dot product of 2 vectors
MatVec – Multiply matrix by vector, produce a vector.
1 MR per primitive – 6 MRs per CG iteration, hundreds of MRs per CG
computation, leading to 10 of GBs of communication even for small
matrices.
Other iterative algorithms – fast fourier transform, block tridiagonal
[CB09] C. Bunch, B. Drawert, M. Norman, Mapscale: a cloud environment for scientific computing,
Technical Report, University of California, Computer Science Department, 2009.](https://image.slidesharecdn.com/yarnsparknextgenhadoop8jan2014-140108222152-phpapp02/85/Yarn-spark-next_gen_hadoop_8_jan_2014-5-320.jpg)
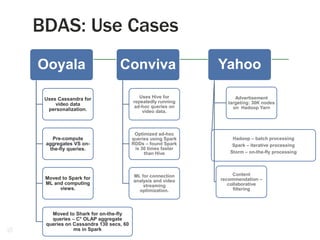
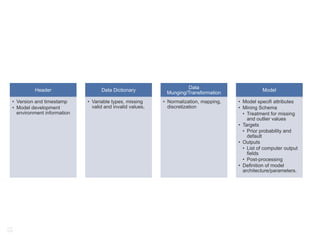
![BDAS: Spark
Transformations/Actions
Map(function f1)
Filter(function f2)
flatMap(function f3)
Union(RDD r1)
Sample(flag, p, seed)
groupByKey(noTasks)
Description
Pass each element of the RDD through f1 in parallel and return the resulting RDD.
Select elements of RDD that return true when passed through f2.
Similar to Map, but f3 returns a sequence to facilitate mapping single input to multiple
outputs.
Returns result of union of the RDD r1 with the self.
Returns a randomly sampled (with seed) p percentage of the RDD.
Can only be invoked on key-value paired data – returns data grouped by value. No. of
parallel tasks is given as an argument (default is 8).
Aggregates result of applying f4 on elements with same key. No. of parallel tasks is the
second argument.
Joins RDD r2 with self – computes all possible pairs for given key.
Joins RDD r3 with self and groups by key.
reduceByKey(function f4,
noTasks)
Join(RDD r2, noTasks)
groupWith(RDD r3,
noTasks)
sortByKey(flag)
Sorts the self RDD in ascending or descending based on flag.
Reduce(function f5)
Aggregates result of applying function f5 on all elements of self RDD
Collect()
Return all elements of the RDD as an array.
Count()
Count no. of elements in RDD
take(n)
Get first n elements of RDD.
First()
Equivalent to take(1)
saveAsTextFile(path)
Persists RDD in a file in HDFS or other Hadoop supported file system at given path.
saveAsSequenceFile(path Persist RDD as a Hadoop sequence file. Can be invoked only on key-value paired RDDs
)
that implement Hadoop writable interface or equivalent.
foreach(function f6)
Run f6 in parallel on elements of self Ankur
[MZ12] Matei Zaharia, Mosharaf Chowdhury, Tathagata Das,RDD. Dave, Justin Ma, Murphy McCauley, Michael
J. Franklin, Scott Shenker, and Ion Stoica. 2012. Resilient distributed datasets: a fault-tolerant abstraction for inmemory cluster computing. In Proceedings of the 9th USENIX conference on Networked Systems Design and
Implementation (NSDI'12). USENIX Association, Berkeley, CA, USA, 2-2.](https://image.slidesharecdn.com/yarnsparknextgenhadoop8jan2014-140108222152-phpapp02/85/Yarn-spark-next_gen_hadoop_8_jan_2014-9-320.jpg)








![Future of Spark
•
Domain specific language approach from
Stanford.
•
•
•
Forge [AKS13] – a meta DSL for high
performance DSLs.
40X faster than Spark!
Spark
•
Explore BLAS libraries for efficiency
24
[Arvind K. Sujeeth, Austin Gibbons, Kevin J. Brown, HyoukJoong Lee, Tiark Rompf, Martin Odersky, and Kunle
Olukotun. 2013. Forge: generating a high performance DSL implementation from a declarative specification.
In Proceedings of the 12th international conference on Generative programming: concepts &
experiences (GPCE '13). ACM, New York, NY, USA, 145-154.](https://image.slidesharecdn.com/yarnsparknextgenhadoop8jan2014-140108222152-phpapp02/85/Yarn-spark-next_gen_hadoop_8_jan_2014-24-320.jpg)



