Download as PDF, PPTX






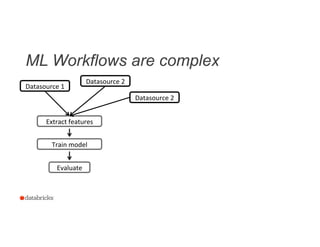



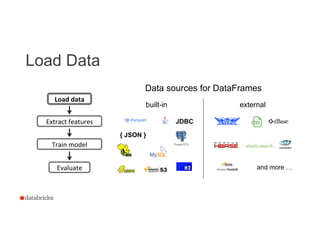


![Extract Features
16
Train
model
Evaluate
Load
data
label: Int
text: String
Current
data
schema
Tokenizer
Hashed
Term
Freq.
features: Vector
words: Seq[String]
Transformer
DataFrame
DataFrame](https://image.slidesharecdn.com/hhozkbdmsbmpmmwmwb2p-signature-9d21828b8995bb45daf6bd98ae827dae2f0010efa3f03f445d719c9fcbe7ef93-poli-150624003520-lva1-app6891/85/Building-Debugging-and-Tuning-Spark-Machine-Leaning-Pipelines-Joseph-Bradley-Databricks-16-320.jpg)
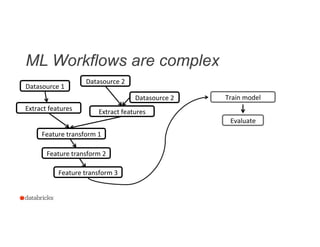
![Train a Model
17
Logis@c
Regression
Evaluate
label: Int
text: String
Current
data
schema
Tokenizer
Hashed
Term
Freq.
features: Vector
words: Seq[String]
prediction: Int
Load
data
Estimator
DataFrame
Model](https://image.slidesharecdn.com/hhozkbdmsbmpmmwmwb2p-signature-9d21828b8995bb45daf6bd98ae827dae2f0010efa3f03f445d719c9fcbe7ef93-poli-150624003520-lva1-app6891/85/Building-Debugging-and-Tuning-Spark-Machine-Leaning-Pipelines-Joseph-Bradley-Databricks-17-320.jpg)
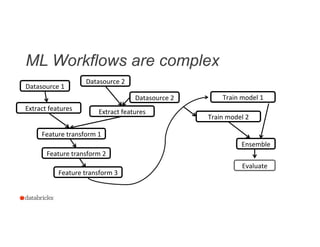
![Evaluate the Model
18
Logiscc
Regression
Evaluate
label: Int
text: String
Current
data
schema
Tokenizer
Hashed
Term
Freq.
features: Vector
words: Seq[String]
prediction: Int
Load
data
Evaluator
DataFrame
metric](https://image.slidesharecdn.com/hhozkbdmsbmpmmwmwb2p-signature-9d21828b8995bb45daf6bd98ae827dae2f0010efa3f03f445d719c9fcbe7ef93-poli-150624003520-lva1-app6891/85/Building-Debugging-and-Tuning-Spark-Machine-Leaning-Pipelines-Joseph-Bradley-Databricks-18-320.jpg)
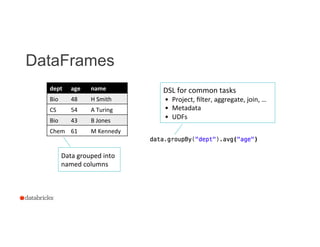
![Data Flow
19
Logiscc
Regression
Evaluate
label: Int
text: String
Current
data
schema
Tokenizer
Hashed
Term
Freq.
features: Vector
words: Seq[String]
prediction: Int
Load
data
By
default,
always
append
new
columns
à Can
go
back
&
inspect
intermediate
results
à Made
efficient
by
DataFrames](https://image.slidesharecdn.com/hhozkbdmsbmpmmwmwb2p-signature-9d21828b8995bb45daf6bd98ae827dae2f0010efa3f03f445d719c9fcbe7ef93-poli-150624003520-lva1-app6891/85/Building-Debugging-and-Tuning-Spark-Machine-Leaning-Pipelines-Joseph-Bradley-Databricks-19-320.jpg)
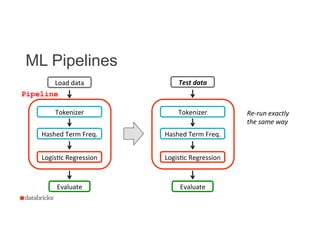
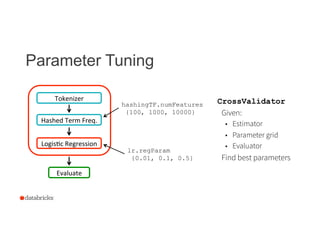






This document discusses Spark ML pipelines for machine learning workflows. It begins with an introduction to Spark MLlib and the various algorithms it supports. It then discusses how ML workflows can be complex, involving multiple data sources, feature transformations, and models. Spark ML pipelines allow specifying the entire workflow as a single pipeline object. This simplifies debugging, re-running on new data, and parameter tuning. The document provides an example text classification pipeline and demonstrates how data is transformed through each step via DataFrames. It concludes by discussing upcoming improvements to Spark ML pipelines.











































































































