Downloaded 70 times














![28
Example: Simple ranking system
High-level API: List<Video> rank(User u, List<Video> videos)
Example model description file:
{
“type”: “ScoringRanker”,
“scorer”: {
“type”: “FeatureScorer”,
“features”: [
{“type”: “Popularity”, “days”: 10},
{“type”: “PredictedRating”}
],
“function”: {
“type”: “Linear”,
“bias”: -0.5,
“weights”: {
“popularity”: 0.2,
“predictedRating”: 1.2,
“predictedRating*popularity”:
3.5
}
}
}
Ranker
Scorer
Features
Linear function
Feature transformations](https://image.slidesharecdn.com/recommendationsformlsoftwarepublic-151114003739-lva1-app6891/85/Recommendations-for-Building-Machine-Learning-Software-28-320.jpg)




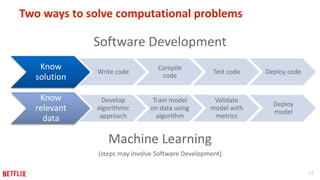



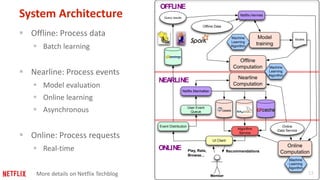
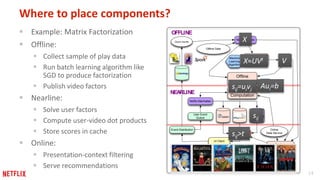
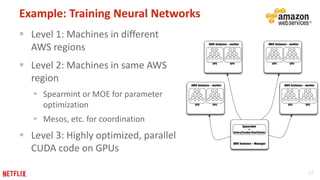
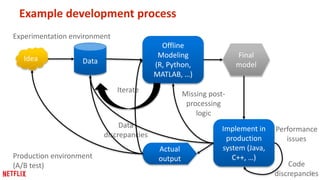
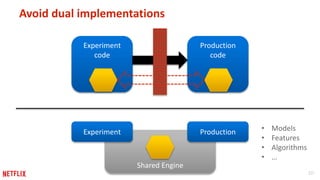
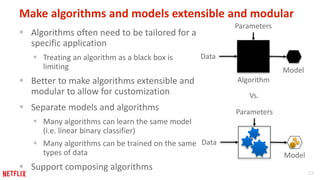
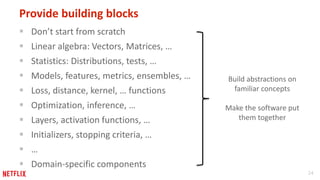
This document provides recommendations for building machine learning software from the perspective of Netflix's experience. The first recommendation is to be flexible about where and when computation happens by distributing components across offline, nearline, and online systems. The second is to think about distribution starting from the outermost levels of the problem by parallelizing across subsets of data, hyperparameters, and machines. The third recommendation is to design application software for experimentation by sharing components between experiment and production code. The fourth recommendation is to make algorithms and models extensible and modular by providing reusable building blocks. The fifth recommendation is to describe input and output transformations with models. The sixth recommendation is to not rely solely on metrics for testing and instead implement unit testing of code.















![[UPDATE] Udacity webinar on Recommendation Systems](https://cdn.slidesharecdn.com/ss_thumbnails/udacitywebinar-190716143828-thumbnail.jpg?width=640&height=640&fit=bounds)








































































