Download as PDF, PPTX


![5#UnifiedAnalytics #SparkAISummit
High Level APIs
RDD
Directed Acyclic Graph (DAG)
Lazy
Execution
Task Scheduler
Synchronous
Multiprocessing
Threaded
Local Spark Standalone
Low Level APIs
Custom
Algorithms
Spark Streaming
Spark MLlib
GraphFrames
Spark SQL /
DataFrames
Distributed
DASK Delayed DASK Futures
Design
Approach
DASK Arrays
[Parallel NumPy]
DASK DataFrames
[Parallel Pandas]
DASK-ML
[Parallel Scikit-learn]
DASK Bag
[Parallel Lists]
Mesos YARN
Local Scheduler
Pluggable Task Scheduling System
Custom
Graphs
Submit
graph as
Python
Dictionary
object
GraphX doesn’tsupport Python](https://image.slidesharecdn.com/052020gurpreetsingh-190509225732/75/DASK-and-Apache-Spark-5-2048.jpg)
![DASK DataFrame & PySpark
6#UnifiedAnalytics #SparkAISummit
DASK DataFrames
[Parallel Pandas]
§ Performance Concerns due to the PySpark Design§ DASK DataFrames API is not identical with Pandas API
§ Performance Concerns with Operations involving Shuffling
§ Inefficiencies of Pandas are carried over
Challenges Challenges
§ Follow the Pandas Performance tips
§ Avoid Shuffle, Use pre-sorting, Persist the Results
§ Use DataFrames API
§ Use Vectorized/Pandas UDF (Spark v2.3 onwards)
RecommendationsRecommendations](https://image.slidesharecdn.com/052020gurpreetsingh-190509225732/75/DASK-and-Apache-Spark-6-2048.jpg)


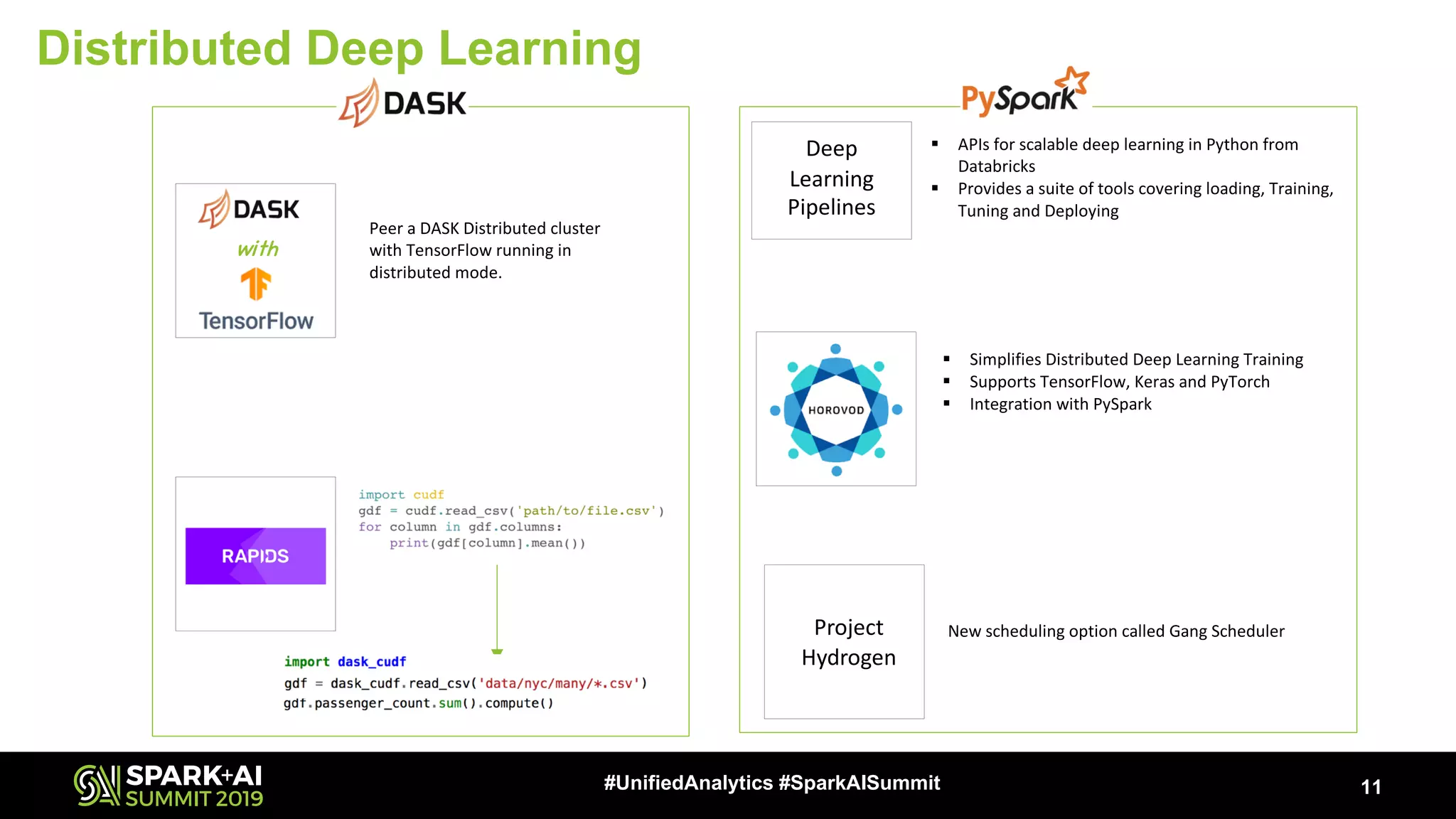





Gurpreet Singh from Microsoft gave a talk on scaling Python for data analysis and machine learning using DASK and Apache Spark. He discussed the challenges of scaling the Python data stack and compared options like DASK, Spark, and Spark MLlib. He provided examples of using DASK and PySpark DataFrames for parallel processing and showed how DASK-ML can be used to parallelize Scikit-Learn models. Distributed deep learning with tools like Project Hydrogen was also covered.




































































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)