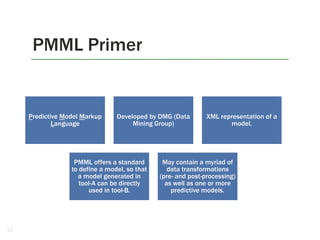
![GraphLab: Ideal Engine for Processing Natural Graphs [YL12]
Goals – targeted at machine
learning.
• Model graph dependencies, be
asynchronous, iterative, dynamic.
Data associated with edges
(weights, for instance) and
vertices (user profile data, current
interests etc.).
Update functions – lives on each
vertex
Consistency is important in ML
algorithms (some do not even
converge when there are
inconsistent updates –
collaborative filtering).
• Transforms data in scope of vertex.
• Can choose to trigger neighbours (for
example only if Rank changes drastically)
• Run asynchronously till convergence –
no global barrier.
• GraphLab – provides varying level of
consistency. Parallelism VS consistency.
Implemented several algorithms,
including ALS, K-means, SVM,
Belief propagation, matrix
factorization, Gibbs sampling,
SVD, CoEM etc.
• Co-EM (Expectation Maximization)
algorithm 15x faster than Hadoop MR –
on distributed GraphLab, only 0.3% of
Hadoop execution time.
[YL12] Yucheng Low, Danny Bickson, Joseph Gonzalez, Carlos Guestrin, Aapo Kyrola, and Joseph M. Hellerstein. 2012. Distributed
GraphLab: a framework for machine learning and data mining in the cloud. Proceedings of the VLDB Endowment 5, 8 (April 2012), 716-727.](https://image.slidesharecdn.com/yarnsparknextgenhadoop8jan2014-140108222152-phpapp02/85/Yarn-spark-next_gen_hadoop_8_jan_2014-28-320.jpg)
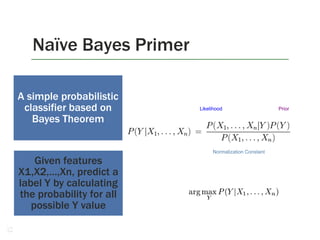
![GraphLab 2: PowerGraph – Modeling Natural Graphs [1]
GraphLab could not
scale to Altavista web
graph 2002, 1.4B
vertices, 6.7B edges.
Powergraph provides
new way of
partitioning power law
graphs
• Most graph parallel
abstractions assume small
neighbourhoods – low
degree vertices
• But natural graphs
(LinkedIn, Facebook,
Twitter) – power law
graphs.
• Hard to partition power law
graphs, high degree
vertices limit parallelism.
• Edges are tied to
machines, vertices (esp.
high degree ones) span
machines
• Execution split into 3
phases:
• Gather, apply and
scatter.
Triangle counting on
Twitter graph
• Hadoop MR took 423
minutes on 1536 machines
• GraphLab 2 took 1.5
minutes on 1024 cores (64
machines)
[1] Joseph E. Gonzalez, Yucheng Low, Haijie Gu, Danny Bickson, and Carlos Guestrin (2012). "PowerGraph:
Distributed Graph-Parallel Computation on Natural Graphs." Proceedings of the 10th USENIX Symposium
on Operating Systems Design and Implementation (OSDI '12).](https://image.slidesharecdn.com/yarnsparknextgenhadoop8jan2014-140108222152-phpapp02/85/Yarn-spark-next_gen_hadoop_8_jan_2014-29-320.jpg)

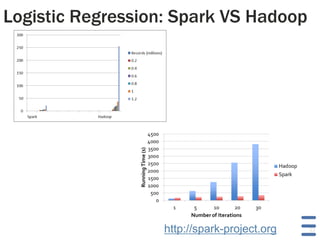





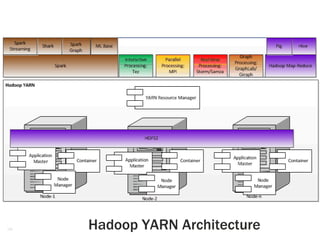
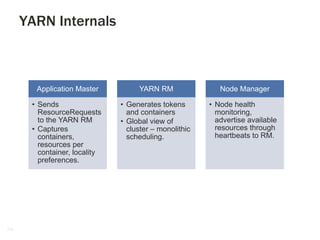
The document discusses advancements in big data processing, focusing on Apache Hadoop and Spark frameworks, particularly their architecture and functionalities like real-time processing and machine learning algorithms. It highlights the evolution of Hadoop to Yarn, addressing scalability and multi-tenancy challenges, and presents use cases that demonstrate the efficiency of Spark over Hive in data analytics. The document also covers the implementation and benefits of Predictive Model Markup Language (PMML) for integrating machine learning models across different platforms.



























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)







